题目:Understanding the Users and Videos by Mining a Novel Danmu Dataset
作者:Guangyi Lv, Kun Zhang, Le Wu, Enhong Chen, Tong Xu, Qi Liu, and Weidong He
发表:IEEE TRANSACTIONS ON BIG DATA, 2022
切入点:弹幕交流是否有助于更好的用户行为建模或视频分析?
解决方案:建立大数据集,并进行基本分析
一、数据集生成
针对这一问题,本文通过引入一个从bilibili平台收集的弹幕数据集,对用户和视频进行了初步的分析尝试。该数据集包含1.7TB的视频和弹幕,涉及8个视频类别,790万弹幕记录和480万视频帧。
数据集下载网址:“http://bigdata.ustc.edu.cn/dataset/Danmus”
对数据集的预处理包括:弹幕文本翻译、字体颜色字段缩减、视频关键帧抽取等。
二、对数据集的统计分析
1.弹幕句子长度情况:短

2.弹幕数随播放时间的分布:先多后少
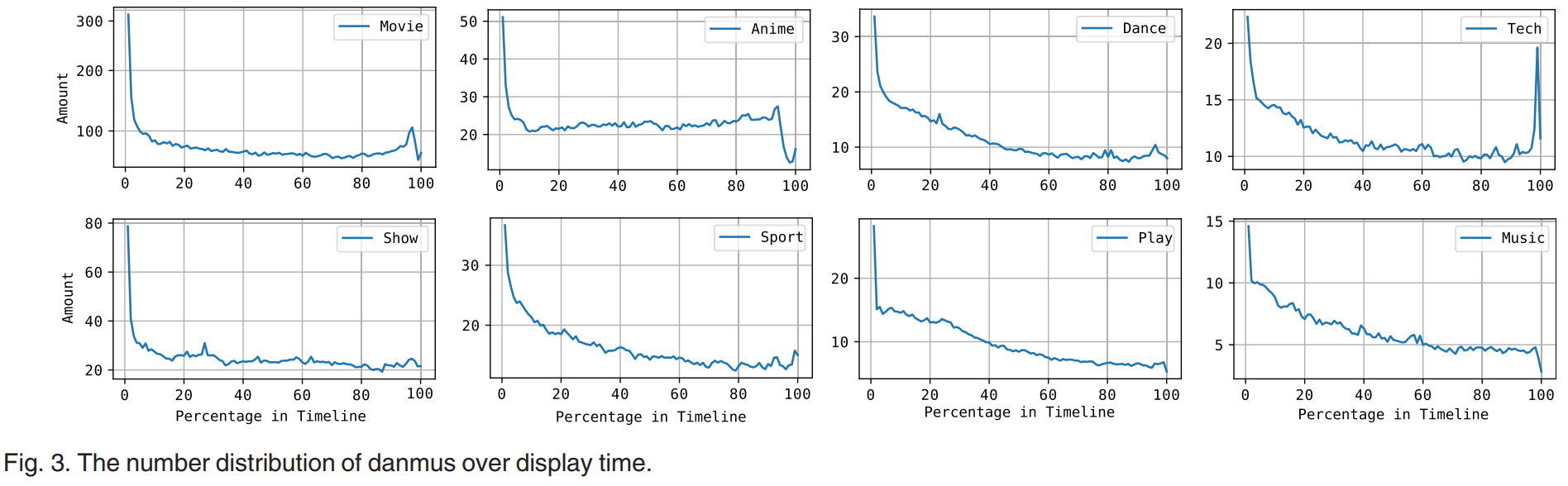
3.颜色:白为默认,红色最多

4~5、弹幕类型与表情使用情况:

三、对数据集的语义分析
1.style与主题,作者利用Gensim Tool在每个类别中生成danmus评论的主题信息,结果如表1:

2.特有表达。本文方法基于词向量,结果如表2:

根据这些现象可以得出结论,当表达特定的意义或特定的对象时,弹幕包含了更多的领域知识,具有更精确的意义。
3.弹幕语义嵌入(Semantic Embedding)
处理文本数据时常用Bag-Of-Word或TF-IDF作为特征,它们通常擅长对长文档建模。弹幕可以被看作是一种特殊类型的短文本。此外,由于深度学习技术在许多NLP任务中被广泛采用,本文对弹幕进行深度语义嵌入(deep semantic embedding).得到弹幕语义表达后,完成聚类分析,结果如图7
|
| 蓝色:完结撒花 红色:233333,哈哈哈哈哈哈 粉色:后宫 紫色:flag,插旗 |

5.弹幕与用户行为,评分公式如下:

结果表3:

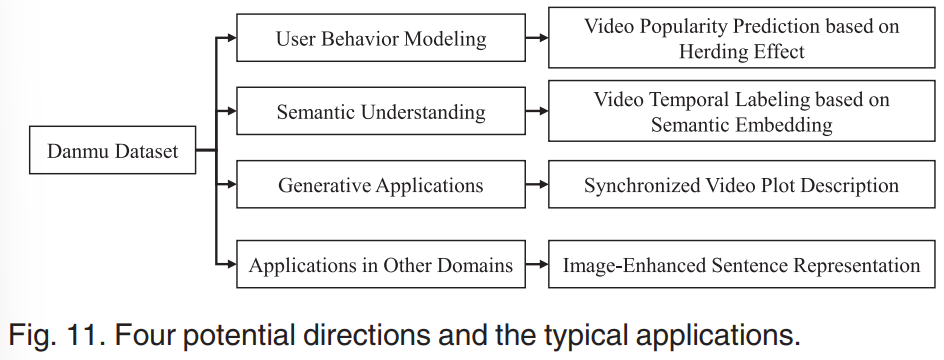
四、数据集的潜在应用
为进一步展示弹幕数据集的潜在价值,展示一些工作,包括用户行为建模、细粒度视频理解和标记、视频情节生成和图像增强语义理解。对于每个应用程序,还提出了其可能的未来发展方向。如图11所示。