1. 安装配置
- 具体的安装过程, 官网已经写的很清楚了http://doc.scrapy.org/en/latest/intro/install.html#windows
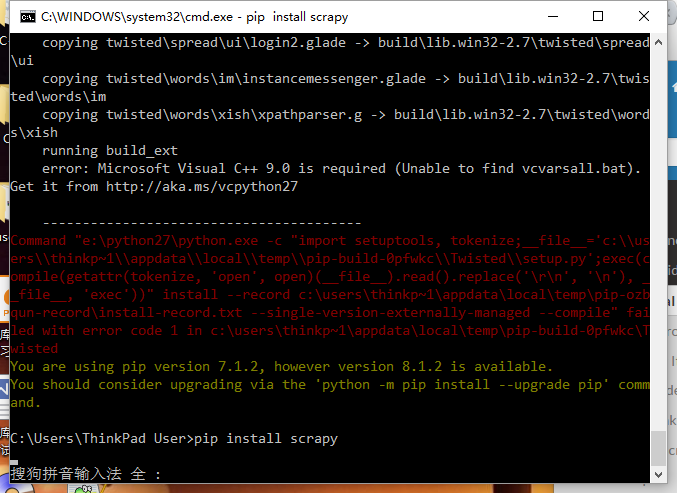
不过在实际安装过程中还是遇到了一个小问题:
ie, 缺少microsoft visual c++ 9.0 运行库,
上图中已经告诉我们了解决方法: 去到 http://aka.ms/vcpython27 下载相应文件即可。
这里直接给出下载链接
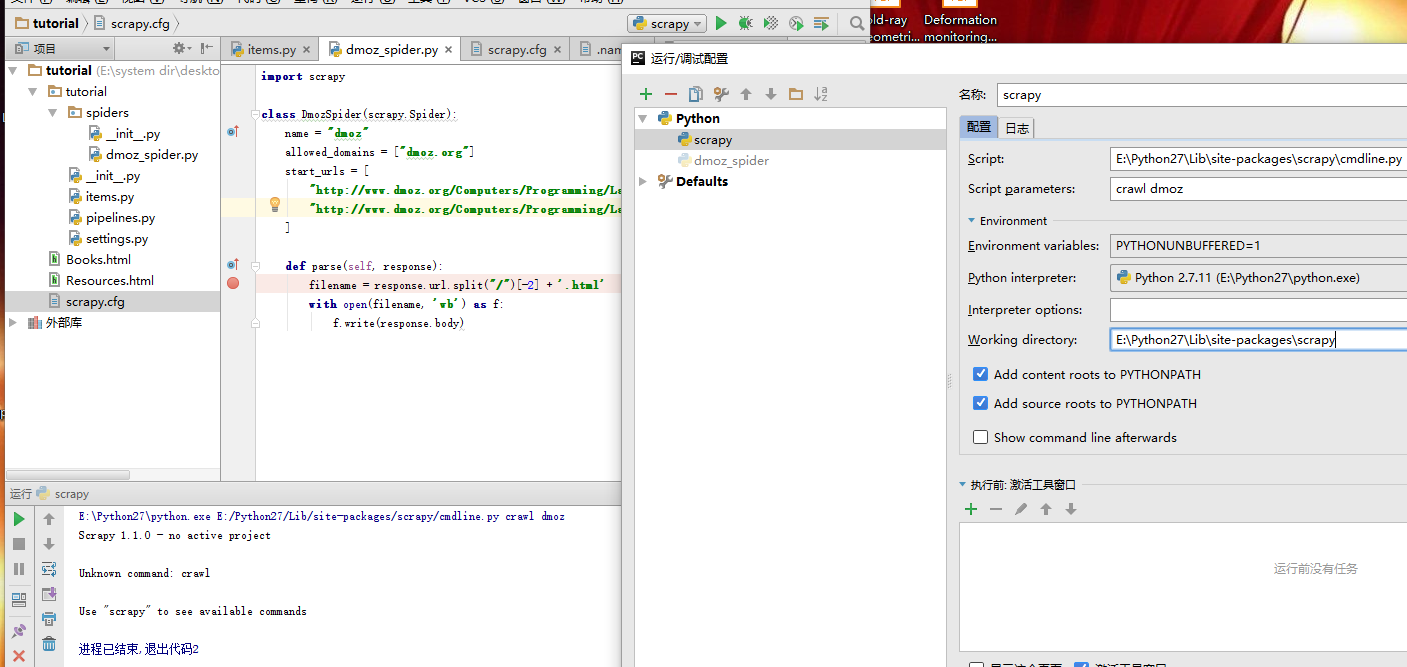
https://www.microsoft.com/en-us/download/confirmation.aspx?id=44266Scrapy运行项目时出错:Scrapy 1.0.1 – no active project,Unknown command: crawl,Use “scrapy” to see available commands
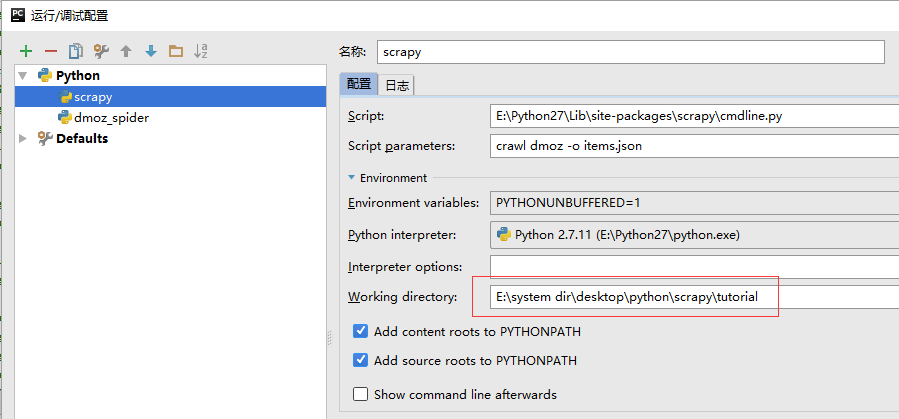
这个问题, 我们研究了很久, 终于发现, 是我们的这里的 working directory 配置有问题。 应该将这个工作路径配置到工程的最顶级路径, ie:
至此, scrapy 在pycharm中配置完成
可以参考: http://www.07net01.com/2015/08/904875.html
2. 爬取需要的信息
- 接下来的操作都是参考 http://doc.scrapy.org/en/latest/intro/tutorial.html 官网的引导完成的, 英文好的可以直接查看原文, 便于理解
新建项目
scrapy startproject tutorial并将项目文件夹用pycharm 打开
确定我们的item 结构
个人理解, 这个结构有点数据结构的意思在里面, 主要用来保存提取的信息import scrapy class DmozItem(scrapy.Item):title = scrapy.Field()link = scrapy.Field()desc = scrapy.Field()简单爬虫
这里有几个要素:- name, 标记爬虫
- start_urls 标记起始url
- parse,默认的回调函数
import scrapyclass DmozSpider(scrapy.Spider):name = "dmoz"allowed_domains = ["dmoz.org"]start_urls = ["http://www.dmoz.org/Computers/Programming/Languages/Python/Books/","http://www.dmoz.org/Computers/Programming/Languages/Python/Resources/"]def parse(self, response):filename = response.url.split("/")[-2] + '.html'with open(filename, 'wb') as f:f.write(response.body)爬虫运行
scrapy crawl dmozscrapy 自动为每个 start_urls 中的url 发起request 请求, 对得到的response 调用parse 进行处理
提取信息
这里面主要用到各种选择器: xpath, css, re, extract完成版本
从主页中提取感兴趣的url后, 再对相应的url 页面提取信息import scrapyfrom tutorial.items import DmozItemclass DmozSpider(scrapy.Spider):name = "dmoz"allowed_domains = ["dmoz.org"]start_urls = ["http://www.dmoz.org/Computers/Programming/Languages/Python/",]def parse(self, response):for href in response.css("ul.directory.dir-col > li > a::attr('href')"):url = response.urljoin(href.extract())yield scrapy.Request(url, callback=self.parse_dir_contents)def parse_dir_contents(self, response):for sel in response.xpath('//ul/li'):item = DmozItem()item['title'] = sel.xpath('a/text()').extract()item['link'] = sel.xpath('a/@href').extract()item['desc'] = sel.xpath('text()').extract()yield item存储信息
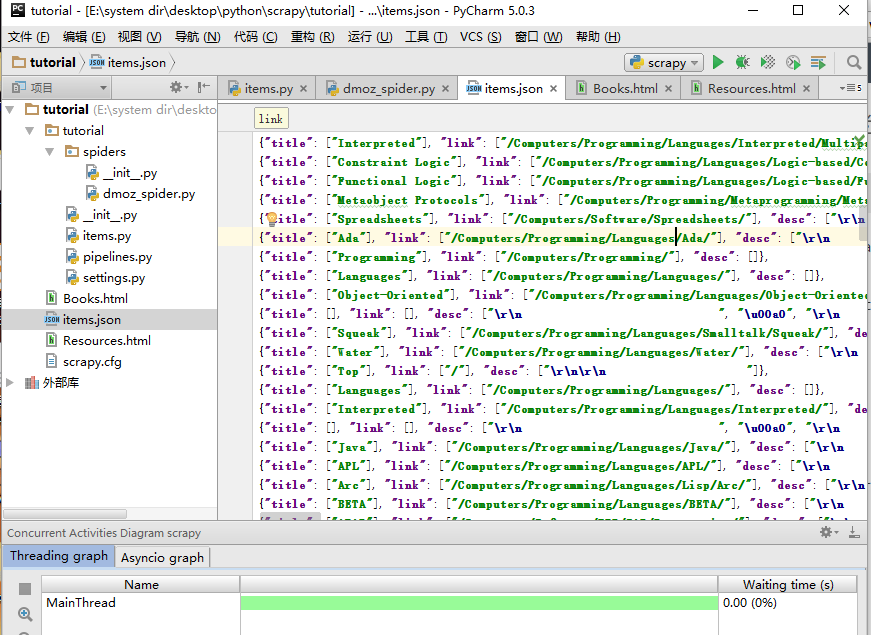
scrapy crawl dmoz -o items.json存储效果:











![[.Net Core学习一]网站发布](https://img-blog.csdnimg.cn/20190802152135263.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L2xpdXppc2hhbmc=,size_16,color_FFFFFF,t_70)