计算图的介绍结束了,下面我们来实现一些实用的层。这里,我们将实现Sigmoid层、全连接层,Affine层和Softmax with Loss层。
1.Sigmoid层
sigmoid函数由
表示,
sigmoid函数的导数由下式表示
Sigmoid层的计算图可以绘制成如下图。这里,将输出侧的层传来的梯度()乘以sigmoid函数的导数(
),然后将这个值传递给输入侧的层。

接下来,我们使用Python来实现Sigmoid层。
class Sigmoid:def __init__(self):self.params,self.grads=[],[]self.out=Nonepassdef forward(self,x):out = 1/(1+np.exp(-x))self.out=outreturn outdef backward(self,dout):dx = dout*(1.0-self.out)*self.outreturn dx这里将正向传播的输出保存在实例变量out中。然后,在反向传播中,使用这个out变量进行计算。
2.Affine层
如前所示,我们通过y = np.dot(x, W) + b实现了Affine层的正向传播。此时,在偏置的加法中,使用了NumPy的广播功能。如果明示这一点,则Affine层的计算图如图.

通过MatMul节点进行矩阵乘积的计算。偏置被Repeat节点复制,然后进行加法运算(可以认为NumPy的广播功能在内部进行了Repeat节点的计算)。下面是Affine层的实现.
class Affine:def __init__(self,W,b):self.params = [W,b]self.grads = [np.zeros_like(W),np.zeros_like(b)]self.x =Nonepassdef forward(self,x):W,b =self.paramsout =np.dot(x,W)+bself.x =xreturn outdef backward(self,dout):W,b = self.paramsdx = np.dot(dout,W.T)dW = np.dot(self.x.T,dout)db = np.sum(dout,axis=0)self.grads[0][...]=dWself.grads[1][...]=dbreturn dx根据本书的代码规范,Affine层将参数保存在实例变量params中,将梯度保存在实例变量grads中。它的反向传播可以通过执行MatMul节点和Repeat节点的反向传播来实现。Repeat节点的反向传播可以通过np.sum()计算出来,此时注意矩阵的形状,就可以清楚地知道应该对哪个轴(axis)求和。最后,将权重参数的梯度设置给实例变量grads。以上就是Affine层的实现。
使用已经实现的MatMul层,可以更轻松地实现Affine层。这里出于复习的目的,没有使用MatMul层,而是使用NumPy的方法进行了实现。
3 Softmax with Loss层
我们将Softmax函数和交叉熵误差一起实现为Softmax with Loss层。此时,计算图如图
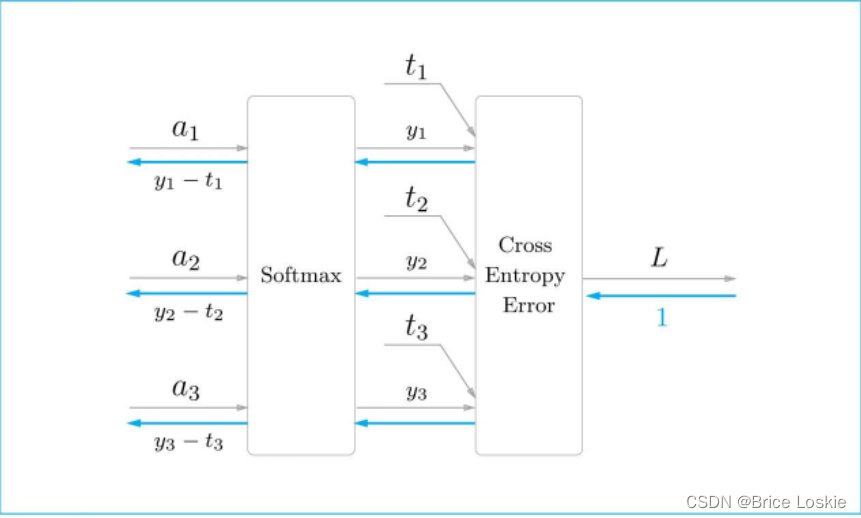
计算图将Softmax函数记为Softmax层,将交叉熵误差记为Cross Entropy Error层。这里假设要执行3类别分类的任务,从前一层(靠近输入的层)接收3个输入。
Softmax层对输入a1, a2, a3进行正规化,输出y1, y2, y3。Cross Entropy Error层接收Softmax的输出y1, y2,y3和监督标签t1, t2, t3,并基于这些数据输出损失L。
需要注意的是反向传播的结果。从Softmax层传来的反向传播有y1-t1, y2-t2, y3-t3这样一个很“漂亮”的结果。因为y1, y2, y3是Softmax层的输出,t1, t2, t3是监督标签,所以y1-t1, y2-t2, y3-t3是Softmax层的输出和监督标签的差分。神经网络的反向传播将这个差分(误差)传给前面的层。这是神经网络的学习中的一个重要性质。
class SoftmaxWithLoss:def __init__(self):self.params, self.grads = [], []self.y = None # softmax的输出self.t = None # 监督标签def forward(self, x, t):self.t = tself.y = softmax(x)# 在监督标签为one-hot向量的情况下,转换为正确解标签的索引if self.t.size == self.y.size:self.t = self.t.argmax(axis=1)loss = cross_entropy_error(self.y, self.t)return lossdef backward(self, dout=1):batch_size = self.t.shape[0]dx = self.y.copy()dx[np.arange(batch_size), self.t] -= 1dx *= doutdx = dx / batch_sizereturn dx