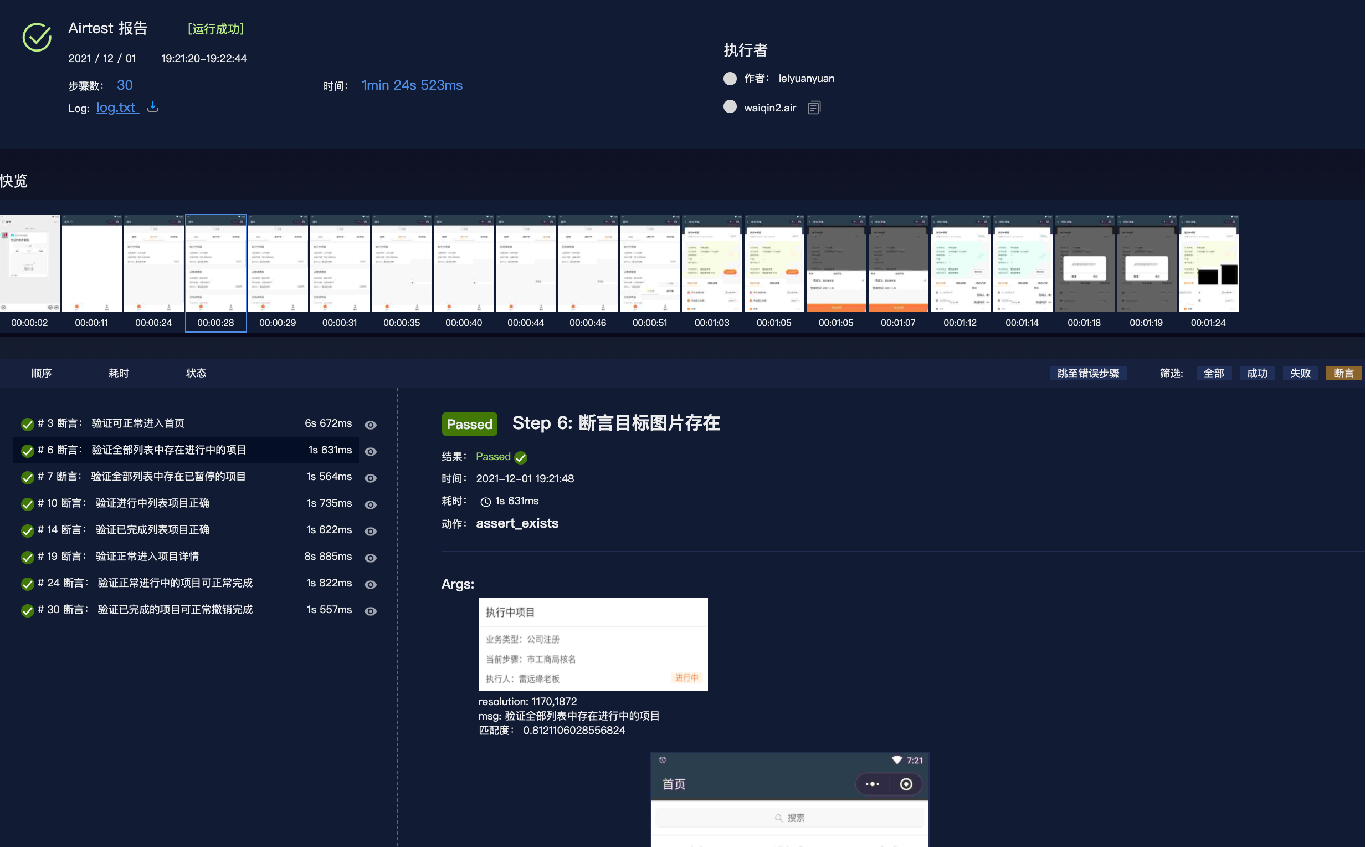
缓存是一种临时存储少量数据至内存或者是磁盘的一种技术.减少数据的加载次数,可以降低工作量,提高程序响应速度
缓存的重要性是不言而喻的。mybatis的缓存将相同查询条件的SQL语句执行一遍后所得到的结果存在内存或者某种缓存介质当中,当下次遇到一模一样的查询SQL时候不在执行SQL与数据库交互,而是直接从缓存中获取结果,减少服务器的压力;尤其是在查询越多、缓存命中率越高的情况下,使用缓存对性能的提高更明显。
MyBatis允许使用缓存,缓存一般放置在高速读/写的存储器上,比如服务器的内存,能够有效的提高系统性能。MyBatis分为一级缓存和二级缓存,同时也可配置关于缓存设置。
一级存储是SqlSession上的缓存,二级缓存是在SqlSessionFactory(namespace)上的缓存。默认情况下,MyBatis开启一级缓存,没有开启二级缓存。当数据量大的时候可以借助一些第三方缓存框架或Redis缓存来协助保存Mybatis的二级缓存数据。
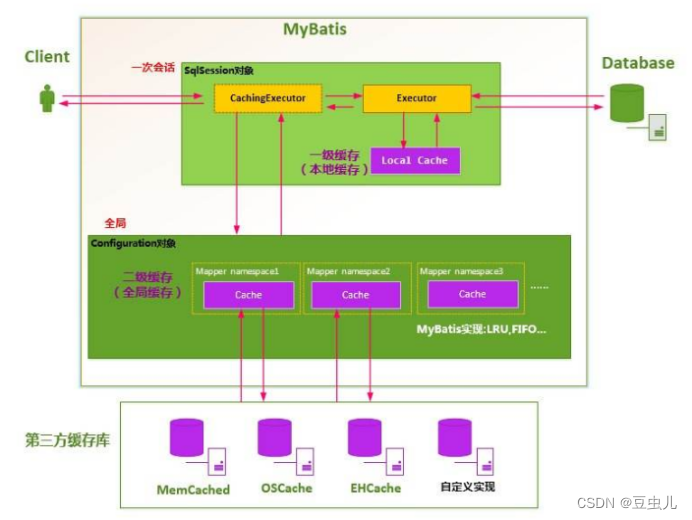
1. 一级缓存
一级存储是SqlSession上的缓存(使用同一个SqlSession),默认开启,是一种内存型缓存,不要求实体类对象实现Serializable接口,相同的sql语句执行一次后会将结果保存在sqlsession的缓存区中,下一次执行同一个sqlsession下的sql语句是时则不再重新执行SQL语句,而是从缓存中获取数据。
缓存中的数据使用键值(key-value)对形式存储数据,namespace+sqlid+args(参数)+offset>>> hash值作为键,查询出的结果作为值,如果中间发生了增删改或者是调用了SqlSession调用了commit,会自动清空缓存,以防止数据不一致的情况.
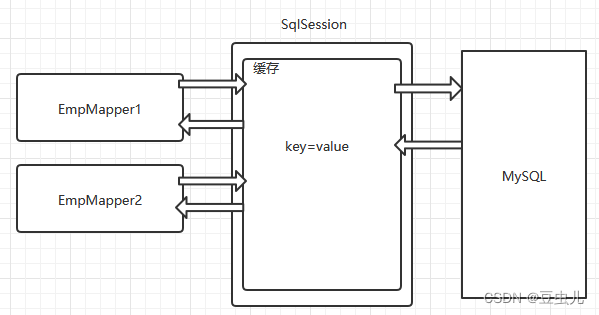
@Test
public void testFindDeptByDetpno() {EmpMapper mapper = sqlSession.getMapper(EmpMapper.class);Emp emp = mapper.findByEmpno(7521);System.out.println(emp);// 中间发生了增删改或者是调用了SqlSession调用了commit,会自动清空缓存sqlSession.commit();// 增删改的时候调用EmpMapper mapper2 = sqlSession.getMapper(EmpMapper.class);Emp emp2 = mapper2.findByEmpno(7521);System.out.println(emp2);System.out.println(emp==emp2);System.out.println(mapper==mapper2);}
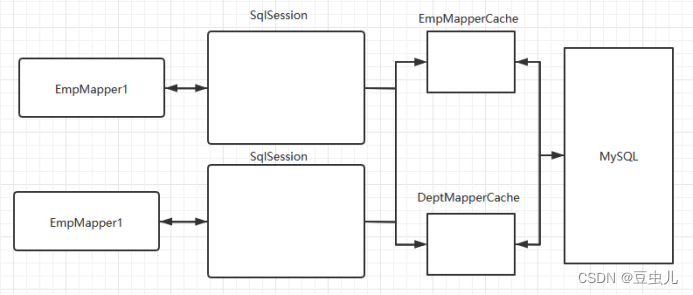
1.2 二级缓存
二级缓存是以namespace为标记的缓存,可以是由一个SqlSessionFactory创建的多个SqlSession之间共享缓存数据(每个sqlsession对应一个缓存区)。默认并不开启。下面的代码中创建了两个SqlSession,执行相同的SQL语句,尝试让第二个SqlSession使用第一个SqlSession查询后缓存的数据。要求实体类必须实现序列化接口
接口:
public interface EmpMapper {Emp findByEmpno(int empno);
}映射文件:
<mapper namespace="com.msb.mapper.EmpMapper"><cache/><select id="findByEmpno" resultType="emp" useCache="true" flushCache="false">select * from emp where empno =#{empno}</select></mapper>
测试代码:
package com.msb.test;import com.msb.mapper.EmpMapper;
import com.msb.pojo.Emp;
import org.apache.ibatis.io.Resources;
import org.apache.ibatis.session.SqlSession;
import org.apache.ibatis.session.SqlSessionFactory;
import org.apache.ibatis.session.SqlSessionFactoryBuilder;
import org.junit.After;
import org.junit.Before;
import org.junit.Test;import java.io.IOException;
import java.io.InputStream;/*** @Author: Ma HaiYang* @Description: MircoMessage:Mark_7001*/
public class Test3 {private SqlSession sqlSession;private SqlSession sqlSession2;@Beforepublic void init(){SqlSessionFactoryBuilder ssfb =new SqlSessionFactoryBuilder();InputStream resourceAsStream = null;try {resourceAsStream = Resources.getResourceAsStream("sqlMapConfig.xml");} catch (IOException e) {e.printStackTrace();}SqlSessionFactory factory=ssfb.build(resourceAsStream) ;sqlSession=factory.openSession();sqlSession2=factory.openSession();}@Testpublic void testFindDeptByDetpno() {EmpMapper mapper = sqlSession.getMapper(EmpMapper.class);Emp emp = mapper.findByEmpno(7521);System.out.println(emp);// SqlSession提交之后,才会将查询的结果放入二级缓存sqlSession.commit();EmpMapper mapper2 = sqlSession2.getMapper(EmpMapper.class);Emp emp2 = mapper2.findByEmpno(7521);System.out.println(emp2);}@Afterpublic void release(){// 关闭SQLSessionsqlSession.close();sqlSession2.close();}}
注意其中的commit(),执行该命令后才会将该SqlSession的查询结果从一级缓存中放入二级缓存,供其他SqlSession使用。另外执行SqlSession的close()也会将该SqlSession的查询结果从一级缓存中放入二级缓存。两种方式区别在当前SqlSession是否关闭了。
执行结果显示进行了两次对数据库的SQL查询,说明二级缓存并没有开启。需要进行如下步骤完成开启。
1.全局开关:在sqlMapConfig.xml文件中的<settings>标签配置开启二级缓存
<settings><setting name="cacheEnabled" value="true"/>
</settings>cacheEnabled的默认值就是true,所以这步的设置可以省略。
2.分开关:在要开启二级缓存的mapper文件中开启缓存:
<mapper namespace="com.msb.mapper.EmployeeMapper"><cache/>
</mapper>3.二级缓存未必完全使用内存,有可能占用硬盘存储,缓存中存储的JavaBean对象必须实现序列化接口
public class Emp implements Serializable { }经过设置后,查询结果如图所示。发现第一个SqlSession会首先去二级缓存中查找,如果不存在,就查询数据库,在commit()或者close()的时候将数据放入到二级缓存。第二个SqlSession执行相同SQL语句查询时就直接从二级缓存中获取了。
注意:
- MyBatis的二级缓存的缓存介质有多种多样,而并不一定是在内存中,所以需要对JavaBean对象实现序列化接口。
- 二级缓存是以 namespace 为单位的,不同 namespace 下的操作互不影响
- 加入Cache元素后,会对相应命名空间所有的select元素查询结果进行缓存,而其中的insert、update、delete在操作是会清空整个namespace的缓存。
- cache 有一些可选的属性 type, eviction, flushInterval, size, readOnly, blocking。
<cache type="" readOnly="" eviction=""flushInterval=""size=""blocking=""/>| 属性 | 含义 | 默认值 |
| type | 自定义缓存类,要求实现org.apache.ibatis.cache.Cache接口 | null |
| readOnly | 是否只读 true:给所有调用者返回缓存对象的相同实例。因此这些对象不能被修改。这提供了很重要的性能优势。 false:会返回缓存对象的拷贝(通过序列化) 。这会慢一些,但是安全 | false |
| eviction | 缓存策略 LRU(默认) – 最近最少使用:移除最长时间不被使用的对象。 FIFO – 先进先出:按对象进入缓存的顺序来移除它们。 SOFT – 软引用:基于垃圾回收器状态和软引用规则移除对象。 WEAK – 弱引用:更积极地基于垃圾收集器状态和弱引用规则移除对象。 | LRU |
| flushInterval | 刷新间隔,毫秒为单位。默认为null,也就是没有刷新间隔,只有执行update、insert、delete语句才会刷新 | null |
| size | 缓存对象个数 | 1024 |
| blocking | 是否使用阻塞性缓存BlockingCache true:在查询缓存时锁住对应的Key,如果缓存命中了则会释放对应的锁,否则会在查询数据库以后再释放锁,保证只有一个线程到数据库中查找指定key对应的数据 false:不使用阻塞性缓存,性能更好 | false |
5.如果在加入Cache元素的前提下让个别select 元素不使用缓存,可以使用useCache属性,设置为false。useCache控制当前sql语句是否启用缓存 flushCache控制当前sql执行一次后是否刷新缓存,如果刷新了,则会清空缓存区内容,导致二级缓存失效
| <select id="findByEmpno" resultType="emp" useCache="true" flushCache="false"> |
1.3 三方缓存
分布式缓存框架:我们系统为了提高系统并发 和性能,一般对系统进行分布式部署(集群部署方式)不适用分布缓存, 缓存的数据在各个服务单独存储,不方便系统开发。所以要使用分布式缓存对缓存数据进行集中管理.ehcache,redis ,memcache缓存框架。
Ehcache:是一种广泛使用的开源java分布式缓存。主要面向通用缓存,javaEE 和 轻量级容器。它具有内存和磁盘存储功能。被用于大型复杂分布式web application的
这里的三方缓存是作用于二级缓存使用的
导入依赖的jar文件
<dependency><groupId>org.mybatis.caches</groupId><artifactId>mybatis-ehcache</artifactId><version>1.0.2</version>
</dependency>
<dependency><groupId>net.sf.ehcache</groupId><artifactId>ehcache</artifactId><version>2.10.1</version>
</dependency><dependency><groupId>org.slf4j</groupId><artifactId>slf4j-nop</artifactId><version>1.7.2</version>
</dependency>去各自的sql映射文件里,开启二级缓存,并把缓存类型指定为EhcacheCache
<cache type="org.mybatis.caches.ehcache.EhcacheCache"/>
在资源目录下放置一个缓存配置文件,文件名为: ehcache.xml 内容如下
<?xml version="1.0" encoding="UTF-8"?>
<ehcache xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:noNamespaceSchemaLocation="ehcache.xsd"updateCheck="true" monitoring="autodetect"dynamicConfig="true"><diskStore path="D:\msb\ehcache" /><defaultCachemaxElementsInMemory="1000"maxElementsOnDisk="10000000"eternal="false"overflowToDisk="true"timeToIdleSeconds="120"timeToLiveSeconds="120"diskExpiryThreadIntervalSeconds="120"memoryStoreEvictionPolicy="LRU"></defaultCache></ehcache><!-- Cache配置· name:Cache的唯一标识· maxElementsInMemory:内存中最大缓存对象数。· maxElementsOnDisk:磁盘中最大缓存对象数,若是0表示无穷大。· eternal:Element是否永久有效,一但设置了,timeout将不起作用。· overflowToDisk:配置此属性,当内存中Element数量达到maxElementsInMemory时,Ehcache将会Element写到磁盘中。· timeToIdleSeconds:设置Element在失效前的允许闲置时间。仅当element不是永久有效时使用,可选属性,默认值是0,也就是可闲置时间无穷大。· timeToLiveSeconds:设置Element在失效前允许存活时间。最大时间介于创建时间和失效时间之间。仅当element不是永久有效时使用,默认是0.,也就是element存活时间无穷大。· diskExpiryThreadIntervalSeconds:磁盘失效线程运行时间间隔,默认是120秒。· diskSpoolBufferSizeMB:这个参数设置DiskStore(磁盘缓存)的缓存区大小。默认是30MB。每个Cache都应该有自己的一个缓冲区。· memoryStoreEvictionPolicy:当达到maxElementsInMemory限制时,Ehcache将会根据指定的策略去清理内存。默认策略是LRU(最近最少使用)。你可以设置为FIFO(先进先出)或是LFU(较少使用)。 -->