文章目录
- ①. LBS出现的背景
- ②. 重新认识经纬度
- ③. 感性认识GeoHash
- ④. Geohash算法介绍
- ⑤. Geohash算法步骤
- ⑥. 更深入剖析GeoHash
- ⑦. 邻近网格位置推算
①. LBS出现的背景
-
①. 移动互联网时代LBS应用越来越多,所在位置附近三公里的药店、交友软件中附近的小姐姐、外卖软件中附近的美食店铺、打车软件附近的车辆等等,那这种附近各种形形色色的XXX地址位置选择是如何实现的?
-
②. 地球上的地理位置是使用二维的经纬度表示,经度范围 (-180, 180],纬度范围 (-90, 90],只要我们确定一个点的经纬度就可以名曲他在地球的位置
- 例如滴滴打车,最直观的操作就是实时记录更新各个车的位置,
- 然后当我们要找车时,在数据库中查找距离我们(坐标x0,y0)附近r公里范围内部的车辆
# 使用如下SQL即可
select taxi from position where x0-r < x < x0 + r and y0-r < y < y0+r
- ③. 但是这样会有什么问题呢?
- 查询性能问题,如果并发高,数据量大这种查询是要搞垮数据库的
- 这个查询的是一个矩形访问,而不是以我为中心r公里为半径的圆形访问
- 精准度的问题,我们知道地球不是平面坐标系,而是一个圆球,这种矩形计算在长距离计算时会有很大误差
②. 重新认识经纬度
-
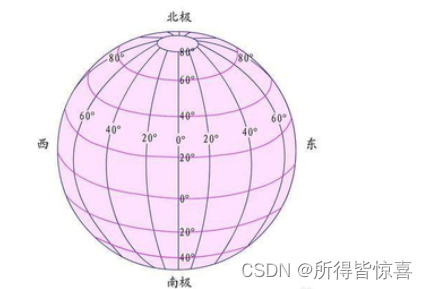
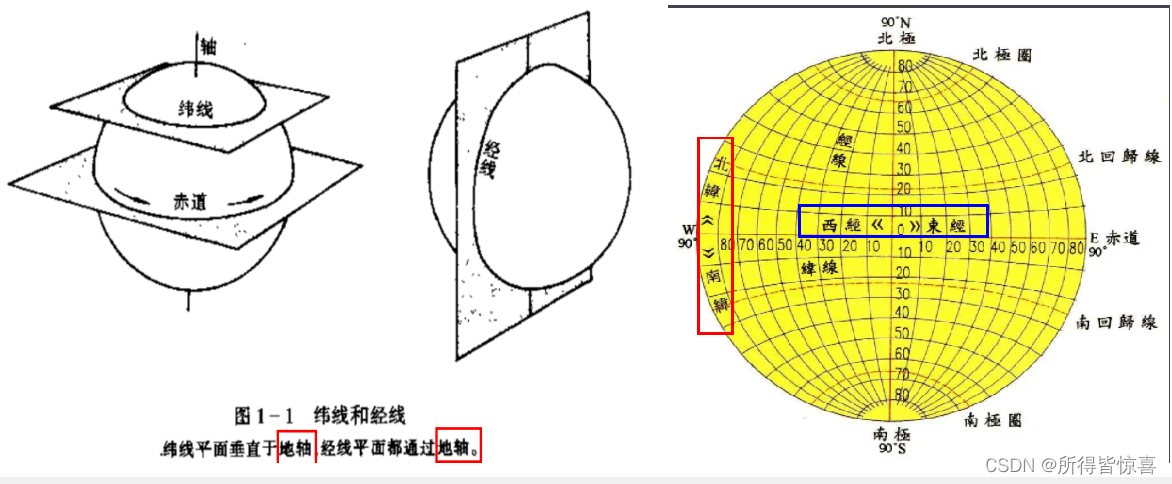
①. 经纬度:经度与纬度的合称组成一个坐标系统。又称为地理坐标系统,它是一种利用三度空间的球面来定义地球上的空间的球面坐标系统,能够标示地球上的任何一个位置
-
②. 经线和纬线
- 是人们为了在地球上确定位置和方向的,在地球仪和地图上画出来的,地面上并线
- 和经线相垂直的线叫做纬线(纬线指示东西方向)。纬线是一条条长度不等的圆圈。最长的纬线就是赤道
- 因为经线指示南北方向,所以经线又叫子午线。 国际上规定,把通过英国格林尼治天文台原址的经线叫做0°所以经线也叫本初子午线
- 在地球上经线指示南北方向,纬线指示东西方向
- ③. 经度和维度
- 经度(longitude):东经为正数,西经为负数。东西经
- 经度(longitude):东经为正数,西经为负数。东西经

- ④. 在一定误差范围内,通常情况下,经纬线和米的换算为:经度或者纬度0.00001度,约等于1米。以下表格列出更细致的换算关系
| 在纬度相等的情况下 | 在经度相等的情况下 |
|---|---|
| 经度每隔0.00001度,距离相差约1米;每隔0.0001度,距离相差约10米;每隔0.001度,距离相差约100米;每隔0.01度,距离相差约1000米;每隔0.1度,距离相差约10000米 | 纬度每隔0.00001度,距离相差约1.1米;每隔0.0001度,距离相差约11米;每隔0.001度,距离相差约111米;每隔0.01度,距离相差约1113米;每隔0.1度,距离相差约11132米 |
③. 感性认识GeoHash
-
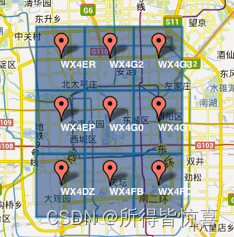
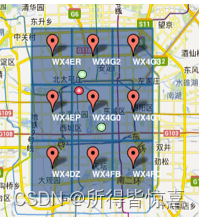
①. GeoHash将二维的经纬度转换成字符串,比如下图展示了北京9个区域的GeoHash字符串,分别是WX4ER,WX4G2、WX4G3等等,每一个字符串代表了某一矩形区域。也就是说,这个矩形区域内所有的点(经纬度坐标)都共享相同的GeoHash字符串,这样既可以保护隐私(只表示大概区域位置而不是具体的点),又比较容易做缓存,比如左上角这个区域内的用户不断发送位置信息请求餐馆数据,由于这些用户的GeoHash字符串都是WX4ER,所以可以把WX4ER当作key,把该区域的餐馆信息当作value来进行缓存,而如果不使用GeoHash的话,由于区域内的用户传来的经纬度是各不相同的,很难做缓存
-
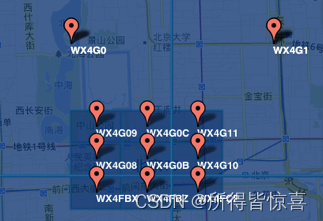
②. 字符串越长,表示的范围越精确。如图所示,5位的编码能表示10平方千米范围的矩形区域,而6位编码能表示更精细的区域(约0.34平方千米)
-
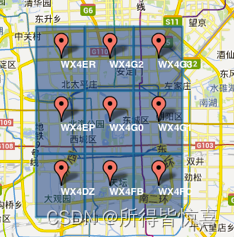
③. 字符串相似的表示距离相近(特殊情况后文阐述),这样可以利用字符串的前缀匹配来查询附近的POI信息。如下两个图所示,一个在城区,一个在郊区,城区的GeoHash字符串之间比较相似,郊区的字符串之间也比较相似,而城区和郊区的GeoHash字符串相似程度要低些
-
④. 通过上面的介绍我们知道了GeoHash就是一种将经纬度转换成字符串的方法,并且使得在大部分情况下,字符串前缀匹配越多的距离越近,回到我们的案例,根据所在位置查询来查询附近餐馆时,只需要将所在位置经纬度转换成GeoHash字符串,并与各个餐馆的GeoHash字符串进行前缀匹配,匹配越多的距离越近
④. Geohash算法介绍
-
①. GeoHash是空间索引的一种方式,其基本原理是将地球理解为一个二维平面,通过把二维的空间经纬度数据编码为一个字符串,可以把平面递归分解成更小的子块,每个子块在一定经纬度范围内拥有相同的编码
-
②. 以GeoHash方式建立空间索引,可以提高对空间poi数据进行经纬度检索的效率
-
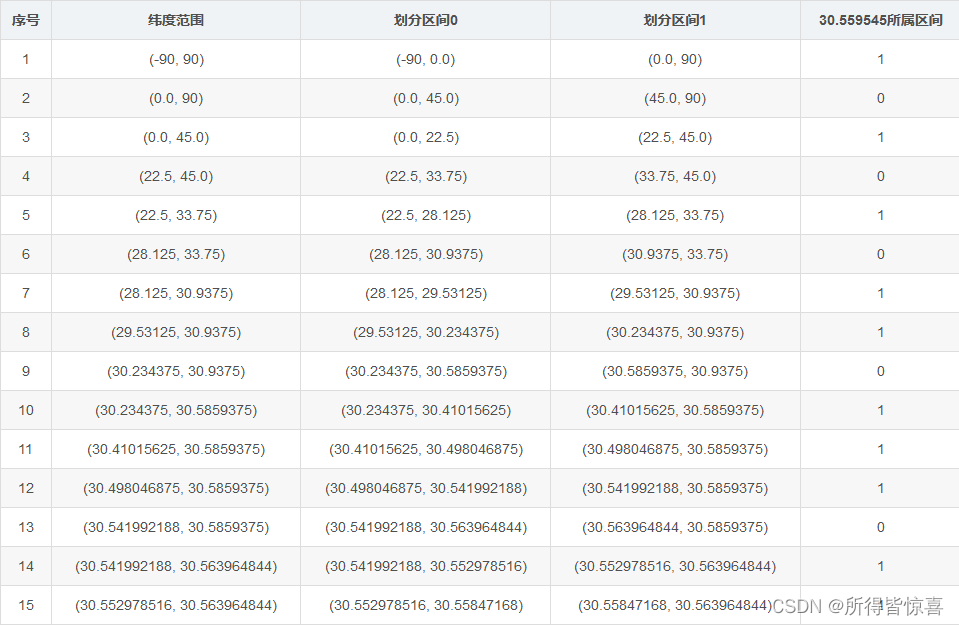
③. 编码规则为:先将纬度范围(-90, 90)平分成两个区间(-90, 0)和(0, 90),如果目标维度位于前一个区间,则编码为0,否则编码为1,然后根据目标纬度所落的区间再平均分成两个区间进行编码,以此类推,直到精度满足要求,经度也用同样的算法,对(-180, 180)依次细分,然后合并经度和纬度的编码,奇数位放纬度,偶数位放经度,组成一串新的二进制编码,按照Base32进行编码
⑤. Geohash算法步骤
-
①. 以当前所在办公区【两江国际】的位置坐标为例, 经纬度为(104.059684,30.559545)
-
②. 将经纬度转换为二进制
最后得到维度的二进制编码为:101010110111011, 用同样的方式可以得到精度(104.059684)的二进制编码:110010011111111
-
③. 将经纬度的二进制编码合并,从偶数0开始,经度占偶数位,纬度占奇数位

-
④. 将合并后的二进制数做Base32编码
- 按照每5位一组,分成6组,每组计算其对应的十进制数值,按照Base32进行编码
- Base32编码表的其中一种如下,是用0-9、b-z(去掉a, i, l, o)这32个字母进行编码

11100 10011 00011 11011 11111 01111
28(w) 19(m) 3(3) 27(v) 31(z) 15(g)
-
⑤. 最终得到的经纬度编码为:wm3vzg
-
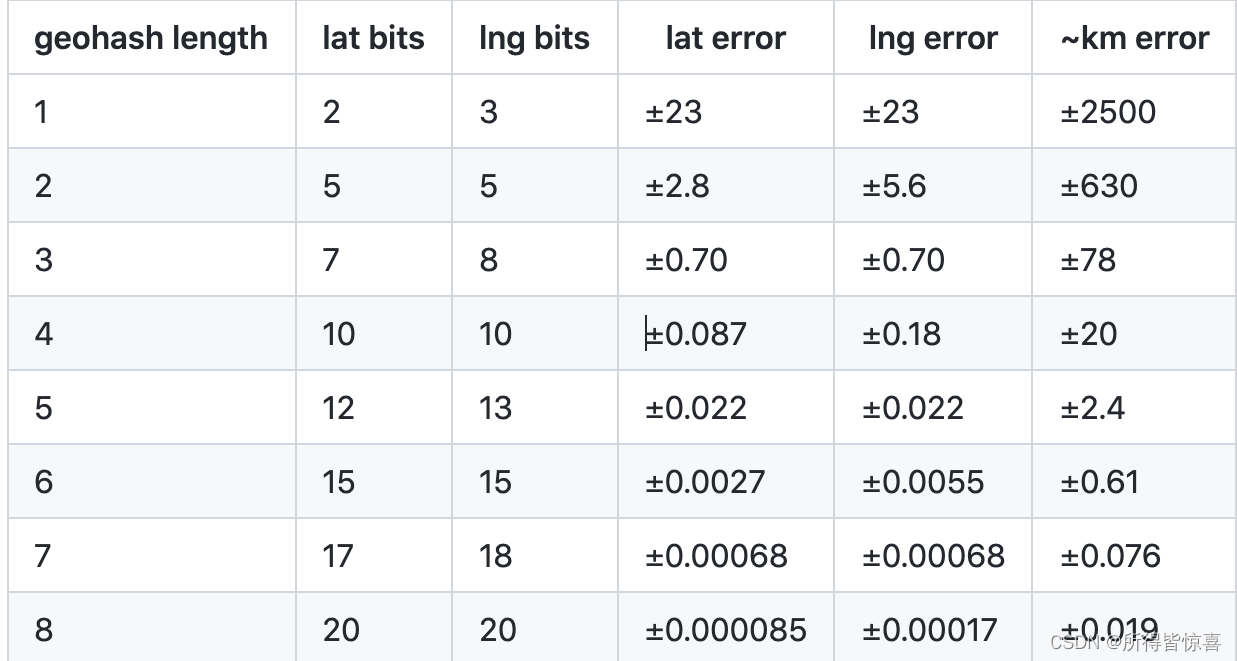
⑥. 如上文二进制编码的计算过程,如果递归的次数越大,则生成的二进制编码越长,因此生成的geohash编码越长,位置越精确。目前Geohash使用的精度说明如下:
-
⑦. GeoHash用一个字符串表示经度和纬度两个坐标, 比直接用经纬度的高效很多,而且使用者可以发布地址编码,既能表明自己位于某位置附近,又不至于暴露自己的精确坐标,有助于隐私保护
-
⑧. 编码过程中,通过二分范围匹配的方式来决定某个经纬坐标是编码为1还是0,因此某些邻近坐标的编码是相同的,因此GeoHash表示的并不是一个点,而是一个矩形区域。 GeoHash编码的前缀可以表示更大的区域。例如wm3vzg,它的前缀wm3vz表示包含编码wm3vzg在内的更大范围。 这个特性可以用于附近地点搜索
-
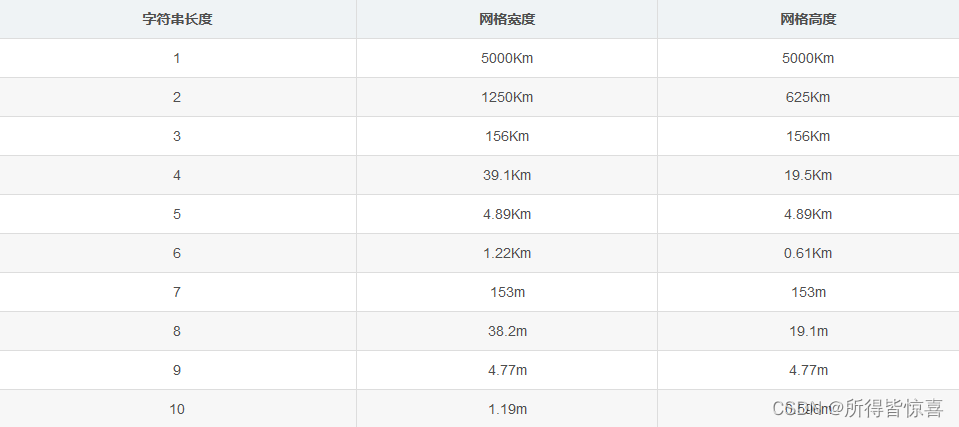
⑨. 如果把某个区域或整个地图上的地理位置都按照Geohash编码,则会得到一个网格,编码递归粒度越细,网格的矩形区域越小,geohash编码的长度越大,则Geohash编码越精确。 不同的编码长度,生成的网格与实际地理的精度如下(Geohash字符串编码长度对应网格大小)
⑥. 更深入剖析GeoHash
-
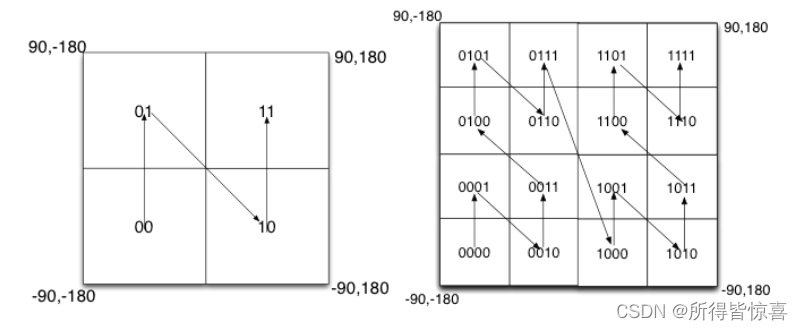
①. 如图所示,我们将二进制编码的结果填写到空间中,当将空间划分为四块时候,编码的顺序分别是左下角00,左上角01,右下脚10,右上角11,也就是类似于Z的曲线,当我们递归的将各个块分解成更小的子块时,编码的顺序是自相似的(分形),每一个子快也形成Z曲线,这种类型的曲线被称为Peano空间填充曲线
-
②. 这种类型的空间填充曲线的优点是将二维空间转换成一维曲线(事实上是分形维),对大部分而言,编码相似的距离也相近, 但Peano空间填充曲线最大的缺点就是突变性,有些编码相邻但距离却相差很远,比如0111与1000,编码是相邻的,但距离相差很大
-
③. 除Peano空间填充曲线外,还有很多空间填充曲线,如图所示,其中效果公认较好是Hilbert空间填充曲线,相较于Peano曲线而言,Hilbert曲线没有较大的突变。为什么GeoHash不选择Hilbert空间填充曲线呢?可能是Peano曲线思路以及计算上比较简单吧,事实上,Peano曲线就是一种四叉树线性编码方式

-
④. 由于GeoHash是将区域划分为一个个规则矩形,并对每个矩形进行编码,这样在查询附近POI信息时会导致以下问题,比如红色的点是我们的位置,绿色的两个点分别是附近的两个餐馆,但是在查询的时候会发现距离较远餐馆的GeoHash编码与我们一样(因为在同一个GeoHash区域块上),而较近餐馆的GeoHash编码与我们不一致。这个问题往往产生在边界处
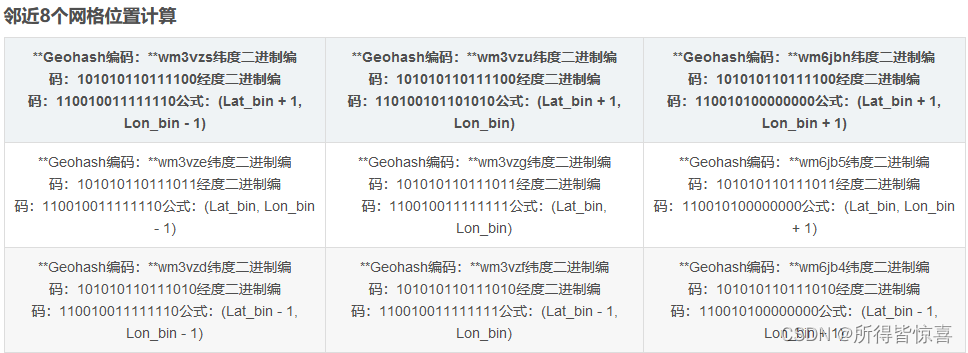
解决的思路很简单,我们查询时,除了使用定位点的GeoHash编码进行匹配外,还使用周围8个区域的GeoHash编码,这样可以避免这个问题
-
⑤. 我们已经知道现有的GeoHash算法使用的是Peano空间填充曲线,这种曲线会产生突变,造成了编码虽然相似但距离可能相差很大的问题,因此在查询附近餐馆时候,首先筛选GeoHash编码相似的POI点,然后进行实际距离计算
⑦. 邻近网格位置推算
-
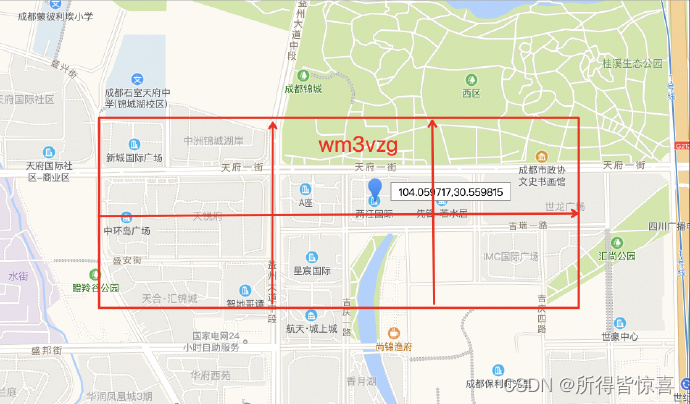
①. 当前选取的编码长度为6,因此一个网格实际的地理差异在1.2公里与0.6公里,示例中两江国际对应的网格大致效果如图:
-
②. 结论:
根据Geohash的编码规则将经纬度分解到二进制,结合地理常识,中心网格在南北(上下)方向上体现为纬度的变化,往北则维度的二进制加1,往南则维度的二进制减1,在东西(左右)方向上体现为经度的变化,往东则经度的二进制加1,往西则减1,可以计算出上下左右四个网格经纬度的二进制编码,再将加减得出的经纬度两两组合,计算出左上、左下、右上和右下四个网格的经纬度二进制编码,从而就可以根据Geohash的编码规则计算出周围八个网格的字符串 -
③. 正向推导
- 以Geohash编码长度为6为基础,网格的宽高与实际距离换算为:1.2Km*0.6Km.
- 参考上文提到的,在经度相同情况下,每隔0.001度,距离相差约111米。0.6Km换算为纬度为:0.005405405。
- 当前两江国际粗粒度的wgs84坐标(104.05503,30.562251), 纬度二进制编码:101010110111011,经度二进制编码:110010011111111, Geohash值为:wm3vzg
- 正北方向近邻的网格维度为增加一个网格的高度,即纬度增加0.005405405,为:30.562251 + 0.005405405 = 30.567656405, 转换为二进制编码后为(可用工具快速转换):101010110111100
- 正好是原纬度的二进制编码101010110111011 加1后的结果(101010110111011 + 000000000000001 = 101010110111100)
- ④. 反向推导
- 当前两江国际粗粒度的wgs84坐标(104.05503,30.562251), 纬度二进制编码:101010110111011,经度二进制编码:110010011111111, Geohash值为:wm3vzg
- 基于当前坐标的网格,正北方向近邻的网格N,其纬度二进制加1后为:101010110111100,经度不变,其Geohash值为:wm3vzu
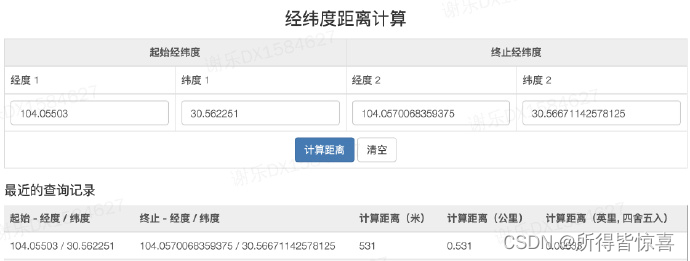
- 通过http://geohash.co/ 反向转换其经纬坐标为:(104.0570068359375,30.56671142578125)
- 通过https://www.box3.cn/tools/lbs.html 查询2个坐标的实际位置,误差在531m(符合精度范围)
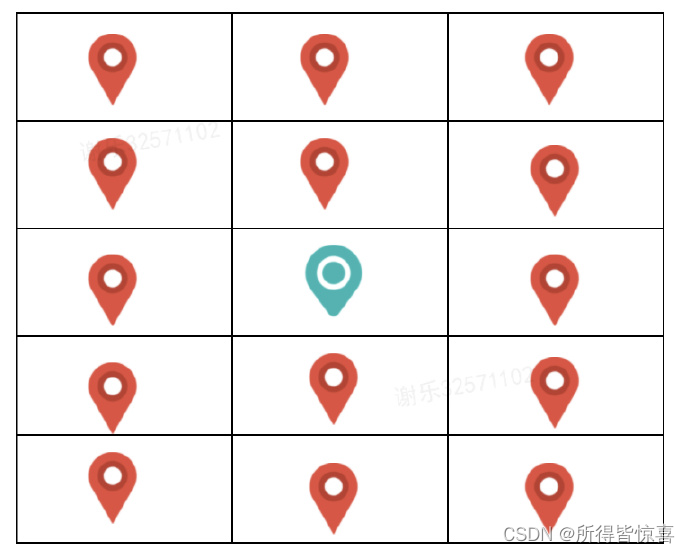
- ⑤. 附近3公里网格模型
青色代表:用户位置的网格编码,红色代表:附近附近3公里的网格编码
![[Flink]概述day1第4个视频完](https://img-blog.csdnimg.cn/img_convert/f6b147431ed74c94b8b693a69e663887.png)