1. 前言
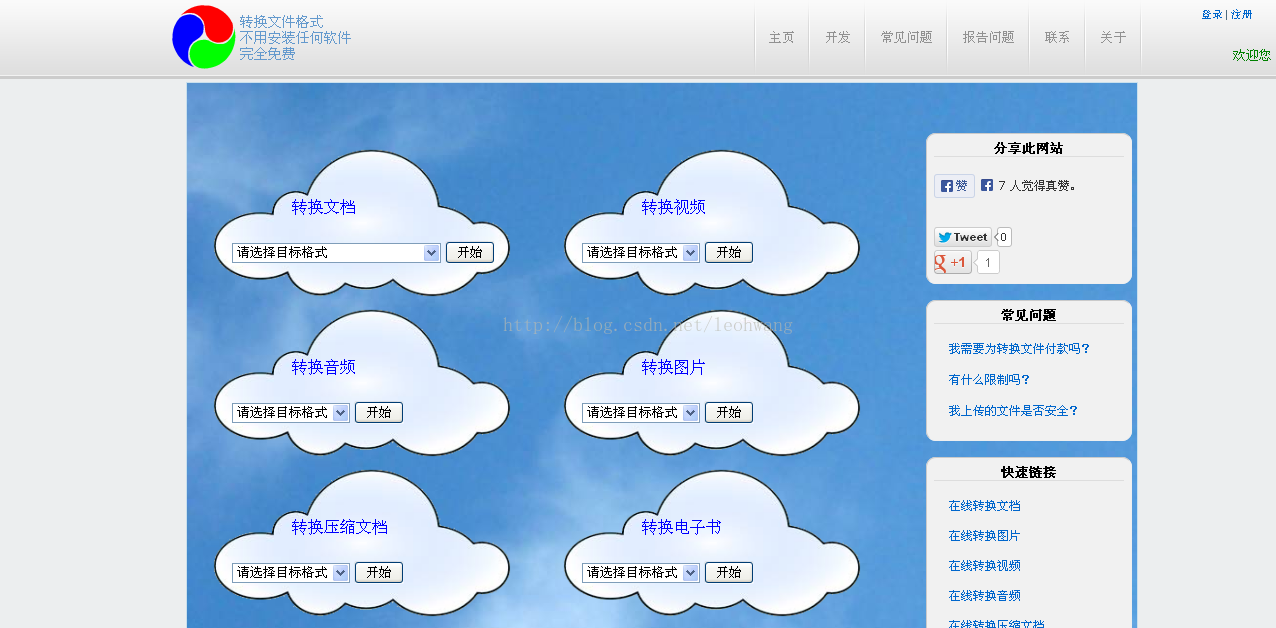
我们之前使用flask实现了一个模拟instagram的图片分享网站的开发, 但是图片的更新需要用户上传, 但是由于用户比较少, 鉴于这个问题, 我们就考虑引入一个爬虫机器人, 自动的向web程序相关的数据库表项中写入数据。
2. scrapy框架
这里选用的是scrapy框架:
参考资料:
1.官方文档: http://doc.scrapy.org/en/latest/intro/tutorial.html
2. http://blog.csdn.net/zhyh1435589631/article/details/51516241
借助这个框架, 我们可以借助非常精简的代码, 实现复杂的抓取工作。
3. 思路分析
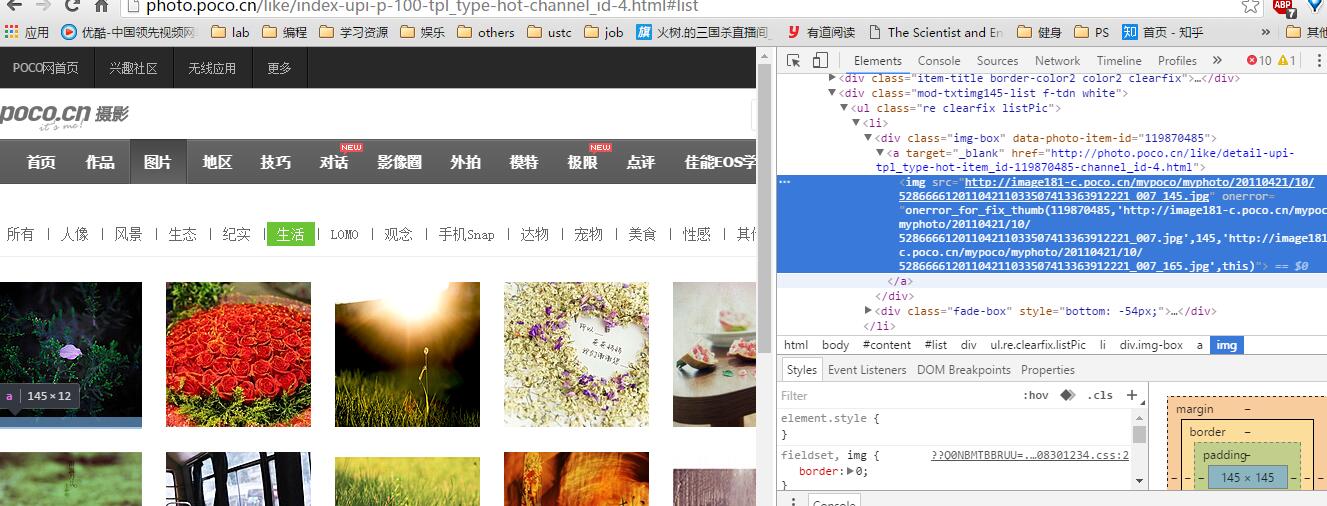
我们这里需要抓取的页面为 poco.cn 的风景图:
http://photo.poco.cn/like/index-upi-p-1-tpl_type-hot-channel_id-4.html#list
通过分析, 发现这里 p-1 标识第一页, 相应的第n页, 即为 p-n提取相应图片的url
经过测试, 发现onerror后面紧接着的连接即为我们需要的图片的url地址了, 通过简单的xpath, 和 re 方法组合, 我们可以方便的提取相应的元素将爬取下来的图片的url存入数据库
这里主要使用之前instagram项目中的数据库中的表项 image, 利用mysqldb 方法进行连接。
参考资料: http://blog.csdn.net/zhyh1435589631/article/details/51544903
4. 实现代码
主要实现功能, 抓取poco风景类前100页对应的图片的url, 并存到相应的image 表中。
import scrapy
from model import db1
from datetime import datetimefrom tutorial.items import TutorialItemINSERT_SQL = "insert into image (url, user_id, create_date) values ('%s', %d, '%s')"class DmozSpider(scrapy.Spider):name = "poco"allowed_domains = ["poco.cn"]page_id = 1url_prefix = "http://photo.poco.cn/like/index-upi-p-"url_suffix = "-tpl_type-hot-channel_id-1.html#list"start_urls = [url_prefix + str(page_id) + url_suffix,]def parse(self, response):total_page = response.xpath('//*[@id="list"]/div/a/text()').extract()[-2]# for i in range(1, int(total_page) + 1, 1):for i in range(1, 2, 1):url = self.url_prefix + str(i) + self.url_suffixprint urlyield scrapy.Request(url, callback=self.parse_url)def parse_url(self, response):for item in response.xpath('//*[@id="list"]/div/ul/li/div/a/img/@onerror'):item1 = TutorialItem()item1['url'] = item.re("onerror_for.*'(.*)'.*'http:.*'");sql = INSERT_SQL % (item1['url'][0], 32, datetime.now().strftime("%Y-%m-%d %H:%M:%S"))print sqldb1.execute(sql)yield item15. 抓取效果
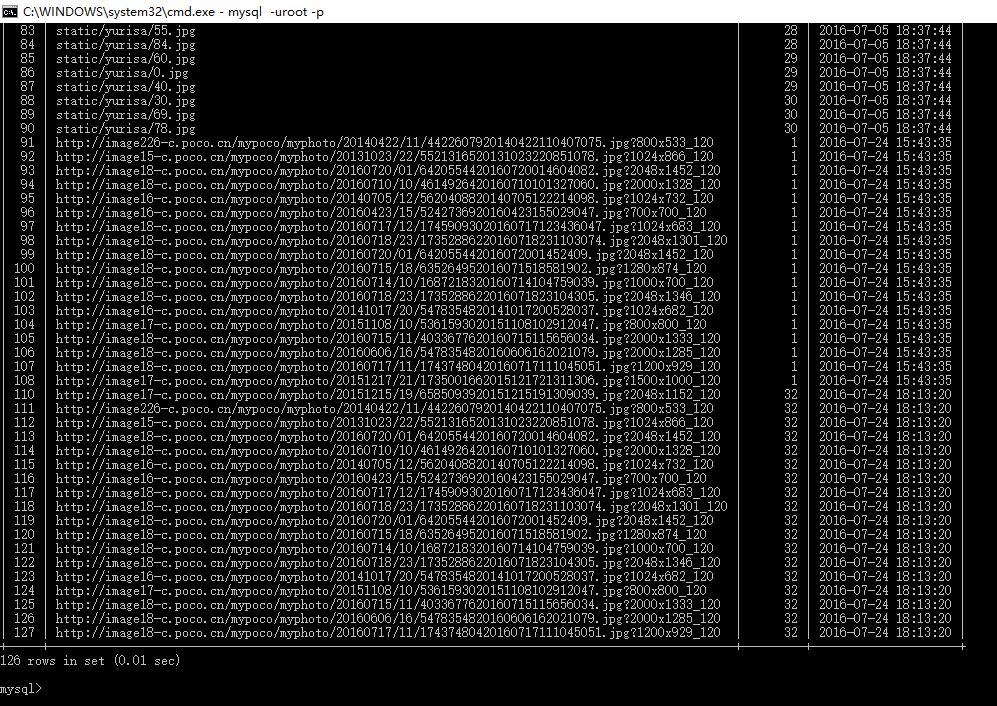
为了简单起见, 我们这里只抓取了前2页的图片url信息, 存入数据库。
6. 说明
本来想将这个程序放到服务器上的, 不过可惜配置lxml的时候出现了问题。
command ‘gcc’ failed with exit status 4
找了好久终于发现, 原来是我们的服务器的内存太小导致的。。。那就没办法了。。。











![[.Net Core学习一]网站发布](https://img-blog.csdnimg.cn/20190802152135263.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L2xpdXppc2hhbmc=,size_16,color_FFFFFF,t_70)