一、概述
什么是Flink
是一种大数据计算引擎,用于对无界(流数据)和有界(批数据)数据进行有状态计算。
特点
1)批流一体:统一批处理、流处理
2)分布式:Flink程序可以运行在多台电脑上
3)高性能:处理速度很快
4)高可用:Flink支持高可用性(HA)
5)Flink可以保证数据处理的准确性,及时出现问题,也能进行修正
Flink的核心组成
1)Deploy(部署)层
①本地模式:启动单个JVM让Flink以Local模式运行。
②集群模式运行:standalone(flink自己管理自己的资源)、yarn(yarn管理集群资源)
③运行在云服务器
2)Core层:runtime运行时的核心技术
3)API层
在runtime之上提供了两套核心api:DataStream API(流处理)、DataSet API(批处理)。
4)应用框架层(用于满足特定应用)
datastream:CEP(Event Processing复杂事件处理)、Table(Relational关系型数据库处理)
dataset :Table(关系型数据库)、flinkML(机器学习)、Gelly(图计算)
3.flink可以处理哪些数据
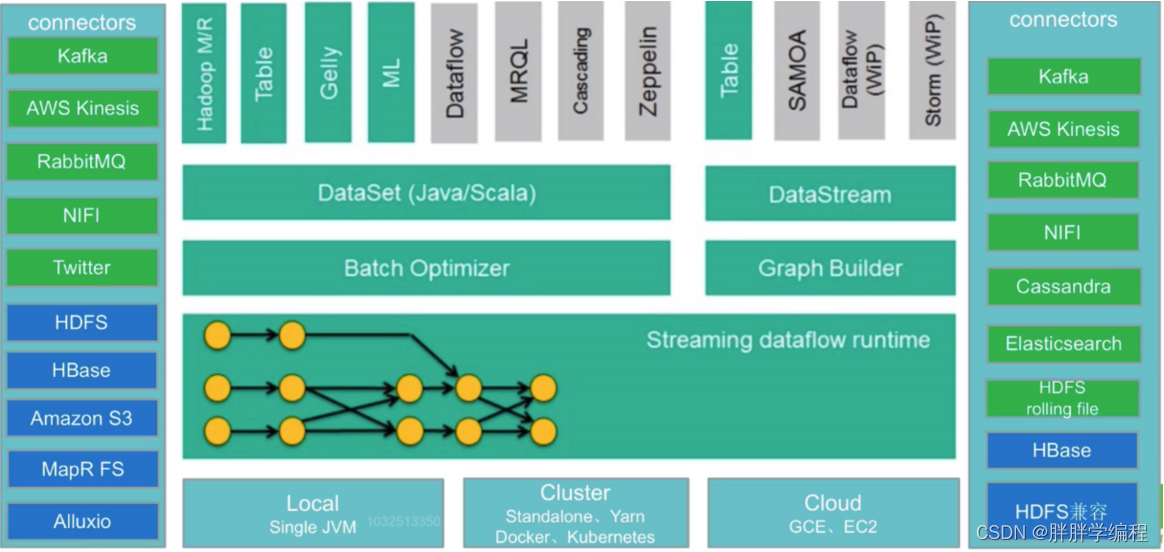
绿色:流处理 蓝色:批处理
输入Connectors(左侧部分)
流处理:kafka等
批处理:HDFS、HBase等
输出Connectors(右侧部分)
流处理:kafka、elasticsearch(全文检索)、HDFS rolling file(滚动文件)
批处理:HBase、HDFS
4.Flink的处理模型:流处理与批处理
1)无限流处理:输入的数据像水一样源源不断
2)有限流处理:一次处理一部分数据
5.有状态的流处理:
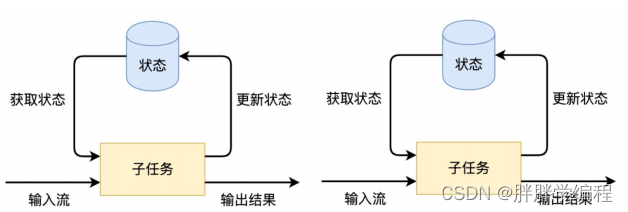
1)flink在处理有限流和无线流时,都可以保存处理状态。
2)可以将第一个子任务的处理结果形成一个状态,将状态保存起来(可以保存在内存中,也可以持久化大到外部存储系统中)。当前状态保存了其中一个子任务处理的中间结果。
3)优点:在第一个任务的位置挂掉了,程序重新启动时,不在需要把第一个任务和之前任务进行重新计算,可以直接找到第一个子任务的状态,用它快读恢复输出结果。甚至可以是直接把输出结果保存到状态里,直接读取出来即可。
6.流处理引擎的技术选型
如果需要保证exactly-once或者at least once不能选择strom.且strom不能处理大量数据.
如果项目已经使用spark框架,并且实时性要求不高,选择spark streaming
满足exactly once,数据量大,高吞吐,低延迟需求,要进行状态管理和窗口统计,选择flink。
二、Flink快读应用
1、java wordcount(批处理)
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.operators.AggregateOperator;
import org.apache.flink.api.java.operators.DataSource;
import org.apache.flink.api.java.operators.FlatMapOperator;
import org.apache.flink.api.java.operators.UnsortedGrouping;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.util.Collector;public class WordCountJavaBatch {public static void main(String[] args) throws Exception {String inputPath="/Users/kelisiduofu/IdeaProjects/zhiwang/flink/src/main/resources/input/hello.txt";//结果会直接输入到这个文件中String outputPath="/Users/kelisiduofu/IdeaProjects/zhiwang/flink/src/main/resources/output";//获取flink处理批数据的运行环境ExecutionEnvironment executionEnvironment = ExecutionEnvironment.getExecutionEnvironment();//从文件读取数据:按行读取(存储的元素就是每行的文本)DataSource<String> text = executionEnvironment.readTextFile(inputPath);FlatMapOperator<String, Tuple2<String, Integer>> wordAndOnes = text.flatMap(new SplitCls());//目前数据为(hello,1)参数为二元组内的哪个元素,0就是第一个参数:word,返回值为group后的结果UnsortedGrouping<Tuple2<String, Integer>> groupWordAndOne = wordAndOnes.groupBy(0);//(hello,1)按照第二个参数进行聚合AggregateOperator<Tuple2<String, Integer>> out = groupWordAndOne.sum(1);//第2个参数:行间的分隔符,第3个参数:字段间分隔符//setParallelism:设置并行度out.writeAsCsv(outputPath,"\n","\t").setParallelism(1);executionEnvironment.execute();//必须人为调用才会运行程序}//参数<a,b> a为数据源,即每行数据. b为处理完结果的数据类型即(word,count)static class SplitCls implements FlatMapFunction<String, Tuple2<String,Integer>> {@Override //s为输出的数据的类型, Collector:将处理的结果向下游算子发送的对象public void flatMap(String s, Collector<Tuple2<String, Integer>> collector) throws Exception {String[] words=s.split("\\s+");for(String word : words){collector.collect(new Tuple2<String,Integer>(word,1));//将结果发送到下游}}}
}