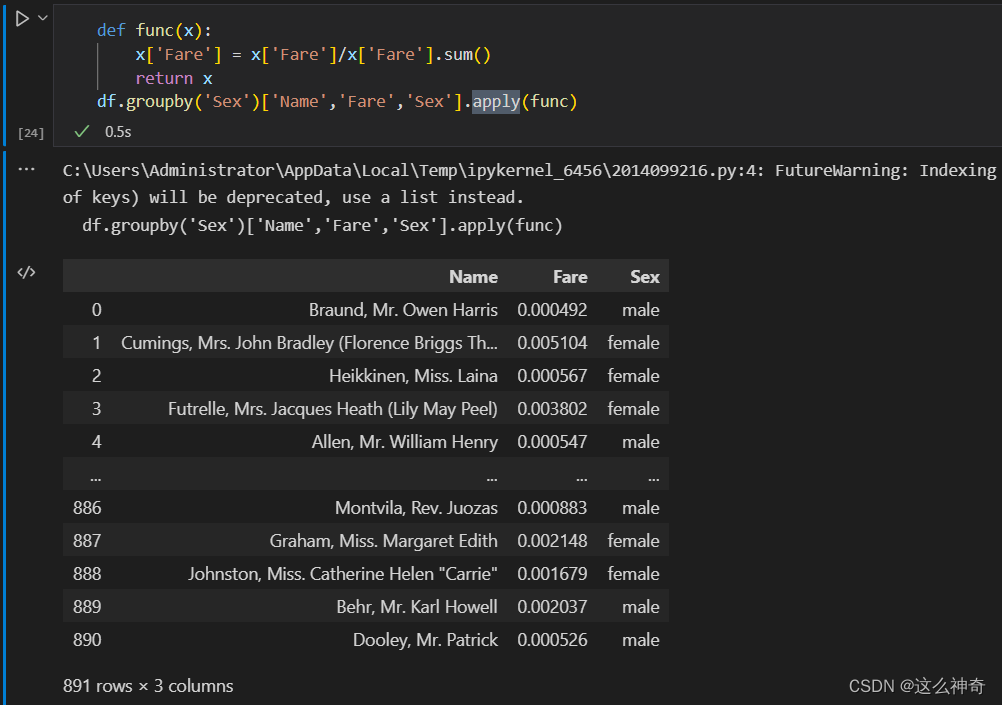
下面,我们将研究误差反向传播法。不过在此之前,作为准备工作,我们先来介绍一下计算图的相关内容。计算图是计算过程的图形表示。所示为计算图的一个例子

计算图通过节点和箭头来表示。这里,“+”表示加法,变量x和y写在各自的箭头上。像这样,在计算图中,用节点表示计算,处理结果有序(本例中是从左到右)流动。这就是计算图的正向传播。
使用计算图,可以直观地把握计算过程。另外,这样也可以直观地求梯度。这里重要的是,梯度沿与正向传播相反的方向传播,这个反方向的传播称为反向传播。
这里我想先说明一下反向传播的全貌。虽然我们处理的是z=x+y这一计算,但是在该计算的前后,还存在其他的“某种计算”。另外,假设最终输出的是标量L(在神经网络的学习阶段,计算图的最终输出是损失,它是一个标量)。

我们的目标是求L关于各个变量的导数(梯度)。这样一来,计算图的反向传播就可以绘制成图。

反向传播用蓝色的粗箭头表示,在箭头的下方标注传播的值。此时,传播的值是指最终的输出L关于各个变量的导数。在这个例子中,关于z的导数是,关于x和y的导数分别是
,
,接着,该链式法则出场了。根据刚才复习的链式法则,反向传播中流动的导数的值是根据从上游(输出侧)传来的导数和各个运算节点的局部导数之积求得的。因此,在上面的例子中,


这里,我们来处理z=x+y这个基于加法节点的运算。

像这样,计算图直观地表示了计算过程。另外,通过观察反向传播的梯度的流动,可以帮助我们理解反向传播的推导过程。
在构成计算图的运算节点中,除了这里见到的加法节点之外,还有很多其他的运算节点。下面,我们将介绍几个典型的运算节点。
1. 1 乘法节点
乘法节点是z=x×y这样的计算。此时,导数可以分别求出,即和
。因此,如下图所示,乘法节点的反向传播会将“上游传来的梯度”乘以“将正向传播时的输入替换后的值”。

另外,在目前为止的加法节点和乘法节点的介绍中,流过节点的数据都是“单变量”。但是,不仅限于单变量,也可以是多变量(向量、矩阵或张量)。当张量流过加法节点(或者乘法节点)时,只需独立计算张量中的各个元素。也就是说,在这种情况下,张量的各个元素独立于其他元素进行对应元素的运算。
1.2 分支节点
分支节点是有分支的节点

严格来说,分支节点并没有节点,只有两根分开的线。此时,相同的值被复制并分叉。因此,分支节点也称为复制节点。如图,它的反向传播是上游传来的梯度之和。
1.3 Repeat节点
分支节点有两个分支,但也可以扩展为N个分支(副本),这里称为Repeat节点。现在,我们尝试用计算图绘制一个Repeat节点。

这个例子中将长度为D的数组复制了N份。因为这个Repeat节点可以视为N个分支节点,所以它的反向传播可以通过N个梯度的总和求出,如下所示。
import numpy as np
D , N = 8 , 7
x = np.random.randn(1 , D) # 输入
y = np.repeat(x , N , axis=0) # 正向传播
dy = np.random.randn(N , D) # 假设的梯度
dx = np.sum(dy , axis=0 , keepdims=True) # 反向传播这里通过np.repeat()方法进行元素的复制。上面的例子中将复制N次数组x。通过指定axis,可以指定沿哪个轴复制。因为反向传播时要计算总和,所以使用NumPy的sum()方法。此时,通过指定axis来指定对哪个轴求和。另外,通过指定keepdims=True,可以维持二维数组的维数。在上面的例子中,当keepdims=True时,np.sum()的结果的形状是(1, D);当keepdims=False时,形状是(D,)
1.4 Sum节点
Sum节点是通用的加法节点。这里考虑对一个N×D的数组沿第0个轴求和。此时,Sum节点的正向传播和反向传播如图1-22所示。

如图所示,Sum节点的反向传播将上游传来的梯度分配到所有箭头上。这是加法节点的反向传播的自然扩展。下面,和Repeat节点一样,我们也来展示一下Sum节点的实现示例,如下所示。
D,N=8,7
x=np.random.randint(10,size=(8,7))
y=np.sum(x,axis=0,keepdims=True)
dy=np.random.randint(10,size=(1,7))
dx=np.repeat(dy,N,axis=0)如上所示,Sum节点的正向传播通过np.sum()方法实现,反向传播通过np.repeat()方法实现。有趣的是,Sum节点和Repeat节点存在逆向关系。所谓逆向关系,是指Sum节点的正向传播相当于Repeat节点的反向传播,Sum节点的反向传播相当于Repeat节点的正向传播。
本书将矩阵乘积称为MatMul节点。MatMul是Matrix Multiply的缩写。因为MatMul节点的反向传播稍微有些复杂,所以这里我们先进行一般性的介绍,再进行直观的解释。
1.5 MatMul节点
为了解释MatMul节点,我们来考虑y=xW这个计算。这里,x、W、y的形状分别是1×D、D×H、1×H。

此时,可以按如下方式求得关于x的第i个元素的导数。

式表示变化程度,即当
发生微小的变化时,L会有多大程度的变化。如果此时改变xi,则向量y的所有元素都会发生变化。另外,因为y的各个元素会发生变化,所以最终L也会发生变化。因此,从
到L的链式法则的路径有多个,它们的和是
。

从这个关系可以导出下式

` 矩阵形状的演变是正确的。由此,可以确认式的计算是正确的。然后,我们可以反过来利用它(为了保持形状合规)来推导出反向传播的数学式(及其实现)。为了说明这个方法,我们再次考虑矩阵乘积的计算y=xW。不过,这次考虑mini-batch处理,假设x中保存了N笔数据。此时,x、W、y的形状分别是N×D、D×H、N×H,反向传播的计算图如图所示

class MatMul:def __init__(self, W):self.params = [W]self.grads = [np.zeros_like(W)]self.x = Nonedef forward(self, x):W, = self.paramsout = np.dot(x, W)self.x = xreturn outdef backward(self, dout):W, = self.paramsdx = np.dot(dout, W.T)dW = np.dot(self.x.T, dout)self.grads[0][...] = dWreturn dx和省略号一样,这里也可以进行基于grads[0] = dW的赋值。不同的是,在使用省略号的情况下会覆盖掉NumPy数组。这是浅复制(shallow copy)和深复制(deep copy)的差异。grads[0] = dW的赋值相当于浅复制,grads[0][...] = dW的覆盖相当于深复制。
省略号的话题稍微有些复杂,我们举个例子来说明。假设有a和b两个NumPy数组。
import numpy as np
a = np.array([1,2,3])
b = np.array([4,5,6])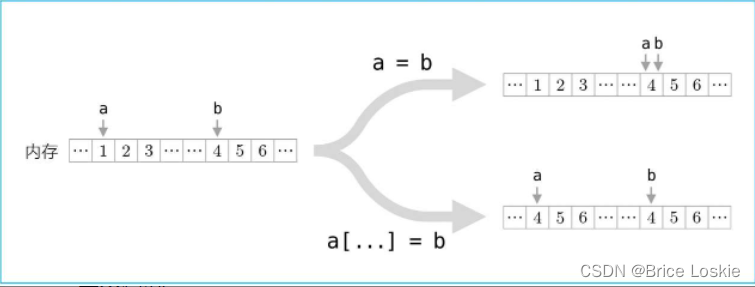
如图1-27所示,在a = b的情况下,a指向的内存地址和b一样。由于实际的数据(4,5,6)没有被复制,所以这可以说是浅复制。而在a[...] = b时,a的内存地址保持不变,b的元素被复制到a指向的内存上。这时,因为实际的数据被复制了,所以称为深复制。
由此可知,使用省略号可以固定变量的内存地址(在上面的例子中,a的地址是固定的)。通过固定这个内存地址,实例变量grads的处理会变简单。
在grads列表中保存各个参数的梯度。此时,grads列表中的各个元素是NumPy数组,仅在生成层时生成一次。然后,使用省略号,在不改变NumPy数组的内存地址的情况下覆盖数据。这样一来,将梯度汇总在一起的工作就只需要在开始时进行一次即可。