1:创建项目

2:创建爬虫

3:编写start.py文件用于运行爬虫程序
# -*- coding:utf-8 -*- #作者: baikai #创建时间: 2018/12/14 14:09 #文件: start.py #IDE: PyCharm from scrapy import cmdlinecmdline.execute("scrapy crawl js".split())
4:设置settings.py文件的相关设置



爬取详情页数据
编写items.py文件
# -*- coding: utf-8 -*-# Define here the models for your scraped items # # See documentation in: # https://doc.scrapy.org/en/latest/topics/items.htmlimport scrapyclass ArticleItem(scrapy.Item):# 定义我们需要的存储数据字段title=scrapy.Field()content=scrapy.Field()article_id=scrapy.Field()origin_url=scrapy.Field()author=scrapy.Field()avatar=scrapy.Field()pub_time=scrapy.Field()
编写js.py
# -*- coding: utf-8 -*- import scrapy from scrapy.linkextractors import LinkExtractor from scrapy.spiders import CrawlSpider, Rule from jianshu_spider.items import ArticleItemclass JsSpider(CrawlSpider):name = 'js'allowed_domains = ['jianshu.com']start_urls = ['https://www.jianshu.com/']rules = (# 匹配地址https://www.jianshu.com/p/d8804d18d638Rule(LinkExtractor(allow=r'.*/p/[0-9a-z]{12}.*'), callback='parse_detail', follow=True),)def parse_detail(self, response):# 获取内容页数据并解析数据title=response.xpath("//h1[@class='title']/text()").get()#作者图像avatar=response.xpath("//a[@class='avatar']/img/@src").get()author=response.xpath("//span[@class='name']/a/text()").get()#发布时间pub_time=response.xpath("//span[@class='publish-time']/text()").get()#详情页idurl=response.url#https://www.jianshu.com/p/d8804d18d638url1=url.split("?")[0]article_id=url1.split("/")[-1]#文章内容content=response.xpath("//div[@class='show-content']").get()item=ArticleItem(title=title,avatar=avatar,author=author,pub_time=pub_time,origin_url=response.url,article_id=article_id,content=content)yield item
设计数据库和表
数据库jianshu
表article
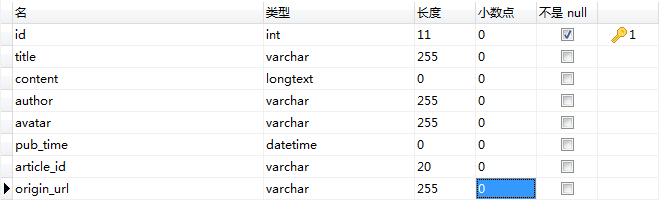
id设置为自动增长

将爬取到的数据存储到mysql数据库中
# -*- coding: utf-8 -*-# Define your item pipelines here # # Don't forget to add your pipeline to the ITEM_PIPELINES setting # See: https://doc.scrapy.org/en/latest/topics/item-pipeline.htmlimport pymysql from twisted.enterprise import adbapi from pymysql import cursorsclass JianshuSpiderPipeline(object):def __init__(self):dbparams = {'host': '127.0.0.1','port': 3306,'user': 'root','password': '8Wxx.ypa','database': 'jianshu','charset': 'utf8'}self.conn = pymysql.connect(**dbparams)self.cursor = self.conn.cursor()self._sql = Nonedef process_item(self, item, spider):self.cursor.execute(self.sql, (item['title'], item['content'], item['author'], item['avatar'], item['pub_time'], item['origin_url'],item['article_id']))self.conn.commit()return item@propertydef sql(self):if not self._sql:self._sql = """insert into article(id,title,content,author,avatar,pub_time,origin_url,article_id) values(null,%s,%s,%s,%s,%s,%s,%s)"""return self._sqlreturn self._sql
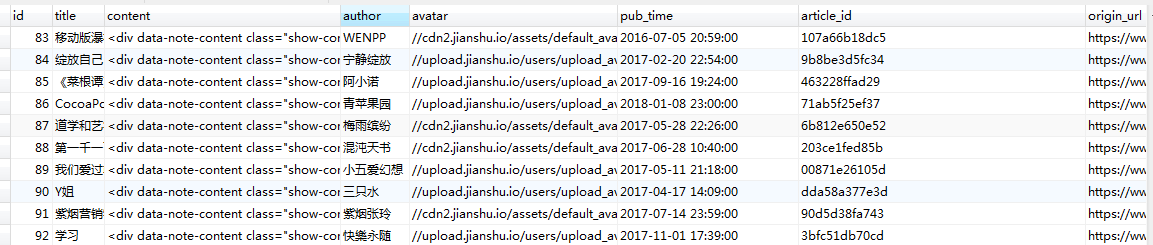
运行start.py效果如下