音乐是人们永恒的追求。自古有以来就有语音绕梁三日的佳话,由此几千年来我国人民对音乐的重视程度。为了让音乐得到更好的传播,让更多的人能够听到美妙的音乐。我们开发了PHP在线音乐点歌系统
PHP在线音乐点歌系统是一个音乐爱好者的乐土,本系统采用PHP:MySQL进行开发系统分为前台和后台两部分,现在部分主要是让用户查看和播放音乐,使用的后台部分主要是让管理人员对系统的音乐和其他信息以及管理使用的。
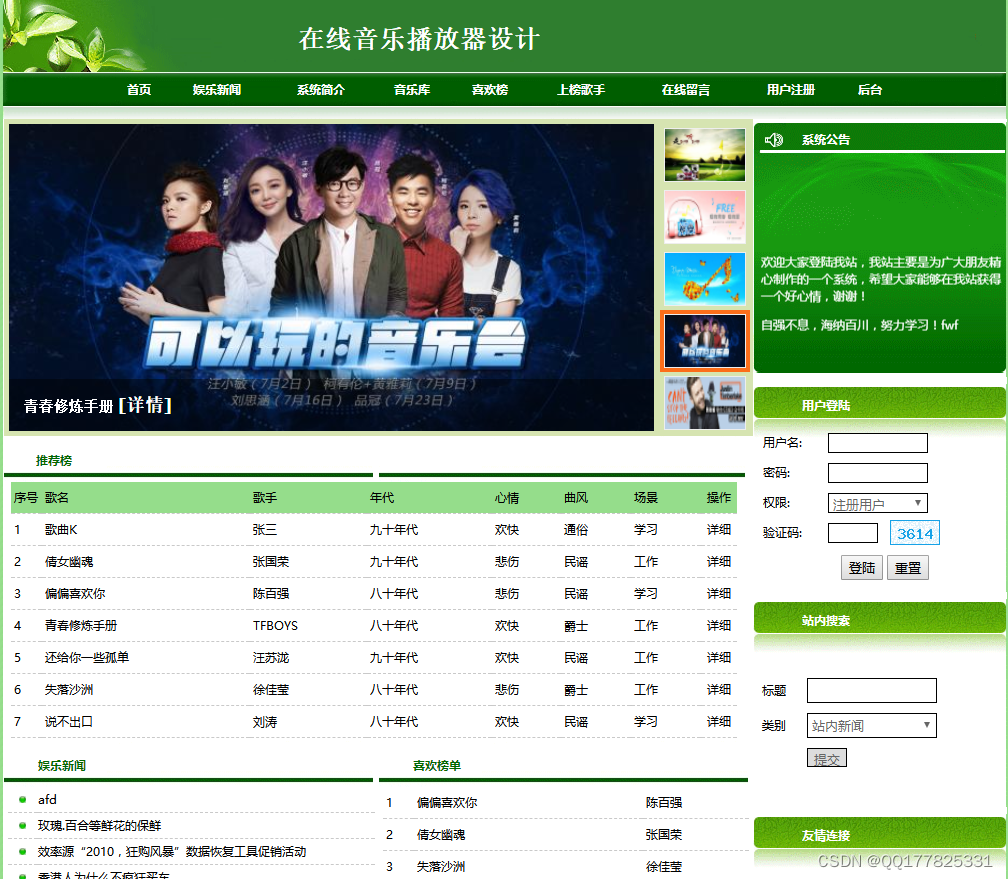
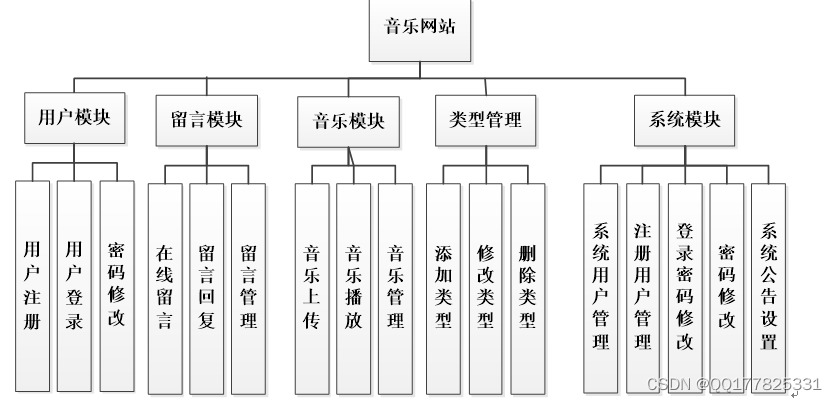
根据前面的各项设计分析,按照系统开发的基本理念对系统进行分解,从模块上主要可分为前台模块和后台模块。
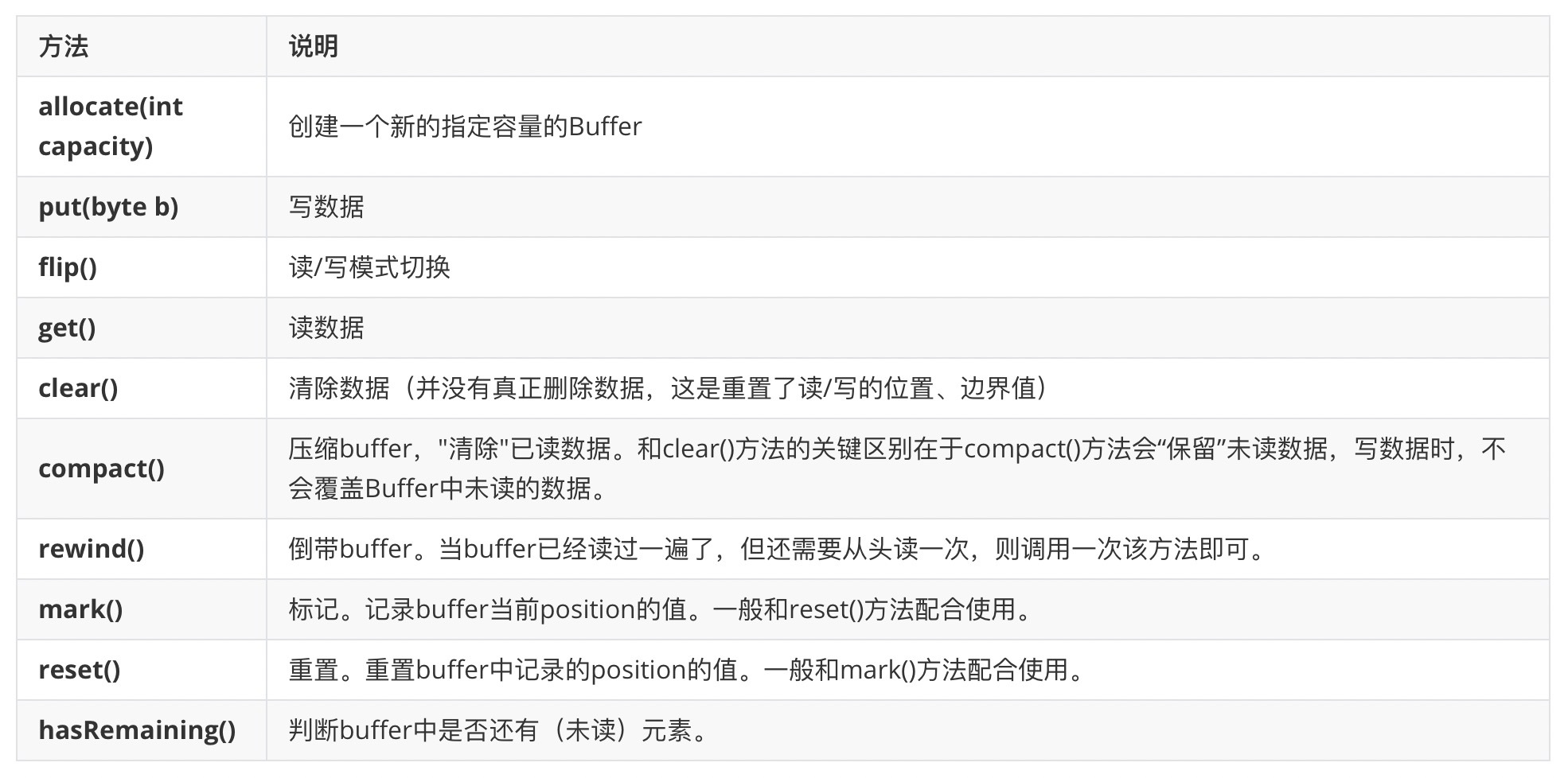
前台模块只要是让普通用户和游客用户使用,包括在线留言、音乐播放、添加喜欢、个人资料管理、上传音乐、喜欢音乐管理,后台模块只要是让管理员使用,包括系统用户管理(系统用户录入、删除、修改、登录密码修改、注册会员管理)、娱乐音乐管理(娱乐音乐录入、删除、修改)、属性标签管理(年代标签、心情标签、曲风标签、场景标签、语言标签)、音乐管理、用户喜欢管理、系统管理(系统公告设置、系统简介设置、留言管理、友情链接管理),后台可以对数据进行添加、删除、修改及查询等操作。
1.系统登录:系统登录是用户访问系统的路口,设计了系统登录界面,包括用户名、密码和验证码,然后对登录进来的用户判断身份信息,判断是管理员用户还是普通用户。
2.页面打印:设计系统时,在代码中连接打印机,进行系统的一些页面的打印。
3.导出报表:用户可能需要将某些数据列表提取出来,在代码中调用导出至excel中的函数,并开启连接excel的驱动,实现导出报表的功能。
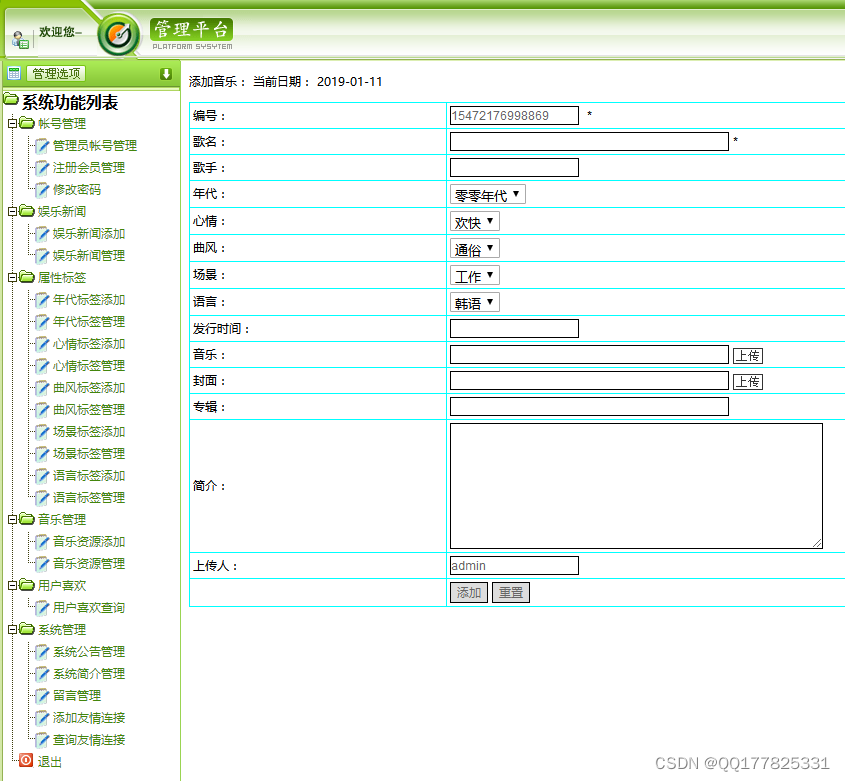
4.系统用户管理:不管是超级管理员还是普通管理员都需要管理系统用户,包括普通管理员的添加、删除、修改、查询,修改管理员的登录密码,新添加的管理员用户可以登录系统。
5.注册用户管理:游客在前台首页注册后,经过管理员后台,不管是超级管理员还是普通管理员都需要管理注册用户,包括注册用户审核、删除、修改、查询,审核通过后,注册用户既可以通过账号和密码登录系统。
6.修改密码:系统所有用户(管理员和注册用户)应该都要能修改自己的登录密码,修改后需要重新登录。
7.系统简介设置:系统管理员应该可以通过系统简介设置功能设置系统前台的系统简介信息,系统前台的系统简介是随后台的变化而变化的,系统简介应该使用编辑器,实现图片,文字,列表,样式等多功能输入。
8.系统公告设置:系统管理员应该可以通过系统公告设置功能设置系统前台的系统公告信息,系统前台的系统公告是随后台的变化而变化的,系统公告应该使用编辑器,实现图片,文字,列表,样式等多功能输入。
9.增加留言:设计留言信息表,包含留言标题、留言内容、回复内容、留言人等字段,留言标题、留言内容用来存储用户增加的留言,回复内容用来存储管理员回复的留言内容。
10.留言管理:系统管理员对留言信息表的删除、查询等操作,回复留言则将回复内容存储在留言表的回复内容字段里,删除不需要的留言,使用户有足够的空间进行留言。
11.个人资料管理:由注册用户使用,注册用户登录个人后台,可以修改个人当初的注册信息,如修改电话号码、邮箱等,用户的用户名是无法修改的。
12.友情链接管理:由超级管理员和普通管理员使用,对系统所有的友情链接信息进行添加、删除、修改、查询,同时系统前台的友情链接随着后台的友情链接变化而更新。
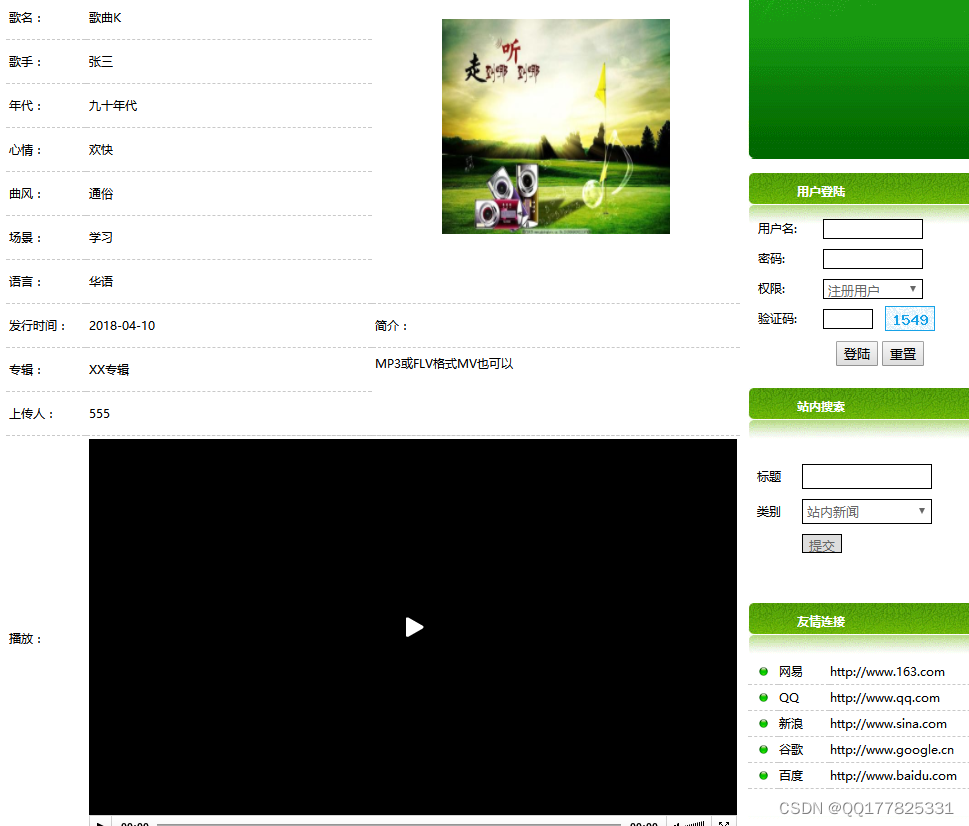
13.音乐管理:用户发布音乐信息,跳转至发布音乐页面,填写音乐表单,提交后,管理员审核音乐信息,审核成功,该音乐成功显示在系统前台。
14.音乐播放:管理员上传音乐文件,跳转至音乐上传页,填写表单,选择本地音乐文件,提交后,音乐发布成功,用户可以选择播放或者下载。
15.音乐类型管理:音乐类型管理包括音乐类型录入、音乐类型修改、音乐类型删除,在数据库中设计并建立音乐类型表,管理员添加音乐类型,即往数据表中插入一条数据,删除音乐类型,则在数据库删除一条数据,修改音乐类型,则修改数据库的数据。
随着网络技术的发展,人民在利用网络学习的同时,也在享受着网络带来的各种附带产品所产生的效应,如网络游戏,网络歌曲。音乐网站正是在这样的需求前提下应运而生。给人们的日常生活带来了极大的乐趣,让人们在繁忙疲惫的工作之后可以进行休闲。
根据在音乐网站的研究现状和发展趋势,系统从需求分析、结构设计、数据库设计,在到系统实现,分别为前端实现和后端实现。论文内容从系统描述、系统分析、系统设计、系统实现、系统测试来阐述系统的开发过程。本系统力求结合实际找出一种切实可行的开发方案,经过反复研究和学习,借助php编程语言、mysql数据库和apache服务器来完成系统的所有功能,最后进行系统测试,来检测系统的权限和漏洞,从而将系统完善,达到符合标准。
<?php
error_reporting(E_ALL ^ E_NOTICE);$conn=@mysql_connect("localhost","root","root") or die("数据库链接失败".mysql_error());
mysql_select_db("daizu",$conn) or die("数据库链接失败".mysql_error());
mysql_query('set names utf8');//设置时区
date_default_timezone_set('asia/shanghai');
define('SYS_ROOT', str_replace("\\", '/', dirname(__FILE__)));
define('File_ROOT', SYS_ROOT."/upload/");
define('IMG_ROOT', SYS_ROOT . "/upload/");@extract($_POST);
@extract($_GET);function getfirst($sql)
{$res=mysql_query($sql);$rows=mysql_fetch_array($res);return $rows;
}
//
function getcount($sql){$res=mysql_query($sql);return mysql_num_rows($res);
}
function get_name($id,$table)
{$sql="select * from $table where id='$id'";$rows=getfirst($sql);return $rows[name];
}
//遍历创建目录
function Remkdir($path) {if (!file_exists($path)) {Remkdir(dirname($path));@mkdir($path, 0777);}
}
//上传图片
function upload_image($inputname, $image=null, $type='upimages', $width=440) {$n = time().rand(1000,9999).'.jpg';$z = $_FILES[$inputname];if ($z && strpos($z['type'], 'image')===0 && $z['error']==0) {if (!$image) {Remkdir( IMG_ROOT . '/' . "{$type}/" );$image = "{$type}/{$n}";$path = IMG_ROOT . '/' . $image;} else {Remkdir( dirname(IMG_ROOT .'/' .$image) );$image = "{$type}/{$n}";$path = IMG_ROOT . '/' .$image;}
//echo $path ;move_uploaded_file($z['tmp_name'], $path);//echo $image;exit;return $image;}return $image;
}
//获取文件后缀名
function get_extend($file_name)
{
$extend = pathinfo($file_name);
$extend = strtolower($extend["extension"]);
return $extend;
}
//文件上传实现function upload_file($inputname, $file=null)
{$year = date('Y'); $day = date('md');$z = $_FILES[$inputname];$file_ext=get_extend($z['name']);$n = time().rand(1000,9999).".".$file_ext;if ($z && $z['error']==0) {if (!$file) {Remkdir( File_ROOT . '/' . "{$day}" );$file = "{$day}/{$n}";$path = File_ROOT . '/' . $file;} else {Remkdir( File_ROOT . '/' . "{$day}" );$file = "{$day}/{$n}";$path = File_ROOT . '/' .$file;}
//echo $path ;move_uploaded_file($z['tmp_name'], $path);//echo $file;exit;return $file;}return $file;
}
//分页函数.
function get_pager($url, $param, $count, $page = 1, $size = 10)
{$size = intval($size);if($size < 1)$size = 10;$page = intval($page);if($page < 1)$page = 1;$count = intval($count);$page_count = $count > 0 ? intval(ceil($count / $size)) : 1;if ($page > $page_count)$page = $page_count;$page_prev = ($page > 1) ? $page - 1 : 1;$page_next = ($page < $page_count) ? $page + 1 : $page_count;$param_url = '?';foreach ($param as $key => $value)$param_url .= $key . '=' . $value . '&';$pager['url'] = $url;$pager['start'] = ($page-1) * $size;$pager['page'] = $page;$pager['size'] = $size;$pager['count'] = $count;$pager['page_count'] = $page_count;if($page_count <= '1'){$pager['first'] = $pager['prev'] = $pager['next'] = $pager['last'] = '';}else{if($page == $page_count){$pager['first'] = $url . $param_url . 'page=1';$pager['prev'] = $url . $param_url . 'page=' . $page_prev;$pager['next'] = '';$pager['last'] = '';}elseif($page_prev == '1' && $page == '1'){$pager['first'] = '';$pager['prev'] = '';$pager['next'] = $url . $param_url . 'page=' . $page_next;$pager['last'] = $url . $param_url . 'page=' . $page_count;}else{$pager['first'] = $url . $param_url . 'page=1';$pager['prev'] = $url . $param_url . 'page=' . $page_prev;$pager['next'] = $url . $param_url . 'page=' . $page_next;$pager['last'] = $url . $param_url . 'page=' . $page_count;}}return $pager;
}
?>目录
1 绪论 1
1.1课题背景 1
1.2课题研究现状 1
1.3初步设计方法与实施方案 2
1.4本文研究内容 2
2 系统开发环境 4
2.1 使用工具简介 4
2.2 环境配置 4
2.3 B/S结构简介 4
2.4 MySQL数据库 5
2.5 框架介绍 5
3 系统分析 6
3.1系统可行性分析 6
3.1.1经济可行性 6
3.1.2技术可行性 6
3.1.3运行可行性 6
3.2系统现状分析 6
3.3功能需求分析 7
3.4系统设计规则与运行环境 8
3.5系统流程分析 8
3.5.1操作流程 8
3.5.2添加信息流程 9
3.5.3删除信息流程 10
4 系统设计 11
4.1系统设计主要功能 11
4.2数据库设计 11
4.2.1数据库设计规范 11
4.2.2 E/R图 11
4.2.3数据表 12
5 系统实现 25
5.1系统功能模块 25
5.2后台模块 27
5.2.1管理员功能模块 27
5.2.2用户功能模块 30
6 系统测试 33
6.1功能测试 33
6.2可用性测试 33
6.3性能测试 34
6.4测试结果分析 34
7结 论 35
参考文献 36
致 谢 37