大家好,我是半虹,这篇文章来讲分词算法
1 概述
分词是自然语言处理领域中的基础任务,是文本预处理的重要步骤
简单来说,就是将文本段落分解为基本语言单位,亦可称之为词元 ( token\text{token}token )
按照粒度的不同,可以细分为:字、词、子词等
我们知道,自然语言是十分典型的非结构化数据,机器是无法直接识别出来的
通过分词,自然语言可以转化为有限的词元组合,结合词表就可以将其表示为结构化的数据
这样机器才可以接收自然语言为输入,才有后续的各种模型的处理
对于分词的研究目前已经十分地成熟,按照类型的不同可以细分为:词典匹配、统计模型、深度学习等
虽然这些方法都可以达到很好的效果,但是仍然有一些难点要考虑:
-
分词粒度:分词没有唯一的标准,不同场景对分词粒度的要求也不同
例如苹果手机,既可以将其切分为苹果和手机两个词,也可以将其作为一个词
-
歧义切分:有些时候不同的切分会导致不同的含义,而且有可能都是合理的
例如这文章我写不好,既可以是这文章 / 我写不好,也可以是这文章 / 我写 / 不好
-
未登录词:在这信息爆炸的时代,互联网上很经常会出现一些新的词
例如不明觉厉,怎么才能识别出这些新兴词语也是个难点
下面我们将会从不同的类型来讲一些目前常用的分词算法
下篇文章才会从不同的粒度去将另外一些常用的分词算法(由于篇幅原因,不得不分开两篇文章
2 按类型划分
分词算法按照类型可以分为以下三类:
- 基于词典匹配的分词算法,例如:最大匹配算法、最短路径算法
- 基于统计模型的分词算法,例如:N-gram model\text{N-gram model}N-gram model、HMM\text{HMM}HMM、CRF\text{CRF}CRF
- 基于深度学习的分词算法,例如:LSTM + CRF\text{LSTM + CRF}LSTM + CRF
2.1 基于词典匹配
基于词典匹配的分词算法,其目标为:根据输入的文本和给定的词典,返回对文本分词后的结果
所谓词典实际上就是常用词元的集合,算法通过将输入的文本与词典来匹配从而将其切分为词元
此类方法必须要事先准备好一个词典,至于词典怎么来和词典怎么用,正是需要考虑的关键问题
先说词典怎么来,这对分词算法的最终效果影响很大,因为对输入文本切分得到的词元必定是在词典中的
但是词典怎么来并不是此类方法的研究重点,较常见的做法是用简单的工具从大规模训练语料中提取得到
再说词典怎么用,基于词典匹配的分词算法,顾名思义,就是用特定的规则,将输入文本与词典进行匹配
从而将输入文本切分为词典当中的词元达到分词的目标,目前经过长时间的研究已有很多成熟的匹配方法
基于其基本设计,这类方法有直观的优缺点:
-
从一方面说,可以很方便通过增删词典内容来调整分词结果
另一方面说,太过于依赖词典导致其对未登陆词的处理欠佳
-
如果词典中的词元有公共子串,可能会出现歧义切分的问题
下面会具体介绍,各种基于词典匹配的算法
2.1.1 最大匹配算法
该算法的核心思想如下:对于输入文本,从左端或右端开始,以贪心的思想,匹配词典中可匹配的最长词元
- 若从文本左端开始进行匹配,则称为正向最大匹配算法
- 若从文本右端开始进行匹配,则称为逆向最大匹配算法
- 若同时从两端开始进行匹配,则称为双向最大匹配算法
大家有没有想过为什么匹配方式是最大匹配,而非最小匹配呢
这是因为一般来说越长的词语所表达的语义是越明确且丰富的
正向最大匹配算法的步骤如下:
- 给定一段输入文本,找到以文本左端第一个字为开头的且存在于词典中的最长匹配文本
- 将该文本切分出来,并将剩余文本作为新的输入文本,重复上述步骤,直到输入文本被全部切分
逆向最大匹配算法的步骤如下:
- 给定一段输入文本,找到以文本右端第一个字为结尾的且存在于词典中的最长匹配文本
- 将该文本切分出来,并将剩余文本作为新的输入文本,重复上述步骤,直到输入文本被全部切分
那么怎么找到最长匹配文本呢?最简单的方法就是纯暴力搜索,下面通过一个例子进行说明
假设输入文本如下:南京市长江大桥
假设给定词典如下:南、京、市、长、江、大、桥、南京、市长、长江、大桥、南京市、江大桥(人名)
正向匹配算法如下:
-
未匹配文本为 南京市长江大桥 因此要找以南字开头的最长匹配词元
第一步,判断 南京市长江大桥 是否存在于词典,显然不在
第二步,判断 南京市长江大 是否存在于词典,显然不在
第三步,判断 南京市长江 是否存在于词典,显然不在
第四步,判断 南京市长 是否存在于词典,显然不在
第五步,判断 南京市 是否存在于词典,此时符合,因此将该文段切分作为词元
-
未匹配文本为 长江大桥 因此要找以长字开头的最长匹配词元
第一步,判断 长江大桥 是否存在于词典,显然不在
第二步,判断 长江大 是否存在于词典,显然不在
第三步,判断 长江 是否存在于词典,此时符合,因此将该文段切分作为词元
-
未匹配文本为 大桥 因此要找以大字开头的最长匹配词元
第一步,判断 大桥 是否存在于词典,此时符合,因此将该文段切分作为词元
-
故分词结果为 南京市 / 长江 / 大桥
逆向匹配算法如下:
-
未匹配文本为 南京市长江大桥 因此要找以桥字结尾的最长匹配词元
第一步,判断 南京市长江大桥 是否存在于词典,显然不在
第二步,判断 京市长江大桥 是否存在于词典,显然不在
第三步,判断 市长江大桥 是否存在于词典,显然不在
第四步,判断 长江大桥 是否存在于词典,显然不在
第五步,判断 江大桥 是否存在于词典,此时符合,因此将该文段切分作为词元
-
未匹配文本为 南京市长 因此要找以长字结尾的最长匹配词元
第一步,判断 南京市长 是否存在于词典,显然不在
第二步,判断 京市长 是否存在于词典,显然不在
第三步,判断 市长 是否存在于词典,此时符合,因此将该文段切分作为词元
-
未匹配文本为 南京 因此要找以京字结尾的最长匹配词元
第一步,判断 南京 是否存在于词典,此时符合,因此将该文段切分作为词元
-
故分词结果为 南京 / 市长 / 江大桥
但纯暴力搜索时间效率比较差,可以利用字典树对其进行优化,主要的思路如下:
-
将词典构造成一棵字典树,所谓字典树就是一种数据结构,能减少存储空间、加快查找速度
字典树的根节点不包含任何信息,其余节点是词元的公共前缀
从根节点到其余节点的路径表示由路径上的字连接而成的词元
-
当进行匹配时,本质上是查找字典树中的一条路径,因此使用普通的树节点查找算法就可以
如果用上面的例子来说明,正向匹配算法的字典树和匹配过程如下:

-
未匹配文本为南京市长江大桥,因此要找以南字开头的最长匹配词元
第一步,查找最开始根节点的子节点,找到南节点,此时匹配南
第二步,查找上一步南节点的子节点,找到京节点,此时匹配南京
第三步,查找上一步京节点的子节点,找到市节点,此时匹配南京市
第四步,查找上一步市节点的子节点,没有找得到,因此将上一步的文段切分作为词元
-
未匹配文本为 长江大桥,因此要找以长字开头的最长匹配词元
第一步,查找最开始根节点的子节点,找到长节点,此时匹配长
第二步,查找上一步长节点的子节点,找到江节点,此时匹配长江
第三步,查找上一步江节点的子节点,没有找得到,因此将上一步的文段切分作为词元
-
未匹配文本为 大桥,因此要找以大字开头的最长匹配词元
第一步,查找最开始根节点的子节点,找到大节点,此时匹配大
第二步,查找上一步大节点的子节点,找到桥节点,此时匹配大桥
第三步,查找上一步桥节点的子节点,没有找得到,因此将上一步的文段切分作为词元
-
故分词结果为 南京市 / 长江 / 大桥
还是用上面的例子来说明,逆向匹配算法的字典树和匹配过程如下:

-
未匹配文本为南京市长江大桥,因此要找以桥字结尾的最长匹配词元
第一步,查找最开始根节点的子节点,找到桥节点,此时匹配桥
第二步,查找上一步桥节点的子节点,找到大节点,此时匹配大桥
第三步,查找上一步大节点的子节点,找到江节点,此时匹配江大桥
第四步,查找上一步江节点的子节点,没有找得到,因此将上一步的文段切分作为词元
-
未匹配文本为南京市长 ,因此要找以长字结尾的最长匹配词元
第一步,查找最开始根节点的子节点,找到长节点,此时匹配长
第二步,查找上一步长节点的子节点,找到市节点,此时匹配市长
第三步,查找上一步市节点的子节点,没有找得到,因此将上一步的文段切分作为词元
-
未匹配文本为南京 ,因此要找以京字结尾的最长匹配词元
第一步,查找最开始根节点的子节点,找到京节点,此时匹配京
第二步,查找上一步京节点的子节点,找到南节点,此时匹配南京
第三步,查找上一步南节点的子节点,没有找得到,因此将上一步的文段切分作为词元
-
故分词结果为 南京 / 市长 / 江大桥
无论使用纯暴力搜索还是字典树,我们可以发现上述两种方法得到的分词结果是不同的
- 正向最大匹配:南京市 / 长江 / 大桥
- 逆向最大匹配:南京 / 市长 / 江大桥
双向最大匹配算法会综合考虑正向和逆向的分词结果,从而决定最终分词,其规则如下:
- 如果正向和逆向分词最终的词元数不同,那么选择词元数较少的那个结果
- 如果正向和逆向分词最终的词元数相同,那么选择单字词较少的那个结果(若一样,则随便)
2.1.2 最短路径算法
基于词典匹配的另一种算法是最短路径分词,该算法的核心思想如下:
- 首先根据词典将输入文本中的所有词元识别出来构成有向无环图,即词图
- 找到从起点到终点的最短路径作为最佳组合方式,即为分词结果
具体操作如下:
-
假设给定文本 S=c1c2...cnS = c_1c_2...c_nS=c1c2...cn,其中 cic_ici 为单个汉字,nnn 为文本长度
-
建立 n+1n + 1n+1 个节点 V0,V1,...VnV_0,\ V_1,\ ...\ V_nV0, V1, ... Vn,将这些节点作为词图中的节点
-
相邻节点 Vi−1V_{i-1}Vi−1 和 ViV_{i}Vi (1≤i≤n)(1 \le i \le n)(1≤i≤n) 之间建立有向边 Vi−1→ViV_{i-1} \rightarrow V_{i}Vi−1→Vi,此时对应的词元就是 cic_ici
-
若 w=ci...cjw = c_i...c_jw=ci...cj (0<i<j≤n)(0 \lt i \lt j \le n)(0<i<j≤n) 存在于词典,那么节点 Vi−1V_{i-1}Vi−1 和 VjV_{j}Vj 之间建立有向边 Vi−1→VjV_{i-1} \rightarrow V_{j}Vi−1→Vj
-
最后,使用 Dijkstra\text{Dijkstra}Dijkstra 算法寻找以 V0V_0V0 为起点、以 VnV_nVn 为终点的最短路径即为分词结果
一个例子如下:

当然,寻找图最短路径是很常见的问题,除了经典的 Dijkstra\text{Dijkstra}Dijkstra 算法 ,也可以用其他合适的算法
另外,根据上述的设置,词图中每条边的权重值都是 111,也可以用词频等统计信息给边赋予权重
2.2 基于统计模型
基于统计模型的分词算法,其目标为:根据输入的文本和统计信息,对文本进行分词得到词元
通常认为在一定上下文中,相邻的文字同时出现的频率或概率越大,就越有可能可以构成词元
这种信息被称为字的共现,能体现文字组合关系的紧密程度和水平,属于统计信息的其中一种
该算法通过建立统计模型从大量训练语料获取词元的各种统计信息并将这些信息用于分词预测
下面会详细介绍各种基于统计模型的分词算法
2.2.1 N-gram model
在上节提到,我们可以给词图中的边赋予权重,权重信息可以通过语言概率统计得到
该模型认为,给定输入文本,其中某个词出现的概率由之前出现的词所决定,形式化表达如下:
假设给定输入文本 S=c1c2...cnS = c_1c_2...c_nS=c1c2...cn,其中 cic_ici 为单个词元,nnn 为文本长度
该文本的出现概率:
P(S)=P(c1,c2,...,cn)P(S) = P(c_1,\ c_2,\ ...,\ c_n) P(S)=P(c1, c2, ..., cn)
根据条件概率公式:
P(S)=P(c1)⋅P(c2∣c1)⋅P(c3∣c1,c2)⋅⋯⋅P(cn∣c1,c2,...,cn−1)P(S) = P(c_1) \cdot P(c_2|c_1) \cdot P(c_3|c_1, c_2) \cdot \cdots \cdot P(c_n|c_1, c_2, ..., c_{n-1}) P(S)=P(c1)⋅P(c2∣c1)⋅P(c3∣c1,c2)⋅⋯⋅P(cn∣c1,c2,...,cn−1)
可见,第 nnn 个词 cnc_ncn 出现的概率取决于前 n−1n - 1n−1 个词 c1,c2,...,cn−1c_1,\ c_2,\ ...,\ c_{n-1}c1, c2, ..., cn−1
然而这种方式的计算复杂度太高,因此需要引入马尔可夫假设近似上式计算
马尔科夫假设认为:某个词出现的概率只取决于之前有限个词
假如某个词出现的概率只取决于前面一个词,那么该模型称为二元模型,即 2-gram2\text{-gram}2-gram 语言模型
上述的计算公式可改写为:
P(S)=P(c1)⋅P(c2∣c1)⋅P(c3∣c2)⋅⋯⋅P(cn∣cn−1)P(S) = P(c_1) \cdot P(c_2|c_1) \cdot P(c_3|c_2) \cdot \cdots \cdot P(c_n|c_{n-1}) P(S)=P(c1)⋅P(c2∣c1)⋅P(c3∣c2)⋅⋯⋅P(cn∣cn−1)
假如某个词出现的概率只取决于前面两个词,那么该模型称为三元模型,即 3-gram3\text{-gram}3-gram 语言模型
上述的计算公式可改写为:
P(S)=P(c1)⋅P(c2∣c1)⋅P(c3∣c1,c2)⋅⋯⋅P(cn∣cn−2,cn−1)P(S) = P(c_1) \cdot P(c_2|c_1) \cdot P(c_3|c_1, c_2) \cdot \cdots \cdot P(c_n|c_{n-2}, c_{n-1}) P(S)=P(c1)⋅P(c2∣c1)⋅P(c3∣c1,c2)⋅⋯⋅P(cn∣cn−2,cn−1)
以此类推,这些模型被称为: n-gram modeln\text{-gram model}n-gram model,可用于建模在上下文语境中词元出现的概率
我们可以用这些统计概率给词图的边赋予权重,示意图如下:

加权词图中存在许多从起点到终点的路径,例如:
- P(南京市长江大桥)=P(南∣S)⋅P(京∣南)⋅P(市∣京)⋅P(长∣市)⋅P(江∣长)⋅P(大∣江)⋅P(桥∣大)P(南京市长江大桥) = P(南|S) \cdot P(京|南) \cdot P(市|京) \cdot P(长|市) \cdot P(江|长) \cdot P(大|江) \cdot P(桥|大)P(南京市长江大桥)=P(南∣S)⋅P(京∣南)⋅P(市∣京)⋅P(长∣市)⋅P(江∣长)⋅P(大∣江)⋅P(桥∣大)
- P(南京市长江大桥)=P(南京市∣S)⋅P(长江∣南京市)⋅P(大桥∣长江)P(南京市长江大桥) = P(南京市|S) \cdot P(长江|南京市) \cdot P(大桥|长江)P(南京市长江大桥)=P(南京市∣S)⋅P(长江∣南京市)⋅P(大桥∣长江)
- …
找出其中使输入文本出现概率最大的路径,即为最佳分词组合
**那么上述的这些条件概率需要怎么计算呢?**这里会以条件概率 P(ci∣ci−1)P(c_{i}|c_{i-1})P(ci∣ci−1) 为例进行说明
首先条件概率等于联合概率除以边缘概率:
P(ci∣ci−1)=P(ci,ci−1)P(ci−1)P(c_{i}|c_{i-1}) = \frac{P(c_{i},c_{i-1})}{P(c_{i-1})} P(ci∣ci−1)=P(ci−1)P(ci,ci−1)
联合概率只需统计 ci−1,c1c_{i-1},c_{1}ci−1,c1 在训练语料中前后相邻出现的频率即可,具体是用出现次数除以语料大小
P(ci,ci−1)=#(ci,ci−1)#P(c_{i},c_{i-1}) = \frac{\#(c_{i},c_{i-1})}{\#} P(ci,ci−1)=##(ci,ci−1)
边缘概率则是统计 ci−1c_{i-1}ci−1 在训练语料中自己单独出现的频率即可,仍然是用出现次数除以语料大小
P(ci−1)=#(ci−1)#P(c_{i-1}) = \frac{\#(c_{i-1})}{\#} P(ci−1)=##(ci−1)
最后化简可以得到 :
P(ci∣ci−1)=#(ci,ci−1)#(ci−1)P(c_{i}|c_{i-1}) = \frac{\#(c_{i},c_{i-1})}{\#(c_{i-1})} P(ci∣ci−1)=#(ci−1)#(ci,ci−1)
2.2.2 HMM
HMM\text{HMM}HMM 全称为 Hidden Markov Model\textbf{H}\text{idden}\ \textbf{M}\text{arkov}\ \textbf{M}\text{odel}Hidden Markov Model,翻译为:隐马尔可夫模型
隐马尔可夫模型是目前应用广泛的分词模型之一,它将分词问题看作是序列标注任务
所谓的序列标注就是说给定任意的一段输入序列,要求模型返回该序列中每个元素的状态标签
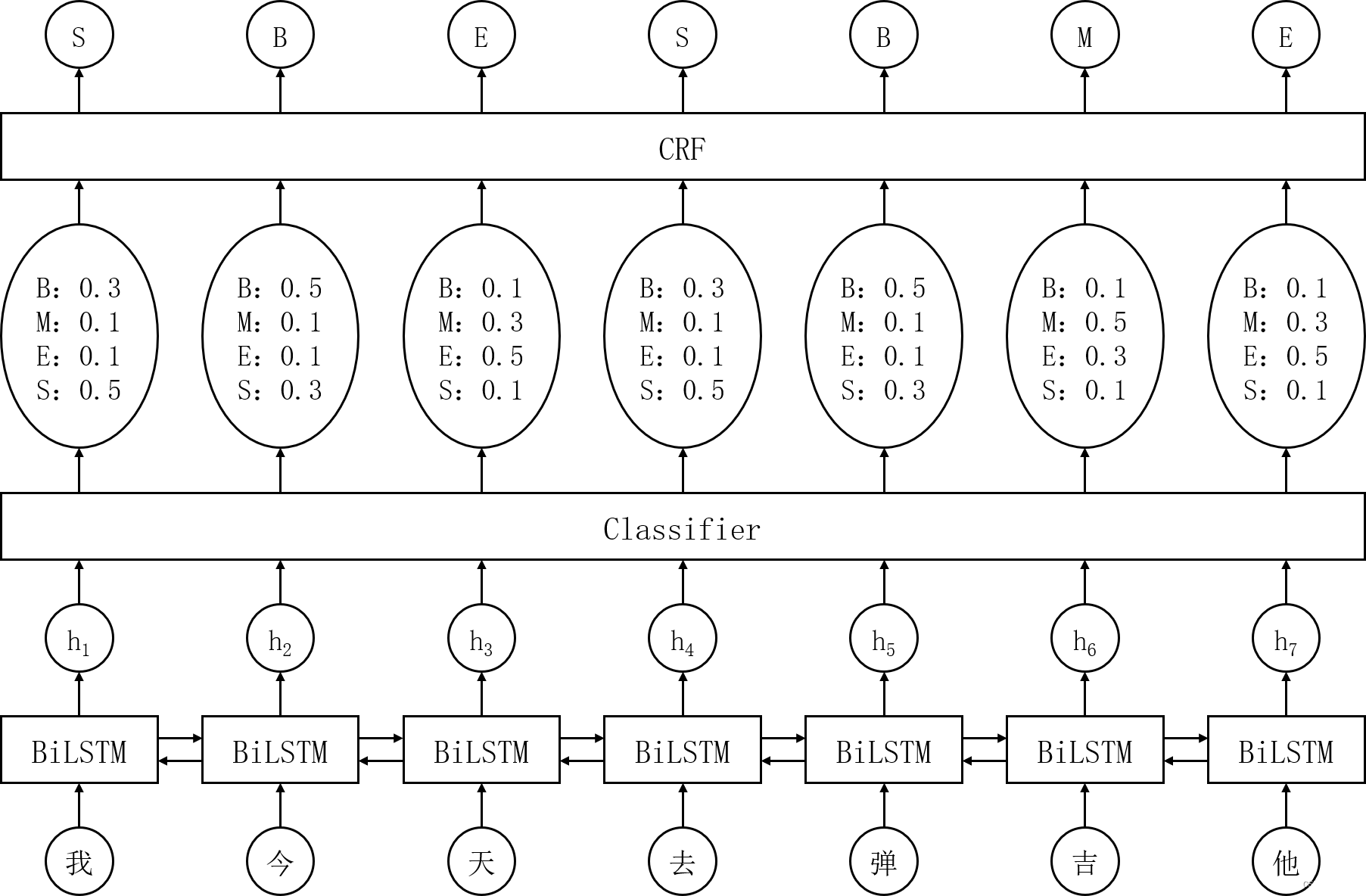
文本序列分词所定义的状态标签总共有以下四种:
B(Begin):表示该文字是某个词语的开头,此时无需对其进行切分M(Middle):表示该文字是某个词语的中间,此时无需对其进行切分E(End):表示该文字是某个词语的结尾,此时要对该词进行切分S(Single):表示该文字是作为单个字存在,此时要对该字进行切分
根据以上的描述,只要能推理出文本序列的标签,就能对该文本进行分词
下面是一个例子:

隐马尔可夫模型用于文本序列分词时包含两个关键的序列:
- 文本序列:作为模型的输入,即人们显式看到的句子,又称为观测序列
- 状态序列:作为模型的输出,即人们不能看到的因素,又称为隐藏序列
上述隐藏序列又称为马尔可夫链,即当前状态的概率分布只由上一状态决定(一阶)
隐马尔可夫模型认为观测序列是由隐藏序列对应生成的,对应的概率图如下:

由于隐藏序列是人们不可观察的,所以要通过观测序列来推理得到隐藏序列
若从数学上理解,假设观测序列为 XXX,隐藏序列为 YYY,隐马尔可夫模型实际上是一个生成式模型
因为生成式模型会认为输出 YYY 按照一定的规律生成输入 XXX,模型对联合概率 P(X,Y)P(X,\ Y)P(X, Y) 进行建模
在解决此类问题时,隐马尔可夫模型会有两个重要的假设:
- 齐次马尔可夫假设:隐藏的马尔可夫链在任一时刻的状态只与上一时刻的状态有关
- 观察值独立性假设:任一时刻的观测只与当前时刻的状态有关
最后来讲该模型的训练和预测过程,会有三个核心的矩阵,这些矩阵实际上就是隐马尔可夫模型的参数
- 初始概率矩阵:各个状态出现在句子开头的概率
- 转移概率矩阵:一个状态出现在另一个状态之后的概率
- 发射概率矩阵:某个状态下出现某字的概率
训练的过程就是根据给定的观测序列和隐藏序列对,通过统计来求解这三个矩阵
预测的过程就是根据给定的观测序列,应用这三个矩阵得到概率最大的隐藏序列
下面用一个例子来讲解如何求解和应用这三个矩阵,现假设给定的训练语料如下:

首先计算初始概率矩阵,先统计各个状态出现在句子开头的次数,再转化成概率矩阵就可以

然后计算转移概率矩阵,先统计一个状态出现在另一个状态之后的次数,再转化成概率矩阵就可以

最后计算发射概率矩阵,先统计某个状态下出现某字的次数,再转化成概率矩阵就可以

至此我们已经得到三个矩阵,接下来就是用这些矩阵对新输入句子中的每个文字预测其状态标签
假设现在给定一个输入句子,例如:我今天去弹吉他,显然句子中的每个文字都可能有四种状态
实际上我们需要计算所有可能的状态组合,并从中选择出概率最大的即为预测结果,示意图如下:

然而这样的纯暴力搜索方法的时间效率是非常低下的,为此我们可以使用维特比算法来进行优化
维特比算法可以理解成是动态规划算法、或贪心算法、或剪枝算法都可以
下面我们从剪枝的角度来讲维特比算法是怎么运作的,其算法的步骤如下:
-
当 “我” 的状态为
B时,到达此节点的路径有一条,保留这一条路径是:
O→B -
当 “我” 的状态为
M时,到达此节点的路径有一条,保留这一条路径是:
O→M -
当 “我” 的状态为
E时,到达此节点的路径有一条,保留这一条路径是:
O→E -
当 “我” 的状态为
S时,到达此节点的路径有一条,保留这一条路径是:
O→S -
当 “今” 的状态为
B时,达到此节点的路径有四条,保留一条最优路径,其余路径不再考虑 (剪枝)这四条路径是:
O→B→B,O→M→B,O→E→B,O→S→B设保留路径是:
O→S→B -
当 “今” 的状态为
M时,达到此节点的路径有四条,保留一条最优路径,其余路径不再考虑 (剪枝)这四条路径是:
O→B→M,O→M→M,O→E→M,O→S→M设保留路径是:
O→B→M -
当 “今” 的状态为
E时,达到此节点的路径有四条,保留一条最优路径,其余路径不再考虑 (剪枝)这四条路径是:
O→B→E,O→M→E,O→E→E,O→S→E设保留路径是:
O→B→E -
当 “今” 的状态为
S时,达到此节点的路径有四条,保留一条最优路径,其余路径不再考虑 (剪枝)这四条路径是:
O→B→S,O→M→S,O→E→S,O→S→S设保留路径是:
O→S→S -
当 “天” 的状态为
B时,达到此节点的路径有四条,保留一条最优路径,其余路径不再考虑 (剪枝)这四条路径是:
O→S→B→B,O→B→M→B,O→B→E→B,O→S→S→B设保留路径是:
O→B→E→B -
当 “天” 的状态为
M时,达到此节点的路径有四条,保留一条最优路径,其余路径不再考虑 (剪枝)这四条路径是:
O→S→B→M,O→B→M→M,O→B→E→M,O→S→S→M设保留路径是:
O→B→M→M -
…
2.2.3 CRF
CRF\text{CRF}CRF 全称为 Conditional Random Field\textbf{C}\text{onditional}\ \textbf{R}\text{andom}\ \textbf{F}\text{ield}Conditional Random Field,翻译为:条件随机场模型
条件随机场模型将分词问题看作是序列标注任务,实际上该模型可以由隐马尔可夫模型引申得到
下面从数学角度入手,横向对比隐马尔可夫模型、最大熵马尔可夫模型、条件随机场模型的异同
首先以数学角度重新来回顾一下隐马尔可夫模型,该模型的概率图如下:

为了简化运算,模型有以下假设:
- 齐次马尔可夫假设:P(yt∣y1:t−1,x1:t−1)=P(yt∣yt−1)P(y_{t}|y_{1:t-1},\ x_{1:t-1}) = P(y_{t}|y_{t-1})P(yt∣y1:t−1, x1:t−1)=P(yt∣yt−1)
- 观察值独立性假设:P(xt∣y1:t,x1:t−1)=P(xt∣yt)P(x_{t}|y_{1:t\ \ \ },\ x_{1:t-1}) = P(x_{t}|y_{t})P(xt∣y1:t , x1:t−1)=P(xt∣yt)
模型的参数包括:初始概率分布 π\piπ、转移概率矩阵 AAA、发射概率矩阵 BBB,可将其表示为 λ=(π,A,B)\lambda = (\pi,\ A,\ B)λ=(π, A, B)
模型为生成模型,其建模对象定义为联合概率分布
P(X,Y∣λ)=∏t=1TP(xt,yt∣λ)=∏t=1TP(yt∣yt−1,λ)⋅P(xt∣yt,λ)P(X,\ Y|\lambda) = \prod_{t=1}^{T} P(x_t,\ y_t|\lambda) = \prod_{t=1}^{T} P(y_t|y_{t-1}, \lambda) \cdot P(x_t|y_t, \lambda) P(X, Y∣λ)=t=1∏TP(xt, yt∣λ)=t=1∏TP(yt∣yt−1,λ)⋅P(xt∣yt,λ)
式子的前半部分 P(yt∣yt−1,λ)P(y_t|y_{t-1}, \lambda)P(yt∣yt−1,λ) 对应 转移概率矩阵,初始概率分布可以看作是转移概率矩阵的初始状态
式子的后半部分 P(xt∣yt,λ)P(x_t|y_t\ \ \ , \lambda)P(xt∣yt ,λ) 对应 发射概率矩阵
实际上,该模型的假设并不十分合理,很大程度上是为了降低计算复杂度而妥协的
以观察值独立性假设为例,每个观察值应该与整个序列有关,而不是仅与当前时刻的隐藏状态有关
最大熵马尔可夫模型打破了观察值独立性假设,模型的概率图如下:

上半部分表示整个观测序列对每个隐藏状态的影响,下半部分表示当前观测对当前隐藏状态的影响
通常来说只画上半部分或只画下半部分都是可以的,这里是为了对比方便才将二者同时画出
与隐马尔可夫模型最大的区别在于箭头方向的改变,该模型的箭头方向由观测指向隐藏状态
这说明模型更关心的是,在给定观测数据的情况下,其隐藏状态的取值
模型为判别模型,其建模对象定义为条件概率分布
P(Y∣X,λ)=∏t=1TP(yt∣yt−1,x1:T,λ)P(Y|X,\ \lambda) = \prod_{t=1}^{T} P(y_{t}|y_{t-1},\ x_{1:T},\ \lambda) P(Y∣X, λ)=t=1∏TP(yt∣yt−1, x1:T, λ)
对序列标注任务,该建模方式实际上是更有优势的,因为模型只需关心隐藏状态就可以
虽然最大熵马尔可夫模型打破了观察值独立性假设,但同时又带来了标注偏差问题
所谓标记偏差问题,简单来说,就是在状态转移时,若条件转移概率分布的熵越小,则越不关心观测值
极端的例子就是在上图虚线框,若 yt−1y_{t-1}yt−1 转移到 yty_{t}yt 时只有一条转移路径,则此时的观测值完全不起作用
根本的原因在于:上图虚线框中的局部有向图要求满足概率分布的性质,因此必须对其进行局部归一化
条件随机场模型解决了标记偏差问题,并间接了打破齐次马尔可夫假设,模型的概率图如下:

对比最大熵马尔可夫模型最大的改变在于隐藏状态从有向图变成无向图,而无向图是天然的全局归一化
我们假设 XXX 和 YYY 有相同的结构分布,此时条件随机场称为线性随机场
模型还是判别模型,建模对象还是条件概率分布
P(y∣x)=1Z(x)∑t=1Texp[∑k=1Kλkfk(yt−1,yt,x)+∑l=1Lμlsl(yt,x)]P(y|x) = \frac{1}{Z(x)} \sum_{t=1}^{T} \exp{[ \sum_{k=1}^{K} \lambda_k f_k(y_{t-1}, y_{t}, x) + \sum_{l=1}^{L} \mu_l s_l( y_{t}, x) ]} P(y∣x)=Z(x)1t=1∑Texp[k=1∑Kλkfk(yt−1,yt,x)+l=1∑Lμlsl(yt,x)]
其中,Z(x)Z(x)Z(x) 是规范化因子 ,表示对 yyy 所有可能的取值求和
另外,式子中最核心的部分是两个特征函数
-
fkf_kfk:定义在边上的特征函数,又称为转移特征函数,KKK 代表定义在该边上的特征函数的数量
这类函数只和上一节点、当前节点和输入有关,λk\lambda_kλk 表示函数对应的权重
-
sls_lsl:定义在点上的特征函数,又称为状态特征函数,LLL 代表定义在该点上的特征函数的数量
这类函数只和当前节点和输入有关,μl\mu_lμl 表示函数对应的权重
特征函数的取值只能是零或一,分别表示不满足或满足特征条件
每一个特征函数定义一个规则,对应权重定义这个规则的可信度,所有规则和可信度构成了条件概率分布
上述的参数需要通过训练语料来统计得到,之后便可利用该模型对新输入的句子进行标注和分词
最后将特征函数和可信度的分数叠加起来,选择使得整个句子得分最高的路径即为最佳分词组合

最后来总结一下 HMM 和 CRF 的区别:
-
HMM是生成模型,对联合概率分布建模,其概率图为有向图CRF是判别模型,对条件概率分布建模,其概率图为无向图 -
HMM的建立基于两个假设,即当前观测只依赖于当前状态和当前状态只依赖于上一状态CRF的建立没有这些假设,因此其特征函数的选择更多样,例如可以考虑当前词和句首词的关系
2.3 基于深度学习
基于深度学习的分词算法,还是将分词问题看作是序列标注任务,然后使用端到端的模型来进行训练
而在自然语言处理领域中,经常用循环神经网络来建模文本序列,因为它能够很好地捕捉上下文信息
长短期记忆网络是循环神经网络的变种,在一定程度上能缓解循环神经网络在训练时出现的梯度问题
在此基础上,模型一般会采用双向结构,这可以进一步增强模型的编码能力,从而提升分词预测效果
目前用于分词的深度模型通常会先用双向长短期记忆网络编码序列,然后接一个线性层用于标签预测
示意图如下:

我们可以在线性层后再接一个条件随机场,来学习标签间的状态转移,以避免一些不合理的标签组合
示意图如下:
好啦,本文到此结束,感谢您的阅读!
如果你觉得这篇文章有需要修改完善的地方,欢迎在评论区留下你宝贵的意见或者建议
如果你觉得这篇文章还不错的话,欢迎点赞、收藏、关注,你的支持是对我最大的鼓励 (/ω\)
![[Flink]概述day1第4个视频完](https://img-blog.csdnimg.cn/img_convert/f6b147431ed74c94b8b693a69e663887.png)