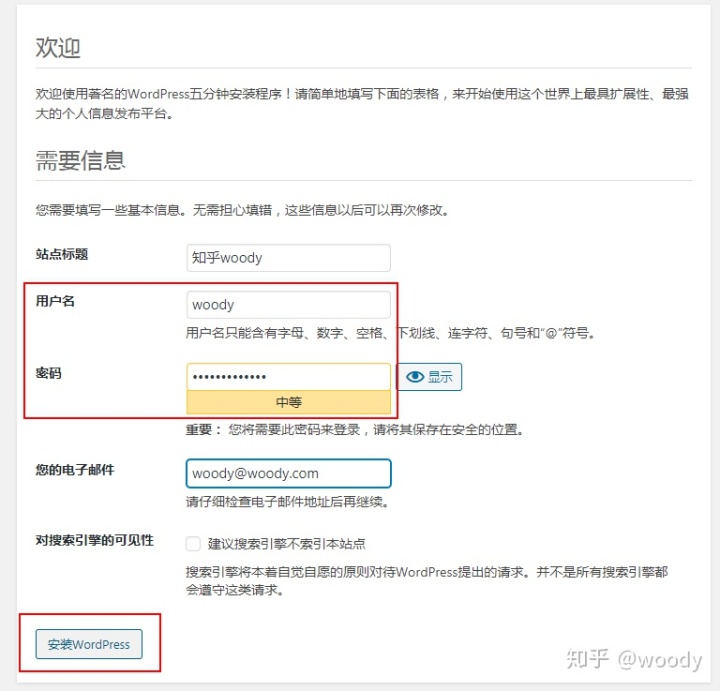
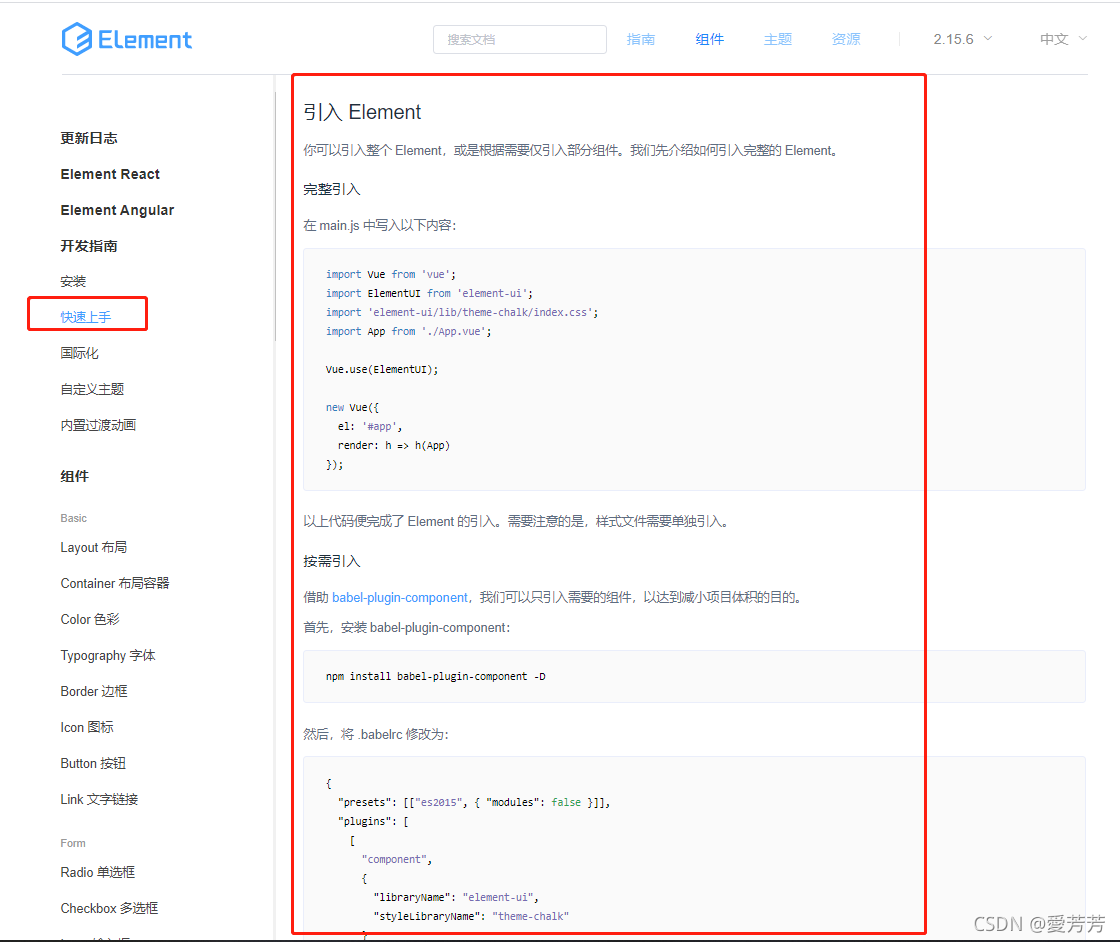
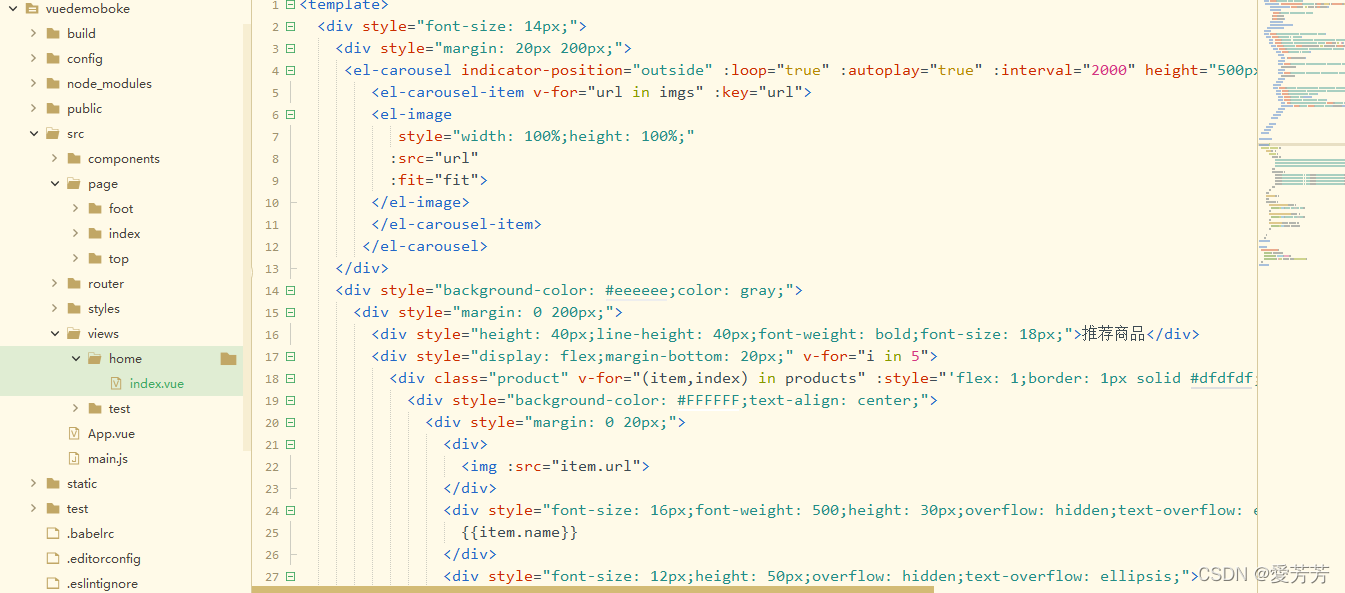
代码如下:
import requestsfrom bs4 import BeautifulSoupimport pandas as pd #导入pandas模块,并设置为pdr=requests.get("http://www.runoob.com/html/html-intro.html")html=r.text.encode(r.encoding).decode() #对r的内容进行中文解码并赋值给htmlsoup=BeautifulSoup(html,'lxml')print(soup) #打印解码后的soup内容,即html内容print("*"*50) #打印50个星号分割符print(soup.body.div) #打印soup的html文件内的body标签内的div标签的内容list1=[x for x in soup.findAll('div')] #遍历soup里的所有div标签,并赋值给list1df=pd.DataFrame(list1,columns=["http://www.runoob.com/html/html-intro.html"]) #将列标题设置为http://www.runoob.com/html/html-intro.html,并将list列表的数据依次存入相应单元格df.to_excel("将HTML的div数据存入Excel表格.xlsx") #将数据存入excel中,文件名为将HTML的div数据存入Excel表格.xlsx图片示例如下: