作为一个NLPer,bert应该是会经常用到的一个模型了。但bert可调参数很多,一些技巧也很多,比如加上weight-decay, layer初始化、冻结参数、只优化部分层参数等等,方法太多了,每次都会纠结该怎么样去finetune,才能让bert训练的又快又好呢,有没有可能形成一个又快又好又准的大体方向的准则呢。于是,就基于这个研究、实践了一番,总结了这篇文章。
1.使用误差修正,训练收敛变快,效果变好。
这个方法主要来自于这篇文章Revisiting Few-sample BERT Fine-tuning。文章中提到,原优化器adam它的数学公式中是带bias-correct,而在官方的bert模型中,实现的优化器bertadam是不带bias-correction的。

在代码上, 也就是这个BertAdam的实现,是不带bias-correction。不过这个pytorch_pretrained_bert这个package是抱抱脸2019年的推出的开发代码了,已经废弃了。
from pytorch_pretrained_bert.optimization import BertAdam
optimizer = BertAdam(optimizer_grouped_parameters,lr=2e-05,warmup= 0.1 ,t_total= 2000)现在的transformers的已经更正过这个问题了,修改的更加灵活了。
import transformers
optimizer = transformers.AdamW(model_parameters, lr=lr, correct_bias=True)于是,俺砖头在THNews数据上做文本分类任务试验了一下有无correct_bias的情况,影响不大,效果还略微有降,但paper中讨论的是小数据量场景,可能存在些场景适应性问题,大家可以自行尝试。
2.使用权重初始化。
用bert做finetune时,通常会直接使用bert的预训练模型权重,去初始化下游任务中的模型参数,这样做是为了充分利用bert在预训练过程中学习到的语言知识,将其能够迁移到下游任务的学习当中。
以bert-base为例,由12层的transformer block堆叠而成。那到底是直接保留bert中预训练的模型参数,还是保留部分,或是保留哪些层的模型参数对下游任务更友好呢?其实有一些论文讨论过这个这个问题,总结起来就是,底部的层也就是靠近输入的层,学到的是通用语义信息,比如词性、词法等语言学知识,而靠近顶部的层也就是靠近输出的层,会倾向于学习到接近下游任务的知识,拿预训练任务来说,就是masked word prediction、next sentence prediction任务的知识。
所以借此经验,finetune时,可以保留底部的bert权重,对于顶部层的权重(1~6 layers)可以重新进行随机初始化,让这部分参数在你的 任务上进行重新学习。这部分实验,这篇文章Revisiting Few-sample BERT Fine-tuning也帮大家实践了,采取重新初始化部分层参数的方法,在一部分任务上,指标获得了一些明显提升。
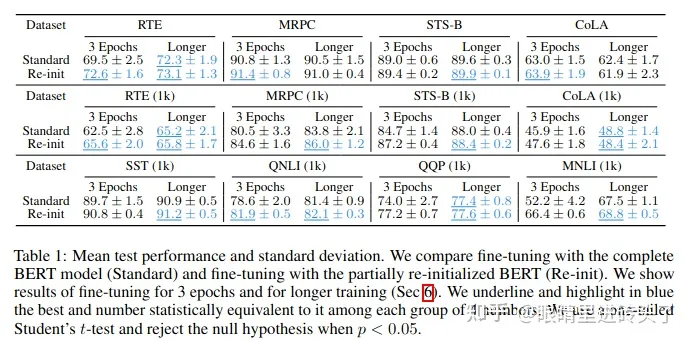
于是,砖头也实践了一下文本分类任务,在训练上能明显看到收敛变快,但效果上变化不大,这些实验代码都放在文章末尾的仓库了,大家感兴趣的可以研究交流。
3.weight-decay (L2正则化)
由于在bert官方的代码中对于bias项、LayerNorm.bias、LayerNorm.weight项是免于正则化的。因此经常在bert的训练中会采用与bert原训练方式一致的做法,也就是下面这段代码。
param_optimizer = list(multi_classification_model.named_parameters())
no_decay = ['bias', 'LayerNorm.bias', 'LayerNorm.weight']
optimizer_grouped_parameters = [{'params': [p for n, p in param_optimizerif not any(nd in n for nd in no_decay)], 'weight_decay': 0.01},{'params': [p for n, p in param_optimizerif any(nd in n for nd in no_decay)], 'weight_decay': 0.0}
]
optimizer = transformers.AdamW(optimizer_grouped_parameters, lr=config.lr, correct_bias=not config.bertadam)实践出真知,砖头在文本分类的任务上试验了一下,加与不加,这个差别没什么影响,大家也可以在训练的时候对比试一试,代码代价很小。
4.冻结部分层参数(Frozen parameter)
冻结参数经常在一些大模型的训练中使用,主要是对于一些参数较多的模型,冻结部分参数在不太影响结果精度的情况下,可以减少参数的迭代计算,加快训练速度。在bert中fine-tune中也常用到这种措施,一般会冻结的是bert前几层,因为有研究bert结构的论文表明,bert前面几层冻结是不太影响模型最终结果表现的。这个就有点类似与图像类的深度网络,模型前面层学习的都是一些通用且广泛的知识(比如一些基础的线、点形状类似),这类知识都差不多。这里关于冻结参数主要有这么两种方法。
# 方法1: 设置requires_grad = False
for param in model.parameters():param.requires_grad = False
# 方法2: torch.no_grad()
class net(nn.Module):def __init__():......def forward(self.x):with torch.no_grad(): # no_grad下参数不会迭代 x = self.layer(x)......x = self.fc(x)return xtrain.py
# code reference: https://github.com/asappresearch/revisit-bert-finetuningimport os
import sys
import time
import argparse
import logging
import numpy as np
from tqdm import tqdm
from sklearn import metricsimport torch
import torch.nn as nn
import torch.nn.functional as F
from torch.utils.data import Dataset, DataLoaderimport transformers
from transformers import BertModel, AlbertModel, BertConfig, BertTokenizerfrom dataloader import TextDataset, BatchTextCall
from model import MultiClass
from utils import load_configlogging.basicConfig(format='%(asctime)s - %(levelname)s - %(name)s - %(filename)s:%(lineno)d:%(message)s',datefmt='%m/%d/%Y %H:%M:%S',level=logging.INFO)
logger = logging.getLogger(__name__)def choose_bert_type(path, bert_type="tiny_albert"):"""choose bert type for chinese, tiny_albert or macbert(bert)return: tokenizer, model"""if bert_type == "albert":model_config = BertConfig.from_pretrained(path)model = AlbertModel.from_pretrained(path, config=model_config)elif bert_type == "bert" or bert_type == "roberta":model_config = BertConfig.from_pretrained(path)model = BertModel.from_pretrained(path, config=model_config)else:model_config, model = None, Noneprint("ERROR, not choose model!")return model_config, modeldef evaluation(model, test_dataloader, loss_func, label2ind_dict, save_path, valid_or_test="test"):# model.load_state_dict(torch.load(save_path))model.eval()total_loss = 0predict_all = np.array([], dtype=int)labels_all = np.array([], dtype=int)for ind, (token, segment, mask, label) in enumerate(test_dataloader):token = token.cuda()segment = segment.cuda()mask = mask.cuda()label = label.cuda()out = model(token, segment, mask)loss = loss_func(out, label)total_loss += loss.detach().item()label = label.data.cpu().numpy()predic = torch.max(out.data, 1)[1].cpu().numpy()labels_all = np.append(labels_all, label)predict_all = np.append(predict_all, predic)acc = metrics.accuracy_score(labels_all, predict_all)if valid_or_test == "test":report = metrics.classification_report(labels_all, predict_all, target_names=label2ind_dict.keys(), digits=4)confusion = metrics.confusion_matrix(labels_all, predict_all)return acc, total_loss / len(test_dataloader), report, confusionreturn acc, total_loss / len(test_dataloader)def train(config):label2ind_dict = {'体育': 0, '娱乐': 1, '家居': 2, '房产': 3, '教育': 4, '时尚': 5, '时政': 6, '游戏': 7, '科技': 8, '财经': 9}os.environ["CUDA_VISIBLE_DEVICES"] = config.gputorch.backends.cudnn.benchmark = True# load_data(os.path.join(data_dir, "cnews.train.txt"), label_dict)tokenizer = BertTokenizer.from_pretrained(config.pretrained_path)train_dataset_call = BatchTextCall(tokenizer, max_len=config.sent_max_len)train_dataset = TextDataset(os.path.join(config.data_dir, "train.txt"))train_dataloader = DataLoader(train_dataset, batch_size=config.batch_size, shuffle=True, num_workers=10,collate_fn=train_dataset_call)valid_dataset = TextDataset(os.path.join(config.data_dir, "dev.txt"))valid_dataloader = DataLoader(valid_dataset, batch_size=config.batch_size, shuffle=True, num_workers=10,collate_fn=train_dataset_call)test_dataset = TextDataset(os.path.join(config.data_dir, "test.txt"))test_dataloader = DataLoader(test_dataset, batch_size=64, shuffle=True, num_workers=10,collate_fn=train_dataset_call)model_config, bert_encode_model = choose_bert_type(config.pretrained_path, bert_type=config.bert_type)multi_classification_model = MultiClass(bert_encode_model, model_config,num_classes=10, pooling_type=config.pooling_type)multi_classification_model.cuda()# multi_classification_model.load_state_dict(torch.load(config.save_path))if config.weight_decay:param_optimizer = list(multi_classification_model.named_parameters())no_decay = ['bias', 'LayerNorm.bias', 'LayerNorm.weight']optimizer_grouped_parameters = [{'params': [p for n, p in param_optimizerif not any(nd in n for nd in no_decay)], 'weight_decay': 0.01},{'params': [p for n, p in param_optimizerif any(nd in n for nd in no_decay)], 'weight_decay': 0.0}]optimizer = transformers.AdamW(optimizer_grouped_parameters, lr=config.lr, correct_bias=not config.bertadam)else:optimizer = transformers.AdamW(multi_classification_model.parameters(), lr=config.lr, betas=(0.9, 0.999),eps=1e-08, weight_decay=0.01, correct_bias=not config.bertadam)num_train_optimization_steps = len(train_dataloader) * config.epochif config.warmup_proportion != 0:scheduler = transformers.get_linear_schedule_with_warmup(optimizer,int(num_train_optimization_steps * config.warmup_proportion),num_train_optimization_steps)else:scheduler = transformers.get_linear_schedule_with_warmup(optimizer,int(num_train_optimization_steps * config.warmup_proportion),num_train_optimization_steps)loss_func = F.cross_entropy# reinit pooler-layerif config.reinit_pooler:if config.bert_type in ["bert", "roberta", "albert"]:logger.info(f"reinit pooler layer of {config.bert_type}")encoder_temp = getattr(multi_classification_model, config.bert_type)encoder_temp.pooler.dense.weight.data.normal_(mean=0.0, std=encoder_temp.config.initializer_range)encoder_temp.pooler.dense.bias.data.zero_()for p in encoder_temp.pooler.parameters():p.requires_grad = Trueelse:raise NotImplementedError# reinit encoder layersif config.reinit_layers > 0:if config.bert_type in ["bert", "roberta", "albert"]:# assert config.reinit_poolerlogger.info(f"reinit layers count of {str(config.reinit_layers)}")encoder_temp = getattr(multi_classification_model, config.bert_type)for layer in encoder_temp.encoder.layer[-config.reinit_layers:]:for module in layer.modules():if isinstance(module, (nn.Linear, nn.Embedding)):module.weight.data.normal_(mean=0.0, std=encoder_temp.config.initializer_range)elif isinstance(module, nn.LayerNorm):module.bias.data.zero_()module.weight.data.fill_(1.0)if isinstance(module, nn.Linear) and module.bias is not None:module.bias.data.zero_()else:raise NotImplementedErrorif config.freeze_layer_count:logger.info(f"frozen layers count of {str(config.freeze_layer_count)}")# We freeze here the embeddings of the modelfor param in multi_classification_model.bert.embeddings.parameters():param.requires_grad = Falseif config.freeze_layer_count != -1:# if freeze_layer_count == -1, we only freeze the embedding layer# otherwise we freeze the first `freeze_layer_count` encoder layersfor layer in multi_classification_model.bert.encoder.layer[:config.freeze_layer_count]:for param in layer.parameters():param.requires_grad = Falseloss_total, top_acc = [], 0for epoch in range(config.epoch):multi_classification_model.train()start_time = time.time()tqdm_bar = tqdm(train_dataloader, desc="Training epoch{epoch}".format(epoch=epoch))for i, (token, segment, mask, label) in enumerate(tqdm_bar):token = token.cuda()segment = segment.cuda()mask = mask.cuda()label = label.cuda()multi_classification_model.zero_grad()out = multi_classification_model(token, segment, mask)loss = loss_func(out, label)loss.backward()optimizer.step()scheduler.step()optimizer.zero_grad()loss_total.append(loss.detach().item())logger.info("Epoch: %03d; loss = %.4f cost time %.4f" % (epoch, np.mean(loss_total), time.time() - start_time))acc, loss, report, confusion = evaluation(multi_classification_model,test_dataloader, loss_func, label2ind_dict,config.save_path)logger.info("Accuracy: %.4f Loss in test %.4f" % (acc, loss))if top_acc < acc:top_acc = acc# torch.save(multi_classification_model.state_dict(), config.save_path)logger.info(f"{report} \n {confusion}")time.sleep(1)if __name__ == "__main__":parser = argparse.ArgumentParser(description='bert finetune test')parser.add_argument("--data_dir", type=str, default="../data/THUCNews/news")parser.add_argument("--save_path", type=str, default="../ckpt/bert_classification")parser.add_argument("--pretrained_path", type=str, default="/data/Learn_Project/Backup_Data/bert_chinese",help="pre-train model path")parser.add_argument("--bert_type", type=str, default="bert", help="bert or albert")parser.add_argument("--gpu", type=str, default='0')parser.add_argument("--epoch", type=int, default=20)parser.add_argument("--lr", type=float, default=0.005)parser.add_argument("--warmup_proportion", type=float, default=0.1)parser.add_argument("--pooling_type", type=str, default="first-last-avg")parser.add_argument("--batch_size", type=int, default=512)parser.add_argument("--sent_max_len", type=int, default=44)parser.add_argument("--do_lower_case", type=bool, default=True,help="Set this flag true if you are using an uncased model.")parser.add_argument("--bertadam", type=int, default=0, help="If bertadam, then set correct_bias = False")parser.add_argument("--weight_decay", type=int, default=0, help="If weight_decay, set 1")parser.add_argument("--reinit_pooler", type=int, default=1, help="reinit pooler layer")parser.add_argument("--reinit_layers", type=int, default=6, help="reinit pooler layers count")parser.add_argument("--freeze_layer_count", type=int, default=6, help="freeze layers count")args = parser.parse_args()log_filename = f"test_bertadam{args.bertadam}_weight_decay{str(args.weight_decay)}" \f"_reinit_pooler{str(args.reinit_pooler)}_reinit_layers{str(args.reinit_layers)}" \f"_frozen_layers{str(args.freeze_layer_count)}_warmup_proportion{str(args.warmup_proportion)}"logger.addHandler(logging.FileHandler(os.path.join("./log", log_filename), 'w'))logger.info(args)train(args)
dataloader.py
import osimport pandas as pd
import numpy as npimport torch
from torch.utils.data import Dataset, DataLoaderfrom transformers import BertModel, AlbertModel, BertConfig, BertTokenizer
from transformers import BertForSequenceClassification, AutoModelForMaskedLMdef load_data(path):train = pd.read_csv(path, header=0, sep='\t', names=["text", "label"])print(train.shape)# valid = pd.read_csv(os.path.join(path, "cnews.val.txt"), header=None, sep='\t', names=["label", "text"])# test = pd.read_csv(os.path.join(path, "cnews.test.txt"), header=None, sep='\t', names=["label", "text"])texts = train.text.to_list()labels = train.label.map(int).to_list()# label_dic = dict(zip(train.label.unique(), range(len(train.label.unique()))))return texts, labelsclass TextDataset(Dataset):def __init__(self, filepath):super(TextDataset, self).__init__()self.train, self.label = load_data(filepath)def __len__(self):return len(self.train)def __getitem__(self, item):text = self.train[item]label = self.label[item]return text, labelclass BatchTextCall(object):"""call function for tokenizing and getting batch text"""def __init__(self, tokenizer, max_len=312):self.tokenizer = tokenizerself.max_len = max_lendef text2id(self, batch_text):return self.tokenizer(batch_text, max_length=self.max_len,truncation=True, padding='max_length', return_tensors='pt')def __call__(self, batch):batch_text = [item[0] for item in batch]batch_label = [item[1] for item in batch]source = self.text2id(batch_text)token = source.get('input_ids').squeeze(1)mask = source.get('attention_mask').squeeze(1)segment = source.get('token_type_ids').squeeze(1)label = torch.tensor(batch_label)return token, segment, mask, labelif __name__ == "__main__":data_dir = "/GitProject/Text-Classification/Chinese-Text-Classification/data/THUCNews/news_all"# pretrained_path = "/data/Learn_Project/Backup_Data/chinese-roberta-wwm-ext"pretrained_path = "/data/Learn_Project/Backup_Data/RoBERTa_zh_L12_PyTorch"label_dict = {'体育': 0, '娱乐': 1, '家居': 2, '房产': 3, '教育': 4, '时尚': 5, '时政': 6, '游戏': 7, '科技': 8, '财经': 9}# tokenizer, model = choose_bert_type(pretrained_path, bert_type="roberta")tokenizer = BertTokenizer.from_pretrained(pretrained_path)model_config = BertConfig.from_pretrained(pretrained_path)model = BertModel.from_pretrained(pretrained_path, config=model_config)# model = BertForSequenceClassification.from_pretrained(pretrained_path)# model = AutoModelForMaskedLM.from_pretrained(pretrained_path)text_dataset = TextDataset(os.path.join(data_dir, "test.txt"))text_dataset_call = BatchTextCall(tokenizer)text_dataloader = DataLoader(text_dataset, batch_size=2, shuffle=True, num_workers=2, collate_fn=text_dataset_call)for i, (token, segment, mask, label) in enumerate(text_dataloader):print(i, token, segment, mask, label)out = model(input_ids=token, attention_mask=mask, token_type_ids=segment)# loss, logits = model(token, mask, segment)[:2]print(out)print(out.last_hidden_state.shape)break
model.py
import torch
from torch import nnBertLayerNorm = torch.nn.LayerNormclass MultiClass(nn.Module):""" text processed by bert model encode and get cls vector for multi classification"""def __init__(self, bert_encode_model, model_config, num_classes=10, pooling_type='first-last-avg'):super(MultiClass, self).__init__()self.bert = bert_encode_modelself.num_classes = num_classesself.fc = nn.Linear(model_config.hidden_size, num_classes)self.pooling = pooling_typeself.dropout = nn.Dropout(model_config.hidden_dropout_prob)self.layer_norm = BertLayerNorm(model_config.hidden_size)def forward(self, batch_token, batch_segment, batch_attention_mask):out = self.bert(batch_token,attention_mask=batch_attention_mask,token_type_ids=batch_segment,output_hidden_states=True)# print(out)if self.pooling == 'cls':out = out.last_hidden_state[:, 0, :] # [batch, 768]elif self.pooling == 'pooler':out = out.pooler_output # [batch, 768]elif self.pooling == 'last-avg':last = out.last_hidden_state.transpose(1, 2) # [batch, 768, seqlen]out = torch.avg_pool1d(last, kernel_size=last.shape[-1]).squeeze(-1) # [batch, 768]elif self.pooling == 'first-last-avg':first = out.hidden_states[1].transpose(1, 2) # [batch, 768, seqlen]last = out.hidden_states[-1].transpose(1, 2) # [batch, 768, seqlen]first_avg = torch.avg_pool1d(first, kernel_size=last.shape[-1]).squeeze(-1) # [batch, 768]last_avg = torch.avg_pool1d(last, kernel_size=last.shape[-1]).squeeze(-1) # [batch, 768]avg = torch.cat((first_avg.unsqueeze(1), last_avg.unsqueeze(1)), dim=1) # [batch, 2, 768]out = torch.avg_pool1d(avg.transpose(1, 2), kernel_size=2).squeeze(-1) # [batch, 768]else:raise "should define pooling type first!"out = self.layer_norm(out)out = self.dropout(out)out_fc = self.fc(out)return out_fcif __name__ == '__main__':path = "/data/Learn_Project/Backup_Data/bert_chinese"MultiClassModel = MultiClass# MultiClassModel = BertForMultiClassificationmulti_classification_model = MultiClassModel.from_pretrained(path, num_classes=10)if hasattr(multi_classification_model, 'bert'):print("-------------------------------------------------")else:print("**********************************************")
utils.py
import yamlclass AttrDict(dict):"""Attr dict: make value private"""def __init__(self, d):self.dict = ddef __getattr__(self, attr):value = self.dict[attr]if isinstance(value, dict):return AttrDict(value)else:return valuedef __str__(self):return str(self.dict)def load_config(config_file):"""Load config file"""with open(config_file) as f:if hasattr(yaml, 'FullLoader'):config = yaml.load(f, Loader=yaml.FullLoader)else:config = yaml.load(f)print(config)return AttrDict(config)if __name__ == "__main__":import argparseparser = argparse.ArgumentParser(description='text classification')parser.add_argument("-c", "--config", type=str, default="./config.yaml")args = parser.parse_args()config = load_config(args.config)
5.warmup & lr_decay
warm_up是在bert训练中是一个经常用到的小技巧了,就是模型迭代前期用较大的lr进行warmup,后期随着迭代,用较小的lr。有一篇文章On Layer Normalization in the Transformer Architecture对此进行了些分析,总结一下就是作者发现Transformer在训练的初始阶段,输出层附近的期望梯度非常大,warmup可以避免前向FC层的不稳定的剧烈改变,所以没有warm-up的话模型优化过程就会非常不稳定。特别是深网络,batch_size较大的时候,这个影响会比较明显。
num_train_optimization_steps = len(train_dataloader) * config.epoch
optimizer = transformers.AdamW(optimizer_grouped_parameters, lr=config.lr)
scheduler = transformers.get_linear_schedule_with_warmup(optimizer,int(num_train_optimization_steps *0.1),num_train_optimization_steps)关于learning_rate衰减, 原来有写过一篇关于自适应优化器Adam还需加learning-rate decay吗?解析,在这里通过文章与实验检验,结论就是发现加了还是会有些许的提升,具体的可以看看这篇噢。
最后,看看结论
基于以上不同策略参数的实验设置,组合下来总计做了64组实验(1/0 represented used or not),其中总体结果f1介于0.9281~0.9405。总体结果来看,不同的fine-tune设置下来,对于结果的影响不是很大,最多只相差了一个多点。对于工程应用上来讲,影响不大,但大家打比赛或刷榜的时候,资源充足时可以试试。不同的策略下,收敛速度还是有相差比较大的,其中有进行一些frozen参数的,迭代计算确实速度快了许多。
最后由于64组结果太长,就不全部贴过来了。以下只贴出了其中最好或最差的前三组结果。完整的实验结果及代码,大家感兴趣的可以看这里 github.com/Chinese-Text-Classification。
| index | bertadam | weight_decay | reinit_pooler | reinit_layers | frozen_layers | warmup_proportion | result |
|---|---|---|---|---|---|---|---|
| 37 | 1 | 0 | 0 | 6 | 0 | 0.0 | 0.9287 |
| 45 | 1 | 0 | 1 | 6 | 0 | 0.0 | 0.9284 |
| 55 | 1 | 1 | 0 | 6 | 6 | 0.0 | 0.9281 |
| 35 | 1 | 0 | 0 | 0 | 6 | 0.0 | 0.9398 |
| 50 | 1 | 1 | 0 | 0 | 0 | 0.1 | 0.9405 |
| 58 | 1 | 1 | 1 | 0 | 0 | 0.1 | 0.9396 |
Bert在fine-tune时训练的5种技巧 - 知乎
bert模型的微调,如何固定住BERT预训练模型参数,只训练下游任务的模型参数? - 知乎
GitHub - shuxinyin/Chinese-Text-Classification: Chinese-Text-Classification Project including bert-classification, textCNN and so on.