项目介绍
随着网络技术的发展,当前人们的生活模式发生了巨大的变化,特别是以电子商务为代表的产业影响了人们的生活。当前,电子商务成为振兴国家经济的重要手段,电子商务为人们的生活提供了极大的便利,帮助企业降低销售成本,提高销售效率。高速公路服务区作为传统的实体行业,经营运行中竞争激烈,投入高,管理效率低。而把高速公路服务区销售工作转移到网络中来,可以提高高速公路服务区销售利润,方便用户在线订购,具有一定的研究价值和实际意义。
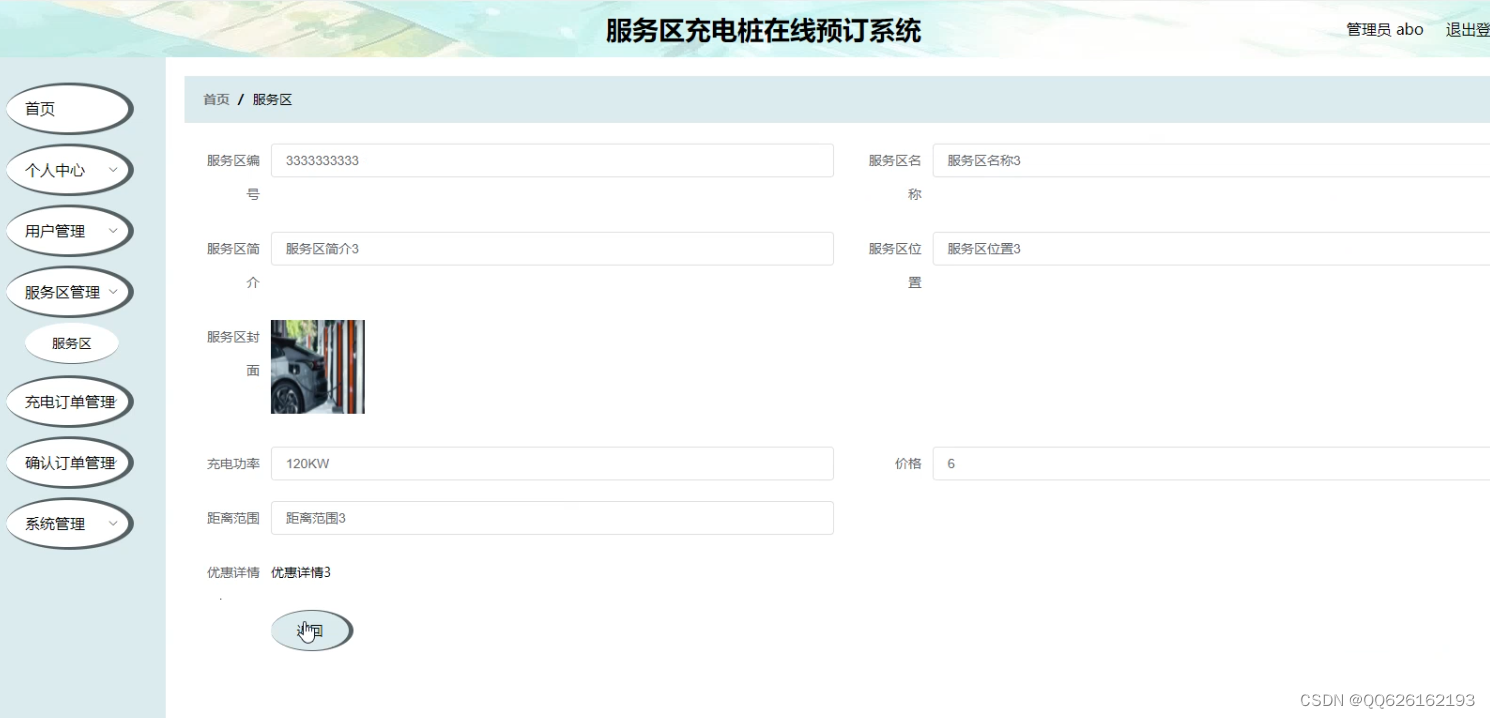
高速公路服务区充电桩在线预订系统根据目前实际的需求,开发出管理员后台管理高速公路服务区,微信小程序会员订购的高速公路服务区充电桩在线预订系统。该系统使用JAVA技术,MySQL数据库存储数据,实现了高速公路服务区信息管理、高速公路服务区订单管理、会员管理等功能。
本文主要工作是对网上高速公路服务区充电桩在线预订系统的分析,提出高速公路服务区充电桩在线预订系统的主要技术,对实体高速公路服务区需求进行分析,并转化为相应的功能模块,然后进行数据库设计,搭建系统框架,最后编写代码并对代码进行优化,对系统测试,完善程序中的问题。高速公路服务区充电桩在线预订系统提高了高速公路服务区整体的经济效率和管理水平,值得大力推广。
开发环境
开发说明:前端使用微信微信小程序开发工具:后端使用ssm:VUE开发
开发语言:Java
开发工具:IDEA /Eclipse/微信小程序开发工具
数据库:MYSQL5.7或以上
应用服务:Tomcat8或以上
功能介绍
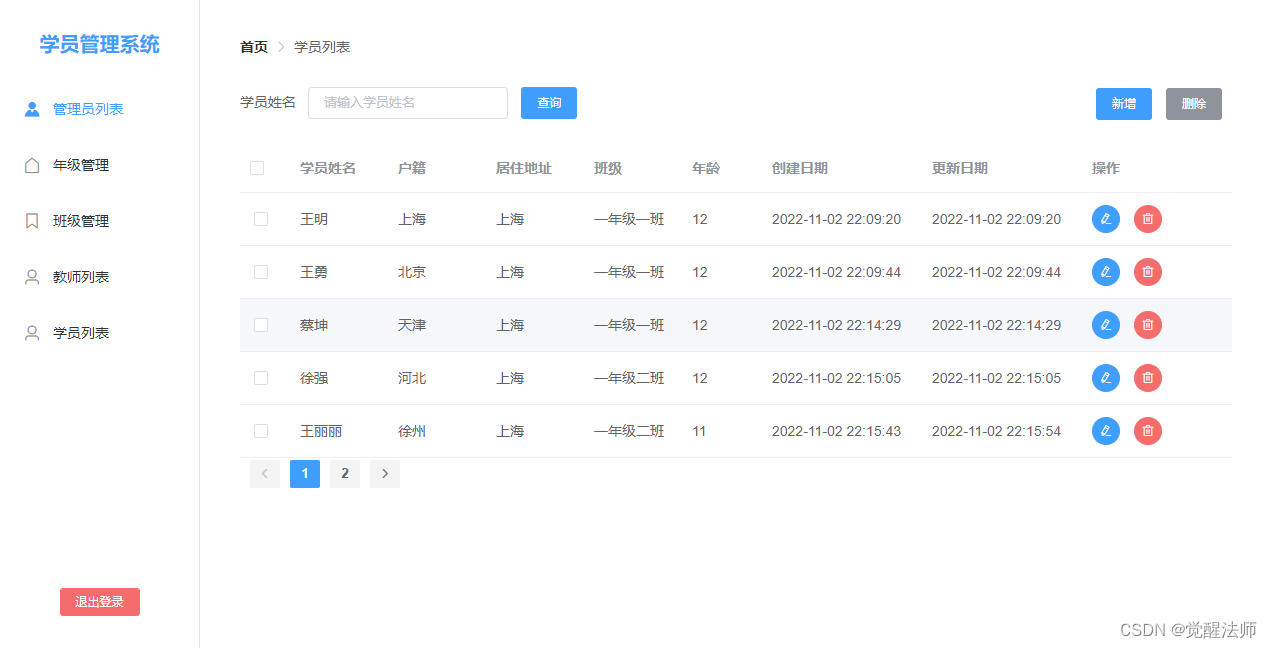
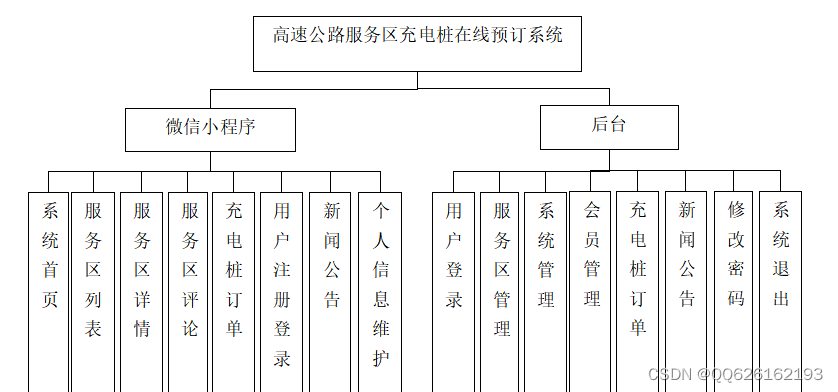
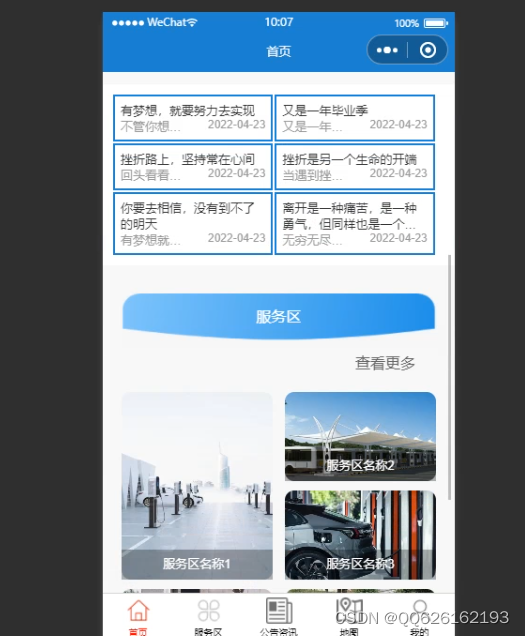
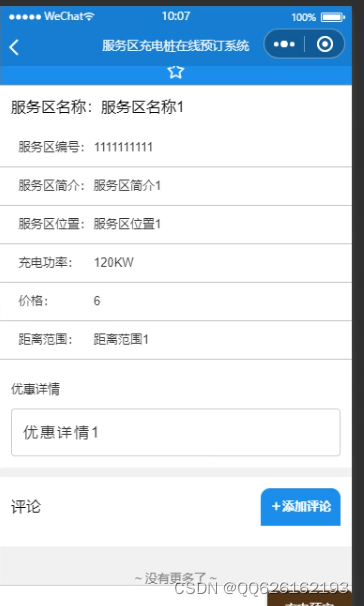
完成高速公路服务区充电桩在线预订系统的系统架构后,对系统的整体功能进行设计,系统从功能划分为微信小程序和后台。后台管理模块分为高速公路服务区管理、订单管理、用户管理、系统管理。微信小程序设计包括注册登录模块,高速公路服务区浏览查询,评论管理,高速公路服务区订单,个人中心。
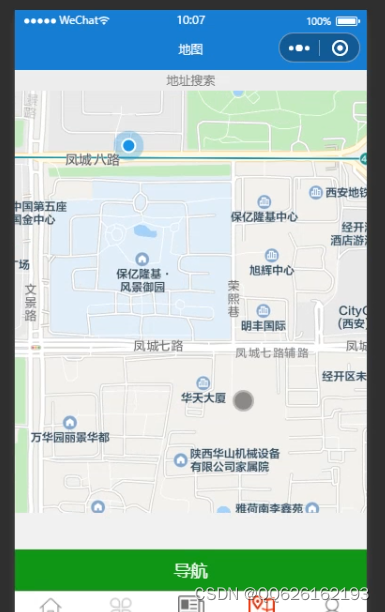
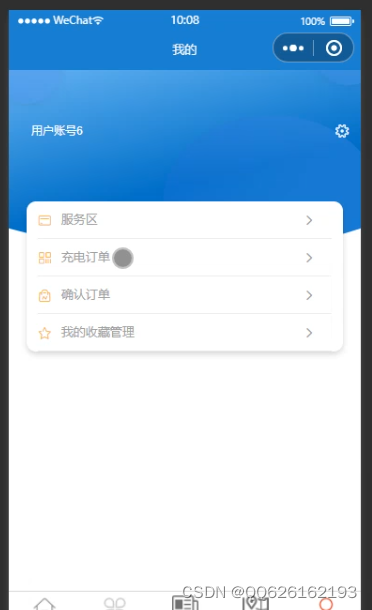
效果图
目 录
1绪论 1
1.1项目研究的背景 1
1.2开发意义 1
1.3项目研究现状及内容 5
1.4论文结构 5
2开发技术介绍 7
2.1 B/S架构 7
2.2 MySQL 介绍 7
2.3 MySQL环境配置 7
2.4 Java语言简介 8
2.5微信小程序技术 8
3系统分析 9
3.1可行性分析 9
3.1.1技术可行性 9
3.1.2经济可行性 9
3.1.3操作可行性 10
3.2网站性能需求分析 10
3.3网站功能分析 10
3.4系统流程的分析 11
3.4.1 用户管理的流程 12
3.4.2 个人中心管理流程 13
3.4.3 登录流程 13
4系统设计 14
4.1 软件功能模块设计 14
4.2 数据库设计 13
4.2.1 概念模型设计 13
4.2.2 物理模型设计 15
5系统详细设计 21
5.1系统前台功能模块 21
5.2管理员功能模块 24
6系统测试 30
7总结与心得体会 33
7.1 总结 33