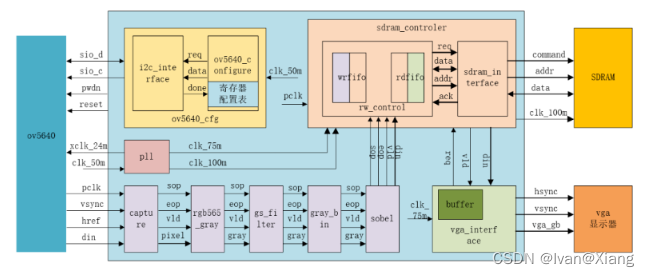
0.实验环境搭建:
-
源代码获取:
来源一:google
来源二:web
来源三:github -
环境:
conda create --name python36_google_deep python=3.6
conda activate python36_google_deep
#建议按照顺序安装
pip install altair,scipy,matplotlib
pip install certifi
pip install pytorch-lightning-bolts==0.2.5
pip install torchvision==0.7.0
pip install pytorch-lightning==0.10.0
'''
可能还需要别的,看报错缺少哪个库,版本应该没啥大事。
'''通用设置
我们有一个数据集D=[{xi,yi},i=1,…,n]D = [\{x_i, y_i \}, i=1,…,n]D=[{xi,yi},i=1,…,n],并定义了似然函数P(D∣θ)P(D|\theta)P(D∣θ),其中 θ∈Rd\theta \in R^dθ∈Rd 中 的θ\thetaθ 是模型中定义的一些参数。我们还为这些参数 定义了一个先验值 P(θ)P(\theta)P(θ) 。后验分布可以写成
P(θ∣D)=P(D∣θ)∗P(θ)P(D)∝P(D∣θ)∗P(θ)P(\theta | D) = \frac{P(D|\theta) * P(\theta)}{P(D)} \propto P(D|\theta) * P(\theta) P(θ∣D)=P(D)P(D∣θ)∗P(θ)∝P(D∣θ)∗P(θ)
除了最简单的情况外,找到 P(D)P(D)P(D) 是不可能的,因为我们对神经网络等复杂的似然函数感兴趣,它显然不适合我们。
因此,我们只有一个固定后验分布。
幸运的是,已经有多种技术可以找到后验分布的近似值,只需要
有多种方法可以推断贝叶斯神经网络的后验分布:
- Variational Inference(变分推理)
- Dropout(剪枝)
- SWAG
- Markov Chain Monte Carlo
- Stochastic Markov Chain Monte Carlo (SG-MCMC)
这里我们将重点讨论后两个。
1.例子
在整个帖子中,我们将使用一个问题来说明我们的意思。
假设我们收集了 NNN 数据点 (xn,yn),N≤N(x_n, y_n), N \le N(xn,yn),N≤N,其中 xn∈R2x_n \in R^2xn∈R2是一个二维向量,yn∈R1y_n \in R^1yn∈R1是一个一维响应。
我们使用一个非常简单的“神经网络”生成数据:
yn=β0+βxn+N(0,σ)y_n = \beta_0 + \beta x_n + N(0,\sigma)yn=β0+βxn+N(0,σ)
其中β0\beta_0β0, β\betaβ和σ\sigmaσ是模型的参数。
我们将在参数θ:={β0,β,σ}\theta:= \{\beta_0, \beta, \sigma \}θ:={β0,β,σ}中收集所有三个参数,以便更容易编写。
我们可以看到,给定输入数据 xnx_nxn 和参数 θ\thetaθ ,yny_nyn 实际上是正态分布的。
这就是我们所说的似然函数:
P(D∣θ)=∏n=1NP(yn∣θ,xn)=∏n=1NN(β0+βxn,σ)P(D|\theta) = \prod_{n=1}^N P(y_n | \theta, x_n) = \prod_{n=1}^N N(\beta_0 + \beta x_n ,\sigma)P(D∣θ)=n=1∏NP(yn∣θ,xn)=n=1∏NN(β0+βxn,σ)
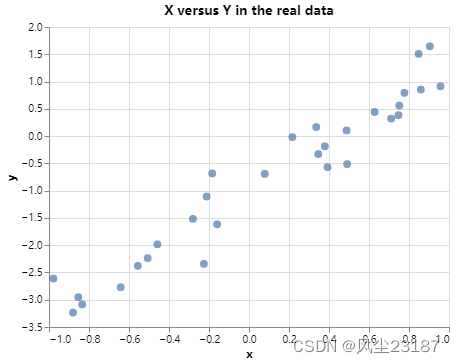
让我们生成一个 β0=−1\beta_0 = -1β0=−1, β=2.0\beta = 2.0β=2.0 和 σ=0.1\sigma = 0.1σ=0.1的数据集:
2.导入库并生成数据
import torch
import torch.nn as nn
import torch.distributions as dist
from torch.optim.optimizer import Optimizer
import copy
import randomimport matplotlib.pyplot as plt
import altair as alt
import pandas as pd
import scipy.stats
N = 30
beta0 = torch.tensor([-1.0])
beta_true = torch.tensor([2.0])
sigma_true = torch.tensor([0.5])X = dist.Uniform(-1,1).sample((N,))
Y = beta0 + X *beta_true + sigma_true*torch.normal(0,1, (N,))
data = {'x' : X,'y' : Y}(alt.Chart(pd.DataFrame(data)).mark_circle(size=60).encode(x='x',y='y').properties(title="X versus Y in the real data")#.interactive()
)
现在,监督学习的目标是找到参数 θ\thetaθ 的估计值。
我们的目标是最大化似然函数加上参数的先验信念。
在这个例子中,我们会做一个非常愚蠢的想法,并说它同样有可能在实线上的任何地方找到参数: P(θ)∼1P(\theta) \sim 1P(θ)∼1。
这简化了分析,然后我们可以将后验写成只与可能性成比例的形式:
P(θ∣X,Y)∼∏n=1NN(yn∣β0+βxn,σ2)P(\theta | X,Y) \sim \prod_{n=1}^N N(y_n | \beta_0 + \beta x_n ,\sigma^2) P(θ∣X,Y)∼n=1∏NN(yn∣β0+βxn,σ2)
我们可以通过以下方式在pytorch中实现这个模型:
class BayesNet(nn.Module):def __init__(self, seed = 42):super().__init__()torch.random.manual_seed(seed)# Initialize the parameters with some random valuesself.beta0 = nn.Parameter(torch.randn((1,)))self.beta = nn.Parameter(torch.randn((1,)))self.sigma = nn.Parameter(torch.tensor([1.0]) ) # this has to be positivedef forward(self, data: dict):return self.beta0 + self.beta*data['x']def loglik(self, data):# Evaluates the log of the likelihood given a set of X and Yyhat = self.forward(data)logprob = dist.Normal(yhat, self.sigma.abs()).log_prob(data['y'])return logprob.sum()def logprior(self):# Return a scalar of 0 since we have uniform priorreturn torch.tensor(0.0)def logpost(self, data):return self.loglik(data) + self.logprior()
model = BayesNet(seed =42)
model.loglik(data)
tensor(-73.9104, grad_fn=)
#hide
#Finally, due to the sampling of data, we may note that the maximum likelihood estimation is slightly off the real parameters:
beta, beta0, r_value, p_value, std_err = scipy.stats.linregress(data['x'], data['y'])
print(f"MLE estimates: beta_0 = {beta0:.2f}, beta = {beta:.2f}")
MLE estimates: beta_0 = -1.01, beta = 2.27
3.Metropolis MCMC算法
metropolis MCMC算法什么都不做,只是从某个随机位置 θ0\theta_0θ0 开始,并随机尝试向某个方向移动(例如,添加一个正态分布 θ1=θ0+N(0,1)\theta_1 = \theta_0 + N(0,1)θ1=θ0+N(0,1))。
如果我们改进(意味着 P(θ∣D)P(\theta | D)P(θ∣D) 增加),我们使用这个新值。
如果它没有改善,我们仍然可能移动到那个点,这取决于某种概率。
形式上算法是这样的:
- 初始化起始点 θ0\theta_0θ0 。这可以是随机的,也可以是你认为合理的。例如,您可以从先验分布 argmaxθP(θ)argmax_{\theta} P(\theta)argmaxθP(θ) 的中心开始。
- 对于每个 n=1,2,3,…n = 1, 2, 3,…n=1,2,3,…执行以下操作:
-
- 使用提案分发:
-
- θ∗∼J(θ∗∣θn−1)\theta_* \sim J(\theta_* | \theta_{n-1})θ∗∼J(θ∗∣θn−1)对提案θ∗\theta_*θ∗进行抽样
(例如多元正态分布:J(θ∗∣θN−1)=N(θ∗∣θN−1,αI)J(\theta_* | \theta_{N -1}) = N(\theta_* | \theta_{N -1}, \alpha I)J(θ∗∣θN−1)=N(θ∗∣θN−1,αI))
- θ∗∼J(θ∗∣θn−1)\theta_* \sim J(\theta_* | \theta_{n-1})θ∗∼J(θ∗∣θn−1)对提案θ∗\theta_*θ∗进行抽样
-
- 计算这个提议比之前的好多少:
θn={θ∗with probability min(1,r)θn−1if not\theta_n = \begin{cases} \theta_* & \text{with probability} \text{ min}(1,r) \\ \theta_{n-1} & \text{if not} \end{cases} θn={θ∗θn−1with probability min(1,r)if not
对于这个提案分布 JJJ 有一个技术限制,那就是它应该是对称的。
这意味着它应该是有可能向两个方向: J(θa∣θb)=J(θb∣θa)J(\theta_a | \theta_b) = J(\theta_b | \theta_a)J(θa∣θb)=J(θb∣θa) 。
我们上面的例子,一个以前一步为均值的多元正态,满足这个要求。
那么,为什么这个方法行得通呢?首先,看看我们是否得到一个比 P(θ∗∣D)>P(θn−1∣D)P(\theta_*|D) > P(\theta_{n-1}|D)P(θ∗∣D)>P(θn−1∣D) 更好的参数集,并且比值大于1。然后我们总是移动到新的值(概率为1)!
这是令人欣慰的。如果我站在一座平坦的山上,只要往上走一步,我就一定能到达山顶!
但是第二项呢?如果我们真的没有进步怎么办?看看这个算法,这是r小于1的情况。
无论如何,我们都有积极的可能性搬家。直觉上,这很重要,有两个原因:
- 我们想找到最后的后验分布。如果我们只在改进的时候移动,我们就会得到一个最终值。实际上,向稍微差一点的方向移动会让我们的参数在最优解附近摆动一点。
幸运的是,这种摆动可以得到后验分布! - 向错误方向移动的正概率也让我们有机会避免局部极小值。事实上,因为我们的建议分布有一个正的概率从任何点跳到任何参数值集,我们可以证明大都会mcmc算法会找到最优的,只要它运行的时间足够长。
步长也就是学习速率
假设我们选择的是具有前一个参数集均值的高斯建议分布,我们还需要设置该分布的协方差矩阵。
在上面的例子中,它是 αI\alpha IαI,其中 α>0\alpha > 0α>0 并且 III 是单位矩阵。
根据这个参数化,α\alphaα决定了我们应该在metropolis算法中尝试跳转多远。
较大的α\alphaα将使我们经常跳得很远,而较小的α\alphaα将使我们跳得很快。
如果我们做短跳,我们可能会得到性能不太差的提议参数,metropolis算法通常会接受新的参数,但我们每次都会采取非常短的步骤。
另一方面,如果我们进行较大的跳跃,我们有时可能会获得非常好的收益,但它们也经常是非常糟糕的。因此,较大的 α\alphaα 值将导致接受概率较低,但无论何时它接受都会获得较大的收益。
这种权衡看起来与深度学习中的学习率非常相似:小的步骤会慢慢收敛,大的步骤需要信心的巨大飞跃,可能不会收敛得很好。当然,不同之处在于,如果您将α\alphaα设置得太高,metropolis算法将不接受任何提议。
还有更复杂的算法试图自动设置α\alphaα,但现在我们只需要找到一个合理的值(通过尝试和错误)并坚持使用它。
3.1 Metropolis算法的实现
让我们实现一个小型的“优化器”,用metropolis算法找到后验分布。
这个类的主要组件是’ step() ‘函数,它执行了上面的步骤。
此外,我们还为训练循环实现了一个’ fit() '函数和 一个保存了迭代中所有的参数值的字典,以便我们稍后查看:
class MetropolisOptimizer():def __init__(self, net, alpha):super().__init__()self.net = netself.alpha = alpha@torch.no_grad()def step(self, data=None):# Step 1:proposal_net = copy.deepcopy(self.net) # we copy the whole network instead of just the parameters for simplicityfor name, par in proposal_net.named_parameters():newpar = par + torch.normal(torch.zeros_like(par), self.alpha)par.copy_(newpar)# Step 2: calculate ratioratio = torch.exp(proposal_net.logpost(data) - self.net.logpost(data))# Step 3: update with some probability:if (random.random()<ratio).bool():self.net = proposal_netelse:passreturn self.netdef fit(self, data=None, num_steps=1000):# We create one tensor per parameter so that we can keep track of the parameter values over time:self.parameter_trace = {key : torch.zeros( (num_steps,) + par.size()) for key, par in self.net.named_parameters()}for s in range(num_steps):current_net = self.step(data)for key, val in current_net.named_parameters():self.parameter_trace[key][s,] = val.datamodel = BayesNet()
trainer = MetropolisOptimizer(model, alpha=0.02)
# Train the model (and take the time):
%time trainer.fit(data, num_steps=5000)
CPU times: user 4.65 s, sys: 19.9 ms, total: 4.67 s
Wall time: 4.99 s
我们只有3个参数,可以把它们都形象化。
我们可以看到,所有三个变量首先都朝着“应该是”的区域前进,然后开始在该区域周围摆动。这是后验分布!
此外,我们可视化一个二维图,其中β0\beta_0β0和β\betaβ在所有步骤中:
#hide_input
def plot_parameter_trace(trainer):trace = pd.DataFrame({key : val.flatten() for key, val in trainer.parameter_trace.items()})chart = alt.vconcat()for col in trace.columns.to_list():ch = (alt.Chart(trace.reset_index()).mark_line().encode(x="index",y=col).properties(width=300,height=100))#.interactive()chart &= chtwodim = (alt.Chart(trace.reset_index()).mark_circle(size=10).encode(x="beta0",y="beta",color="index").properties(width=300,height=300))#.interactive()chart |= twodimreturn chart
plot_parameter_trace(trainer)
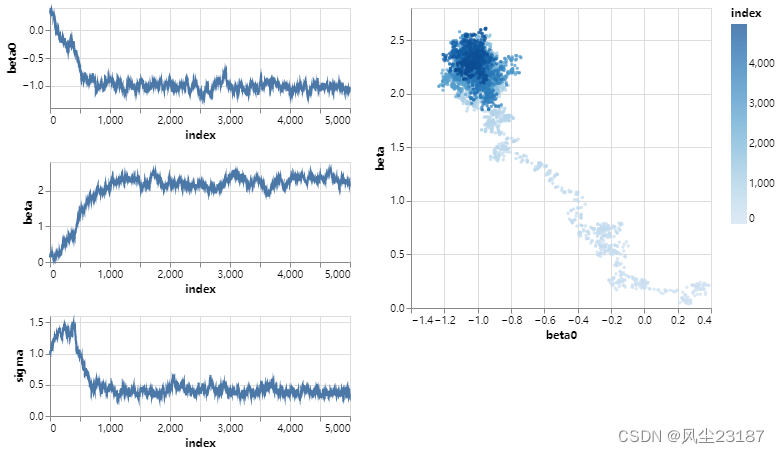
所有的参数都从某个随机的位置开始,然后快速地迭代自己到后验分布应该在的位置。
在最后一个图中,我们可以看到两个参数 β\betaβ 和 β0\beta_0β0,它们从右下区域开始,在左上区域的后向分布附近结束。
模型收敛到后验分布之前的迭代(发生在第1500步左右)被称为磨合阶段,或者在标准的深度学习设置中称为“训练”。
然而,在贝叶斯深度学习中,这是有趣的开始,因为现在mcmc开始描述完整的后验分布。
这两个阶段在右下方的图中非常清楚!
4.Langevin扩散和近似梯度
Metropolis MCMC是一个相当简单的算法。
它甚至要求我们在每一步中朝着随机的方向做一步,当我们明显可以做得更好的时候。
例如,使用分布函数的梯度移动到P(θ∣D)P(\theta| D)P(θ∣D)较大的区域将是明智的。
这样做的基础是朗日万扩散。
让我们先把非归一化后验写成 P(θ∣D)∼e−U(θ)P(\theta | D) \sim e^{-U(\theta)}P(θ∣D)∼e−U(θ),我们引入了势能函数U(θ):=−logP(D∣θ)−logP(θ)U(\theta):= -log P(D|\theta) -log P(\theta)U(θ):=−logP(D∣θ)−logP(θ)。通常,这个函数可以分解为对先验和所有数据点的和: U(θ)=∑n=1NUi(θ):=∑n=1N−log(f(yi∣θ))−1Nlog(P(θ))U(\theta) = \sum_{n=1}^N U_i(\theta) := \sum_{n=1}^N -log(f(y_i|\theta)) - \frac{1}{N}log(P(\theta))U(θ)=∑n=1NUi(θ):=∑n=1N−log(f(yi∣θ))−N1log(P(θ)).
在我们的例子中,UUU 简单地变成U(θ)=−∑n=1nlog(n(yn∣β0+βxn,σ2))U(\theta) = -\sum_{n=1}^ n log(n (y_n | \beta_0 + \beta x_n,\sigma^2))U(θ)=−∑n=1nlog(n(yn∣β0+βxn,σ2))。
我们可以定义朗格万扩散,这是一个随机微分方程:
θ(t)=−12∇U(θ(t))dt+dBt\begin{equation} \theta(t) = -\frac{1}{2} \nabla U(\theta(t))dt + dB_t \end{equation}θ(t)=−21∇U(θ(t))dt+dBt
随机微分方程在直觉上和常规微分方程是一样的,只是它们有一个随机元素 dBtdB_tdBt (一个布朗运动)。
我们不会在这里过多地讨论它,但把它简单地想象成一个打乱了我们在第一项中设定的方向的随机游走。
我们为什么要讲朗格万微分方程呢?
事实证明,上述方程的平稳分布实际上就是我们所寻找的后验分布 !
所以,如果我们能够长时间模拟这个过程,我们就能从后验分布中获得样本!
当然,求解微分方程很难用解析的方法来做。
然而,就像普通的微分方程一样,我们可以通过线性近似逼近随机微分方程,使用小步长α\alphaα:
θ(t+α)=θ(t)−α2∇U(θ(t))+α∗z\begin{equation} \theta(t+\alpha) = \theta(t) -\frac{\alpha}{2} \nabla U(\theta(t)) + \alpha*z \end{equation}θ(t+α)=θ(t)−2α∇U(θ(t))+α∗z
其中 zzz 为 d维标准高斯随机变量。
通过这种近似模拟,我们可以得到后验分布。
这个方程看起来与梯度下降算法惊人地相似:我们通过向目标的梯度移动一小步来更新当前参数。
主要有两个区别:
朗格万扩散增加了一个小的噪声因子αz\alpha zαz。
它还要求我们对所有数据点计算UUU的梯度。这在许多数据集上是不切实际的,深度学习文献通常在每次迭代时通过对数据进行子采样,通过无偏估计来近似梯度
∇^U(θ)=N∣S∣∑i∈S∇Ui(θ)\hat{\nabla} U(\theta) = \frac{N}{|S|} \sum_{i \in S} \nabla U_i(\theta) ∇^U(θ)=∣S∣Ni∈S∑∇Ui(θ)
其中SSS是∣S∣|S|∣S∣数据点数的随机样本。
这就得到了SGLD算法!我们使用小步长 α\alphaα 和估计梯度 ∇^U(θ)\hat{\nabla} U(\theta)∇^U(θ) 通过子采样数据点来模拟朗格万扩散。
值得注意的是,这两种近似(离散化和数据的梯度估计)不会给我们真实的后验分布。如果我们想正确地做到这一点,我们应该在算法中添加一个接受/拒绝步骤。
然而,这通常是昂贵的,因为当我们想这样做时,我们必须估计完整的U(θ)U(\theta)U(θ)。
4.1SGLD算法的实现
SGD算法的实现需要计算似然函数的梯度。
这是深度学习框架非常擅长的。
另一方面,SGLD算法将始终接受提出的参数,使优化算法比之前的metropolis算法简单得多(冒着对后验的糟糕近似的风险)。
对于这个实现,请注意我们没有对数据进行子采样,因为无论如何我们只有30个数据。
from torch.optim.optimizer import Optimizer
class TrainOptimizerSGLD(Optimizer):def __init__(self, net, alpha=1e-4):super(TrainOptimizerSGLD, self).__init__(net.parameters(), {})self.net = netself.alpha = alphadef step(self, batch, batch_size=1, num_data=1):self.zero_grad()weight = num_data/batch_sizeloss = -self.net.loglik(batch)*weight - self.net.logprior()loss.backward()with torch.no_grad():for name, par in self.net.named_parameters():newpar = (par - 0.5*self.alpha*par.grad + torch.normal(torch.zeros_like(par), std=self.alpha))par.copy_(newpar)return lossdef fit(self, data=None, num_steps=1000):# We create one tensor per parameter so that we can keep track of the parameter values over time:self.parameter_trace = {key : torch.zeros( (num_steps,) + par.size()) for key, par in self.net.named_parameters()}for s in range(num_steps):loss = self.step(data)for key, val in self.net.named_parameters():self.parameter_trace[key][s,] = val.datamodel = BayesNet()
trainer = TrainOptimizerSGLD(model, alpha=0.04)
# Train the model (and take the time):
%time trainer.fit(data, num_steps=5000)
plot_parameter_trace(trainer)
CPU times: user 5.06 s, sys: 21.4 ms, total: 5.09 s
Wall time: 5.18 s
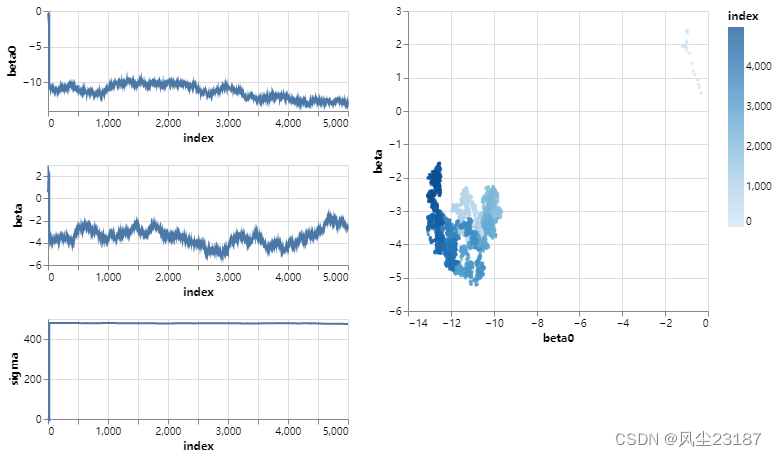
与metropolis算法相比,我们看到beta参数迅速就位。
然而,σ参数的变化比预期的要大得多。
这一定是由于随机微分方程离散化过程中的近似误差。
减小步长可以解决这个问题:
model = BayesNet()
trainer = TrainOptimizerSGLD(model, alpha=0.005)
# Train the model (and take the time):
%time trainer.fit(data, num_steps=5000)
plot_parameter_trace(trainer)
CPU times: user 4.68 s, sys: 354 µs, total: 4.68 s
Wall time: 4.77 s
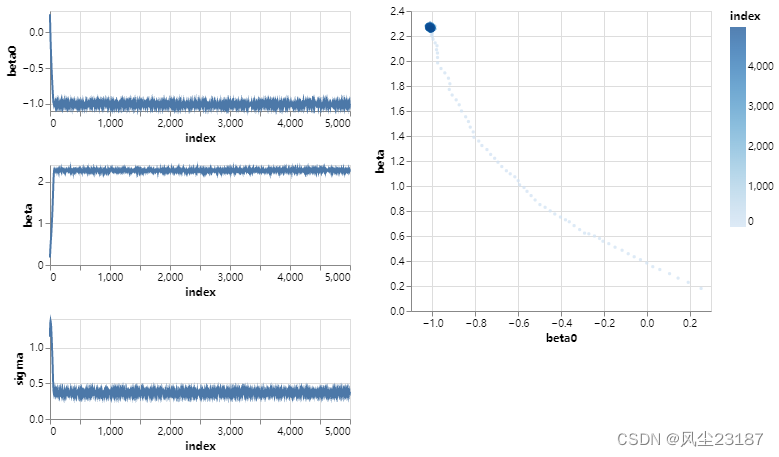
瞧!与Metropolis算法相比,SGLD将betabetabeta参数直接捕捉到正确的区域。
它显示了Metropolis的随机游走算法在速度上的巨大改进,这对于更复杂的问题是至关重要的。
与此同时,我们可以看到σ\sigmaσ从未真正收敛到 0.5 附近的真实值,而是不断地上升。
这一定是由于朗格万扩散中的欧拉近似,并且应该可以通过减小步长来求解。
让我们用更小的步长重复SGLD算法。
我们看到,尽管收敛速度略慢(但比大都市快得多!),我们最终得到了一个更好的近似:
5. 循环SG-MCMC (cSG-MCMC)
我们要讨论的最后一个算法是最近的一篇ICML论文,它利用循环步长来捕获“更好的”后向分布。
他们关注后验分布在参数空间中有多个模态或最优“区域”时的问题。
对于具有大参数空间的神经网络来说,这是一个典型的问题。
循环SG-MCMC算法与上面的SGLD算法一样,但使用不同的步长。
该算法从大步长(探索模式)开始,快速移动到一个感兴趣的模式,然后逐渐减小步长,捕获发现的模式周围的后验分布(采样模式)。
它重复这个过程多次,能够捕获多模态后验分布。
最后将抽样模式下的所有参数样本作为后验分布。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-EwzzJlEc-1665037481994)(assets-bayes-nn/cyclic-stepsize.png "Visualization of cyclical stepsize decay vs traditional stepsize decay")]](https://img-blog.csdnimg.cn/1b5aff7838ee4c0ea0ec1d3ad1e24d3b.png)
该技术类似于其他MCMC算法,试图在不同的点重新初始化MCMC链,以找到不同的模式。
然而,本文认为使用循环将在每次迭代时热启动网络,允许它在一个稍微智能的地方启动,并在相同的性能下节省计算成本。
经验表明,cSG-MCMC能够找到多种模式,而具有4次并行迭代的SGLD只能找到4种模式:

cSGLD比并行SGLD能找到更多的模式。
他们表明,cSG-MCMC可以实现比基准优化算法更低的测试误差:
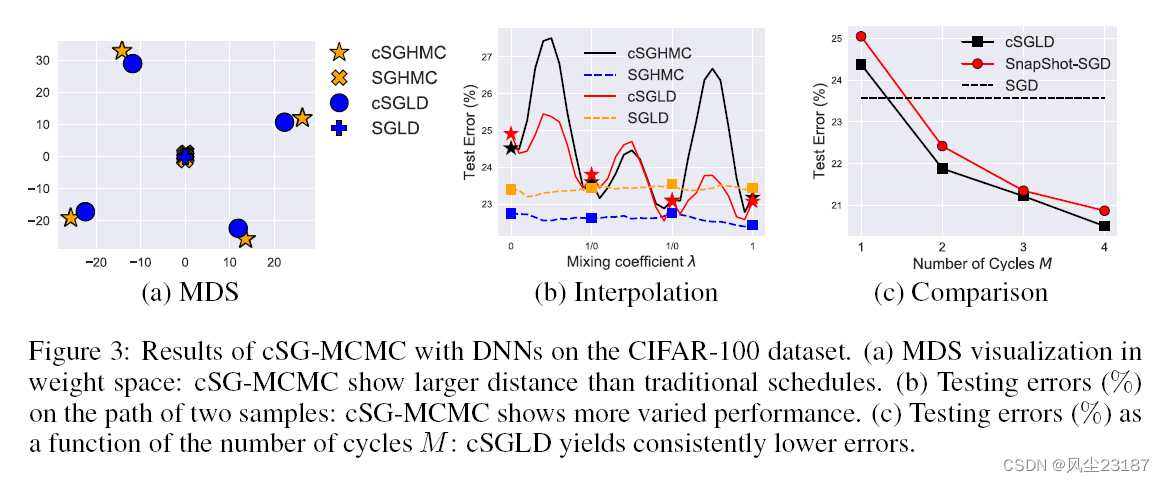
“cSGLD测试错误与非循环变量比较”)
6. 将sg-mcmc扩展到神经网络
到目前为止,我们一直在分析一个简单的例子,但cSG-MCMC和SGLD显然都适用于更大的数据集和神经网络。
因此,我们将数据集更改为CIFAR-10数据集,这是一个包含10个类的图像数据集。
我们的似然是分类分布,我们通过应用nn得到正确的能量函数U(θ)U(\theta)U(θ)。CrossEntropy 损失函数。
我们使用pytorch-lightning来构建模型,但主要成分在优化器(optimizer)中。
#hide
from pl_bolts.datamodules import CIFAR10DataModule
import torch
from torch.nn import functional as F
from torch import nn
from torch.optim.optimizer import Optimizer
from pytorch_lightning.core.lightning import LightningModule
from pytorch_lightning import Trainer, seed_everything
import pytorch_lightning as pl
import matplotlib.pyplot as plt
import torchvision
from pytorch_lightning.loggers import TensorBoardLogger
dataset = CIFAR10DataModule(data_dir=".")# visualize a batch
x,y = next(iter(dataset.train_dataloader()))
_ = plt.imshow(torchvision.utils.make_grid(x).permute(1,2,0))Clipping input data to the valid range for imshow with RGB data ([0…1] for floats or [0…255] for integers).
优化器:
class OptimizerSGLD(Optimizer):""" Optimizer that allows for cyclic learning rate, stochastic mcmc and normal sgd."""def __init__(self, net, lr_max=1e-3, lr_min=1e-5, max_step = 10e3, noise=True, noise_part2=True):super(OptimizerSGLD, self).__init__(net.parameters(), {})self.net = netself.lr_max = lr_maxself.lr_min = lr_minself.lr = self.lr_maxself.max_step = max_stepself.it=0self.noise = noiseself.noise_part2 = noise_part2 # parameter overwriting noise to only have it for sampling stage@torch.no_grad()def step(self, batch_size=1, num_data=1):# Update learning rate:self.it +=1ratio = (self.it % self.max_step)/self.max_stepself.lr = self.lr_max*(1-ratio) + self.lr_min*ratioself.net.log("learning_rate", self.lr)if self.noise_part2:if ratio > 0.5:self.noise = Trueelse:self.noise = False# Update parameters:for name, par in self.net.named_parameters():newpar = par - 0.5*self.lr*par.grad if self.noise:newpar += torch.normal(torch.zeros_like(par), std=self.lr)par.copy_(newpar)class LitMNIST(LightningModule):def __init__(self, lr_max=1e-3, lr_min=1e-5, max_step = 10e3, noise=True, noise_part2=True):super().__init__()self.layer_1 = nn.Conv2d(3, 16, 3)self.layer_2 = nn.Conv2d(16, 32, 3)self.linear1 = nn.Linear(1152, 128)self.linear2 = nn.Linear(128, 10)self.criterion = nn.CrossEntropyLoss()# Metricsself.train_acc = pl.metrics.Accuracy()self.val_acc = pl.metrics.Accuracy()# Initialize optimizerself.opt = OptimizerSGLD(self, lr_max, lr_min, max_step, noise=noise, noise_part2=noise_part2)def forward(self, x):batch_size, channels, width, height = x.size()x = F.relu(self.layer_1(x))x = F.max_pool2d(x,2)x = F.relu(self.layer_2(x))x = F.max_pool2d(x,2)x = x.view(batch_size,-1)x = F.relu(self.linear1(x))x = self.linear2(x)return xdef step(self, batch, batch_idx, phase):x, y = batchlogits = self(x)loss = self.criterion(logits, y)self.log(f"{phase}/loss", loss)if phase == "train":self.train_acc(logits,y)if phase == "val":self.val_acc(logits,y)return lossdef training_step(self, batch, batch_idx):return self.step(batch, batch_idx, "train")def validation_step(self, batch, batch_idx):for key, val in self.named_parameters():self.log(f'param/{key}', value = val.abs().mean())return self.step(batch, batch_idx, "val")def training_epoch_end(self, outs):self.log('train/accuracy', self.train_acc.compute())#self.log("learning_rate", self.optimizers().lr)def validation_epoch_end(self, outs):self.log('val/accuracy', self.val_acc.compute())def configure_optimizers(self):return self.opt
7. 比较cSGMCMC、SGLD和SGD
考虑到上面的优化器,很容易修改它来运行不同的算法,我们将在一个简单的运行中比较这三种算法。
configs = {'cSGMCMC-temp' : {'max_step' : 30e3,'noise' : True,'noise_part2' : True},'cSGMCMC' : {'max_step' : 30e3,'noise' : True},'SGLD' : {'max_step' : 1564*100,'noise' : True},'SGD' : {'max_step' : 1564*100,'noise' : False},
}for name, config in configs.items():model = LitMNIST(lr_max=1e-3, lr_min=1e-5, **config)logger = TensorBoardLogger("logs", name=name)trainer = Trainer(gpus=1, progress_bar_refresh_rate=0, logger=logger, max_epochs=100)trainer.fit(model, dataset)print(f"Finished training {name}")
输出:
GPU available: True, used: True
TPU available: False, using: 0 TPU cores
LOCAL_RANK: 0 - CUDA_VISIBLE_DEVICES: [0]| Name | Type | Params
-----------------------------------------------
0 | layer_1 | Conv2d | 448
1 | layer_2 | Conv2d | 4 K
2 | linear1 | Linear | 147 K
3 | linear2 | Linear | 1 K
4 | criterion | CrossEntropyLoss | 0
5 | train_acc | Accuracy | 0
6 | val_acc | Accuracy | 0
GPU available: True, used: True
TPU available: False, using: 0 TPU cores
LOCAL_RANK: 0 - CUDA_VISIBLE_DEVICES: [0]| Name | Type | Params
-----------------------------------------------
0 | layer_1 | Conv2d | 448
1 | layer_2 | Conv2d | 4 K
2 | linear1 | Linear | 147 K
3 | linear2 | Linear | 1 K
4 | criterion | CrossEntropyLoss | 0
5 | train_acc | Accuracy | 0
6 | val_acc | Accuracy | 0
Finished training cSGMCMC-temp
GPU available: True, used: True
TPU available: False, using: 0 TPU cores
LOCAL_RANK: 0 - CUDA_VISIBLE_DEVICES: [0]| Name | Type | Params
-----------------------------------------------
0 | layer_1 | Conv2d | 448
1 | layer_2 | Conv2d | 4 K
2 | linear1 | Linear | 147 K
3 | linear2 | Linear | 1 K
4 | criterion | CrossEntropyLoss | 0
5 | train_acc | Accuracy | 0
6 | val_acc | Accuracy | 0
Finished training cSGMCMC
GPU available: True, used: True
TPU available: False, using: 0 TPU cores
LOCAL_RANK: 0 - CUDA_VISIBLE_DEVICES: [0]| Name | Type | Params
-----------------------------------------------
0 | layer_1 | Conv2d | 448
1 | layer_2 | Conv2d | 4 K
2 | linear1 | Linear | 147 K
3 | linear2 | Linear | 1 K
4 | criterion | CrossEntropyLoss | 0
5 | train_acc | Accuracy | 0
6 | val_acc | Accuracy | 0
Finished training SGLD
Finished training SGD
8.结果
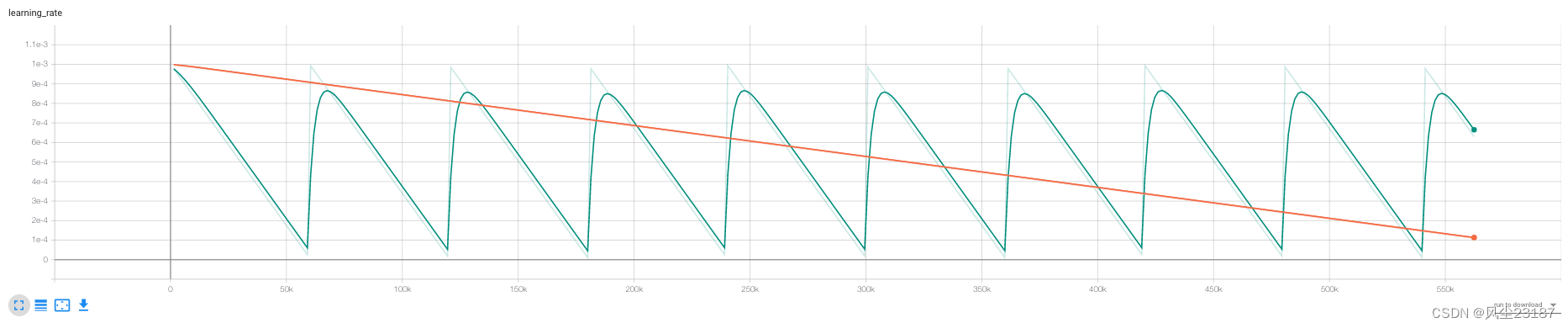
“迭代的学习率”)
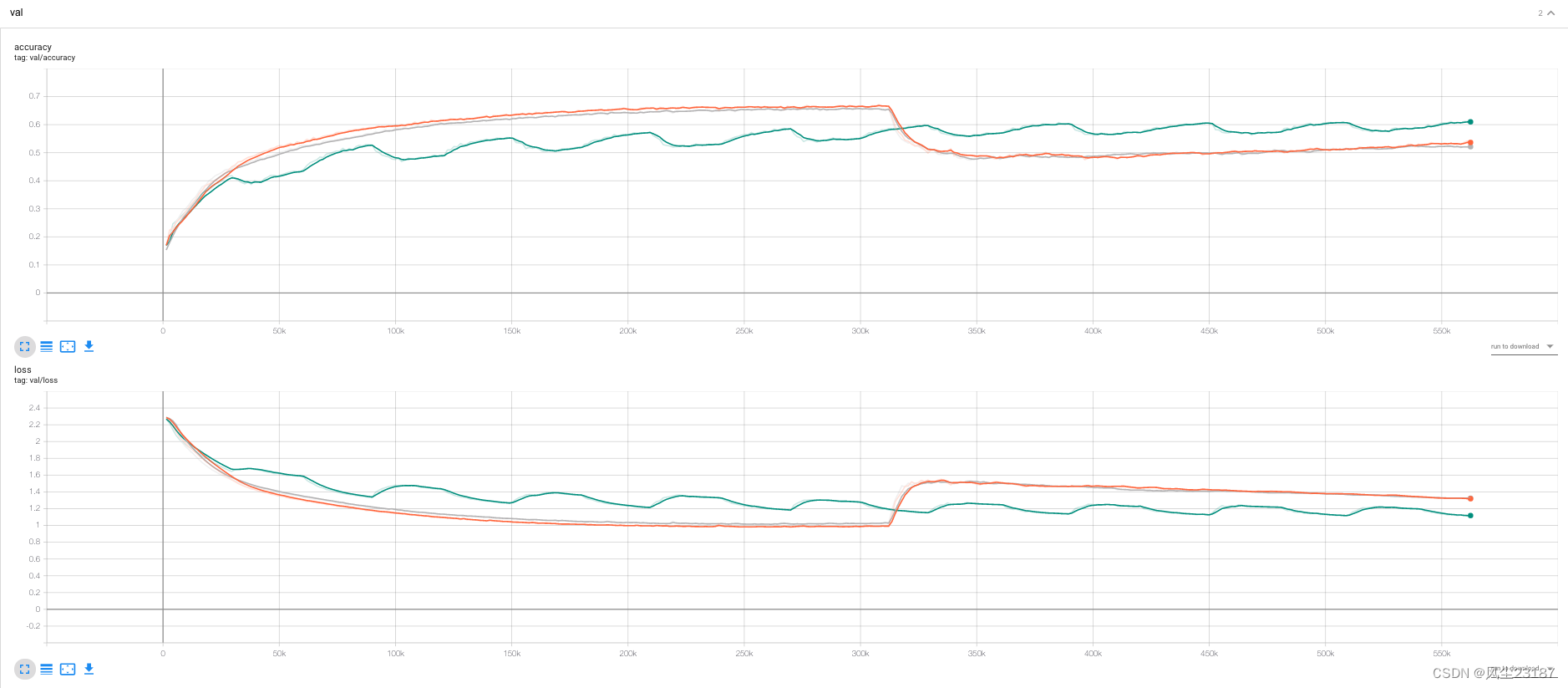
“迭代的损失和精度”)
说明如何实现算法,不幸的是没有足够的时间适当地评估不同的优化算法。一些研究结果:
-在这种情况下,我们期望SGD比其他备选方案执行得更好,因为SGD正在寻找最大后验 θMAX=argmaxθP(D∣θ)\theta_{MAX} = argmax_{\theta} P(D|\theta)θMAX=argmaxθP(D∣θ),而其他SGD是在“周围”找到一个后验分布。
- SGD和SGLD的比较似乎证实了这一点。
- 我们看到cSGLD在振荡,根据cSGLD的论文,每个最优化应该是不同模式的分布。如果我们通过整合整个分布来估计损失,测试损失应该比SGD和SGLD要低。