爬取网站内的全部小说
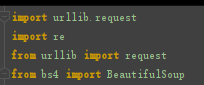
我们需要用到的模块有
re
BeautifulSoup
首先我们要确定我们爬取的网站:http://www.136book.com/tuijian.php?id=1
一在爬取各个书目录的网址时我选择了用正则表达式来爬取:
选用正则爬取单独的href是比较方便的。爬取后要确定是否为书目录的网站。我发现目录章节的网址的后缀target="blank。用此确定是否为目录的href
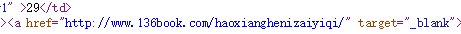
具体代码如下:

二,爬取目录的网址后,就是爬取各个章节网址
这次我们要用到新的模块BeautifulSoup。首先先看一下目录章节的网址源代码
地址都在:id=‘book_detail’, class=‘box1’
利用这一点获取各个章节的href
具体代码如





![[转载]搭建个人网站 |博客](http://upload.idcquan.com/2011/0414/1302767724819.jpg)