python基础
基础学习 自己跟着菜鸟教程看的一些基础,会java或者js的话,1个半小时就可以over
好久没更新博客了,现在慢慢来发吧,基础内容不太多,自己理解会很快的(下面是一段个人的小经历,大家也可以看看,嘻嘻)
假期看了灵魂摆渡几部电视剧,无聊中收到了一个python爬虫公开课穷,没钱只能自己蹭免费的,然后加上自己在java的安卓浏览器上的研究,进入了python爬虫的学习
所谓爬虫就是获取网络数据,进行本地应用操作,当然小的爬虫可以学习,太深的国家饭管饱(请不要入戏太深 >_< !!!)
基础笔记(可能有很多中文,主要是为了更加清晰,强迫症请去看其他的教程,谢谢)
test.py(别忘了第二个代码块的mymodule.py <_<,可能写的不全,不是太基础,其他更加基础的,就去菜鸟教程学习吧)
C:\Users\26462\Desktop\Python.md这个路径自己填个自己的文本路径测试就行,输出日志里也有一些分割线哦~
日志效果,有的没调用,自己试试吧
# -*- coding: UTF-8 -*-
# 避免中文乱码
print("中文测试")#判断1
if 6<2:print("正确")
else:print("错误")#跳过截取
list1 = ["我","是","个","极","客"]
print(list1)
print(list1[0:3:2])#类似Map数组
tinydict = {'name': 'runoob', 'code': 6734, 'dept': 'sales'}
print(tinydict)
print(tinydict.keys())
print(tinydict.values())#分割线
print("\n\n\n\n\n\n\n\n\n\n======================================================\n\n\n")#强转类型
result_=int(6.6)
print(result_)#复数
复数 = complex(0,1) #实部和虚部
print(复数)#动态解释器
print(eval("6*9*6"))#转化为数组
aTuple = (123, 'runoob', 'google', 'abc')
print(tuple(aTuple)) #将序列 s 转换为一个元组
list2 = list(aTuple)
print(list2) #将序列 s 转换为一个列表
a =123
b=666if (a in list2):print("1 - 变量 a 在给定的列表中 list 中")
else:print("1 - 变量 a 不在给定的列表中 list 中")if (b not in list2):print("2 - 变量 b 不在给定的列表中 list 中")
else:print("2 - 变量 b 在给定的列表中 list 中")#Set数组
x = set('runoob')
y = set('google')
print(x)
print("交集",x&y)
print("并集",x|y)
print("差集",x-y) #差集就是说前者里有,而后者没有的
print("补集",x^y) #互相不包括print("\n\n字典=================")
#字典
numbers = dict(_x=5, _y=0)
print('numbers =', numbers)
print(type(numbers))empty = dict()
print('empty =', empty)
print(type(empty))# zip() 创建可迭代对象
numbers3 = dict(zip(['x', 'y', 'z'], [1, 2, 3]))
print('numbers3 =',numbers3)#分割线
print("\n\n\n\n\n\n\n\n\n\n运算======================================================\n\n\n")
print(2 ** 3) #取幂: 2的3次方
print(19%2)#取模: 19/2=9......1
print(19//2)#取整除 - 返回商的整数部分(向下取整)
print(-19//2)#取整除 - 返回商的整数部分(向下取整)#分割线
print("\n\n\n\n\n\n\n\n\n\n条件和循环======================================================\n\n\n")
print(1<=2&2<4)count = 0
while (count < 9):print('The count is:', count)count+=1print("Good bye!")#-------------------------------------发现python里的end/{}就是根据 最近的缩进 来判定的#以上的无限循环你可以使用 CTRL+C 来中断循环。for letter in 'Python': # 第一个实例print("当前字母: %s" % letter)fruits = ['banana', 'apple', 'mango']
for fruit in fruits: # 第二个实例print('当前水果: %s' % fruit)print("Good bye!")
print( r'\n')list = [] ## 空列表
list.append('Google') ## 使用 append() 添加元素
list.append('Runoob')
del list[1]
print(list)#新的数组
list = ['Hi!'] * 4 #同一个元素,在列表里添加多次
print(list)length = len(list) #返回数组的长度
print("当前数组的长度:%d 输出成功!"%length)print("统计 Hi! 元素在列表中出现的次数,为%d次"%list.count("Hi!")) #必须是某一个对应元素,直接是 Hi 查不到,返回0list2 =["测试新数组"]*6
list2.remove('测试新数组') #移除第一个匹配项
del list[1] #移除某个序号的元素
list.extend(list2) #将list2叠加到list里,合并数组
list.reverse()
# 反向列表中元素print(list)#分割线
print("\n\n\n\n\n\n\n\n\n\n定义函数库的引入======================================================\n\n\n")import time as 时间当前时间 = 时间.localtime(时间.time())localtime = 时间.asctime(当前时间)
print(localtime) #直接获取# 格式化成2023-01-10 18:47:20形式
time1 = 时间.strftime("当前时间%Y-%m-%d %H:%M:%S is %j day in a new year \n\n==>当前时间: %X %Z %Y %x" , 时间.localtime())
print(time1) #转化格式print("\n\n\n")
import calendar as 日历
print(time1+"获取本月的日历:-----------------------------")
cal = 日历.month(int(时间.strftime("%Y",时间.localtime())), int(时间.strftime("%m",时间.localtime())))
print(cal)# 定义函数
def printme( str ):print(str)return
printme( str= "打印任何传入的字符串")#定义模块 module
import mymodule
mymodule.测试("牛逼666")print(mymodule.get(10, 20))#分割线
print("\n\n\n\n\n\n\n\n\n\nIO流======================================================\n\n\n")#获取控制台输入内容,并返回
# str = input("请输入:")
# print("你输入的内容是: ", str)#读取
# fileName = "C:\\Users\\26462\\Desktop\\新建文本文档 (2).txt"
# fo = open(fileName,"r+")
# print("文件内容:",fo)
# print(fo.name)
# print("是否已关闭 : ", fo.closed)
# print("访问模式 : ", fo.mode)
# #读
# str = fo.read(6)
#
# # 查找当前位置
# position = fo.tell()
# print("当前文件位置 : ", position)
#
# # 把指针再次重新定位到文件开头
# position = fo.seek(2)
# str = fo.read(4)
# print("重新读取字符串 : ", str)
#
# print(str)
#
#
#
#
#
# # 关闭打开的文件
# fo.close()import os
# os.rename(fileName,"C:\\Users\\26462\\Desktop\\Python重命名.md")
# print("是否已关闭 : ", fo.closed)str1 = "Python666啊"
# os.remove("C:\\Users\\26462\\Desktop\\Python重命名.md")
# os.mkdir("文件夹") #在当前目录下创建文件夹
# os.chdir("newdir") #修改当前文件夹名字
print(os.getcwd()) # 给出当前的目录fo = open("C:\\Users\\26462\\Desktop\\Python重命名.md","w+",2048,"utf-8")
fo.write(str1)
print("当前目录:",fo.tell())
fo.close()#自定义异常 raise Networkerror("Bad hostname") 调用
class Networkerror(RuntimeError):def __init__(self, arg):self.args = argtry:fh = open("C:\\Users\\26462\\Desktop\\Python.md","r+",2048,"utf-8")try:fh.write("这是一个测试文件,用于测试异常!!")finally:fh.close()print("文件流操作已关闭")
except IOError:print("Error: 没有找到文件或读取文件失败")
else:print("写入成功!")# print()#分割线
print("\n\n\n\n\n\n\n\n\n\n面向对象======================================================\n\n\n")
# 创建类
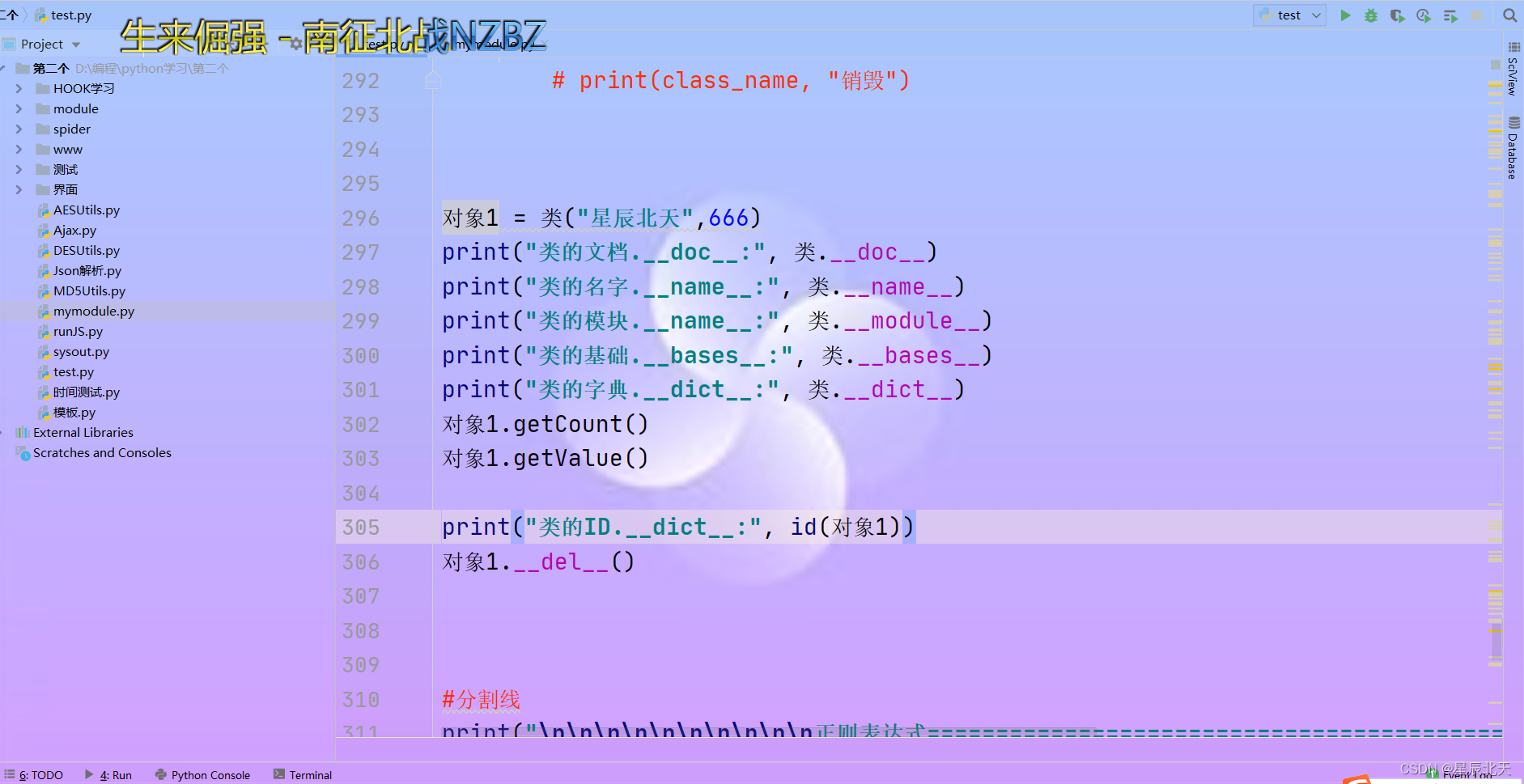
class 类:'这是一个自定义的类'count = 0 #记录当前序号def __init__(self,name,value):self.name = nameself.value = value类.count +=1def getCount(self):print(self.name+"当前序号:"+str(类.count))return countdef getValue(self):print(self.name+"当前值:"+str(self.value))return self.valuedef __del__(self):class_name = self.__class__.__name__# print(class_name, "销毁")对象1 = 类("星辰北天",666)
print("类的文档.__doc__:", 类.__doc__)
print("类的名字.__name__:", 类.__name__)
print("类的模块.__name__:", 类.__module__)
print("类的基础.__bases__:", 类.__bases__)
print("类的字典.__dict__:", 类.__dict__)
对象1.getCount()
对象1.getValue()print("类的ID.__dict__:", id(对象1))
对象1.__del__()#分割线
print("\n\n\n\n\n\n\n\n\n\n正则表达式======================================================\n\n\n")#正则表达式
import reprint(re.match('www', 'www.runoob.com').span()) # 在起始位置匹配
print(re.match('com', 'www.runoob.com')) # 不在起始位置匹配line = "Cats are smarter than dogs"matchObj = re.match(r'(.*) are (.*?) .*', line, re.M | re.I)if matchObj:print("matchObj.group() : ", matchObj.group())print("matchObj.group(1) : ", matchObj.group(1))print("matchObj.group(2) : ", matchObj.group(2))
else:print("No match!!")print(re.search('www', 'www.runoob.com').span()) # 在起始位置匹配
print(re.search('com', 'www.runoob.com').span()) # 不在起始位置匹配# re.match只匹配字符串的开始,如果字符串开始不符合正则表达式,则匹配失败,函数返回None;而re.search匹配整个字符串,直到找到一个匹配。mymodule.py
def 测试(str):print("回调:"+str)returndef get(a,b):return "回调:"+str(a*b)