python堆的创建
问题和动机 (The problem and motivation)
I am not a natural or creative cook so when I want to do some cooking I always need a recipe to follow. My typical process before going on any grocery trip:
我不是天生的或有创造力的厨师,所以当我想做饭时,总是需要遵循一个食谱。 在进行杂货旅行之前,我的典型流程是:
- Look through internet to find interesting recipes 通过互联网查找有趣的食谱
- Aggregate the required ingredients 汇总所需的成分
- Manually group ingredients by food type to optimise shopping approach 手动按食物类型对成分进行分组以优化购物方式
This process becomes tedious with increasing numbers of recipes (and more ingredients). Personally, I can’t handle more than 3 recipes at a time (and admire the super dedicated people who can)!
随着配方(和更多成分)数量的增加,此过程变得乏味。 就我个人而言,我一次不能处理3种以上的菜谱(并且佩服能够做到的超级敬业人士)!
This results in frequent shopping trips which is undesirable because of the extra time involved and the current COVID-19 situation in Melbourne.
这导致频繁的购物旅行,这是不受欢迎的,因为要花费额外的时间以及当前墨尔本的COVID-19情况。
Existing solutions are not ideal
现有解决方案并不理想
A quick Google search shows that there are apps out there which address this problem. However, (1) the good ones cost money and (2) most apps have some sort of restrictions on the websites they accept as input.
快速的Google搜索显示,那里有可以解决此问题的应用程序。 但是,(1)好的应用程序要花钱,(2)大多数应用程序对它们接受的输入网站都有某种限制。
I started looking at ways to write a simple program with to achieve the following:
我开始研究编写简单程序的方法,以实现以下目的:
Accept as Input: list of recipes from any website
接受作为输入:来自任何网站的食谱列表
Produce as Output: list of ingredients, grouped by type, required quantity and associated recipe
生产为输出:成分列表,按类型,所需数量和相关配方分组
方法 (Approach)
The problem consists of two components:
该问题包括两个部分:
Ingredient Extraction: Extract ingredients from different websites and combine into a single list
成分提取:从不同的网站提取成分并合并为一个列表
Food Group Extraction: From the ingredients list, find and extract the associated food groups
食品组提取:从成分列表中查找并提取相关的食品组
My full code, with instructions to run, can be accessed here.
我的完整代码以及运行说明可以在此处访问。
(1) Ingredient Extraction
(1)成分提取
This is the hardest part but luckily a lot of work has already been put into solving this problem!
这是最困难的部分,但幸运的是,已经完成了很多工作来解决这个问题!
I passed each recipe’s URL into an open-source engine created by Zack Scholl and saved the combined output into a data frame, converting all measurements to metric.
我将每个配方的URL传递给Zack Scholl创建的开源引擎 ,并将合并的输出保存到数据框中,将所有度量转换为度量。
This engine takes any recipe website and outputs structured recipe data and in the blog I have linked, Zack describes his approach as well as general challenges with performing this ingredient extraction task.
该引擎可以访问任何食谱网站并输出结构化的食谱数据,在我链接的博客中,Zack描述了他的方法以及执行此成分提取任务的一般挑战。
(2) Food Group Extraction
(2)食物群提取
I used the USDA National Nutritional Database because their food groups roughly aligned to ‘shopping categories’ (I also considered the Australian version but the food group titles were too detailed to be useful).
我之所以使用美国农业部国家营养数据库,是因为他们的食物类别大致与“购物类别”保持一致(我也考虑过澳大利亚版本,但是食物类别的标题太详细了而无用)。
I stored the tables of interest (Food Group and Food Description) into an SQLite database so that I could use SQL queries to match ingredients with their associated food group. My query below:
我将感兴趣的表(食物组和食物描述)存储到SQLite数据库中,以便可以使用SQL查询将成分与其关联的食物组进行匹配。 我的查询如下:
SELECT group_name, COUNT(*) as count
FROM FD_DES
LEFT JOIN FD_GROUP ON FD_DES.group_id = FD_GROUP.group_id
WHERE shortdes LIKE ?
AND FD_GROUP.group_id NOT IN ('0300', '0800',
'1800', '1900',
'2100', '2200',
'2500', '3500','3600')
GROUP BY group_name
ORDER BY count DESC
LIMIT 1Logic of the query:
查询逻辑:
- for each ingredient, find all short descriptions which that ingredient appears in and its associated food groups 对于每种成分,请找到该成分出现的所有简短说明及其相关的食物组
- exclude any food groups with ingredients I almost never use (e.g. ‘0300 — Baby Foods’, ‘0800 — Breakfast Cereals’) 排除任何我几乎从未使用过的成分的食物组(例如“ 0300-婴儿食品”,“ 0800-早餐谷物”)
- output the food group which the ingredient appears most 输出成分最多的食物组
The ‘?’ parameter allows me to alter the query with Python as I iterate over the ingredients list:
'?' 参数允许我遍历配料表使用Python更改查询:
- for all ingredients, remove any plurals 对于所有成分,删除任何复数
for two-word ingredients, first query both words together and if nothing results, then query the second word by itself — this is based on the assumption that the second word is usually more descriptive of a food category (e.g. ‘blue cheese’, but clearly this logic would not work for something like ‘egg whites’)
对于两个单词的成分,首先要同时查询两个单词,如果没有结果,则单独查询第二个单词-这是基于以下假设:第二个单词通常更能描述食物类别(例如“蓝纹奶酪”,显然,这种逻辑不适用于“蛋白”之类的东西)
After extracting the food groups, I sorted my final list first by food group and then by ingredient name.
提取食物组之后,我首先按食物组然后按成分名称对最终列表进行排序。
使用代码 (Using the code)
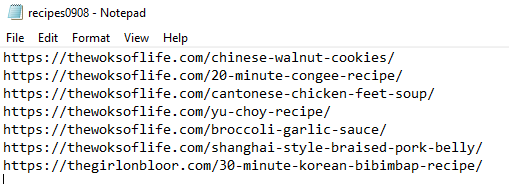
To use the code, I just need to create a text file with a list of recipe URLs (an example below) in the same directory as the code.
要使用该代码,我只需要创建一个文本文件,并在与该代码相同的目录中包含配方URL列表(以下示例)。
Then I run the following in my command prompt:
然后在命令提示符下运行以下命令:
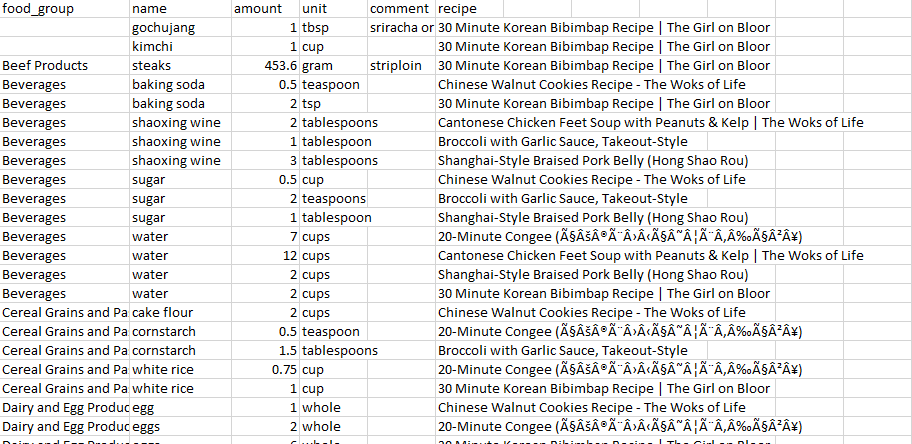
C:\Users\plcpi\Google Drive\Personal Projects\Ingredients extractor> python grocery.py 'recipes0908.txt'And here’s an excerpt of the results :
这是结果的摘录:
绩效评估 (Performance Assessment)
I think the code gets 80–90% of the job done. The initial limitations I found are described below.
我认为代码可以完成80-90%的工作。 我发现的初始限制如下所述。
‘Unusual’ ingredients
'不寻常'的成分
The ingredient parser excluded the crucial ingredient ‘choy sum’ from this recipe . This is probably because the parser didn’t assess this as an ‘ingredient line’ as ‘choy sum’ did not exist in the corpus of ingredients to assess probability of something being an ingredient.
成分分析器从此配方中排除了关键成分“ choy sum”。 这可能是因为解析器没有将其评估为“成分行”,因为在成分语料库中不存在“ choy sum”来评估某物是某种成分的可能性。
‘Choy sum’ was also the first in the ingredients list — the algorithm uses a bottom up extraction approach which is why ‘kimchi’ and ‘gochujang’ in this recipe made it through because they were in the middle of the list (and not necessarily because they were actually in the corpus).
'Choy sum'也是成分列表中的第一个-该算法使用了自下而上的提取方法,这就是为什么此食谱中的 'kimchi'和'gochujang'成功通过的原因,因为它们位于列表的中间(不一定)因为它们实际上在语料库中)。
So now I know to look for any ‘unusual’ ingredients at the bottom or top of my chosen recipe!
所以现在我知道要在我选择的食谱的底部或顶部寻找任何“不寻常”的成分!
Food group categorisation errors
食品组分类错误
The errors represent the limits of the SQL logic e.g. ‘sugar’ appeared the most in the ‘Beverage’ food group because of the ‘sugar added’/’sugar free’ descriptions for all drinks in the food database. In hindsight, I could have removed the ‘Beverage’ group as it is not common for ‘Beverage’ to be an ingredient type anyway.
这些错误代表了SQL逻辑的局限性,例如,“糖”在“饮料”食品组中出现最多,因为食品数据库中所有饮料的“加糖” /“无糖”描述。 事后看来,我可以删除“饮料”组,因为“饮料”成为一种成分类型并不常见。
Using string similarity (e.g. Levenschtein distance) is another approach I could have used to extract food group— I did not test this out on the US database but did so on the Australian one — the results did not improve accuracy by much (on the Australian one at least) and slowed the program down quite a bit.
使用字符串相似性(例如Levenschtein距离)是我可以用来提取食物组的另一种方法-我没有在美国数据库上对此进行过测试,但在澳大利亚的数据库上进行了此测试-结果并没有很大程度地提高准确性(在澳大利亚至少),并使程序运行速度大大降低。
Further, ‘Asian Food’ did not exist as a category in the database which led to some ingredients not being included (‘kimchi’) or incorrectly categorised (‘shaoxing wine’).
此外,“亚洲食品”在数据库中没有作为一个类别存在,这导致某些成分未被包括(“泡菜”)或分类不正确(“绍兴酒”)。
最后的想法 (Final Thoughts)
In the above example, I put in 5 recipe URLs which resulted in a csv file of 67 lines. It then only took me a few minutes to delete the ingredients already in my pantry and re-categorise the couple of ingredients that were in wrong groups.
在上面的示例中,我输入了5个配方URL,这些URL生成了67行的csv文件。 然后,我只花了几分钟就删除了我食品储藏室中已经存在的食材,并对属于错误组的食材进行了重新分类。
Overall, this definitely saves me a lot of time compared to my original manual process — of course, running this code is not worth it for just 1 or 2 (if both are simple) recipes.
总体而言,与原始的手动过程相比,这无疑节省了我很多时间-当然,仅使用1或2个配方(如果两者都很简单),运行此代码是不值得的。
Now … on to the actual shopping (😫).
现在…开始实际的购物(😫)。
旁注:改进 (Side note: Improvements)
- An easy extension is to consolidate ingredients, but personally I like to keep this separate in case I don’t want to shop for a certain recipe while I am out (which sometimes happens when I can’t find a certain ingredient which occurs more often now with COVID-19 shortages). 一个简单的扩展就是合并各种成分,但是就我个人而言,我希望将其分开,以防万一我不想在外出时购买某种食谱(有时会在找不到某种成分且经常出现的情况下发生)现在缺少COVID-19)。
- The code, which requires a Python environment, is not great for sharing or implementing without a desktop — making it a web app (and allowing the user ability to customise for which food groups to exclude and what units of measurements to output) would be a great next step. 该代码需要一个Python环境,不适用于没有桌面的共享或实现-使它成为一个Web应用程序(并允许用户自定义排除哪些食物组以及要输出的度量单位)。伟大的下一步。
翻译自: https://medium.com/@katie.ziyan.zhang/how-i-automated-the-creation-of-my-grocery-list-from-a-bunch-of-recipe-websites-with-python-90d15e5c0c83
python堆的创建
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.luyixian.cn/news_show_856346.aspx
如若内容造成侵权/违法违规/事实不符,请联系dt猫网进行投诉反馈email:809451989@qq.com,一经查实,立即删除!相关文章

Web搜寻网站的多个网页
github创建个人网站_创建一个令人印象深刻的GitHub个人资料

mapstruct简化开发_简化投资组合网站的开发

5g 软件软件开发_在5天内建立一个软件开发人员投资组合网站

重复绑定mouseover和mouseout事件
搭建WebGIS网站
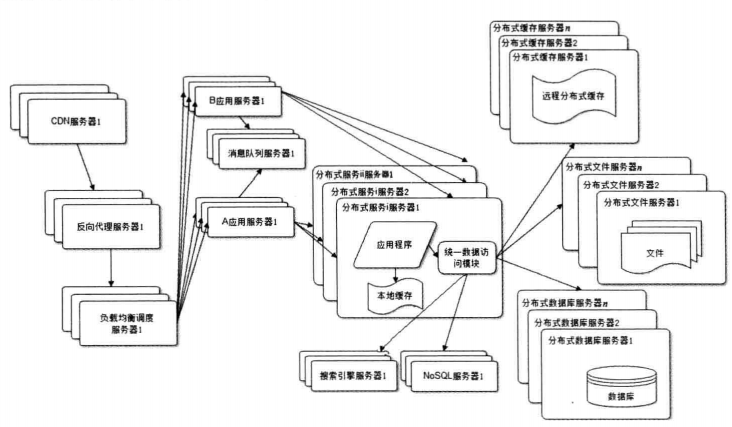
大型网站技术架构(1)
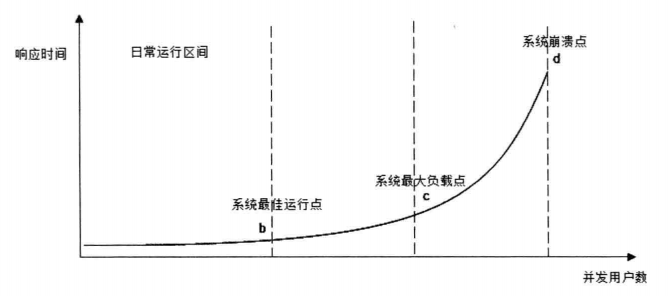
大型网站技术架构(2):架构要素和高性能架构
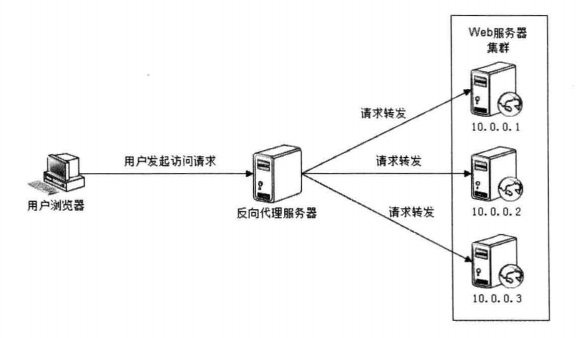
大型网站技术架构(3):WEB 前端性能优化
网站样式快速设计软件_如何(快速)设计样式指南
快速的UX批评:Kanye West的总统签名收集网站

在网站中内置WebRTC视频聊天

LAMP网站架构方案分析
Android webview中定制js的alert,confirm和prompt对话框的方法 (处理webview 带网站地址的弹出框)
网站加速--动态应用篇 (上)
网站加速--动态应用篇 (下)
jsp网站引入外部css或者js失效原因分析

2017 年最受欢迎的 10 个编程挑战网站
