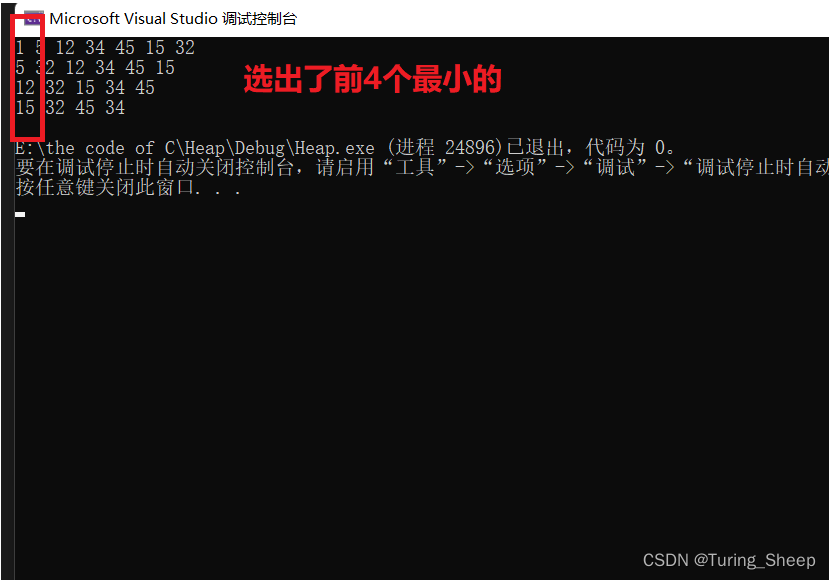
如何简单理解大数据
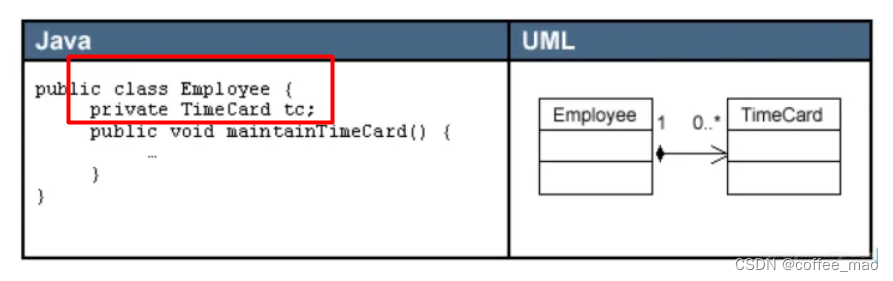
HDFS-存储
海量的数据存储
hadoop 只是一套工具的总称,它包含三部分:HDFS,Yarn,MapReduce,功能分别是分布式文件存储、资源调度和计算。
按理来说,这就足够了,就可以完成大数据分析了。
Hbase-NoSQL
随机查询
海量数据怎样快速查询?HBase 当做是 MySQL,把 HDFS 当做是硬盘。HBase 只是一个 NoSQL 数据库,把数据存在HDFS上。
Hive-调度
降低大数据开发难度,使用 SQL 就行
但第一个问题就是麻烦。这一套相当于用 Yarn 调度资源,读取 HDFS 文件内容进行 MR 计算。要写 Java 代码,但做数据的最好的工具是什么?SQL!所以 Hive 相当于这一套标准流程的 SQL 化。
Hive 可以简单理解为,Hadoop 之上添加了自己的 SQL 解析和优化器,写一段 SQL,解析为 Java 代码,然后去执行MR,底层数据还是在 HDFS 上。
ClickHouse/kylin-OLAP类型
关联查询
亿级数据关联查询处理时,比 Hive 快百倍。支持常用的 SQL 语法,写入速度非常快,适用于大量的数据更新。依赖稀疏索引,列式存储,CPU/内存的充分利用造就了优秀的计算能力,并且不用考虑左侧原则。不支持事务、不支持高并发。
Spark-计算
解决大数据计算问题
这看起来挺完美,但问题是程序员发现好慢啊。原因是 MR,它需要频繁读写文件。这时基于内存的 Spark 出现了,Spark 是替代 MR 的,意图解决所有大数据计算问题,它会为 SQL 生成有向无环图,加上各种算子和宽窄依赖的优化,使得计算速度达到了新的高度。
按理说这就完美解决了呀。
下游-canal-同步
但是,我们回头想想,这些数据怎么来的呢?我们是不是到目前为止都是在处理静态的数据呢?像比如线上支付校验这种需要实时返回结果的总不能等着 Spark 批量算吧。
解决问题之前,我们回头再想想,数据怎么来的。一般数据包含两种:业务数据和日志数据。
业务数据就是数据库中的结构性的数据,规规整整。业务数据怎么到 Hive 呢?开源上一般通过 Sqoop 进行导入,比如一张表,数据少每天我把表全部导入一遍,这叫全量同步;数据特别大,就只同步每天变化和新增的,这是增量同步。
但这种同步比较滞后,都是在夜深人静集群的计算资源比较空闲的时候做的,对应的也是离线分析。
实时怎么理解?来一批处理一批,再细一点儿,来一条,处理一条。
比如,你买一件东西,平台数据库中会多一条订单数据,app 会产生行为日志数据。订单数据插入数据库时一般会有binlog,即记录插入、更新或删除的数据,我们只要能实时拿到这一条 binlog,就相当于拿到了实时数据。
binlog 怎么拿呢?这就要说道数据库的主从备份机制,一般本身就是拿主库的 binlog 同步到备份库,刚好有一个叫 canal的工具可以把自己伪装成备份库,来拉取主库的 binlog,再解析、包装最后抛出,就相当于实时拿到数据了!
下游-MQ-消峰
canal 拿到了 binlog 就能直接处理了吗?可以,但有件事儿大家想一想。马上五一了,加入一下子超级多人下单消费,canal 抛出的消息我们下游一下子消费不完咋办呢?比如快递员每天都只给你派送一件快递,你拿到之后钱货两清。然后突然一天快递员给你送一千件到你楼下,你下楼一件一件搬,快递员还得等你搬完才能回去,这得等到啥时候。聪明的你马上想到了,放快递柜呀,你有时间慢慢搬不就行了,也不占用快递员的时间了。
这就是消息队列,Kafka 就是起这样的作用:异步、解耦、消峰。canal的数据一般会抛到 kafka 或 RocketMQ,可以保存一段时间。然后下游程序再去实时拉取消息来计算。
Spark Streaming/Storm-实时计算
实时计算
说了这么多下游,下游到底由谁来消费计算这些实时数据呢?还记得 Spark 吗,没错它又来了,Spark streaming 就是批量处理 实时流数据 的好手。
Spark 是一整套组件的统称,比如你可以用 Java 写 Spark 任务,用 Spark SQL 去写 SQL,可以用 Spark MLib 完成机器学习的模型训练等等,Spark Streaming 就是用来微批地处理流式数据的。
具体而言,离线数据我们是等半夜数据都抽到 Hive 中再计算,而 Spark Streaming 则是实时数据来一小批,它就处理一小批。所以本质上讲,Spark Streaming 还是批处理,只不过是每一批数据很少,并且处理很及时,从而达到实时计算的目的。
Spark 本身的流行使得 Spark Streaming 也一直大范围使用。
Flink-逐条计算
比 Spark 更强的实时计算
我们可以想一想,实时数据和离线数据最大的差异,是时效性。离线数据像湖水,该多少就多少,就在那里;实时数据像水流,绵绵不绝。时间,便是非常重要的一个特质。当一条数据来的时候,我们需要知道这条数据是什么时候产生的,这便是业务时间。但我们拿到这条数据时往往是业务时间之后的一小会,这边是处理时间。真正世界里的实时数据肯定不是像 Spark Streaming 那样一批一批来的,而是一个一个的事件。对此,Flink 帮助我们解决了这些问题。
无论是业务数据还是日志数据,往往都有相应的时间标志字段,代表着这条消息的业务时间。你可以让 Flink 选择这个时间,这样,Flink 就知道当前处理到哪个时间点了。
Flink 不同于 Spark Streaming 的微批次处理,它是一条一条数据处理的。
TensorFlow-挖掘
海量数据怎样挖掘出隐藏的知识?也就是当前火热的机器学习和深度学习等技术,包括TensorFlow、caffe、mahout等

![[CVPR2022] Cross-Model Pseudo-Labeling for Semi-Supervised Action Recognition](https://img-blog.csdnimg.cn/decf823f99cf4f938b06cf4b6dd88be0.png)