title: Spark系列
第六章 Spark应用程序运行机制
6.1 Spark的基本运行流程
Spark任务的核心执行流程主要分为四大步骤:
Driver工作:Build DAG
DAGScheduler工作:Split DAG to Stage
TaskScheduler工作:Change Stage to TaskSet
Worker工作:execute Task
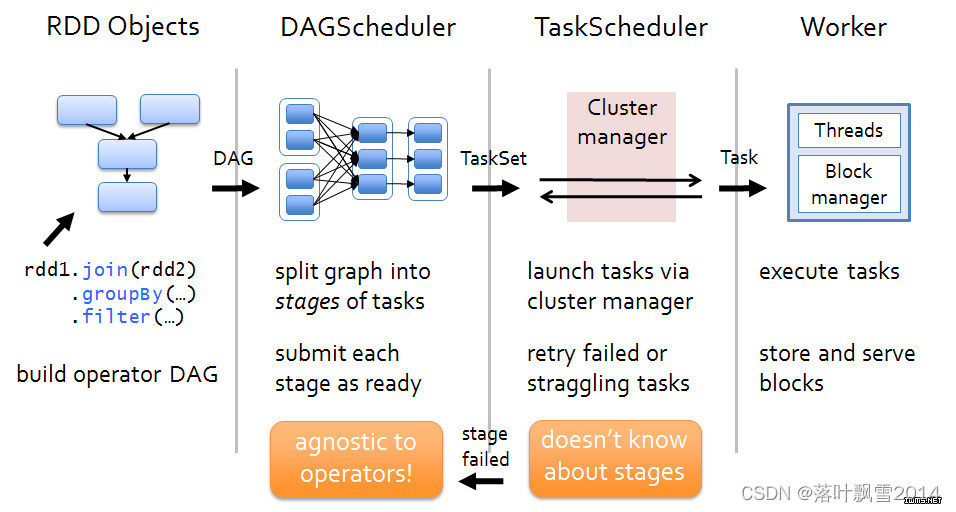
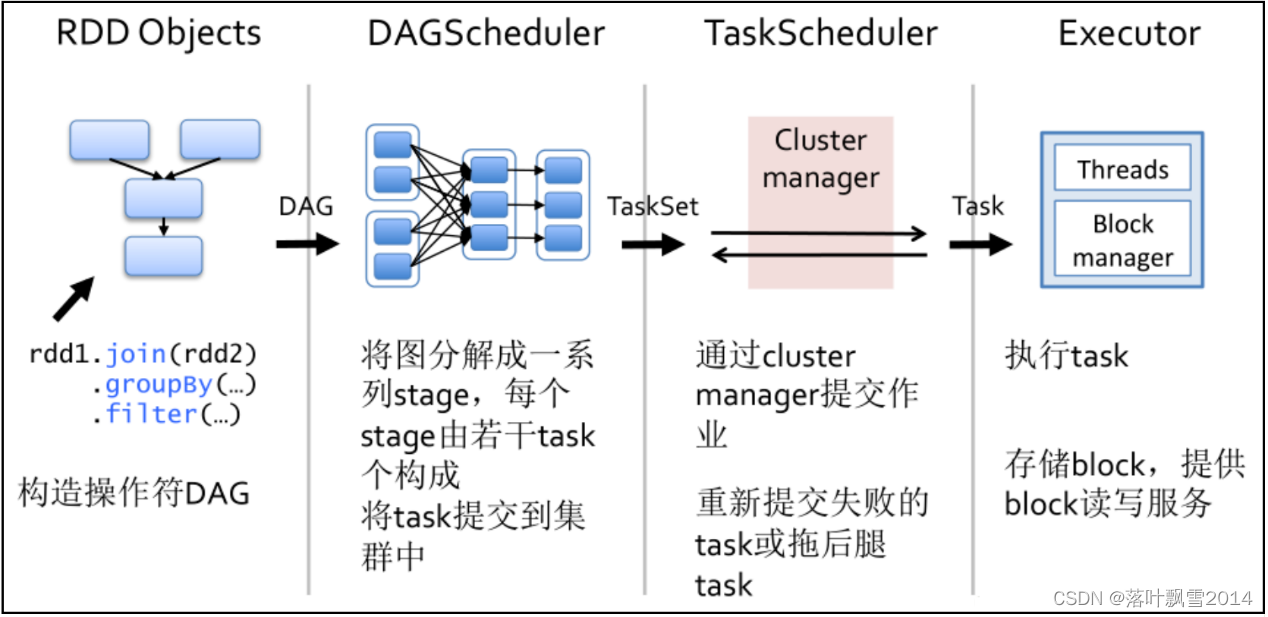
核心四大步骤:
1、构建DAG
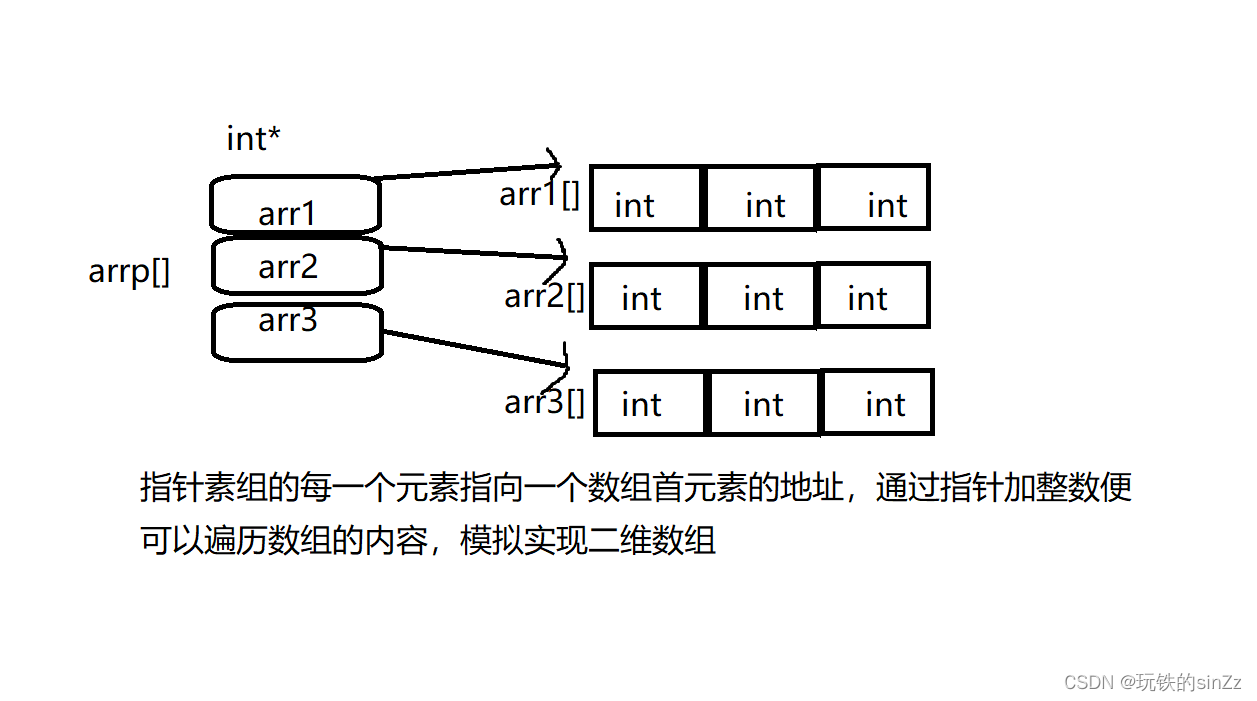
使用算子操作RDD进行各种transformation操作,最后通过action操作触发Spark作业运行。提交之后Spark会根据转换过程所产生的RDD之间的依赖关系构建有向无环图。2、DAG切割
DAG切割主要根据RDD的依赖是否为宽依赖来决定切割节点,当遇到宽依赖就将任务划分为一个新的调度阶段(Stage)。每个Stage中包含一个或多个Task。这些Task将形成任务集(TaskSet),提交给底层调度器进行调度运行。3、任务调度
每一个Spark任务调度器只为一个SparkContext实例服务。当任务调度器收到任务集后负责把任务集以Task任务的形式分发至Worker节点的Executor进程中执行,如果某个任务失败,任务调度器负责重新分配该任务的计算。4、执行任务
当Executor收到发送过来的任务后,将以多线程(会在启动executor的时候就初始化好了一个线程池)的方式执行任务的计算,每个线程负责一个任务,任务结束后会根据任务的类型选择相应的返回方式将结果返回给任务调度器。6.2 运行流程图解
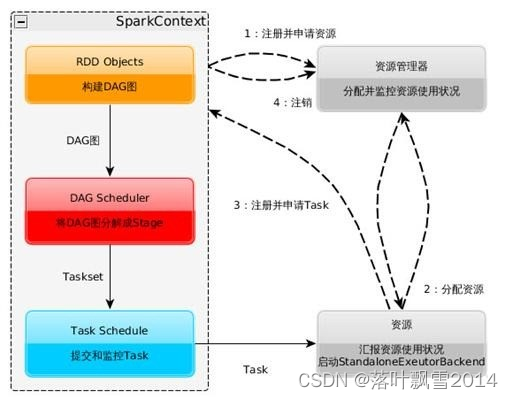
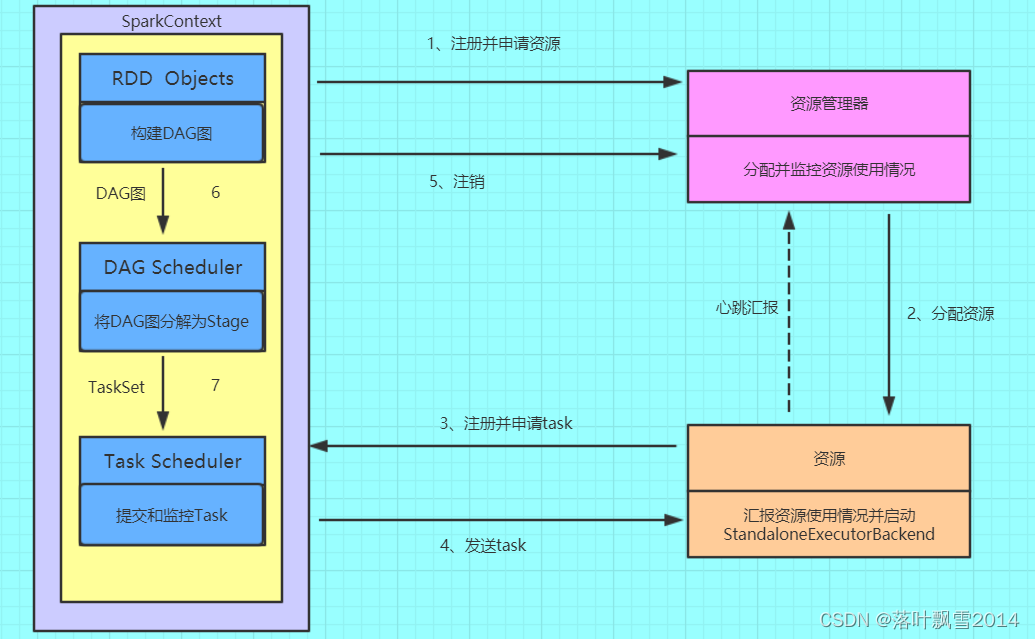
1、构建Spark Application的运行环境(初始化SparkContext),SparkContext向资源管理器(可以是Standalone、Mesos或YARN)注册并申请运行Executor资源2、资源管理器分配Executor资源并启动StandaloneExecutorBackend,Executor运行情况将随着心跳发送到资源管理器上3、SparkContext构建成DAG图,将DAG图分解成Stage,并把Taskset发送给TaskScheduler。Executor向SparkContext申请Task,TaskScheduler将Task发放给Executor运行同时SparkContext将应用程序代码发放给Executor4、Task在Executor上运行,运行完毕释放所有资源。

6.3 SparkContext初始化
关于SparkContext:
1、SparkContext是用户通往Spark集群的唯一入口,可以用来在Spark集群中创建RDD、累加器Accumulator和广播变量Braodcast Variable2、SparkContext 也是整个Spark应用程序中至关重要的一个对象,可以说是整个应用程序运行调度的核心(不是指资源调度)3、SparkContext在实例化的过程中会初始化DAGScheduler、TaskScheduler和SchedulerBackend4、SparkContext会调用DAGScheduler将整个Job划分成几个小的阶段(Stage),TaskScheduler会调度每个Stage的任务(Task)应该如何处理。另外,SchedulerBackend管理整个集群中为这个当前的应用分配的计算资源(Executor)初始化流程:
1、处理用户的jar或者资源文件,和日志处理相关
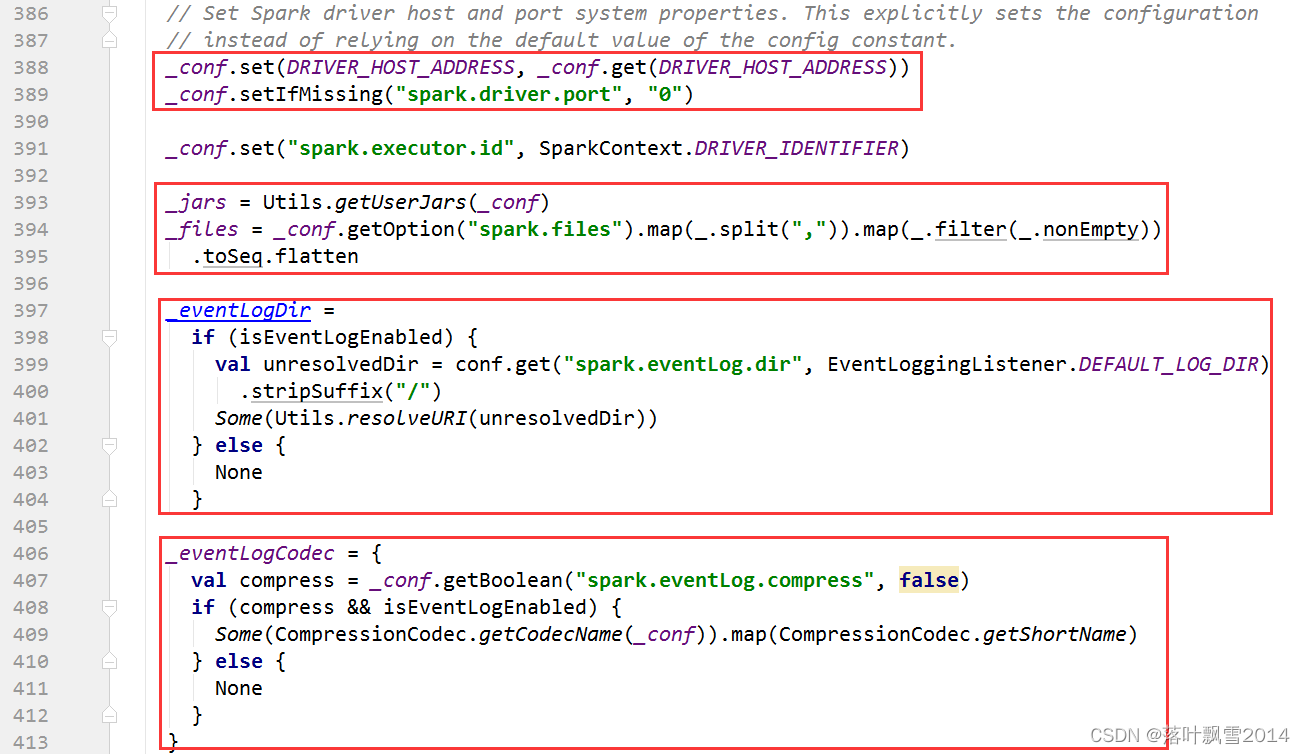
2、初始化异步监听bus:监听spark事件,用于SparkUI的跟踪管理
_listenerBus = new LiveListenerBus(_conf)
3、初始化Spark运行环境相关变量
// Create the Spark execution environment (cache, map output tracker, etc)
_env = createSparkEnv(_conf, isLocal, listenerBus)
SparkEnv.set(_env)
4、启动心跳接收器:在创建taskScheduler之间需要先注册HeartbeatReceiver,因为Executor在创建 时回去检索HeartbeatReceiver
// We need to register "HeartbeatReceiver" before "createTaskScheduler" because
Executor will
// retrieve "HeartbeatReceiver" in the constructor. (SPARK-6640)
_heartbeatReceiver = env.rpcEnv.setupEndpoint(HeartbeatReceiver.ENDPOINT_NAME, new HeartbeatReceiver(this))
5、创建SchedulerBackend、TaskScheduler、DAGScheduler
// Create and start the scheduler
val (sched, ts) = SparkContext.createTaskScheduler(this, master, deployMode)
_schedulerBackend = sched
_taskScheduler = ts
_dagScheduler = new DAGScheduler(this)
_heartbeatReceiver.ask[Boolean](TaskSchedulerIsSet)
6、启动TaskScheduler:在TaskScheduler被DAGScheduler引用后,就可以进行启动
// start TaskScheduler after taskScheduler sets DAGScheduler reference in DAGScheduler's
// constructor
_taskScheduler.start()
调度启动两个角色: 通讯兵
1、跟master打交道:clientEndpoint 负责提交app到master
2、跟worker打交道:driverEndpoint 负责派发task到worker
7、Post Init 各种启动
setupAndStartListenerBus()
postEnvironmentUpdate()
postApplicationStart()// Post init
_taskScheduler.postStartHook()
_env.metricsSystem.registerSource(_dagScheduler.metricsSource)
_env.metricsSystem.registerSource(new BlockManagerSource(_env.blockManager))
_executorAllocationManager.foreach { e =>
_env.metricsSystem.registerSource(e.executorAllocationManagerSource)
}
6.4 DAGScheduler
核心描述:
一个Application = 多个job
一个job = 多个stage,也可以说一个application = 多个stage
一个Stage = 多个同种task并行运行
Task 分为 ShuffleMapTask 和 ResultTask
Dependency 分为 ShuffleDependency宽依赖 和 NarrowDependency窄依赖
面向stage的切分,切分依据为宽依赖
DAGScheduler工作机制:
DAGScheduler拿到一个job,会切分成多个stage
从job的后面往前去寻找Shuffle算子,如果找到一个shuffle算子,就切分。已经找到的这些rdd的执行链连成一个stage,放入到一个 数据结构中(栈 )
将来DAGScheduler要帮这个栈中的每一个stage拿出来,提交给TaskScheduler
主要作用:
维护waiting jobs和active jobs两个队列,维护waiting stages、active stages和failed stages,以及与jobs的映射关系
主要职能:
1、接收提交Job的主入口,submitJob(rdd, ...)或runJob(rdd, ...)。在SparkContext里会调用这两个方法。
应用程序的main运行,最终会调度:DAGScheduler的runJob()方法生成一个Stage并提交,接着判断Stage是否有父Stage未完成,若有,提交并等待父Stage,以此类推。结果是:DAGScheduler里增加了一些waiting stage和一个running stage。
running stage提交后,分析stage里Task的类型,生成一个Task描述,即TaskSet。
调用TaskScheduler.submitTask(taskSet, ...)方法,把Task描述提交给TaskScheduler。TaskScheduler依据资源量和触发分配条件,会为这个TaskSet分配资源并触发执行。
DAGScheduler提交job后,异步返回JobWaiter对象,能够返回job运行状态,能够cancel job,执行成功后会处理并返回结果2、处理TaskCompletionEvent 如果task执行成功,对应的stage里减去这个task,做一些计数工作:
A:如果task是ResultTask,计数器Accumulator加一,在job里为该task置为true,job finish总数加一。加完后如果finish数目与partition数目相等,说明这个stage完成了,标记stage完成,从running stages里减去这个stage,做一些stage移除的清理工作
B:如果task是ShuffleMapTask,计数器Accumulator加一,在stage里加上一个output location,里面是一个MapStatus类。MapStatus是ShuffleMapTask执行完成的返回,包含location信息和block size(可以选择压缩或未压缩)。同时检查该stage完成,向MapOutputTracker注册本stage里的shuffleId和location信息。然后检查stage的output location里是否存在空,若存在空,说明一些task失败了,整个stage重新提交;否则,继续从waiting stages里提交下一个需要做的stage
C:如果task是重提交,对应的stage里增加这个task:
如果task是fetch失败,马上标记对应的stage完成,从running stages里减去。如果不允许retry,abort整个stage;否则,重新提交整个stage。另外,把这个fetch相关的location和map任务信息,从stage里剔除,从MapOutputTracker注销掉。最后,如果这次fetch的blockManagerId对象不为空,做一次ExecutorLost处理,下次shuffle会换在另一个executor上去执行。
D:其他task状态会由TaskScheduler处理,如Exception, TaskResultLost, commitDenied等。3、其他与job相关的操作还包括:cancel job,cancel stage, resubmit failed stage等4、其他职能:cacheLocations 和 preferLocation6.5 TaskScheduler
核心功能:
维护task和executor对应关系,executor和物理资源对应关系,在排队的task和正在跑的task。维护内部一个任务队列,根据FIFO或Fair策略,调度任务。TaskScheduler本身是个接口,spark里只实现了一个TaskSchedulerImpl,理论上任务调度可以定制。
主要职能:
1、submitTasks(taskSet),接收DAGScheduler提交来的tasks
为tasks创建一个TaskSetManager,添加到任务队列里。TaskSetManager跟踪每个task的执行状况,维护了task的许多具体信息。
触发一次资源的需要。
首先,TaskScheduler对照手头的可用资源和Task队列,进行executor分配(考虑优先级、本地化等策略),符合条件的executor会被分配给TaskSetManager。
然后,得到的Task描述交给SchedulerBackend,调用launchTask(tasks),触发executor上task的执行。task描述被序列化后发给executor,executor提取task信息,调用task的run()方法执行计算。2、cancelTasks(stageId),取消一个stage的tasks
调用SchedulerBackend的killTask(taskId, executorId, ...)方法。taskId和executorId在TaskScheduler里一直维护着。3、resourceOffer(offers: Seq[Workers]),这是非常重要的一个方法,调用者是SchedulerBacnend,用途是底层资源SchedulerBackend把空余的workers资源交给TaskScheduler,让其根据调度策略为排队的任务分配合理的cpu和内存资源,然后把任务描述列表传回给SchedulerBackend 从worker offers里,搜集executor和host的对应关系、active executors、机架信息等等。worker offers资源列表进行随机洗牌,任务队列里的任务列表依据调度策略进行一次排序遍历每个taskSet,按照进程本地化、worker本地化、机器本地化、机架本地化的优先级顺序,为每个taskSet提供可用的cpu核数,看是否满足
默认一个task需要一个cpu,设置参数为"spark.task.cpus=1"为taskSet分配资源,校验是否满足的逻辑,最终在TaskSetManager的resourceOffer(execId, host, maxLocality)方法里。满足的话,会生成最终的任务描述,并且调用DAGScheduler的taskStarted(task, info)方法,通知DAGScheduler,这时候每次会触发DAGScheduler做一次submitMissingStage的尝试,即stage的tasks都分配到了资源的话,马上会被提交执行4、statusUpdate(taskId, taskState, data),另一个非常重要的方法,调用者是SchedulerBacnend,用途是SchedulerBacnend会将task执行的状态汇报给TaskScheduler做一些决定
若TaskLost,找到该task对应的executor,从active executor里移除,避免这个executor被分配到其他task继续失败下去。
task finish包括四种状态:finished, killed, failed, lost。只有finished是成功执行完成了。其他三种是失败。
task成功执行完,调用TaskResultGetter.enqueueSuccessfulTask(taskSet, tid, data),否则调用TaskResultGetter.enqueueFailedTask(taskSet, tid, state, data)。TaskResultGetter内部维护了一个线程池,负责异步fetch task执行结果并反序列化。默认开四个线程做这件事,可配参数"spark.resultGetter.threads"=4。
补充:TaskResultGetter取task result的逻辑
1、对于success task,如果taskResult里的数据是直接结果数据,直接把data反序列出来得到结果;如果不是,会调用blockManager.getRemoteBytes(blockId)从远程获取。如果远程取回的数据是空的,那么会调用TaskScheduler.handleFailedTask,告诉它这个任务是完成了的但是数据是丢失的。否则,取到数据之后会通知BlockManagerMaster移除这个block信息,调用TaskScheduler.handleSuccessfulTask,告诉它这个任务是执行成功的,并且把result data传回去。2、对于failed task,从data里解析出fail的理由,调用TaskScheduler.handleFailedTask,告诉它这个任务失败了,理由是什么。
6.6 SchedulerBackend
在TaskScheduler下层,用于对接不同的资源管理系统,SchedulerBackend是个接口,需要实现的主要 方法如下:
def start():Unitdef stop():Unit// 重要方法:SchedulerBackend把自己手头上的可用资源交给TaskScheduler,TaskScheduler根据调度策略分配给排队的任务吗,返回一批可执行的任务描述,SchedulerBackend负责launchTask,即最终把task塞到了executor模型上,executor里的线程池会执行task的run()
def reviveOffers():Unit def killTask(taskId: Long, executorId: String, interruptThread: Boolean): Unit = throw new UnsupportedOperationException
粗粒度:进程常驻的模式,典型代表是Standalone模式,Mesos粗粒度模式,YARN 。
细粒度:Mesos细粒度模式
这里讨论粗粒度模式,更好理解:CoarseGrainedSchedulerBackend。维护executor相关信息(包括 executor的地址、通信端口、host、总核数,剩余核数),手头上executor有多少被注册使用了,有多 少剩余,总共还有多少核是空的等等。
主要职能:
1、 Driver端主要通过actor监听和处理下面这些事件:RegisterExecutor(executorId, hostPort, cores, logUrls)
这是executor添加的来源,通常worker拉起、重启会触发executor的注册。CoarseGrainedSchedulerBackend把这些executor维护起来,更新内部的资源信息,比如总核数增加。最后调用一次makeOffer(),即把手头资源丢给TaskScheduler去分配一次,返回任务描述回来,把任务launch起来。这个makeOffer()的调用会出现在任何与资源变化相关的事件中,下面会看到。StatusUpdate(executorId, taskId, state, data)
task的状态回调。首先,调用TaskScheduler.statusUpdate上报上去。然后,判断这个task是否执行结束了,结束了的话把executor上的freeCore加回去,调用一次makeOffer()。ReviveOffers
这个事件就是别人直接向SchedulerBackend请求资源,直接调用makeOffer()。KillTask(taskId, executorId, interruptThread)
这个killTask的事件,会被发送给executor的actor,executor会处理KillTask这个事件。StopExecutors
通知每一个executor,处理StopExecutor事件。RemoveExecutor(executorId, reason)
从维护信息中,那这堆executor涉及的资源数减掉,然后调用TaskScheduler.executorLost()方法,通知上层我这边有一批资源不能用了,你处理下吧。TaskScheduler会继续把executorLost的事件上报给DAGScheduler,原因是DAGScheduler关心shuffle任务的output location。DAGScheduler会告诉BlockManager这个executor不可用了,移走它,然后把所有的stage的shuffleOutput信息都遍历一遍,移走这个executor,并且把更新后的shuffleOutput信息注册到MapOutputTracker上,最后清理下本地的CachedLocationsMap。2、reviveOffers()方法的实现。直接调用了makeOffers()方法,得到一批可执行的任务描述,调用launchTasks。3、launchTasks(tasks: Seq[Seq[TaskDescription]])方法。
遍历每个task描述,序列化成二进制,然后发送给每个对应的executor这个任务信息 如果这个二进制信息太大,超过了9.2M(默认的akkaFrameSize 10M减去默认为akka留空的200K),会出错,abort整个taskSet,并打印提醒增大akka frame size。如果二进制数据大小可接受,发送给executor的actor,处理LaunchTask(serializedTask)事件。
6.7 Executor
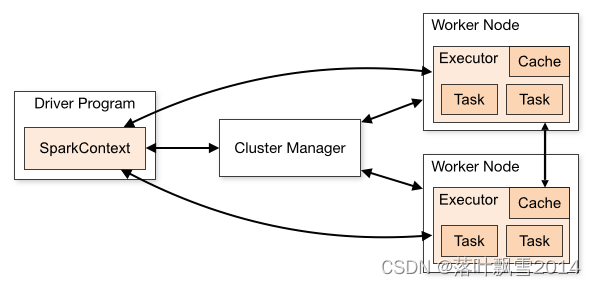
Executor 是 Spark 里的进程模型,可以套用到不同的资源管理系统上,与 SchedulerBackend 配合使用。
内部有个线程池,有个 running tasks map,有个 actor,接收上面提到的由 SchedulerBackend 发来 的事件。

事件处理:
launchTask。根据task描述,生成一个TaskRunner线程,丢尽running tasks map里,用线程池执行这个TaskRunnerkillTask。从running tasks map里拿出线程对象,调它的kill方法。
6.8 Spark运行架构特点
1、每个Application获取专属的executor进程,该进程在Application期间一直驻留,并以多线程方式运行tasks。这种Application隔离机制有其优势的,无论是从调度角度看(每个Driver调度它自己的任务),还是从运行角度看(来自不同Application的Task运行在不同的JVM中)。当然,这也意味着Spark Application不能跨应用程序共享数据,除非将数据写入到外部存储系统。2、Spark与资源管理器无关,只要能够获取executor进程,并能保持相互通信就可以了。3、提交SparkContext的Client应该靠近Worker节点(运行Executor的节点),最好是在同一个Rack里,因为Spark Application运行过程中SparkContext和Executor之间有大量的信息交换;如果想在远程集群中运行,最好使用RPC将SparkContext提交给集群,不要远离Worker运行SparkContext。4、Task采用了数据本地性和推测执行的优化机制。
6.9 Spark任务执行流程分析
6.9.1 Spark任务的任务执行流程图解
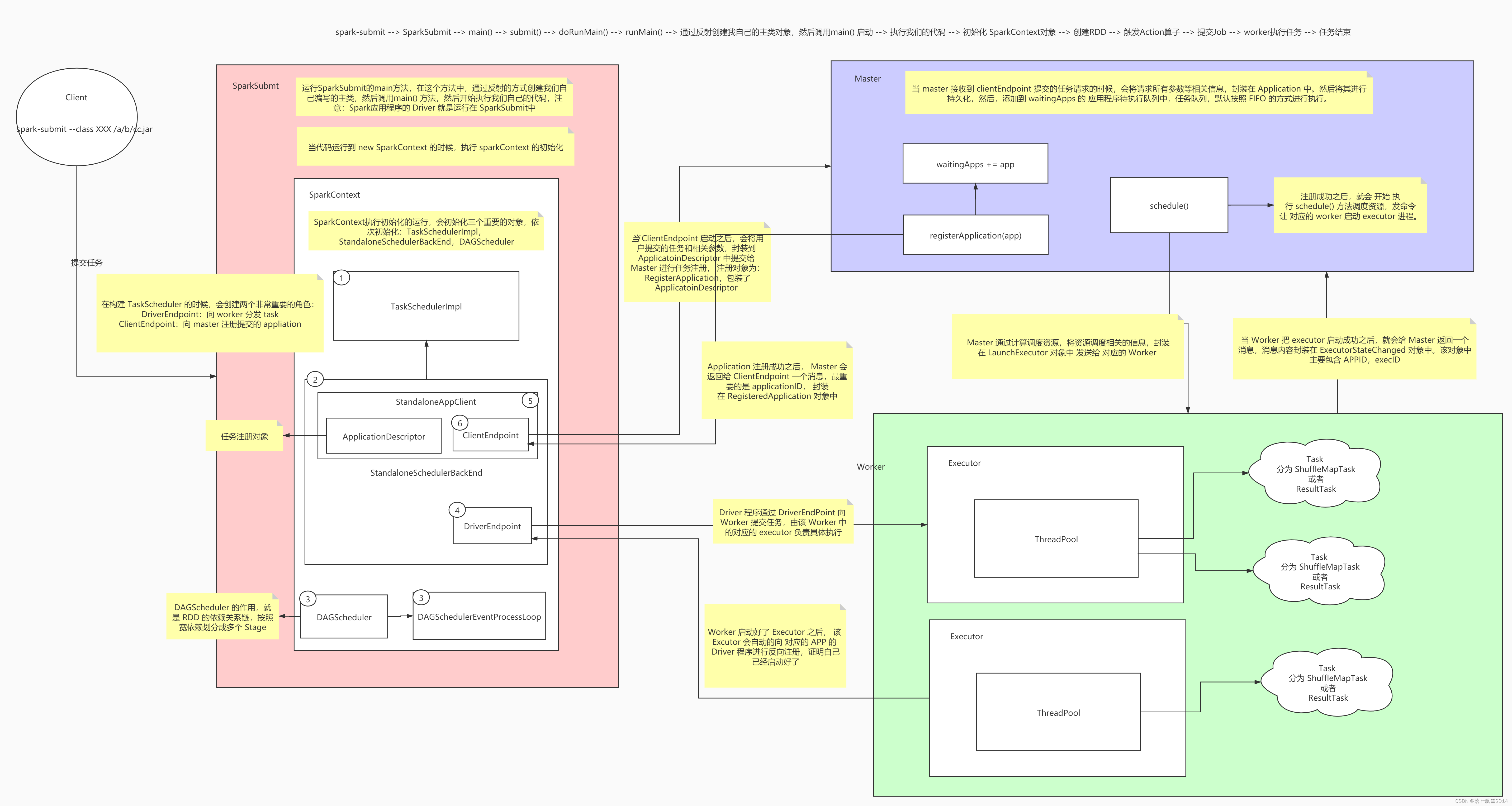
6.9.2 Spark任务的任务执行流程文字描述简介
提交application到standalone集群运行的命令
$SPARK_HOME/bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://hadoop10:7077 \
--driver-memory 512m \
--executor-memory 512m \
--total-executor-cores 1 \
$SPARK_HOME/examples/jars/spark-examples_2.12-3.1.2.jar \
10
详细的执行过程:
--> Spark-submit.sh
--> SparkSubmit.scala
--> main
--> submit
--> doRunMain
--> RunMain
--> 通过反射创建我们编写的主类的实例对象JavaMainApplication,调用main方法
--> 开始执行我们编写的业务代码
--> 初始化SparkContext对象 – 最复杂
--> 创建初始的RDD
--> 触发Action算子
--> 提交job
--> worker执行任务
--> 任务结束
6.9.3 Spark任务的任务执行流程文字详细描述
(1)、将我们编写的程序打成jar包(2)、调用spark-submit脚本提交任务到集群上运行(3)、运行SparkSubmit类中的main方法,在这个方法中通过反射的方式创建我们编写的主类的实例对象,然后调用main方法,开始执行我们的代码(注意,我们的spark程序中的driver就运行在SparkSubmit进程中)(4)、当代码运行到创建SparkContext对象时,那就开始初始化SparkContext对象了(5)、在初始化SparkContext对象的时候,会创建三个特别重要的对象,分别是:DAGScheduler
和TaskScheduler和SchedulersBackend
【DAGScheduler的作用】将RDD的依赖切分成一个一个的stage,然后将stage作为taskSet提交给DriverActor
【TaskScheduler的作用】将接收到的TaskSet进行解析,派发到不同Worker中的Executor中去执行
【SchedulersBackend的作用】负责和Master和Worker进行交互
他们之间的初始化顺序是:TaskScheduler > SchedulersBackend > DAGScheduler(6)、在构建SchedulersBackend的同时,会创建两个非常重要的对象,旧版本叫做分别是DriverActor和ClientActor,新版本叫做:DriverEndpoint和StandAloneAppClient
【clientActor的作用】向Master注册用户提交的任务
【DriverActor的作用】接受Executor的反向注册,将任务提交给Executor(7)、当ClientActor启动后,会将用户提交的任务和相关的参数封装到ApplicationDescription对象中,再封装在RegisterApplication消息中,然后提交给master进行任务的注册(8)、当Master接受到ClientActor提交的任务请求时,会将请求参数进行解析,并封装成ApplicationInfo消息,然后将其持久化,然后将其加入到任务队列waitingApps中,然后返回给ClientActor一个RegisteredApplication消息(9)、当轮到我们提交的任务运行时,就开始调用schedule(),进行任务资源的调度(10)、Master将调度好的资源封装到LaunchExecutor中发送给指定的Worker(11)、Worker接受到Master发送来的LaunchExecutor时,会将其解压并封装到ExecutorRunner中,然后调用这个对象的start(), 启动Executor(12)、Executor启动后会向DriverActor进行反向注册(13)、DriverActor会发送注册成功的消息给Executor(14)、Executor接受到DriverActor注册成功的消息后会创建一个线程池,用于执行DriverActor发送过来的task任务(15)、当属于这个任务的所有的Executor启动并反向注册成功后,就意味着运行这个任务的环境已经准备好了,driver会结束SparkContext对象的初始化,也就意味着new SparkContext这句代码运行完成(16)、当初始化sc成功后,driver端就会继续运行我们编写的代码,然后开始创建初始的RDD,然后进行一系列转换操作,当遇到一个action算子时,也就意味着触发了一个job(17)、driver会将这个job提交给DAGScheduler(18)、DAGScheduler将接受到的job,从最后一个算子向前推导,将DAG依据宽依赖划分成一个一个的stage,然后将stage封装成taskSet,并将taskSet中的task提交给TaskScheduler
通过TaskScheduler中的SchedulerBackend中的DriverActor派发任务到Executor节点中(19)、DriverActor接受到DAGScheduler发送过来的task,会拿到一个序列化器,对task进行序列化,然后将序列化好的task封装到LaunchTask中,然后将LaunchTask发送给指定的Executor(20)、Executor接受到了DriverActor发送过来的LaunchTask时,会拿到一个反序列化器,对LaunchTask进行反序列化,封装到TaskRunner中,然后从Executor中事先初始化好的线程池中获取一个线程,将反序列化好的任务中的算子作用在RDD对应的分区上
声明:
文章中代码及相关语句为自己根据相应理解编写,文章中出现的相关图片为自己实践中的截图和相关技术对应的图片,若有相关异议,请联系删除。感谢。转载请注明出处,感谢。
By luoyepiaoxue2014
微博地址: http://weibo.com/luoyepiaoxue2014 点击打开链接





![[附源码]计算机毕业设计springboot动物保护协会网站](https://img-blog.csdnimg.cn/b7554b4a21fc4ffcac849abfdeca9b94.png)

线程基础,线程控制,线程的互斥与同步](https://img-blog.csdnimg.cn/img_convert/842573432068f52a64d1099f4ff0ac74.png)