Spring最重要的功能就是帮助程序员创建对象(也就是IOC),而启动Spring就是为创建Bean对象做准备,如果先分析Spring启动过程的源码,会比较难理解,因为你可能不知道为什么要做这些准备动作,所以我们先明白Spring到底是怎么去创建Bean的,也就是先弄明白Bean的生命周期,之后再分析Spring启动做了什么会更容易理解。
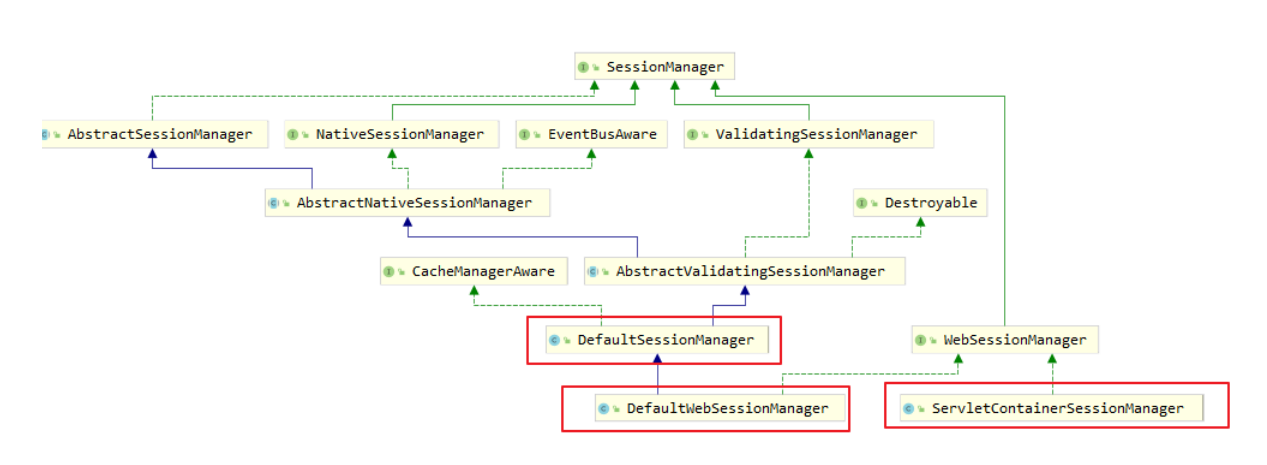
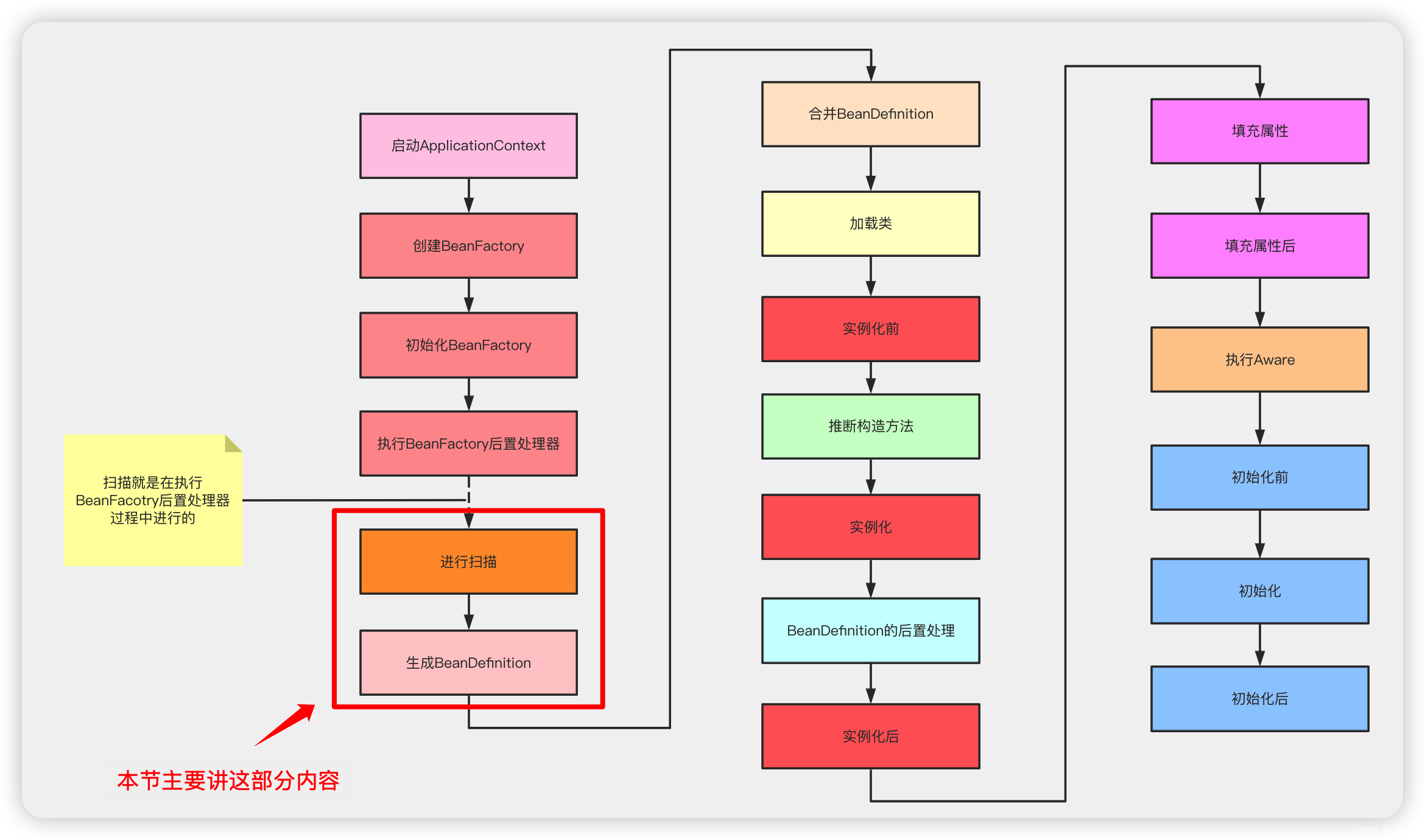
Bean的生命周期就是指:在Spring中,一个Bean是如何生成的,如何销毁的
Bean生命周期流程图:
前言
之前说过,AnnotationConfigApplicationContext的构造函数里会初始化扫描器:
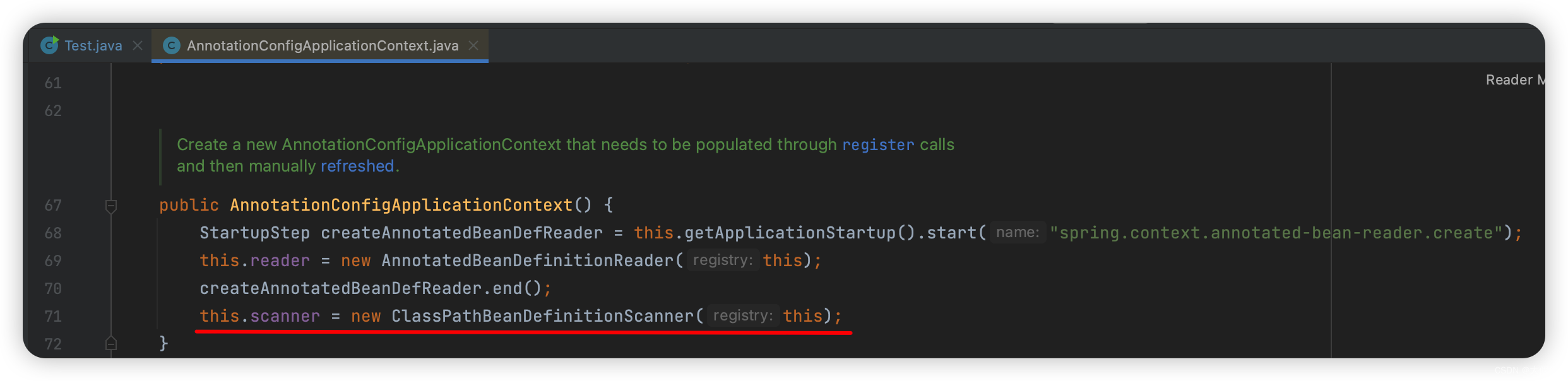
其中第一行StartupStep,是Spring 5.3之后加的新特性,现在有三个实现
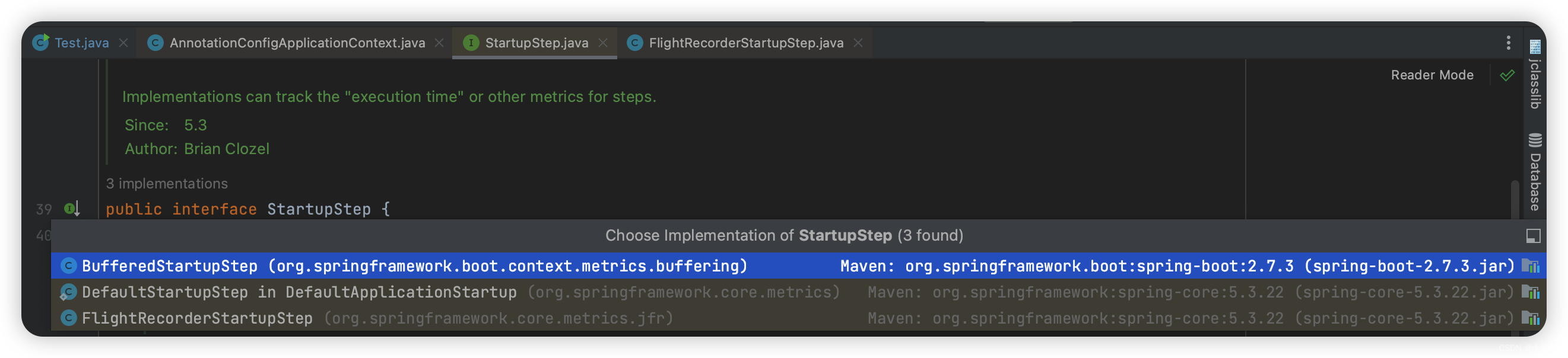
DefaultStartupStep是一个空实现,而FlightRecorderStartupStep使用了 jdk 的JFR 事件机制(jdk9之后新特性)实现了。
JFR:简单来说就是在jdk层面,提供了一种系统监控机制
感兴趣的可以看下这篇博客:https://zhuanlan.zhihu.com/p/122247741
回过头来看一下这段代码:
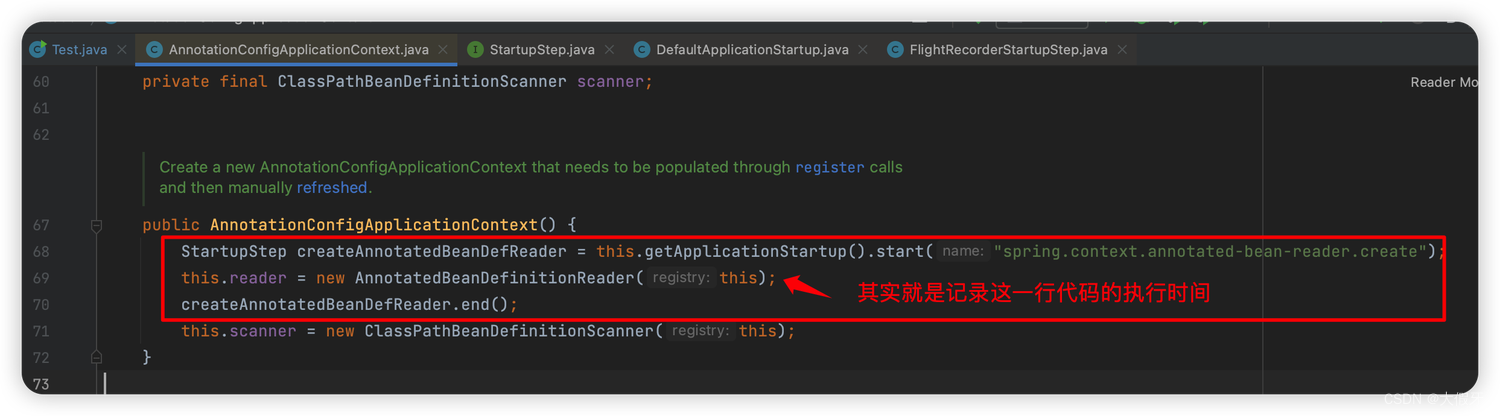
其实就是Spring利用jdk新特性,记录某些步骤的执行时间、等其他统计信息。
后续源码中看到StartupStep,可以直接忽视
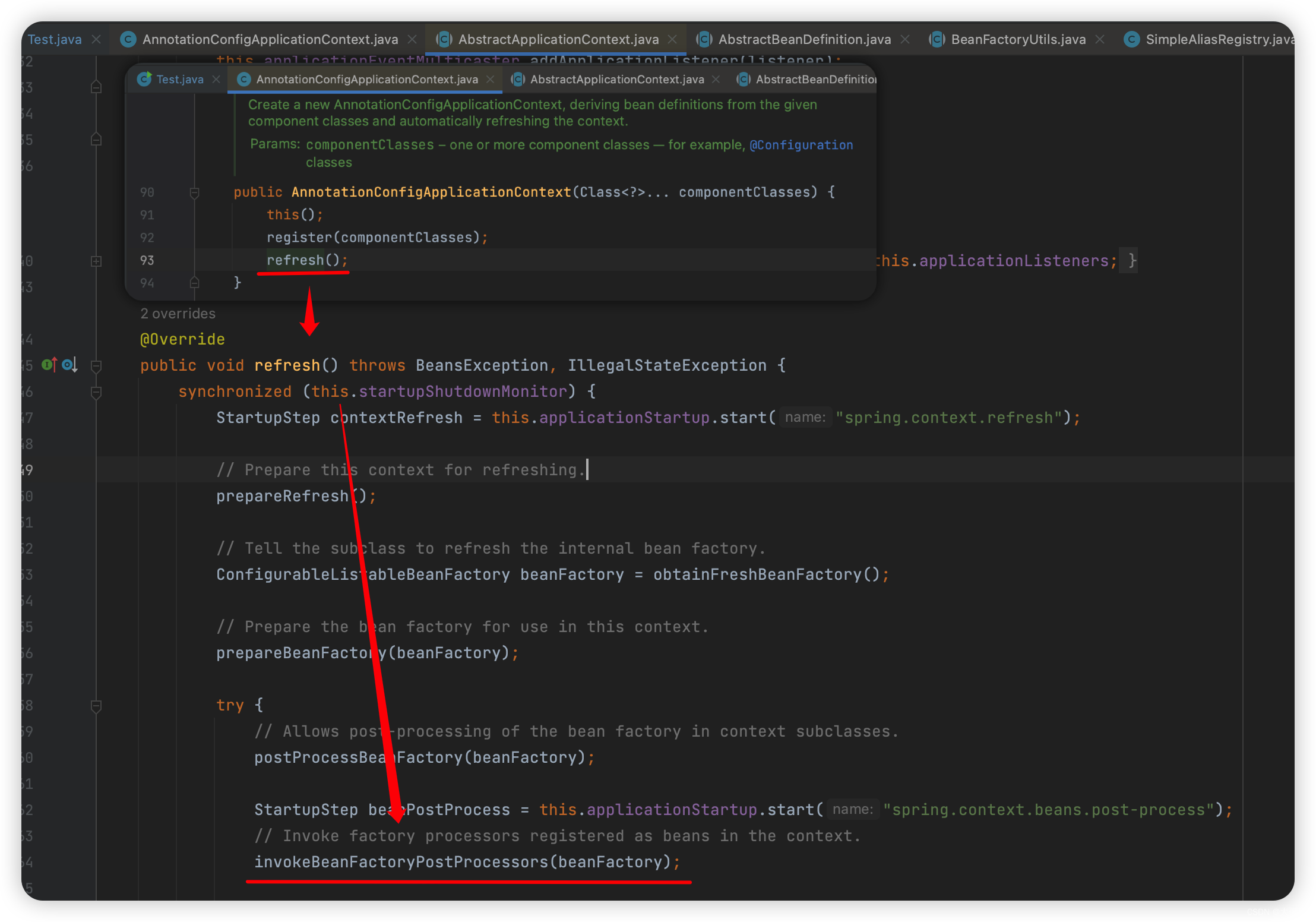
言归正传,这个扫描器是在哪里触发扫描的呢?
其实是在Spring启动、刷新容器的时候,在invokeBeanFactoryPostProcessors方法里会去调scanner的scan方法完成扫描,但是本节先不讲,后续章节会单独讲。
源码分析
入口
直接从扫描器的扫描入口方法看:
org.springframework.context.annotation.ClassPathBeanDefinitionScanner#scan
public int scan(String... basePackages) {//查看当前容器里存在多少个Beanint beanCountAtScanStart = this.registry.getBeanDefinitionCount();//扫描,核心看这里doScan(basePackages);// Register annotation config processors, if necessary.if (this.includeAnnotationConfig) {AnnotationConfigUtils.registerAnnotationConfigProcessors(this.registry);}// 返回本次扫描出多少个BeanDefinitionreturn (this.registry.getBeanDefinitionCount() - beanCountAtScanStart);
}
其中这个registry,在运行的时候其实就是DefaultListableBeanFactory,DefaultListableBeanFactory实现了这个接口(这里利用了接口隔离原则)。
继续看核心doScan方法
protected Set<BeanDefinitionHolder> doScan(String... basePackages) {Assert.notEmpty(basePackages, "At least one base package must be specified");Set<BeanDefinitionHolder> beanDefinitions = new LinkedHashSet<>();for (String basePackage : basePackages) {//1. 核心扫描逻辑在这个方法,会走到父类去//注意返回结果BeanDefinition里,只设置了部分属性:// 只在Object beanClass属性上设置了String className// 以及class对应的Resource资源文件、元数据注解信息// 其他信息都还没处理Set<BeanDefinition> candidates = findCandidateComponents(basePackage);for (BeanDefinition candidate : candidates) {//解析Scope注解ScopeMetadata scopeMetadata = this.scopeMetadataResolver.resolveScopeMetadata(candidate);candidate.setScope(scopeMetadata.getScopeName());//2. 生成Bean的名字String beanName = this.beanNameGenerator.generateBeanName(candidate, this.registry);if (candidate instanceof AbstractBeanDefinition) {//3. 给BeanDefinition设置一些默认的值postProcessBeanDefinition((AbstractBeanDefinition) candidate, beanName);}if (candidate instanceof AnnotatedBeanDefinition) {//4. 解析@Lazy、@Primary、@DependsOn、@Role、@Description,并给BeanDefinition赋值AnnotationConfigUtils.processCommonDefinitionAnnotations((AnnotatedBeanDefinition) candidate);}//5. 检查Spring容器中是否已经存在该beanNameif (checkCandidate(beanName, candidate)) {//将BeanDefinition和beanName封装成一个Holder对象//所以其实BeanDefinition里是没有beanName属性的,另外应该也是考虑到实现别名功能吧BeanDefinitionHolder definitionHolder = new BeanDefinitionHolder(candidate, beanName);definitionHolder =AnnotationConfigUtils.applyScopedProxyMode(scopeMetadata, definitionHolder, this.registry);beanDefinitions.add(definitionHolder);//6. 注册registerBeanDefinition(definitionHolder, this.registry);}}}return beanDefinitions;
}
1. 核心扫描逻辑
org.springframework.context.annotation.ClassPathScanningCandidateComponentProvider#findCandidateComponents
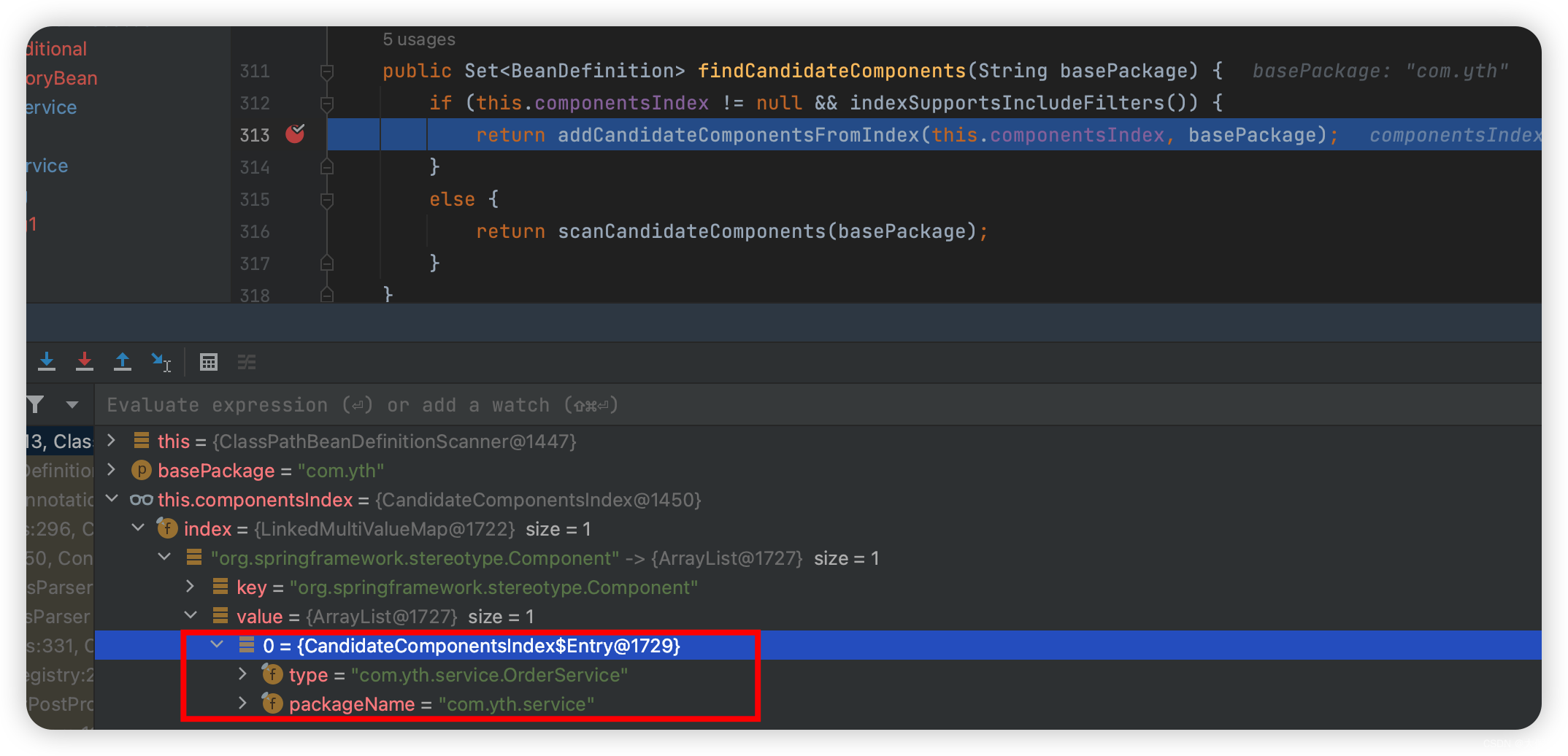
public Set<BeanDefinition> findCandidateComponents(String basePackage) {//这个componentsIndex见1.4if (this.componentsIndex != null && indexSupportsIncludeFilters()) {return addCandidateComponentsFromIndex(this.componentsIndex, basePackage);}else {//大部分走这里//注意此方法返回的BeanDefinition// 只在Object beanClass属性上设置了String className// 以及class对应的Resource资源文件、元数据注解信息// 其他属性都还没有处理return scanCandidateComponents(basePackage);}
}
private Set<BeanDefinition> scanCandidateComponents(String basePackage) {//basePackage包路径,格式比如:com.yth.serviceSet<BeanDefinition> candidates = new LinkedHashSet<>();try {//packageSearchPath = classpath*:com/yth/service/**/*.class//因此只会找当前包路径下的class文件String packageSearchPath = ResourcePatternResolver.CLASSPATH_ALL_URL_PREFIX +resolveBasePackage(basePackage) + '/' + this.resourcePattern;Resource[] resources = getResourcePatternResolver().getResources(packageSearchPath);boolean traceEnabled = logger.isTraceEnabled();boolean debugEnabled = logger.isDebugEnabled();//遍历每一个class文件for (Resource resource : resources) {if (traceEnabled) {logger.trace("Scanning " + resource);}try {//元数据读取器,利用asm技术读取类的信息(上一章提过)MetadataReader metadataReader = getMetadataReaderFactory().getMetadataReader(resource);//1.1 通过元数据读取器,判断是否是候选Bean//这里判断主要包含:excluteFilters、includeFilters、@Conditionalif (isCandidateComponent(metadataReader)) {//1.2 构造ScannedGenericBeanDefinitionScannedGenericBeanDefinition sbd = new ScannedGenericBeanDefinition(metadataReader);sbd.setSource(resource);//1.3 判断当前BeanDefinition是否是候选Bean//主要判断类是否是独立的、是否是具体类..if (isCandidateComponent(sbd)) {if (debugEnabled) {...}candidates.add(sbd);}else {...}}else {...}}catch (FileNotFoundException ex) {...}catch (Throwable ex) {...}}}catch (IOException ex) {...}return candidates;
}
1.1 判断是否是候选Bean(excluteFilters、includeFilters、@Conditional)
org.springframework.context.annotation.ClassPathScanningCandidateComponentProvider#isCandidateComponent(org.springframework.core.type.classreading.MetadataReader)
protected boolean isCandidateComponent(MetadataReader metadataReader) throws IOException {//排除过滤器,判断for (TypeFilter tf : this.excludeFilters) {if (tf.match(metadataReader, getMetadataReaderFactory())) {return false;}}//包含过滤器判断//符合includeFilters的会进行条件匹配,通过了才是Beanfor (TypeFilter tf : this.includeFilters) {//默认的includeFilter会看有没有@Component注解if (tf.match(metadataReader, getMetadataReaderFactory())) {//另外会看是否符合@Conditional的条件return isConditionMatch(metadataReader);}}return false;
}
由此可见,排除的优先级更高!
另外在ClassPathBeanDefinitionScanner的构造函数里会初始化一个默认的includeFilter:

关于条件注解的使用(源码就不看了):
比如自定义一个条件,实现Condition注解:
public class MyConditional implements Condition {@Overridepublic boolean matches(ConditionContext context, AnnotatedTypeMetadata metadata) {try {//存在com.yth.UserService这个类,则条件成立context.getClassLoader().loadClass("com.yth.UserService");return true;} catch (ClassNotFoundException e) {return false;}}
}
使用:
@Component
@Conditional(MyConditional.class)
public class OrderService {public void test() {System.out.println("orderService test");}
}
这样Spring扫描的时候发现class上有@Conditional注解,就会进行条件判断,最终调用Condition的matches方法,true则认为是匹配
源码中没有@Conditional注解则不进行条件判断:
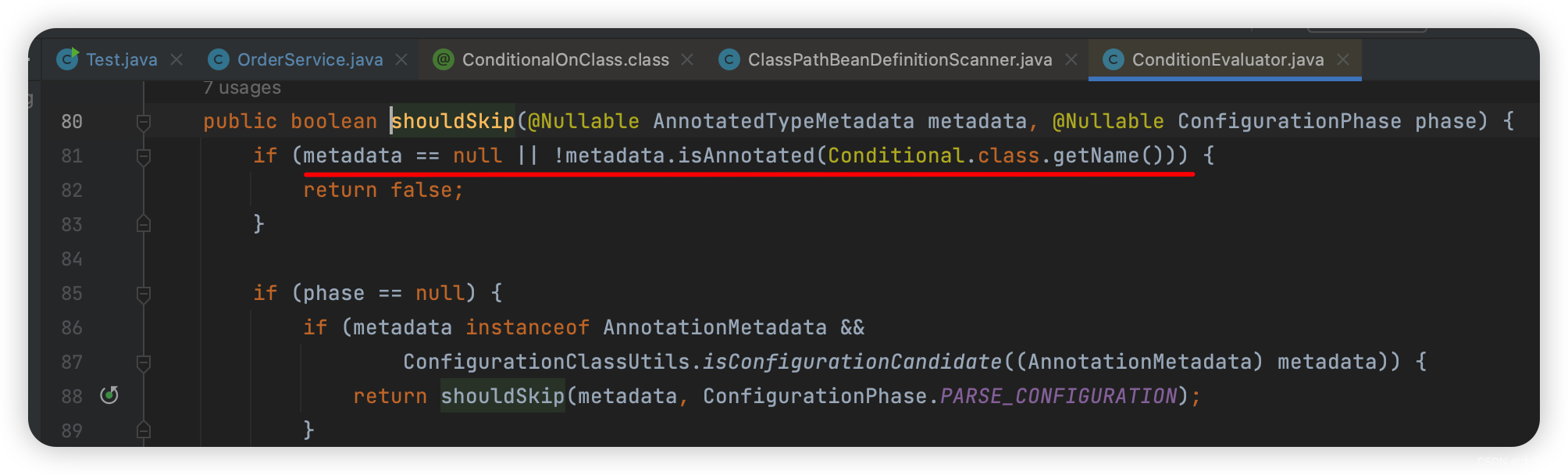
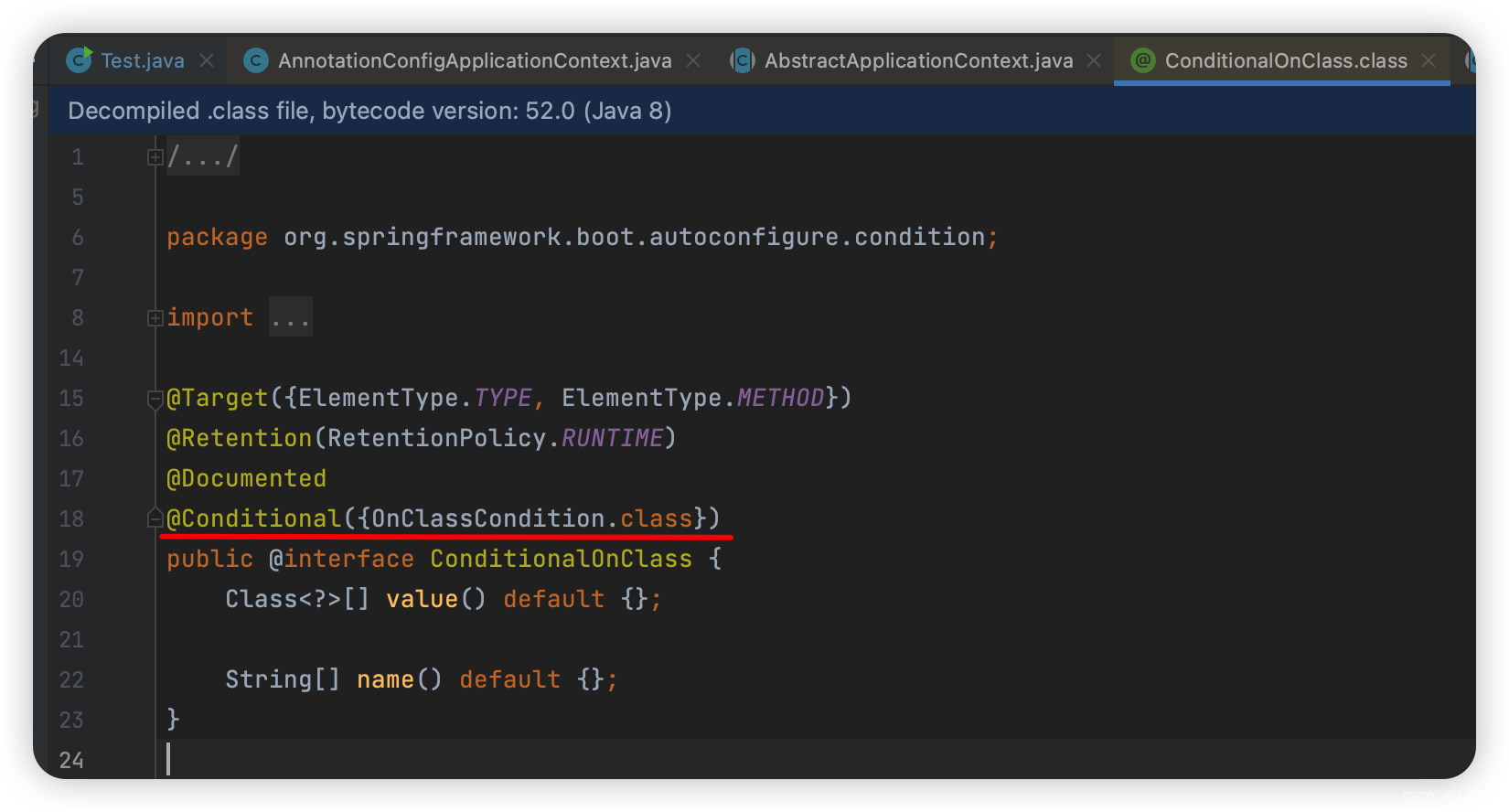
另外像SpringBoot中的@ConditionalOnClass、@ConditionalOnBean…底层都是@Conditional实现的…
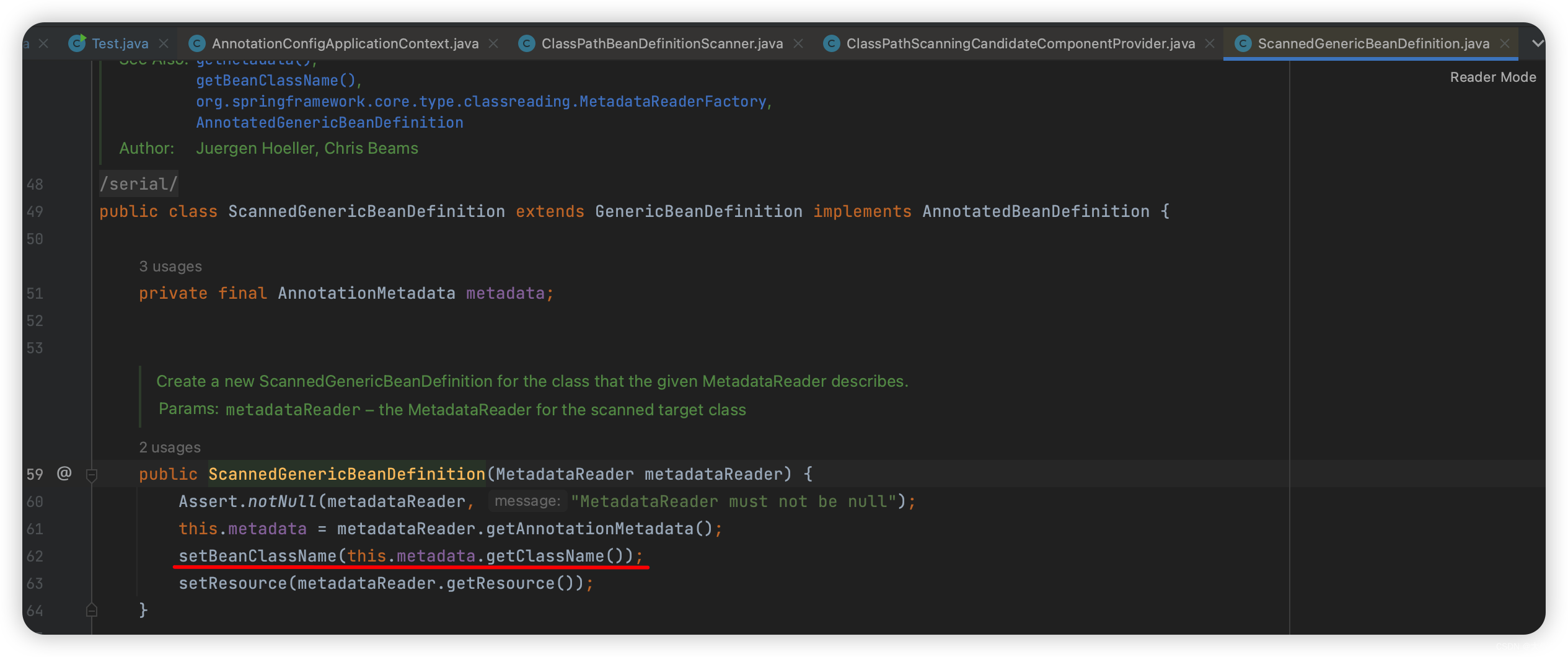
1.2 构造ScannedGenericBeanDefinition
这里只需要注意:
目前只是把当前类的名字设置到了BeanDefinition的beanClass属性!BeanDefinition的其他属性还都没有处理。
注意beanClass是Object类型:
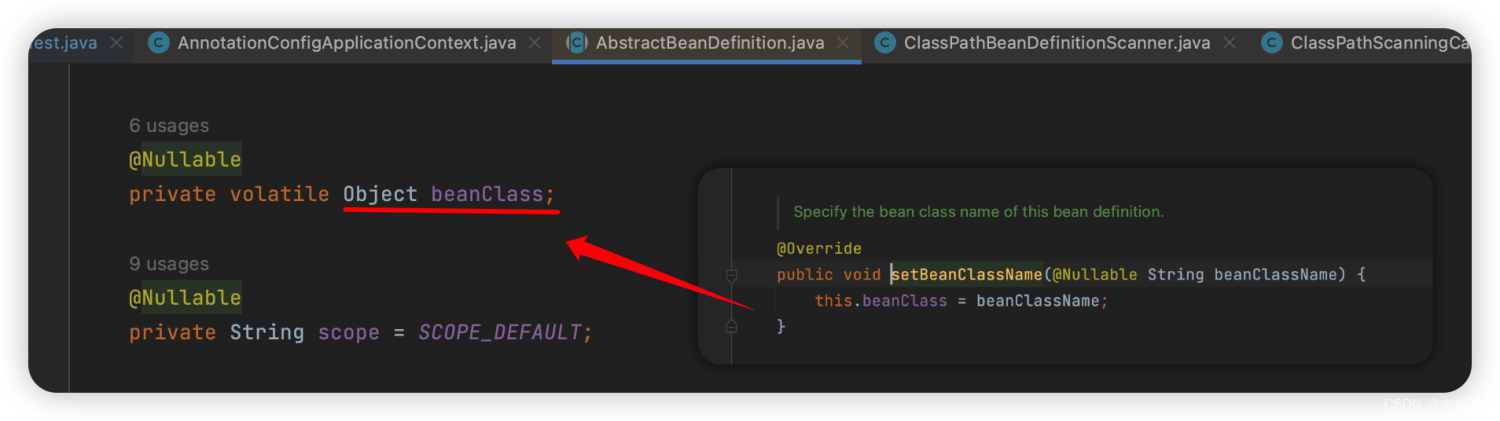
此时赋值的类型是String,不是Class对象
当真正需要创建这个类实例的时候,才会去加载类的Class对象
1.3 判断是否是候选Bean(类是否独立、具体)
org.springframework.context.annotation.ClassPathScanningCandidateComponentProvider#isCandidateComponent(org.springframework.beans.factory.annotation.AnnotatedBeanDefinition)
protected boolean isCandidateComponent(AnnotatedBeanDefinition beanDefinition) {AnnotationMetadata metadata = beanDefinition.getMetadata();//要求类是独立的,且// 是具体类// 或抽象类,但是有@Lookup注解标记的方法return (metadata.isIndependent() && (metadata.isConcrete() ||(metadata.isAbstract() && metadata.hasAnnotatedMethods(Lookup.class.getName()))));
}
-
isIndependent:是否独立
像下面这个内部类Member,就不属于独立的,Member2是静态内部类,是独立的
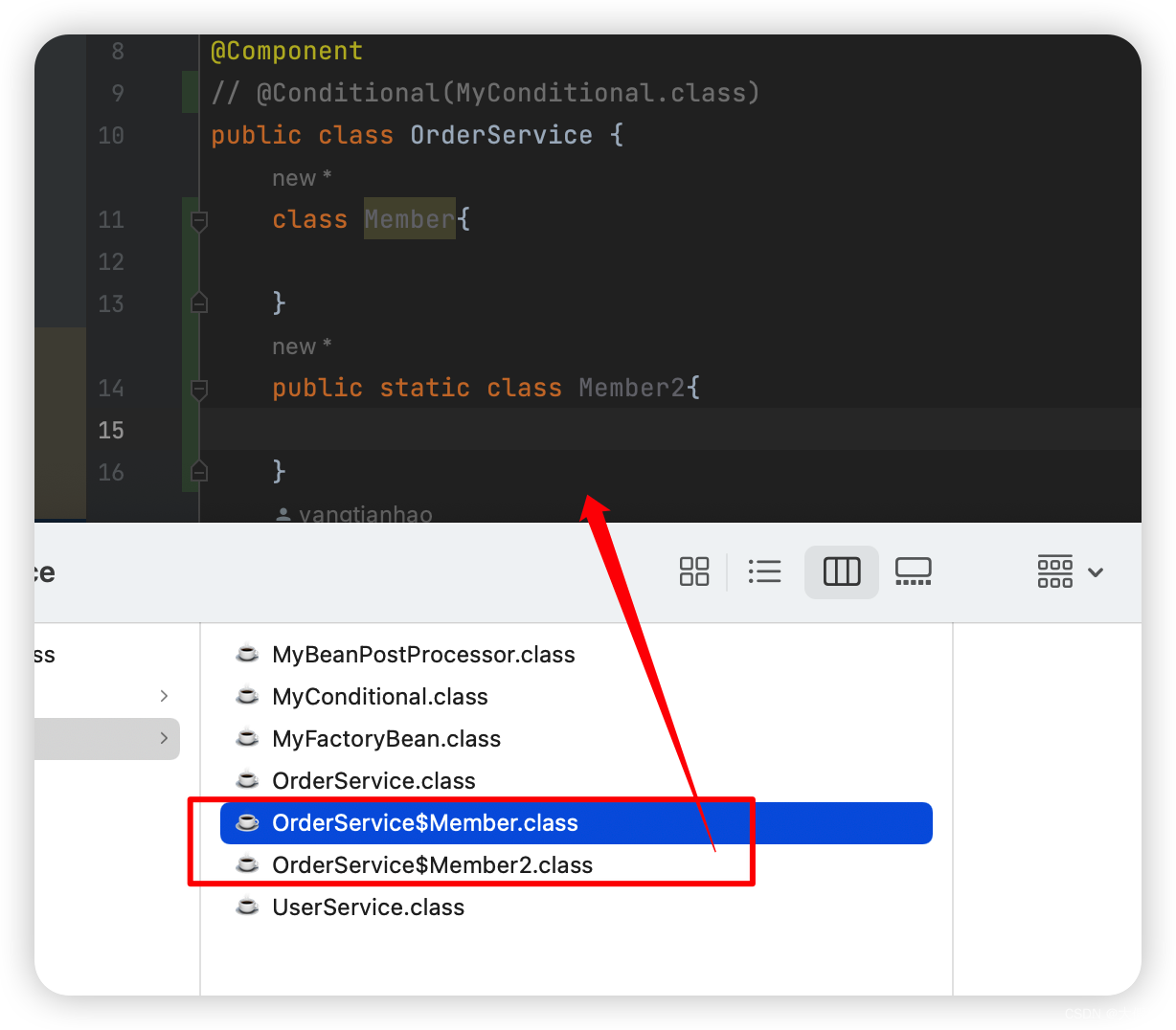
-
isConcrete:是否是具体的,即不是接口、也不是抽象类
-
isAbstract:是否是抽象类
-
hasAnnotatedMethods(Lookup.class.getName()):判断是否有@LookUp注解
这里提一下LookUp注解有什么用:
@Component
@Scope("prototype")//多例
public class User {}@Component
public class OrderService {@Autowiredprivate User user;public void test() {System.out.println(user);}}public static void main(String[] args) throws IOException {AnnotationConfigApplicationContext context = new AnnotationConfigApplicationContext(AppConfig.class);((OrderService)context.getBean("orderService")).test();((OrderService)context.getBean("orderService")).test();}
这个Demo,User虽然是多例的,但是OrderService是单例,只会创建一次,所以只会注入一次,user对象是同一个:
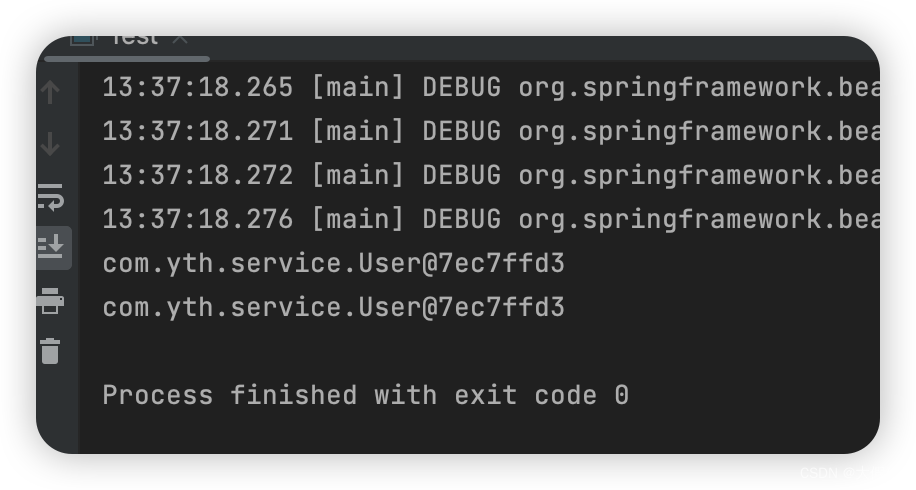
但是如果我希望每调一次test,user拿到的都是新new的,就要用到@LookUp注解
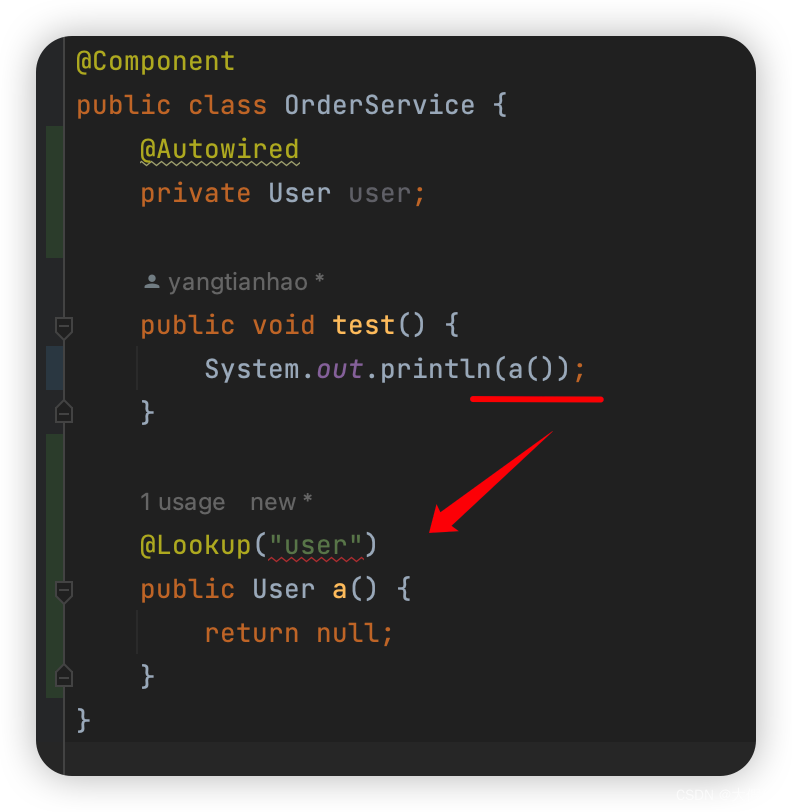
1.4 componentsIndex是干啥的?
index,索引,加速用的?确实。

背景:项目里有很多类需要被Spring扫描,按照正常逻辑Spring可能需要扫描很久。
如果想要提高扫描性能,Spring提供了一个解决方案:
- 直接在一个文件里面配置,告诉Spring当前项目里我们有哪些Component,Spring就不用自己扫描了,直接读文件。
操作:
在resources -> META-INF 下创建spring.components文件
直接定义当前项目里哪些类是Component
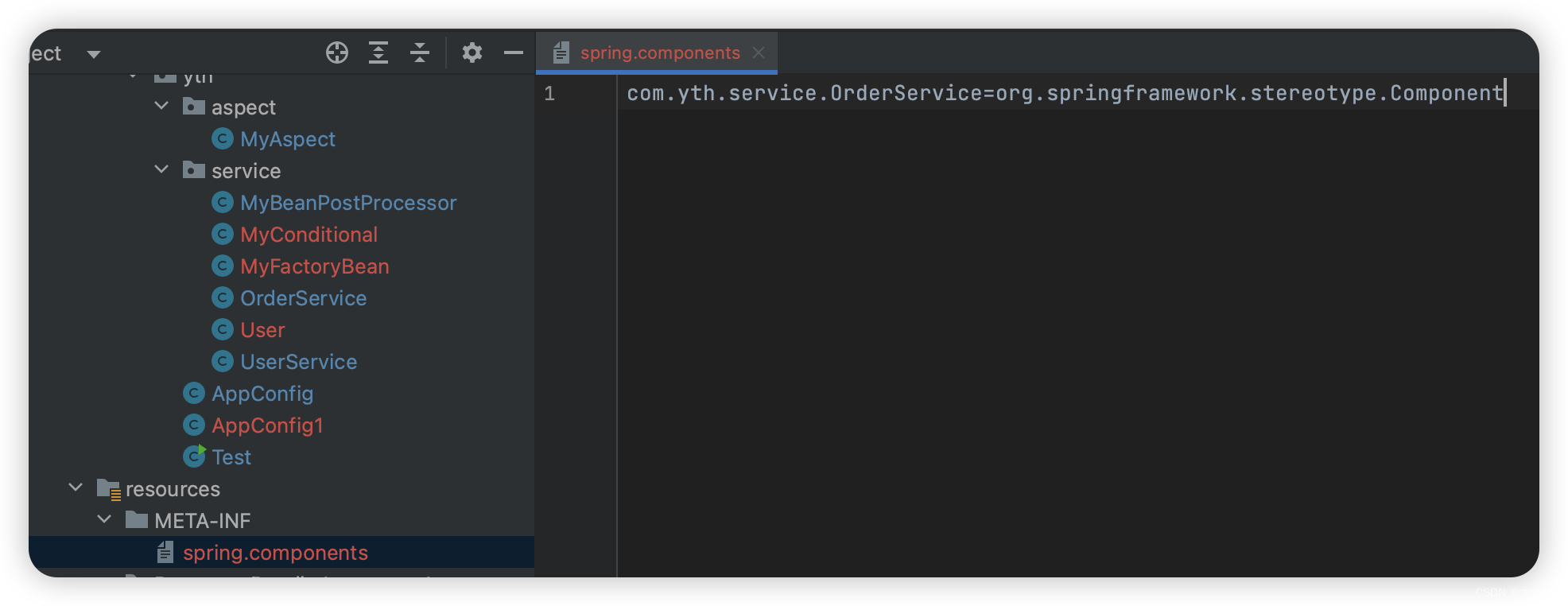
当你配置了这个文件以后,这个配置文件你就可以理解为就是这个componentsIndex
private Set<BeanDefinition> addCandidateComponentsFromIndex(CandidateComponentsIndex index, String basePackage) {Set<BeanDefinition> candidates = new LinkedHashSet<>();try {Set<String> types = new HashSet<>();//遍历过滤器for (TypeFilter filter : this.includeFilters) {//过滤器对应的"索引类型"String stereotype = extractStereotype(filter);if (stereotype == null) {throw new IllegalArgumentException("Failed to extract stereotype from " + filter);}//主要看这types.addAll(index.getCandidateTypes(basePackage, stereotype));}boolean traceEnabled = logger.isTraceEnabled();boolean debugEnabled = logger.isDebugEnabled();//这里后面的逻辑和正常扫描是一样的for (String type : types) {...}}catch (IOException ex) {...}return candidates;
}
org.springframework.context.index.CandidateComponentsIndex#getCandidateTypes
public Set<String> getCandidateTypes(String basePackage, String stereotype) {//这里index其实就是spring.components文件的内容// 文件里左边是类型,右边是stereotype,可以理解为“索引类型”List<Entry> candidates = this.index.get(stereotype);if (candidates != null) {return candidates.parallelStream()//匹配包路径.filter(t -> t.match(basePackage))//返回type,就是类名.map(t -> t.type).collect(Collectors.toSet());}return Collections.emptySet();
}
即配置了spring.components文件,Spring就不会真的扫描了,直接从spring.components文件里找当前所能匹配的Bean。
2. 生成Bean的名字
org.springframework.beans.factory.support.BeanNameGenerator#generateBeanName
默认实现:
org.springframework.context.annotation.AnnotationBeanNameGenerator#generateBeanName
public String generateBeanName(BeanDefinition definition, BeanDefinitionRegistry registry) {if (definition instanceof AnnotatedBeanDefinition) {//获取注解@Component value属性所指定的BeanNameString beanName = determineBeanNameFromAnnotation((AnnotatedBeanDefinition) definition);//有可能没配,返回空if (StringUtils.hasText(beanName)) {// Explicit bean name found.return beanName;}}// Fallback: generate a unique default bean name.return buildDefaultBeanName(definition, registry);
}//默认的BeanName,核心方法就是Introspector.decapitalize(JDK提供的)
protected String buildDefaultBeanName(BeanDefinition definition) {String beanClassName = definition.getBeanClassName();Assert.state(beanClassName != null, "No bean class name set");String shortClassName = ClassUtils.getShortName(beanClassName);//前两个字母都是大写直接返回了,否则首字母小写return Introspector.decapitalize(shortClassName);
}
默认beanName:前两个字母都是大写直接返回,否则首字母小写
3. 给BeanDefinition设置默认值
org.springframework.context.annotation.ClassPathBeanDefinitionScanner#postProcessBeanDefinition
protected void postProcessBeanDefinition(AbstractBeanDefinition beanDefinition, String beanName) {beanDefinition.applyDefaults(this.beanDefinitionDefaults);if (this.autowireCandidatePatterns != null) {beanDefinition.setAutowireCandidate(PatternMatchUtils.simpleMatch(this.autowireCandidatePatterns, beanName));}
}
org.springframework.beans.factory.support.AbstractBeanDefinition#applyDefaults
public void applyDefaults(BeanDefinitionDefaults defaults) {Boolean lazyInit = defaults.getLazyInit();if (lazyInit != null) {setLazyInit(lazyInit);}setAutowireMode(defaults.getAutowireMode());setDependencyCheck(defaults.getDependencyCheck());setInitMethodName(defaults.getInitMethodName());setEnforceInitMethod(false);setDestroyMethodName(defaults.getDestroyMethodName());setEnforceDestroyMethod(false);
}
4. 解析注解给BeanDefinition赋值
org.springframework.context.annotation.AnnotationConfigUtils#processCommonDefinitionAnnotations(org.springframework.beans.factory.annotation.AnnotatedBeanDefinition)
public static void processCommonDefinitionAnnotations(AnnotatedBeanDefinition abd) {processCommonDefinitionAnnotations(abd, abd.getMetadata());
}static void processCommonDefinitionAnnotations(AnnotatedBeanDefinition abd, AnnotatedTypeMetadata metadata) {AnnotationAttributes lazy = attributesFor(metadata, Lazy.class);if (lazy != null) {abd.setLazyInit(lazy.getBoolean("value"));}else if (abd.getMetadata() != metadata) {lazy = attributesFor(abd.getMetadata(), Lazy.class);if (lazy != null) {abd.setLazyInit(lazy.getBoolean("value"));}}if (metadata.isAnnotated(Primary.class.getName())) {abd.setPrimary(true);}AnnotationAttributes dependsOn = attributesFor(metadata, DependsOn.class);if (dependsOn != null) {abd.setDependsOn(dependsOn.getStringArray("value"));}AnnotationAttributes role = attributesFor(metadata, Role.class);if (role != null) {abd.setRole(role.getNumber("value").intValue());}AnnotationAttributes description = attributesFor(metadata, Description.class);if (description != null) {abd.setDescription(description.getString("value"));}
}
5. 检查Spring容器中是否已经存在该beanName
org.springframework.context.annotation.ClassPathBeanDefinitionScanner#checkCandidate
protected boolean checkCandidate(String beanName, BeanDefinition beanDefinition) throws IllegalStateException {if (!this.registry.containsBeanDefinition(beanName)) {return true;}BeanDefinition existingDef = this.registry.getBeanDefinition(beanName);BeanDefinition originatingDef = existingDef.getOriginatingBeanDefinition();if (originatingDef != null) {existingDef = originatingDef;}//是否可兼容,如果兼容返回false表示不会重新注册到Spring容器中if (isCompatible(beanDefinition, existingDef)) {return false;}//如果冲突则会抛出异常throw new ConflictingBeanDefinitionException("Annotation-specified bean name '" + beanName +"' for bean class [" + beanDefinition.getBeanClassName() + "] conflicts with existing, " +"non-compatible bean definition of same name and class [" + existingDef.getBeanClassName() + "]");
}
大部分情况如果容器里已经有,则直接抛异常,除非“兼容”的情况,但也不会再注册
protected boolean isCompatible(BeanDefinition newDefinition, BeanDefinition existingDefinition) {//主要针对扫描的情况!!!// 判断BeanDefinition的source是否相同、或者BeanDefinition本身是否相同return (!(existingDefinition instanceof ScannedGenericBeanDefinition) || // explicitly registered overriding bean(newDefinition.getSource() != null && newDefinition.getSource().equals(existingDefinition.getSource())) || // scanned same file twicenewDefinition.equals(existingDefinition)); // scanned equivalent class twice
}
主要针对扫描的情况!!!(ScannedGenericBeanDefinition是通过扫描生成的BeanDefinition)
那么什么情况下会出现这种情况呢?举个例子:
public static void main(String[] args) throws IOException {AnnotationConfigApplicationContext context = new AnnotationConfigApplicationContext();context.register(AppConfig.class);context.register(AppConfig1.class);context.refresh();((OrderService)context.getBean("orderService")).test();
}@ComponentScan("com.yth")
public class AppConfig {}@ComponentScan("com.yth")
public class AppConfig1 {}
这种情况下,Spring会去扫描两次,所以肯定会扫描到重复的class,于是就存在可兼容的BeanDefinition
6. 注册
org.springframework.context.annotation.ClassPathBeanDefinitionScanner#registerBeanDefinition
protected void registerBeanDefinition(BeanDefinitionHolder definitionHolder, BeanDefinitionRegistry registry) {BeanDefinitionReaderUtils.registerBeanDefinition(definitionHolder, registry);
}
org.springframework.beans.factory.support.BeanDefinitionReaderUtils#registerBeanDefinition
public static void registerBeanDefinition(BeanDefinitionHolder definitionHolder, BeanDefinitionRegistry registry)throws BeanDefinitionStoreException {// Register bean definition under primary name.String beanName = definitionHolder.getBeanName();// 我们知道registry具体实现类就是DefaultListableBeanFactoryregistry.registerBeanDefinition(beanName, definitionHolder.getBeanDefinition());// Register aliases for bean name, if any.String[] aliases = definitionHolder.getAliases();if (aliases != null) {for (String alias : aliases) {registry.registerAlias(beanName, alias);}}
}
我们知道registry具体实现类就是DefaultListableBeanFactory,注册到beanDefinitionMap:
org.springframework.beans.factory.support.DefaultListableBeanFactory#registerBeanDefinition
public void registerBeanDefinition(String beanName, BeanDefinition beanDefinition)throws BeanDefinitionStoreException {Assert.hasText(beanName, "Bean name must not be empty");Assert.notNull(beanDefinition, "BeanDefinition must not be null");if (beanDefinition instanceof AbstractBeanDefinition) {...}BeanDefinition existingDefinition = this.beanDefinitionMap.get(beanName);if (existingDefinition != null) {...}else {if (hasBeanCreationStarted()) {...}else {// Still in startup registration phase// 注册到beanDefinitionMapthis.beanDefinitionMap.put(beanName, beanDefinition);// 单独注册了一下Bean的名字this.beanDefinitionNames.add(beanName);removeManualSingletonName(beanName);}this.frozenBeanDefinitionNames = null;}if (existingDefinition != null || containsSingleton(beanName)) {...}else if (isConfigurationFrozen()) {...}
}
总结
Spring扫描底层流程:
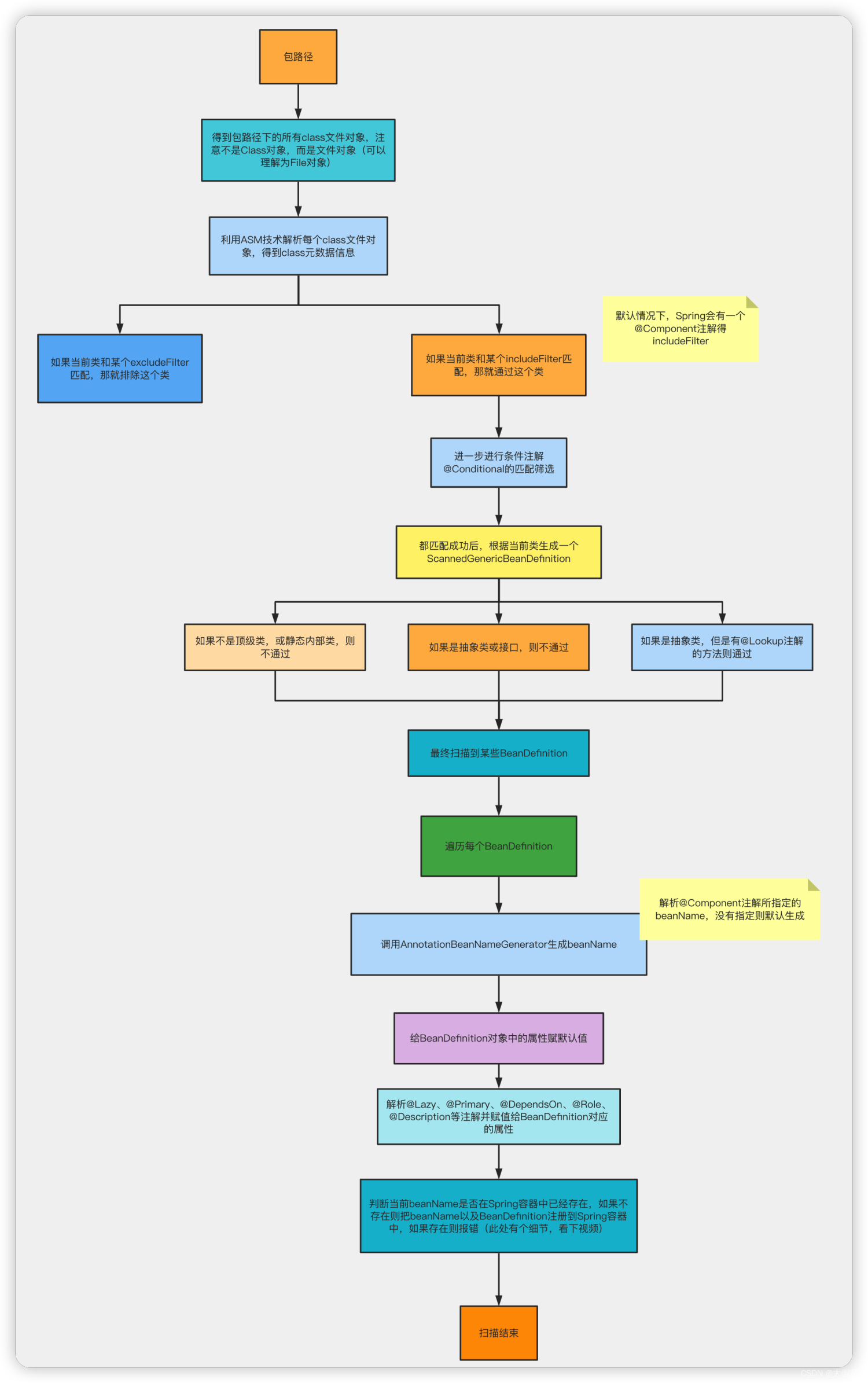
- 首先,通过ResourcePatternResolver获得指定包路径下的所有
.class文件(Spring源码中将此文件包装成了Resource对象) - 遍历每个Resource对象
- 利用MetadataReaderFactory解析Resource对象得到MetadataReader(在Spring源码中MetadataReaderFactory具体的实现类为CachingMetadataReaderFactory,MetadataReader的具体实现类为SimpleMetadataReader)
- 利用MetadataReader进行excludeFilters和includeFilters,以及条件注解@Conditional的筛选(条件注解并不难理解:某个类上是否存在@Conditional注解,如果存在则调用注解中所指定的类的match方法进行匹配,匹配成功则通过筛选,匹配失败则pass掉。)
- 筛选通过后,基于metadataReader生成ScannedGenericBeanDefinition
- 再基于metadataReader判断是不是对应的类是不是接口或抽象类
- 如果筛选通过,那么就表示扫描到了一个Bean,将ScannedGenericBeanDefinition加入结果集
MetadataReader表示类的元数据读取器,主要包含了一个AnnotationMetadata,功能有
- 获取类的名字、
- 获取父类的名字
- 获取所实现的所有接口名
- 获取所有内部类的名字
- 判断是不是抽象类
- 判断是不是接口
- 判断是不是一个注解
- 获取拥有某个注解的方法集合
- 获取类上添加的所有注解信息
- 获取类上添加的所有注解类型集合
值得注意的是,CachingMetadataReaderFactory解析某个.class文件得到MetadataReader对象是利用的ASM技术,并没有加载这个类到JVM。并且,最终得到的ScannedGenericBeanDefinition对象,beanClass属性存储的是当前类的名字,而不是class对象。(beanClass属性的类型是Object,它即可以存储类的名字,也可以存储class对象)
最后,上面是说的通过扫描得到BeanDefinition对象,我们还可以通过直接定义BeanDefinition,或解析spring.xml文件的,或者@Bean注解得到BeanDefinition对象。(后续章节会分析@Bean注解是怎么生成BeanDefinition的)。