【计组 期末版】1.计算机系统概论(一)搞定期末
前言
博主主页:潮.eth的博客_CSDN博客-C学习,C++学习,数据结构and算法领域博主
文章目录:【计组 期末版】计算机组成原理笔记目录
正文
文章目录
- 【计组 期末版】1.计算机系统概论(一)搞定期末
- 0.前言
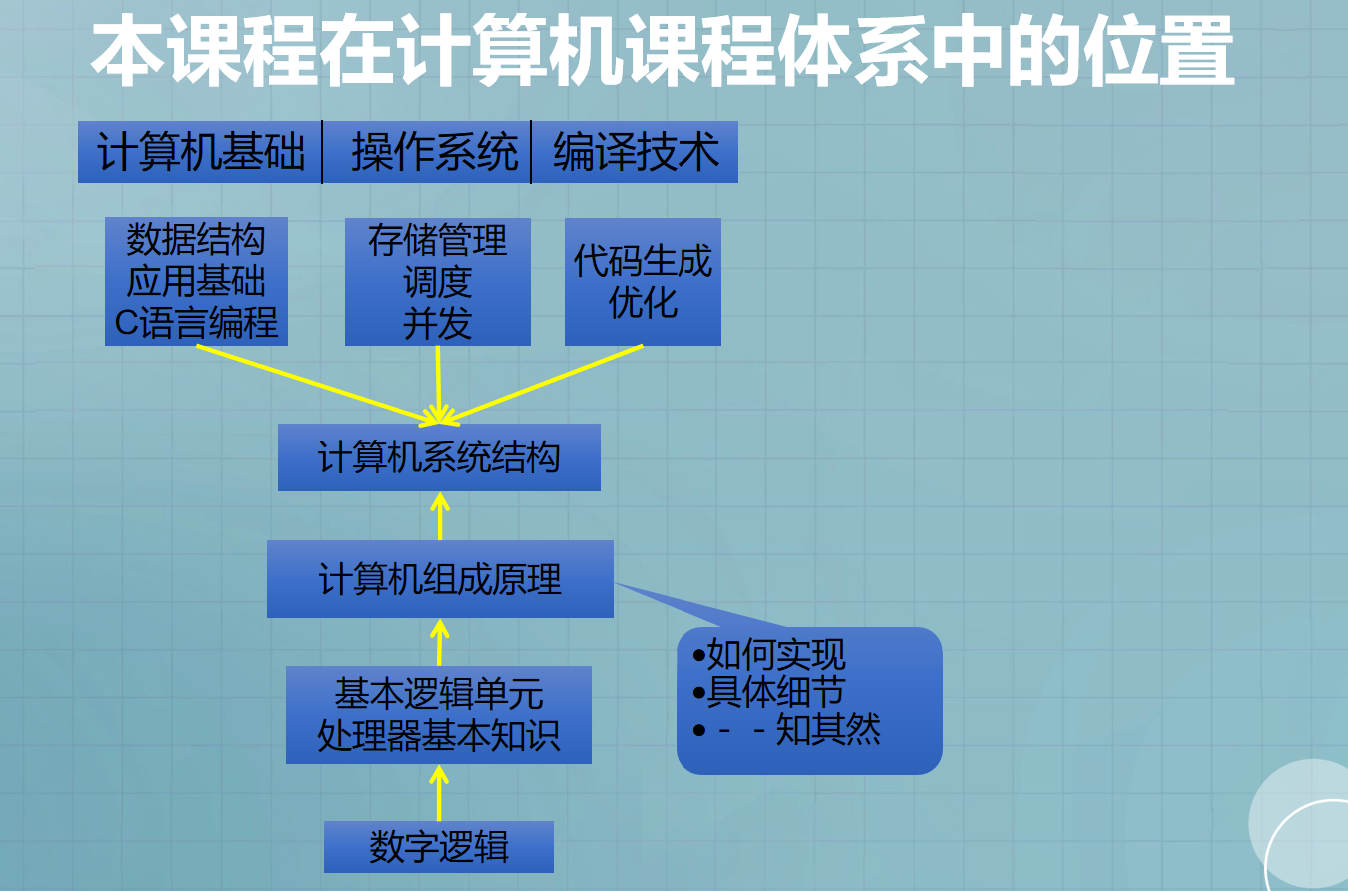
- 1.本课程在计算机课程体系中的位置
- 2.计算机系统简介
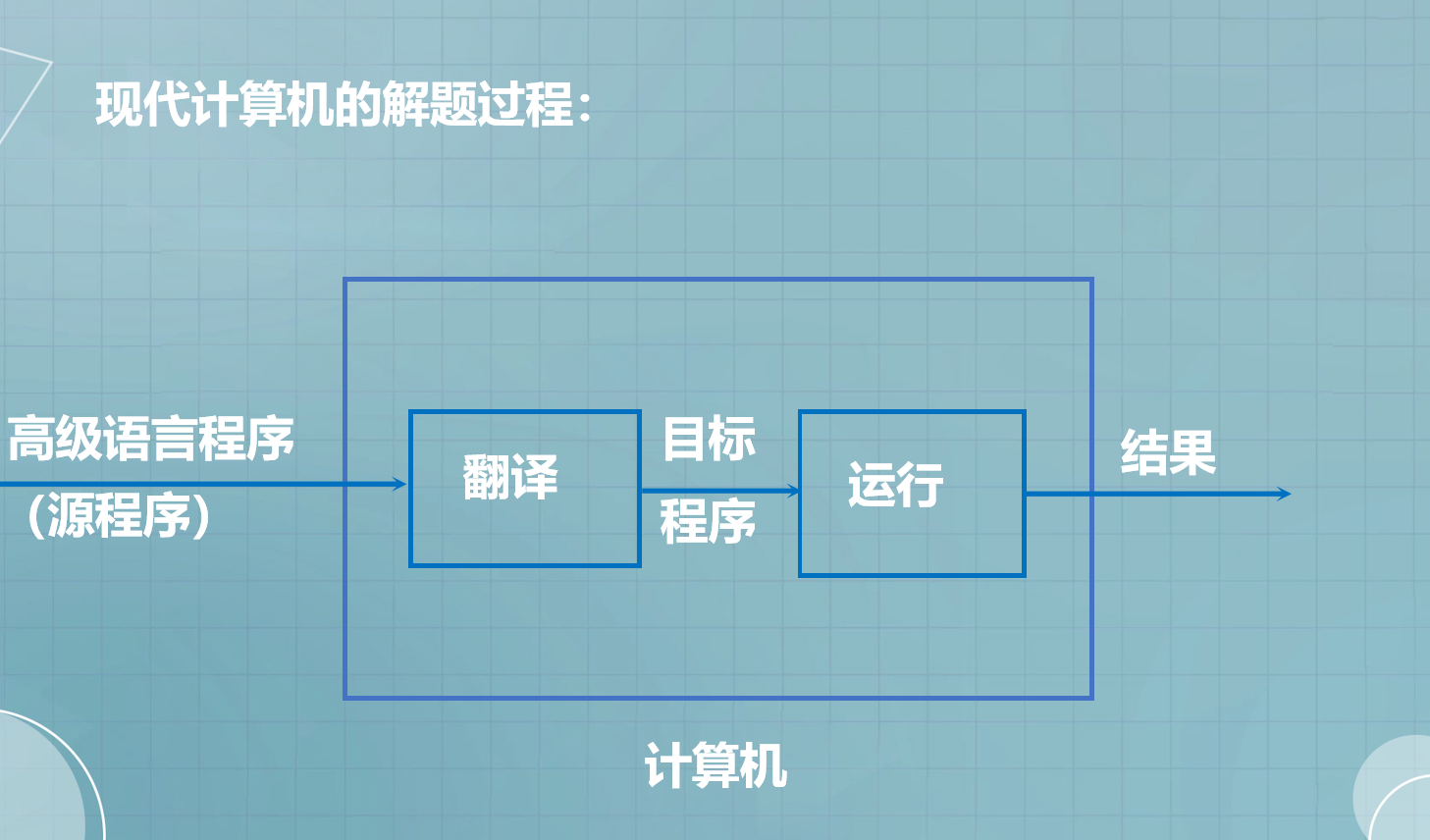
- 3.现代计算机的解题过程:
- 4.计算机系统的层次结构
- 5.计算机体系结构和计算机组成
- 6.计算机的基本组成
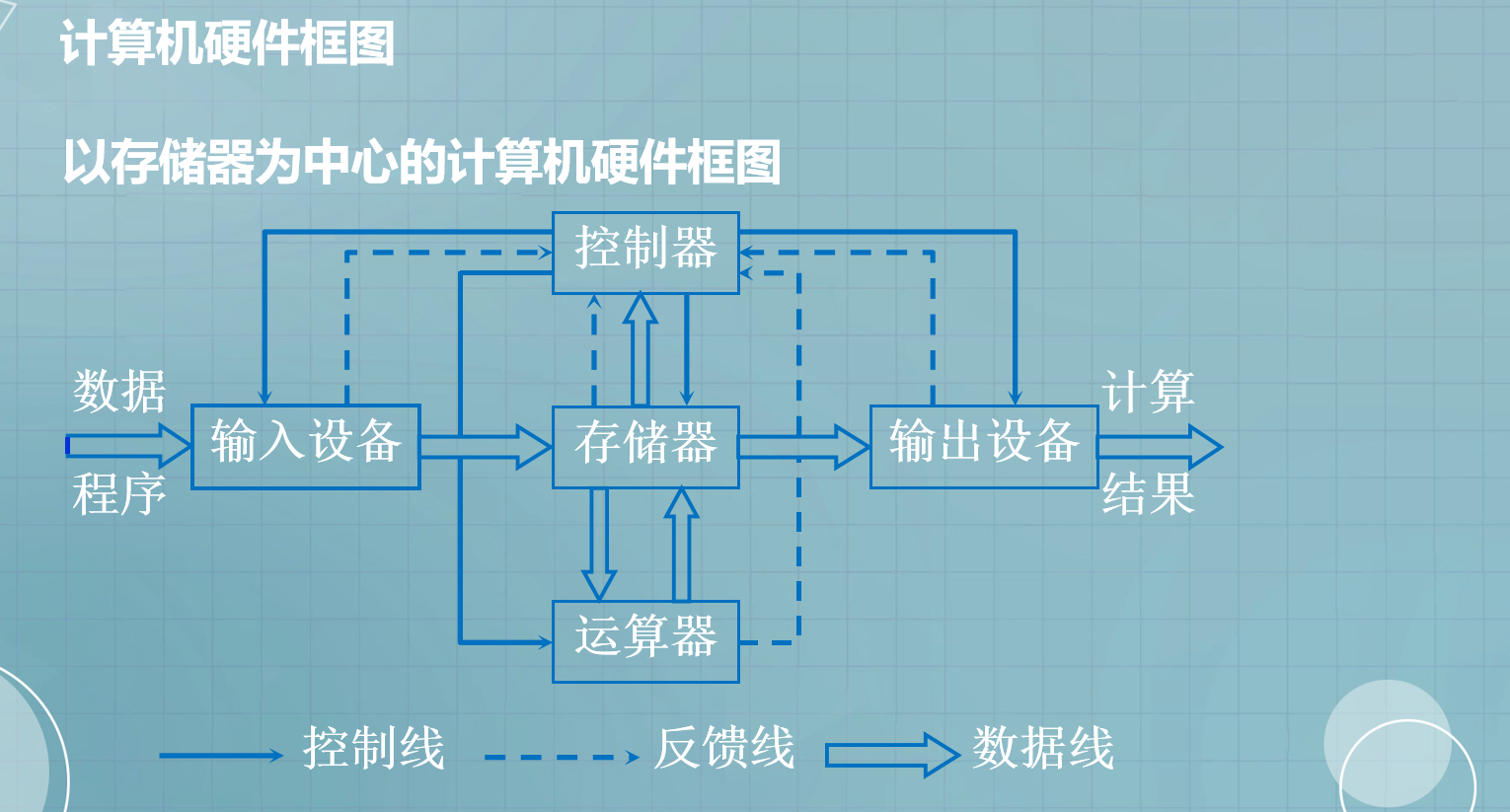
- 7.计算机硬件框图
- 8.现代计算机硬件框图
- 9.计算机的工作过程
- 10.存储器的基本组成
- 11.控制器的基本组成
0.前言
出题形式:选择题与填空题
1.本课程在计算机课程体系中的位置
2.计算机系统简介

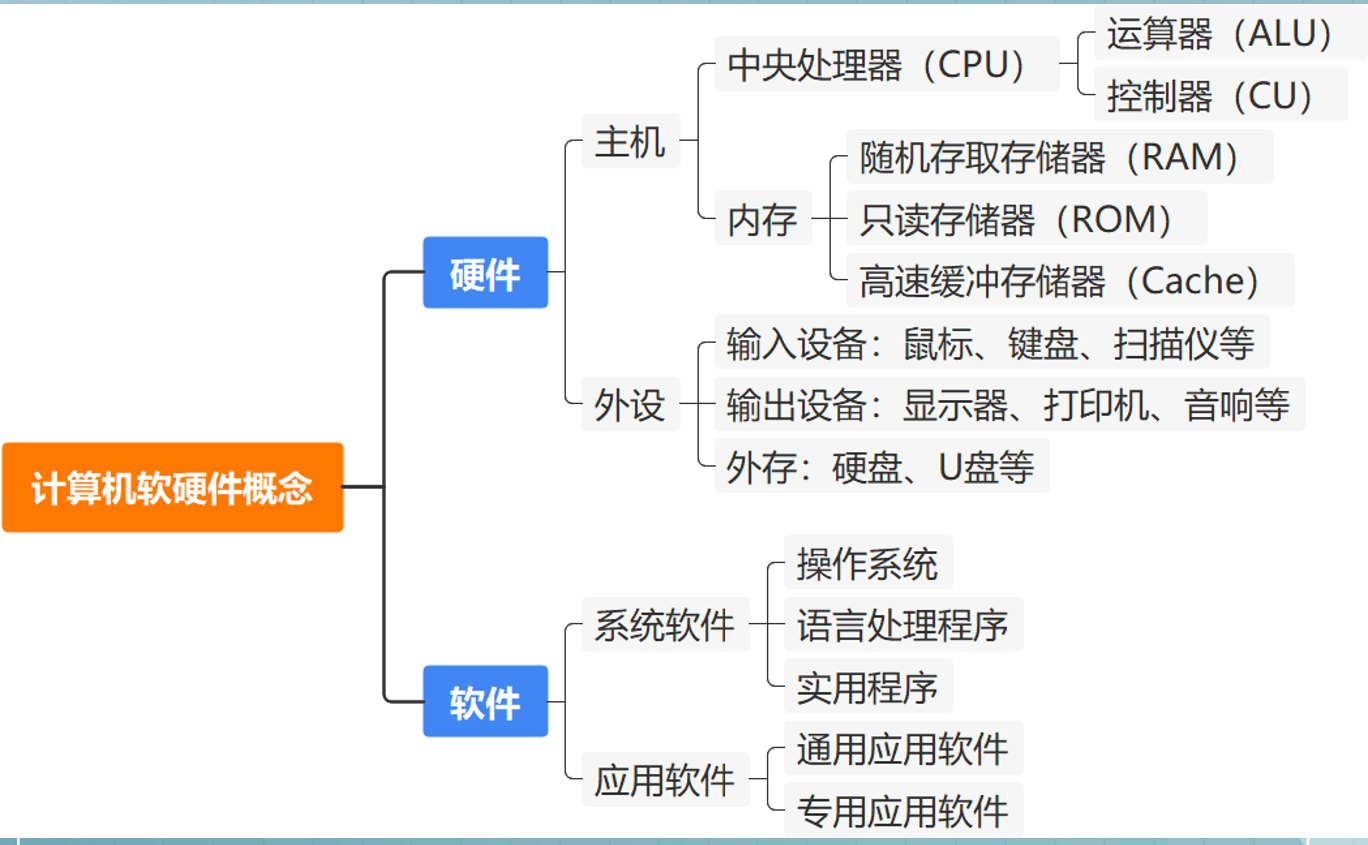
主要看硬件方面的主机部分就好了
3.现代计算机的解题过程:
4.计算机系统的层次结构
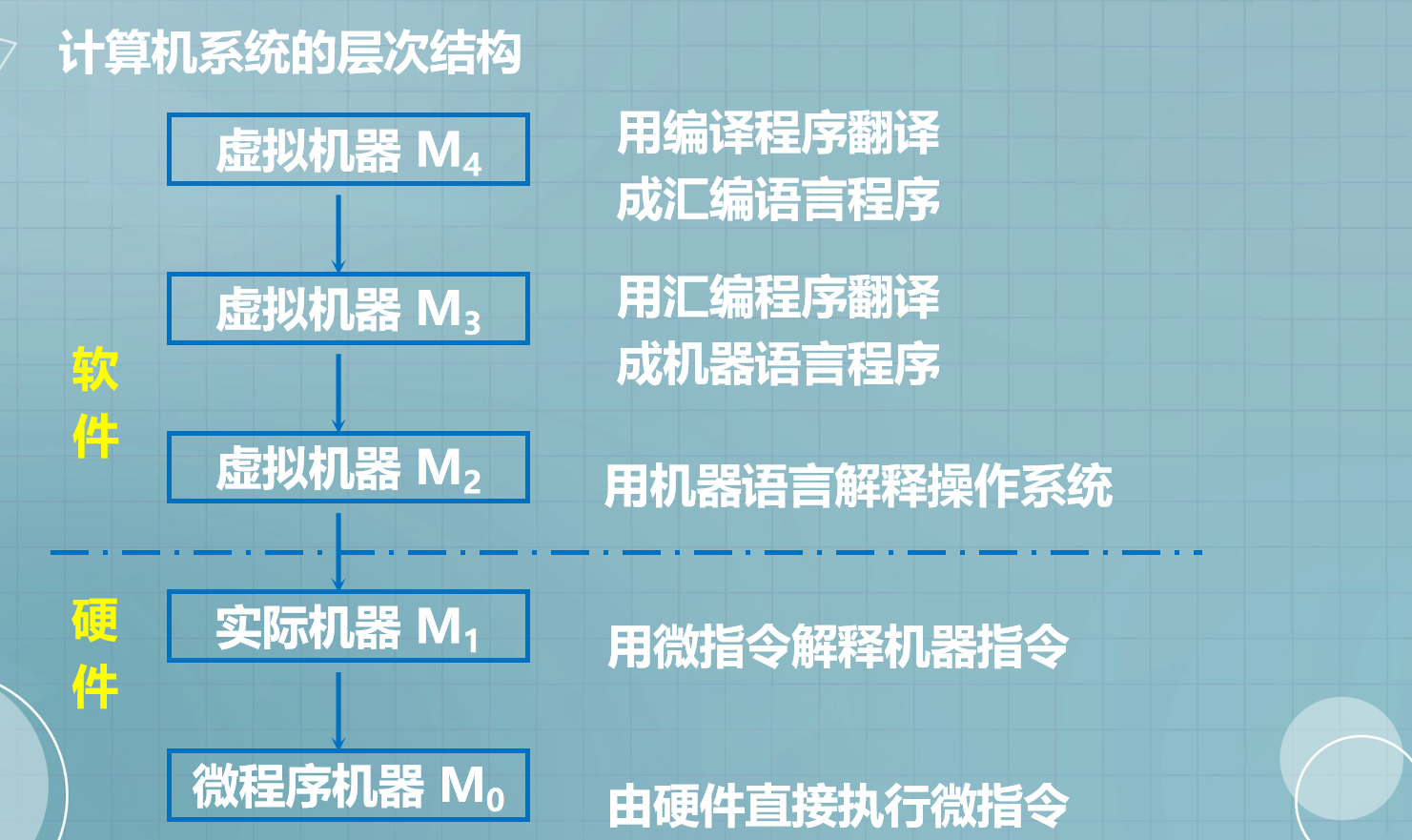
软件之上的可以结合C/C++程序的编译链接的过程理解。
5.计算机体系结构和计算机组成

6.计算机的基本组成

-
五大部件:运算器、存储器、控制器、输入设备和输出设备
-
5.存储程序控制原理!
7.计算机硬件框图


8.现代计算机硬件框图
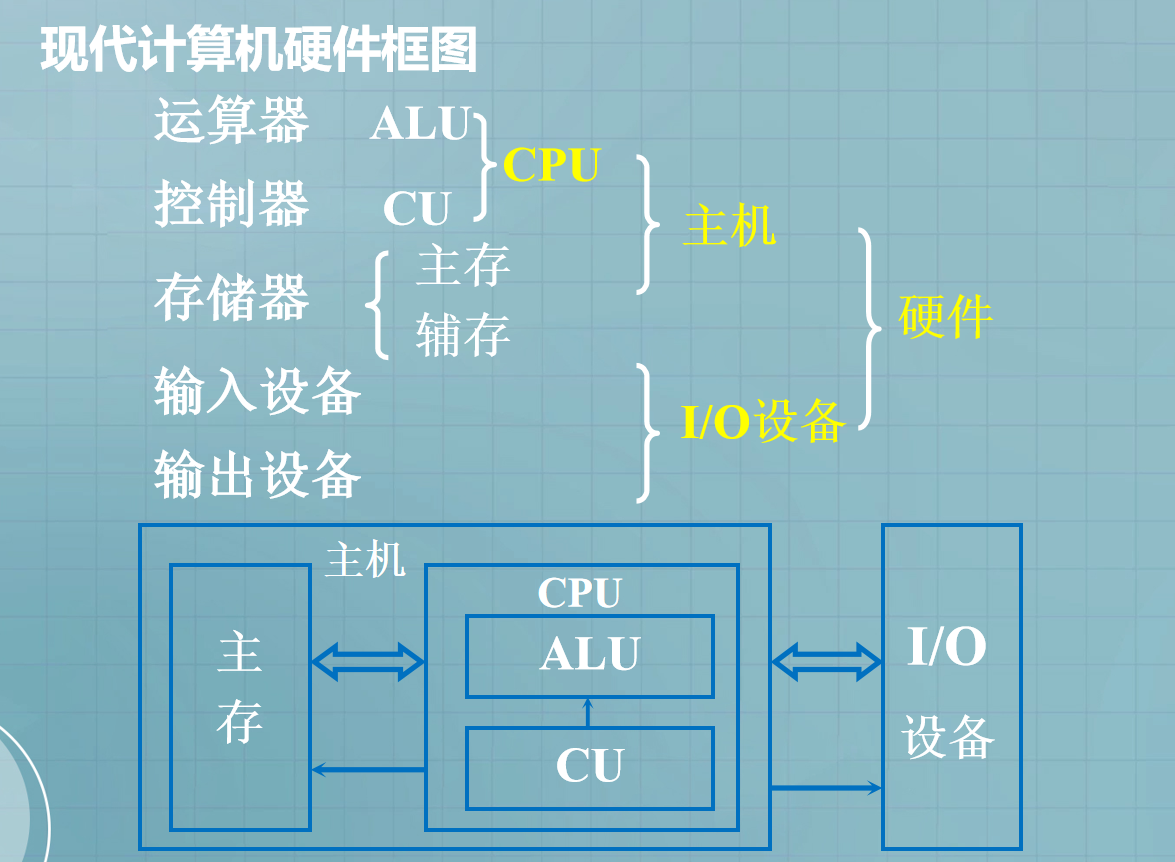
- 主机的组成:CPU、主存
- 辅存又叫外存,与输入设备、输出设备构成I/O设备
9.计算机的工作过程

- ALU:算数逻辑单元
- ACC:累加器
- MQ:商乘寄存器
- X:操作数寄存器
- IR:指令寄存器
- PC:程序计数器
- MAR:存储器地址寄存器
- MDR:存储器数据寄存器
10.存储器的基本组成

- 存储单元包含若干个存储元件,每个存储元件能寄存一位二进制代码“0”或“1”。
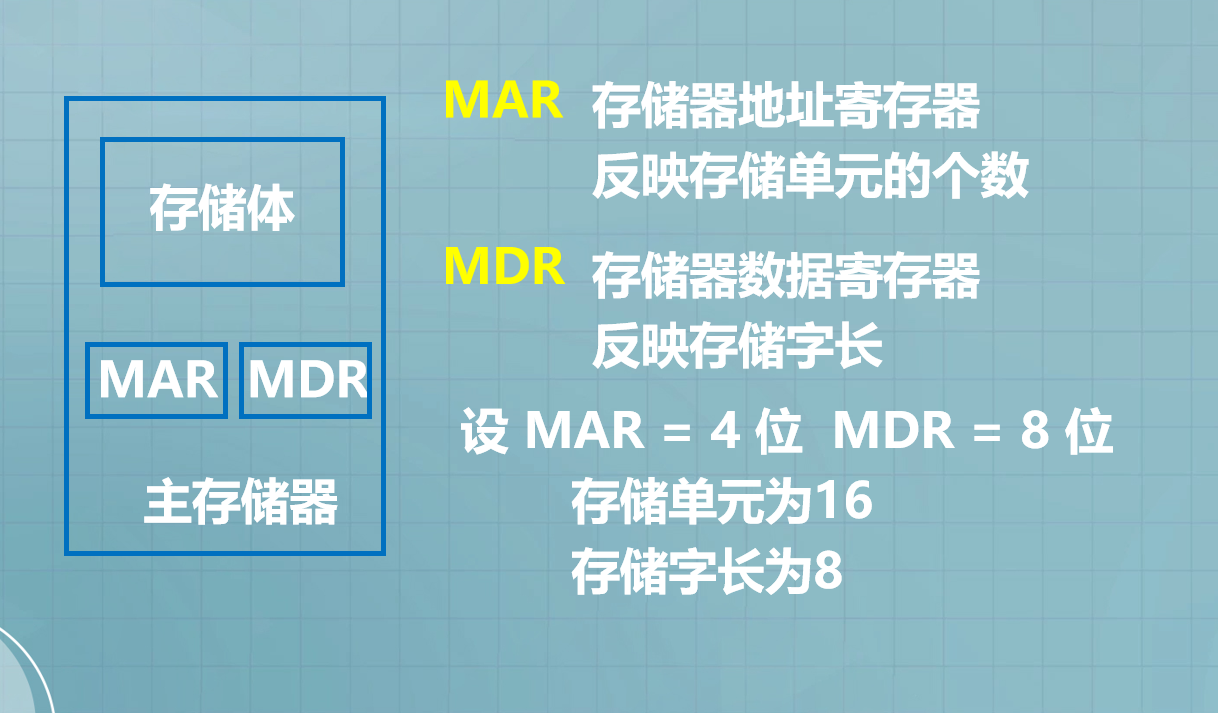
- MAR:用来存放欲访问的存储单元的地址,其位数对应存储单元的个数
(如MAR为10位,则有2^10=1 024个存储单元,记为1K )。
- MDR:用来存放从存储体从存储体某单元取出的代码或者往某存储单元存入的代码,其位数与存储字长相等。
11.控制器的基本组成