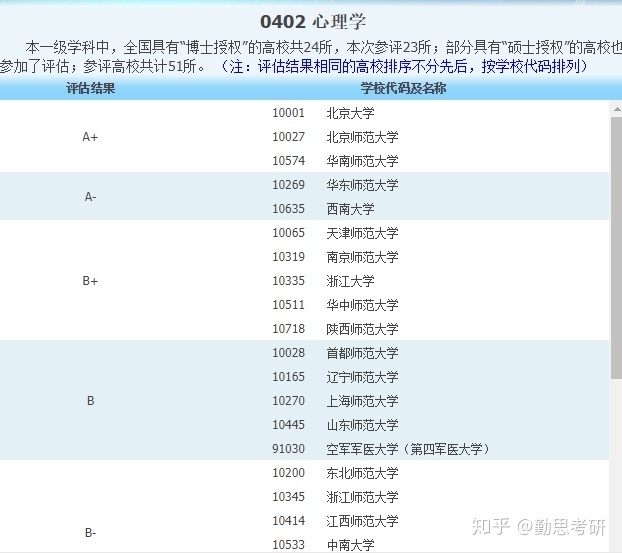
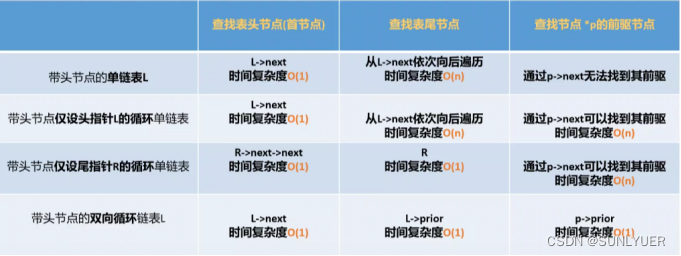
神经网络模型训练简记(一)
- 一、概念介绍
- 1.1人工智能、机器学习、神经网络与深度学习
- 1.2backbone与pretrain_model
- 1.3batch_size、learning_rate、epoch与iteration
- 1.4模型评价指标
- 二、官方数据集简介
- 2.1ImageNet数据集
- 2.2 ILSVRC竞赛
- 2.3 MS COCO数据集
- 2.4 PASCAL VOC数据集
- 2.5 Cityscapes数据集
- 三、机器视觉网络模型分类及简介
- 3.1图像分类
- 3.1.1LeNet
- 3.1.2AlexNet
- 3.1.3ZFNet
- 3.1.4VGGNet
- 3.1.5GoogLeNet
- 3.1.6Inception V2
- 3.1.7Inception V3
- 3.1.8ResNet
- 3.1.9GBD-Net
- 3.1.10Inception V4、Inception-ResNet-v1与Inception-ResNet-v2
- 3.1.11SENet
- 未完待续
- 参考文档
一、概念介绍
首先进行几个概念介绍:
1.1人工智能、机器学习、神经网络与深度学习
(1)人工智能:人工智能是研发用于模拟、延伸和拓展人的智能的理论、方法、技术及应用系统的一门技术学科。人工智能是个较为宽泛的概念,存在很多的分支,机器学习是实现人工智能的一种比较热门而有效的分支。
(2)机器学习:机器学习是一门开发算法和统计模型的科学,它依靠计算机系统研究怎样通过算法和模型,来获取新的知识和技能,达到模拟或实现人类的学习行为。机器学习的实现可分为两步:训练与预测,即归纳和演绎。
(3)神经网络与深度学习: 神经网络与深度学习是机器学习的一种算法,所以实现步骤与机器学习类似。神经网络是受到人类大脑的生理结构——互相交叉相连的神经元启发被提出,自1940s被首次提出至今经历了长期的发展。神经网络包含多个网络层,通过使用数据对各层各神经元的权重与阈值进行调整训练来拟合输入与输出的关系。而网络层数越多,能够拟合的关系越复杂,一般超过三层的神经网络就被称为深度神经网络,对应的实现过程就被称为深度学习。
1.2backbone与pretrain_model
(1)backbone:网络模型的主干部分,如ResNet、VGGNet等,主要用于特征提取。通常是一些被证明特征提取效果好的成熟网络,将其接在自己网络中,并搭配pretrain_model,提升自己网络模型的效果。
(2)pretrain_model:使用backbone在一些官方大型图像数据集如ImageNet、MSCOCO、PASCAL VOC上训练好的模型,以pretrain_model作为自己搭建的网络的预训练模型,可以提升模型训练效果。
1.3batch_size、learning_rate、epoch与iteration
batch_size、learning_rate、epoch属于模型训练的超参数,超参数是在开始学习过程之前设置值的参数,而不是通过训练得到的参数数据。通常情况下,需要对超参数进行优化,设定一组最优超参数,以提高模型训练的性能。可以使用经验法则,在其他问题上使用复制值,或通过反复试验来搜索最佳值。
(1)batch_size:一次训练所选取的样本数。batch_size的大小影响模型的优化程度和速度,同时其上限会受到GPU内存的限制。
(2)learning_rate:网络模型每次参数更新的幅度,会影响模型训练的时间与模型收敛的效果。
(3)epoch:一次使用所有训练数据训练模型的过程。
(4)iteration:epoch除以batch_size就等于iteration,该参数并不是超参数。
1.4模型评价指标
模型训练完成后,需要对模型性能进行评价,以此确定是否已达到要求或需继续进行优化,模型评价指标较多,以下介绍几种常用的评价指标。
(1)混淆矩阵:绘制一个表格,表格每一行是真正的类别,每一列是预测的类别,这个列表矩阵即为混淆矩阵。例如在缺陷检测任务中,目标只分为两类,一类为1(合格品),一类为0(缺陷品),混淆矩阵如下:
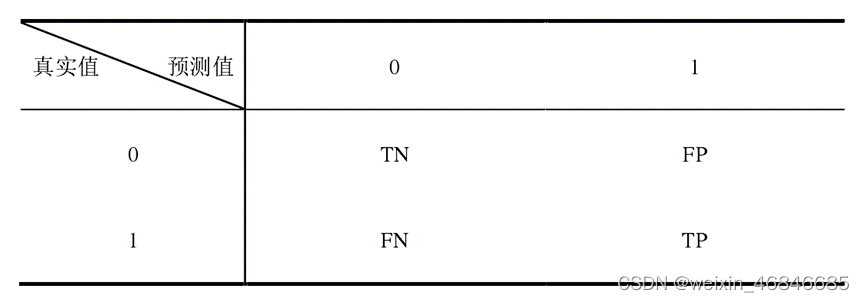
TP:对合格品进行判定,将合格品判定为合格品,判断正确;
TN:对不合格品进行判定,将不合格品判定为不合格品,判断正确;
FP:对不合格品进行判定,将不合格品判定为合格品,判断错误;
FN:对合格品进行判定,将合格品判定为不合格品,判断错误。
(2)正确率或准确率(Accuracy):对所有目标中所有类,判定正确的比例,公式如下

(3)平均正确率或准确率(Average per-class Accuracy):对所有目标中每个类别分别计算准确率,然后取算术平均值,公式如下:

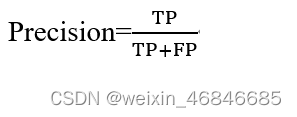
(4)精准率(Precision):判定为合格品中,判定正确的比例,公式如下
(5)召回率(Recall):针对合格品判定,判定正确的比例,公式如下

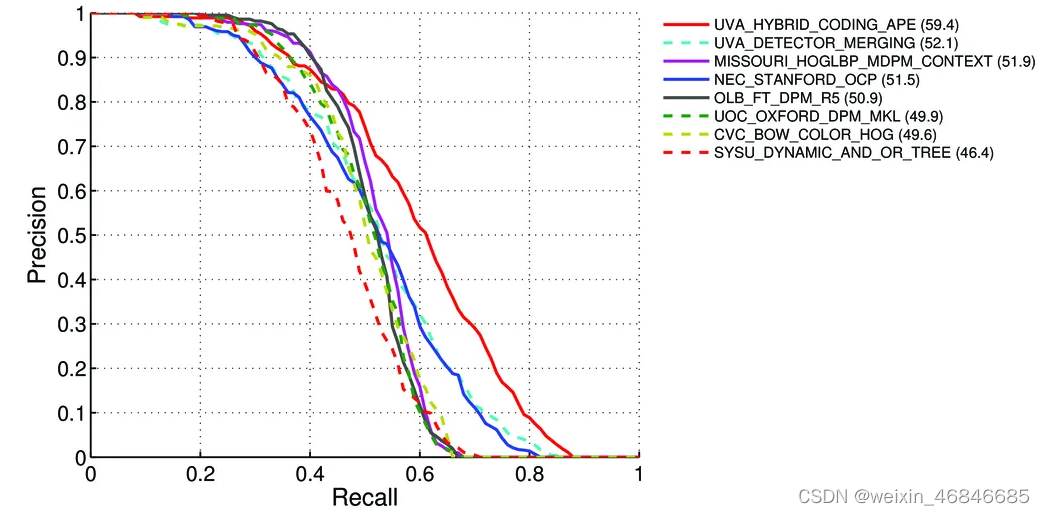
(6)PR曲线:理想情况下,精准率和召回率两者都越高越好。然而事实上这两者在某些情况下是矛盾的,精准率高时,召回率低;精准率低时,召回率高,可以通过观察PR曲线查看两者关系:
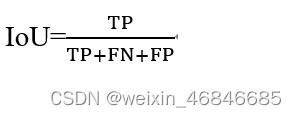
(7)交并比(Intersection over Union,IoU):每个类中真实值和预测值都为真在真实值与预测值有一值为真的比例,公式如下:
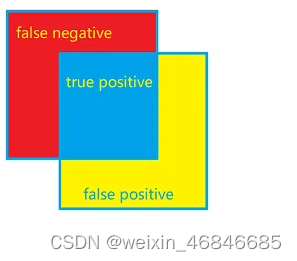
在目标检测或语义分割任务中,IoU定义为两个矩形交集的面积/两个矩形的并集面积,两个矩形分别为预测框与标记框:

(8)平均精度(Average Precision,AP):针对待检测所有目标中的某一类,计算平均精度。简单来说就是对PR曲线上的Precision值求均值。对于pr曲线来说,我们使用积分来进行计算。
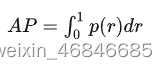
在实际应用中,我们并不直接对该PR曲线进行计算,而是对PR曲线进行平滑处理。即对PR曲线上的每个点,Precision的值取该点右侧最大的Precision的值。详细计算说明可参考知乎目标检测中的AP,mAP
(9)平均精度均值(mean Average Precision,mAP):是一个反映全局性能的指标,对待检测所有目标中的每一类计算平均精度,然后取均值。
二、官方数据集简介
2.1ImageNet数据集
ImageNet 是一个包含超过 1500 万张带标签的高分辨率图像的数据集,大约有 22,000 个类别,并在至少100万张图像中提供了边框。ImageNet包含2万多个典型类别,例如“气球”或“草莓”,每一类包含数百张图像。尽管实际图像不归ImageNet所有,但可以直接从ImageNet免费获得标注的第三方图像URL。官方网站:ImageNet。

AI研究员李飞飞从2006年开始研究ImageNet的想法。在大多数AI研究专注于模型和算法的时候,李飞飞则希望扩展和改进可用于训练AI算法的数据。2007年,李飞飞与普林斯顿大学教授克里斯蒂安·费尔鲍姆(Christiane Fellbaum)会面讨论了该项目,他是WordNet的创建者之一。之后李继续从WordNet的单词数据库开始构建ImageNet,并使用了其许多功能。作为普林斯顿大学的助理教授,李飞飞组建了一个研究团队,致力于ImageNet项目。他们使用Amazon Mechanical Turk来帮助分类图像。他们在2009年美国佛罗里达州举行的计算机视觉与模式识别会议(CVPR)上首次以学术海报的形式展示了自己的数据库。
2.2 ILSVRC竞赛
ILSVR(ImageNet Large Scale Visual Recognition Competition)是由ImageNet所举办的年度大规模视觉识别挑战赛,自2010年开办以來,全球各知名AI企业莫不以取得此项比赛最高名次为殊荣,以宣告其图像识别技术已达登封之境。
ILSVRC 使用 ImageNet 的一个子集,其中包含 1000个类别,每个类别有大约 1000 张图像,总共有大约120万张训练图像、50,000张验证图像和100,000张测试图像。
竞赛中评比的Top-5 error rate分数,其计算方式是每位参赛者针对某张图片进行预测,所给出的五个最有可能的预测中如果有一个为正确就算答对,如果沒有一個正确则算错误。
2.3 MS COCO数据集
MS COCO的全称是Microsoft Common Objects in Context,是微软于2014年出资标注的数据集,与ImageNet 竞赛一样,被视为是计算机视觉领域最受关注和最权威的比赛之一。MS COCO是一个非常大型且常用的数据集,其中包括了目标检测,分割,图像描述等,官网地址:COCO。
其主要特性如下:
- Object segmentation: 目标级分割
- Recognition in context: 图像情景识别
- Superpixel stuff segmentation: 超像素分割
- 330K images (>200K labeled): 超过33万张图像,标注过的图像超过20万张
- 1.5 million object instances: 150万个对象实例
- 80 object categories: 80个目标类别
- 91 stuff categories: 91个材料类别
- 5 captions per image: 每张图像有5段情景描述
- 250,000 people with keypoints: 对25万个人进行了关键点标注

当在ImageNet竞赛停办后,COCO竞赛就成为是当前目标识别、检测等领域的一个最权威、最重要的标杆,也是目前该领域在国际上唯一能汇集Google、微软、Facebook以及国内外众多顶尖院校和优秀创新企业共同参与的大赛。
该数据集主要解决3个问题:目标检测,目标之间的上下文关系,目标的2维上的精确定位。COCO数据集有91类,虽然比ImageNet和SUN类别少,但是每一类的图像多,这有利于获得更多的每类中位于某种特定场景的能力,对比PASCAL VOC,其有更多类和图像。
2.4 PASCAL VOC数据集
PASCAL全称:Pattern Analysis, Statical Modeling and Computational Learning,是一个由欧盟资助的网络组织。
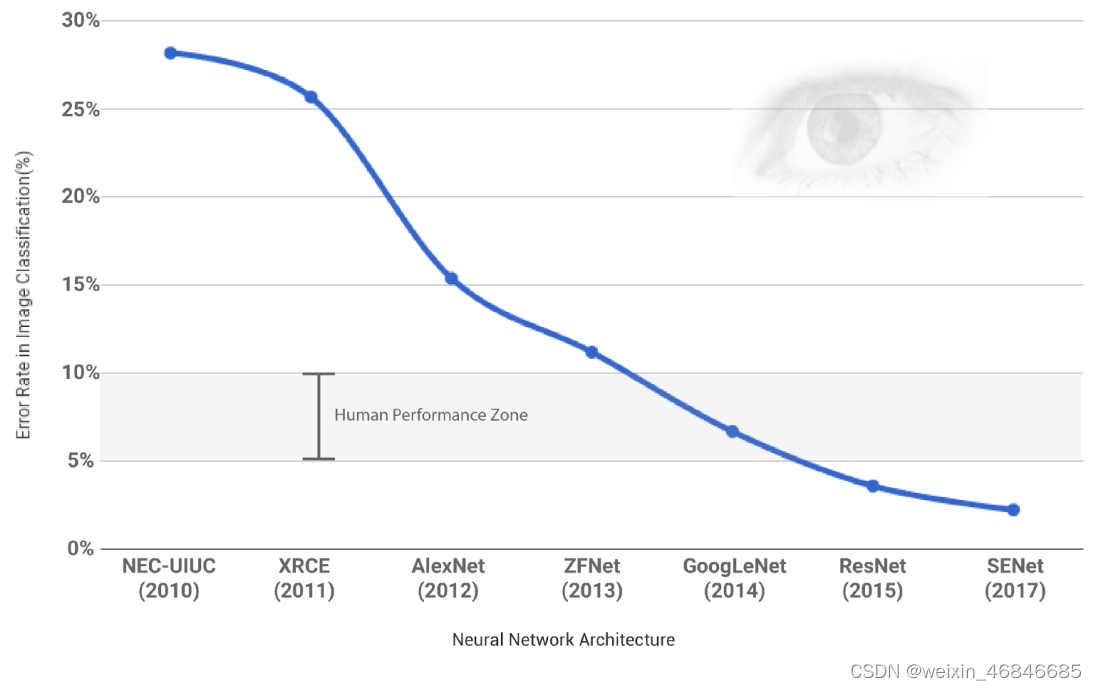
PASCAL VOC (The PASCAL Visual Object Classes )2007 和 2012 数据集总共分 4 个大类:vehicle、household、animal、person,总共 20 个小类(加背景 21 类),官方网站:The PASCAL Visual Object Classes Homepage。预测的时候是只输出下图中黑色粗体的类别:
数据集主要关注分类和检测,也就是分类和检测用到的数据集相对规模较大。关于其他任务比如分割,动作识别等,其数据集一般是分类和检测数据集的子集。
PASCAL VOC挑战赛 是一个世界级的计算机视觉挑战赛, 很多优秀的计算机视觉模型比如分类,定位,检测,分割,动作识别等模型都是基于PASCAL VOC挑战赛及其数据集上推出的,尤其是一些目标检测模型(比如大名鼎鼎的RCNN系列,以及后面的YOLO,SSD等)。
PASCAL VOC从2005年开始举办挑战赛,每年的内容都有所不同,从最开始的分类,到后面逐渐增加检测,分割,人体布局,动作识别(Object Classification 、Object Detection、Object Segmentation、Human Layout、Action Classification)等内容,数据集的容量以及种类也在不断的增加和改善。该项挑战赛催生出了一大批优秀的计算机视觉模型(尤其是以深度学习技术为主的)。

我们知道在 ImageNet挑战赛上涌现了一大批优秀的分类模型,而PASCAL挑战赛上则是涌现了一大批优秀的目标检测和分割模型,这项挑战赛已于2012年停止举办了,但是研究者仍然可以在其服务器上提交预测结果以评估模型的性能。
虽然近期的目标检测或分割模型更倾向于使用MS COCO数据集,但是这丝毫不影响 PASCAL VOC数据集的重要性,毕竟PASCAL对于目标检测或分割类型来说属于先驱者的地位。对于现在的研究者来说比较重要的两个年份的数据集是 PASCAL VOC 2007 与 PASCAL VOC 2012,这两个数据集频频在现在的一些检测或分割类的论文当中出现。
2.5 Cityscapes数据集
Cityscapes是关于城市街道场景的语义理解图片数据集。它主要包含来自50个不同城市的街道场景,拥有5000张在城市环境中驾驶场景的高质量像素级注释图像(其中 2975 for train,500 for val,1525 for test, 共有19个类别);此外,它还有20000张粗糙标注的图像(gt coarse)。官方网站:The Cityscapes Dataset。

数据集下载一般有2-3个包,分别对应2-3个文件夹,即如下:
- leftImg8bit(11G),放置训练源图,按城市分子文件夹,存放png图片
- gtFine(241M),放置精细标注文件,按城市分子文件夹,存放png/json文件
- gtCoarse(1.3G),放置非精细标注的文件(该文件夹不是必须,可不使用)
- cityscapesscripts,放置处理脚本(该文件夹不是必须,可不使用)
三、机器视觉网络模型分类及简介
神经网络算法发展至今,在各个不同领域存在众多的网络模型,难以一一进行叙述,本章节主要围绕机器视觉领域内图像分类、目标检测、语义分割与实例分割四大任务中使用较广的网络模型进行简要介绍。
3.1图像分类
图像分类,是根据图像的不同特征,把不同类别的目标区分开来的图像处理方法。它利用计算机对图像进行定量分析,把图像或图像中的每个像元或区域划归为若干个类别中的某一种,以代替人的视觉判读。
3.1.1LeNet
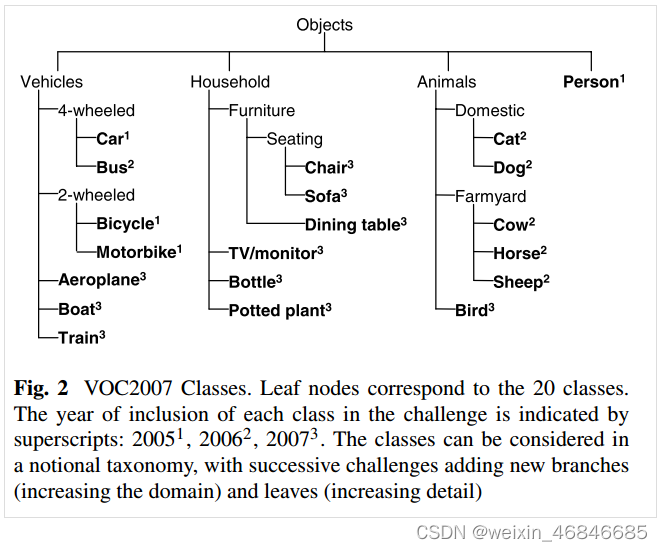
一般LeNet即指代LeNet-5,LeNet-5是Yann LeCun等人在多次研究后提出的最终卷积神经网络结构,诞生于1994年,是最早的卷积神经网络之一,论文链接。
LeNet-5包含七层,不包括输入,每一层都包含可训练参数(权重),当时使用的输入数据是32*32像素的图像。
小结:
LeNet的设计较为简单,因此其处理复杂数据的能力有限;此外,在近年来的研究中许多学者已经发现全连接层的计算代价过大,而使用全部由卷积层组成的神经网络。
现在在研究中已经很少将LeNet使用在实际应用上,对卷积神经网络的设计往往在某个或多个方向上进行优化,如包含更少的参数(以减轻计算代价)、更快的训练速度、更少的训练数据要求等。
3.1.2AlexNet
AlexNet网络是2012年ISLVRC 2012竞赛的冠军网络,它是由Hinton和他的学生Alex设计的。
它以Top-5错误率15.4%超过10%的悬殊差距,轻取Xerox团队所使用的SVM机器学习算法而夺下桂冠,也从此开始,各种创新的神经网络模型如雨后春笋出现,ILSVRC竞赛渐由Deep learning取代了SVM,指标成绩Top-5错误率也在激烈竞争下屡创新低,逐步优于人眼识别的极限5~10%,论文链接。
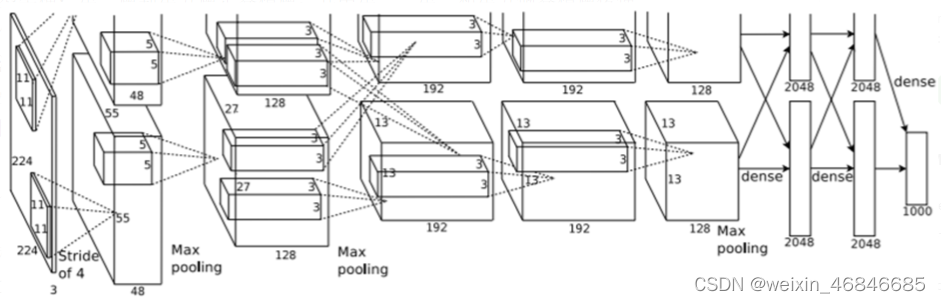
AlexNet的整个网络结构由5个卷积层和3个全连接层组成,深度总共8层,相较于 LeNet 模型更深。
小结:
1.AlexNet首次利用GPU进行网络加速训练。
2.使用了ReLU激活函数,而不是传统的Sigmoid激活函数以及Tanh激活函数,成功解决了Sigmoid在网络较深时的梯度弥散问题。虽然ReLU激活函数在很久之前就被提出了,但是直到AlexNet的出现才将其发扬光大。
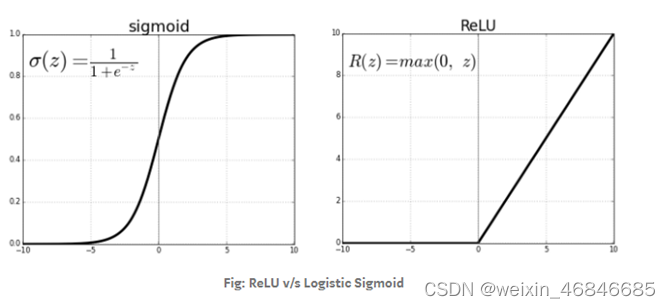
3.使用了LRN局部响应归一化。对局部神经元的活动创建竞争机制,使得其中响应比较大的值变得相对更大,并抑制其他反馈较小的神经元,增强了模型的泛化能力。在神经生物学中,有一个概念叫做侧抑制(lateral inhibitio ),指的是被激活的神经元会抑制它周围的神经元,LRN即模仿生物神经系统的侧抑制机制被提出。
4.在全连接层的前两层中使用了Dropout,Dropout是指在一次训练中随机挑选神经元使其不参与训练,从而减少网络模型对某些特征的过度依赖性,以减少过拟合。Dropout虽有单独的论文论述,但是AlexNet将其实用化,通过实践证实了它的效果。在AlexNet中主要是最后几个全连接层使用了Dropout。
5.使用重叠的最大池化。此前CNN中普遍使用平均池化,AlexNet全部使用最大池化,避免平均池化的模糊化效果。并且AlexNet中提出让步长比池化核的尺寸小,这样池化层的输出之间会有重叠和覆盖,提升了特征的丰富性。
3.1.3ZFNet
ZFNet是Matthew D.Zeiler 和 Rob Fergus 在2013年撰写的论文Visualizing and Understanding Convolutional Networks中提出的,是当年ILSVRC的冠军。ZFNet使用反卷积(deconv)和可视化特征图来达到可视化AlexNet的目的,并指出不足,最后修改网络结构,提升分类结果,论文链接。
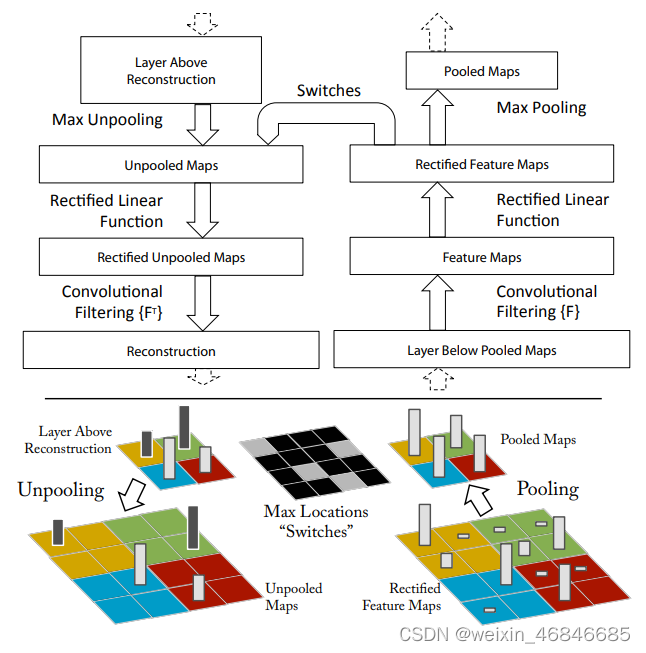
论文使用反卷积网络(deconvnet)进行可视化。反卷积网络可以看成是卷积网络的逆过程,但它不具有学习的能力,只是用于探测卷积网络。
反卷积网络依附于网络中的每一层,不断的间特征图映射回输入图并可视化。过程中将需要检测的激活图送入反卷积网络,而其余激活图都设置为0。进入反卷积网络后,经过1.unpool;2.rectify;3.filter;不断生成新的激活图,直到映射回原图。大致流程如下:
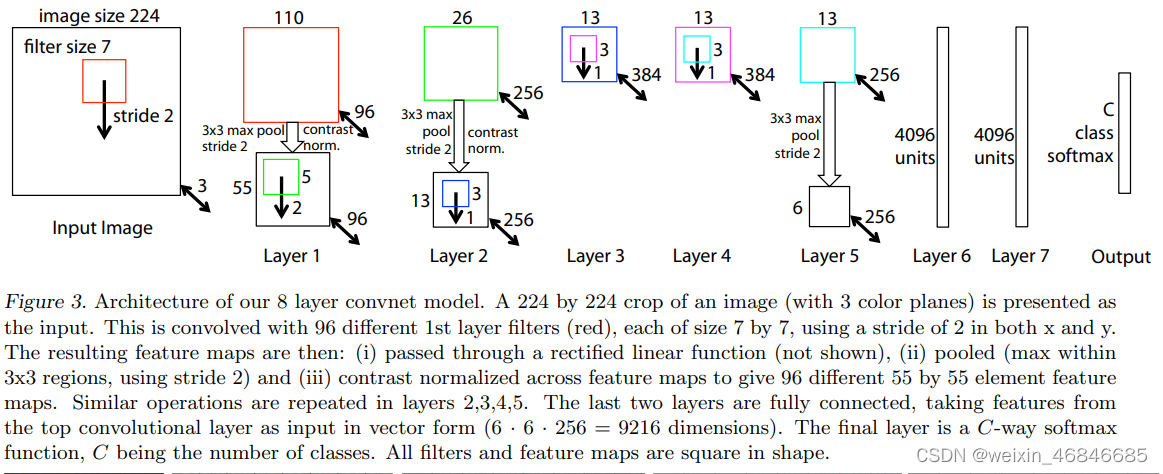
ZFNet基本沿袭了AlexNet的结构,一个不同点在于AlexNet使用两块GPU并行计算,这也使得AlexNet将训练任务“稀疏”成了两部分,而ZFNet去掉了这一结构。
小结:
1.特征可视化。使用反卷积,可视化feature map,通过feature map可以看出,特征分层次体系结构。前面的层学习的是物理轮廓、边缘、颜色、纹理等特征,后面的层学习的是和类别相关的抽象特征。CNN学习到的特征具有平移和缩放不变性,但是,没有旋转不变性。

第二层主要相应图像的角点、边缘和颜色。
第三层具有更复杂的不变形,主要捕获相似的纹理。
第四层提取具有类别性的内容,例如狗脸、鸟腿等。
第五层提取具有重要意义的整个对象,例如键盘、狗等。
2.改进AlexNet网络。AlexNet中第一层使用11×11,步长为4的卷积核。然而在可视化时发现,第一层提取的信息多为高、低频,而中频的信息很少提取出。同时在可视化第二层是会发现由于步长过大引起的混叠伪像(aliasing artifact)。所以论文采用更小的卷积核(7*7)和更短的步长(2)。

3.1.4VGGNet
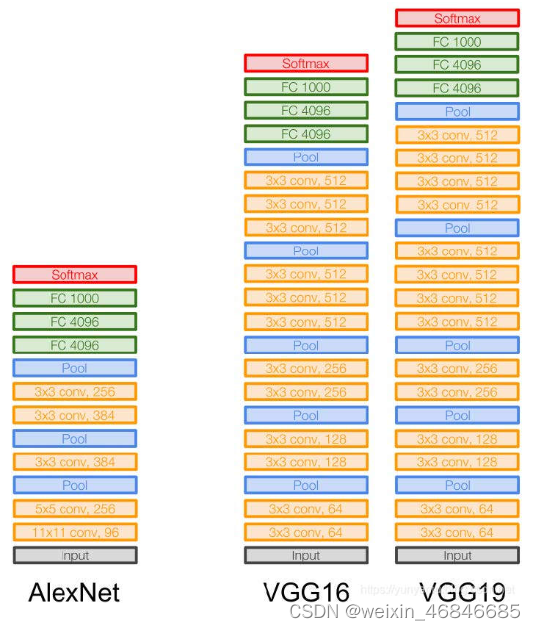
VGG在2014年由牛津大学研究组VGG(Visual Geometry Group)提出,斩获该年ImageNet竞赛中定位任务第一名和分类任务第二名。有多种网络模型,比如VGG11、VGG13、VGG16、VGG19,论文链接。
VGGNet比起AlexNet网络层数更深,并且使用小卷积核代替AlexNet中的中型及大型卷积核,网络模型由n个VGGBlock与3个全连接层组成。VGG Block 就是由不同数量 的 3x3 卷积层 (kernel size=3x3, stride=1, padding=”same”),以及 2x2 的 Maxpooling 组成 (pool size=2, stride=2)。
小结:
1.VGGNet在加深网络模型层数上做出了贡献,此前很少有网络模型超过10层,最多的VGG19有16个卷积层+3个全连接层,但VGG也存在局限性不能无限增加深度,当层数达到一定数量后,就会出现网络训练效果退化、梯度消失或梯度爆炸等问题。
2.使用小卷积核代替中型及大型卷积核,可以在保持感受野的同时减少参数量。
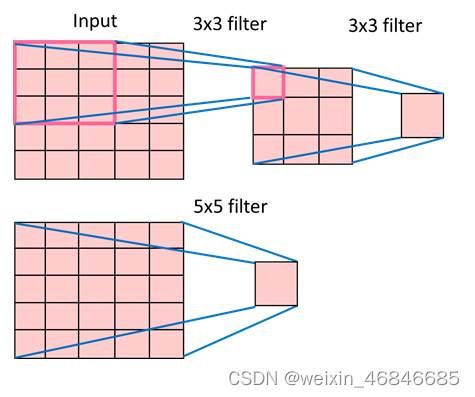
由下图可以看出使用两个 3x3 卷积核可以达到与 5x5 的卷积核相同的感受野,5x5 的卷积核的训练参数量为5x5=25,而 3x3 的卷积核所需要的参数量更少,只需要 3x3x2=18 個参数量 (只考虑权重不考虑偏置)。
3.1.5GoogLeNet
GoogLeNet是在2014年由Google团队提出,又称Inception-v1,斩获当年ImageNet竞赛中分类任务第一名。名称中的L大写是为了致敬LeNet,错误率为 6.67%,论文链接。
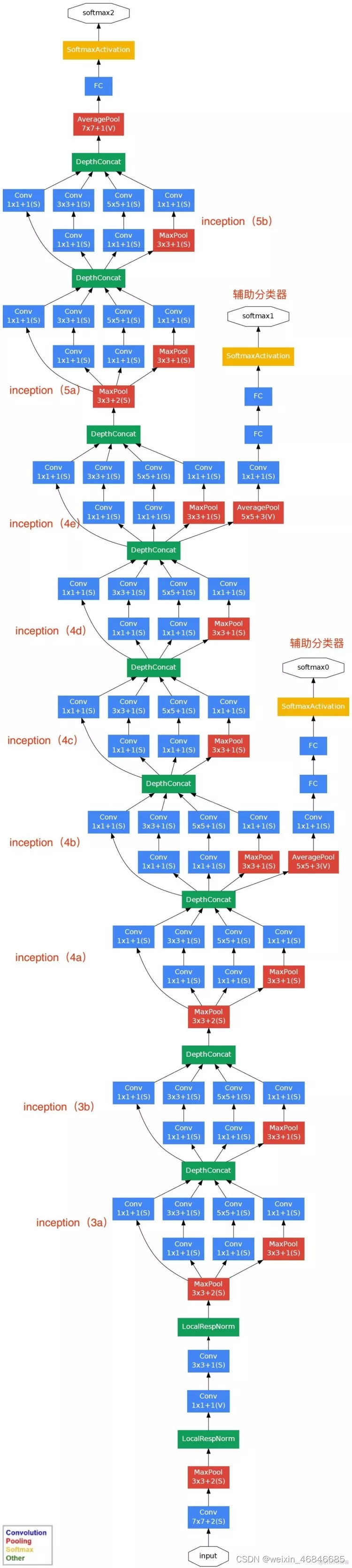
该网络共有22层,相较VGG而言网络层数加深,包含的Inception模块又加大了网络广度,所以带来了参数量过多的问题,因此使用了1×1卷积核进行降维。
小结:
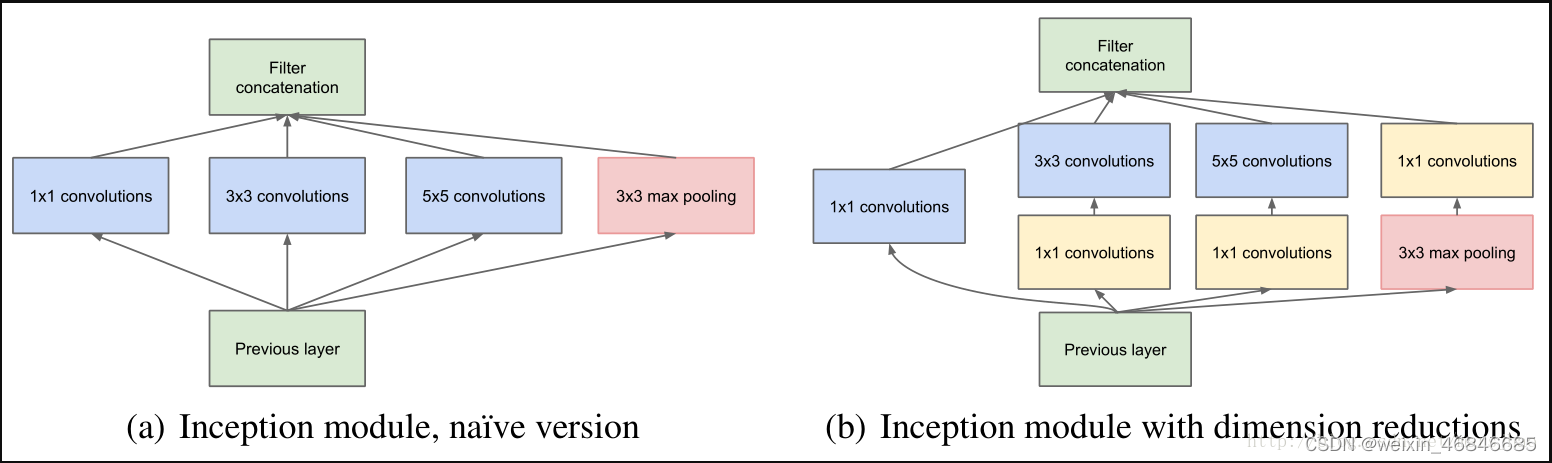
1.GoogLeNet最大的特点就是使用了Inception模块,它将卷积层或池化层并联,目的是对输入图像并行地执行多个卷积运算或池化操作,并将所有输出结果拼接为一个非常深的特征图。
2.Inception V1有22层深,比AlexNet的8层或者VGGNet的19层还要更深。但其计算量只有15亿次浮点运算,同时只有500万的参数量,仅为AlexNet参数量(6000万)的1/12,却可以达到远胜于AlexNet的准确率。
3.去除了最后的全连接层,用全局平均池化层(即将图片尺寸变为1*1)来取代它。全连接层几乎占据了AlexNet或VGGNet中90%的参数量,而且会引起过拟合,去除全连接层后模型训练更快并且减轻了过拟合。
4.中间层使用辅助分类节点(auxiliary classifiers),目的是为了帮助网络收敛,避免梯度消失。辅助单元的计算结果会乘以0.3当做补偿,和最后的LOSS相加作为最终损失函数来训练网络。从网络结构来看,是他有三个输出。
3.1.6Inception V2
2015 年 2 月 11 日,Google 在 arXiv(未提交给 ILSVRC)中提出了Inception-v2又称 BN-Inception,其错误率為 4.8%,超越了 5.1% 的人为错误率,论文链接。
Inception V2学习了VGGNet,用两个3×3的卷积代替5×5的大卷积(用以降低参数量并减轻过拟合),下图左边是 Inception 原本的架构,而右边是將 5x5 卷积层改为两个 3x3 卷积层后的 InceptionV2 架构。

还提出了著名的BatchNormalization(以下简称BN)方法。BN是一个非常有效的正则化方法,可以让大型卷积网络的训练速度加快很多倍,同时收敛后的分类准确率也可以得到大幅提高。BN在用于神经网络某层时,会对每一个mini-batch数据的内部进行标准化(normalization)处理,使输出规范化到N(0,1)的正态分布,减少了InternalCovariate Shift(内部神经元分布的改变)。
BN的论文指出,传统的深度神经网络在训练时,每一层的输入的分布都在变化,导致训练变得困难,我们只能使用一个很小的学习速率解决这个问题。而对每一层使用BN之后,我们就可以有效地解决这个问题,学习速率可以增大很多倍。
因为BN某种意义上还起到了正则化的作用,所以可以减少或者取消Dropout,简化网络结构。
小结:
1.用两个3×3的卷积代替5×5的大卷积,用以降低参数量并减轻过拟合。
2.使用了BN,增大了学习速率,显著提高了网络训练效率。
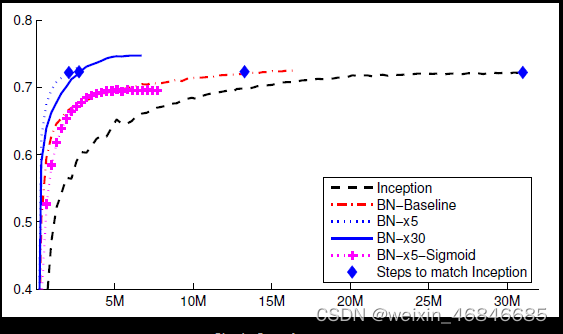
上图中设置如下:
Inception: Inception-v1 without BN
BN-Baseline: Inception with BN
BN-×5: Initial learning rate is increased by a factor of 5 to 0.0075
BN-×30: Initial learning rate is increased by a factor of 30 to 0.045
BN-×5-Sigmoid: BN-×5 but with Sigmoid
通过比较 Inception 和 BN-Baseline,可以看到使用 BN 可以显著提高训练速度。
通过观察 BN-×5 和 BN-×30,可以看到初始学习率可以大大提高,以更好地提高训练速度。
通过观察BN-×5-Sigmoid,可以看到Sigmoid的饱和问题可以被去除。
3.BN某种意义上还起到了正则化的作用,所以可以减少或者取消Dropout,简化网络结构。
3.1.7Inception V3
InceptionV3 跟 InceptionV2 出自于同一篇论文,发表于同年12月,论文中提出了以下四个网络设计的原则:
1.在前面层数的网络架构应避免使用 bottlenecks,虽然 bottlenecks 可以有效的降低参数计算量,但同时也会失去特征信息。从输入到输出特征的维度应缓慢的下降,避免维度过度地压缩;
2.高维度的特征更适合在网络的局部处理,并且在网络中增加非线性可以让训练更快;
3.空间聚合可以先通过低维度进行降维,不会影响模型能力;
4.增加网络的宽度与深度能够提高性能,如果能够平衡二者则可以达到更好的性能。
小结:
1.InceptionV3 尝试将卷积核分解成不对称的卷积核,与分解为对称的卷积核比较计算量:例如将 3x3卷积层分解为 1x3 及 3x1卷积层,可以減少 33% 的计算量;但如果分解为两个 2x2 的卷积层,只能减少11% 的计算量。
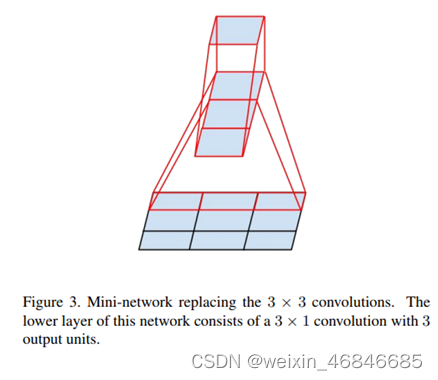
论文在实验中发现不对称卷积不适用于前面层的卷积,而是对于中等大小的卷积核效果比较好,中等尺寸范围在12到20之间。
InceptionV3 在中间卷积核的中等尺寸 17x17 使用 1x7 及 7x1 的卷积核,在降低参数量的同時,也增加了模型深度,获得了不错的结果。
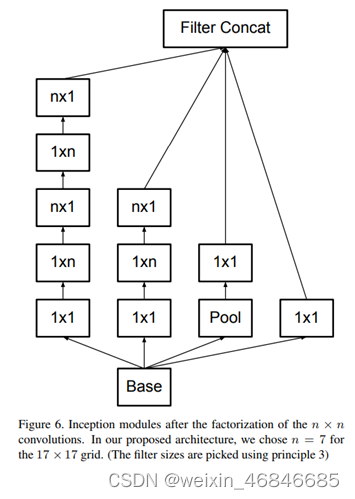
2.根据网络设计原则——高维度的特征更容易处理、有利于训练,因此在 8x8 卷积层中采用增加网络宽度的结构,以产生高维度的特征。

3.论文发现辅助分类节点在训练初期并不能加速收敛,只有训练快结束时,它才会略微提高网络精度。因此去掉第一个辅助分类节点,保留第二个。并且由于辅助分类器如果具有 Batch Normalization 或是 Dropout层,会使得模型性能更好,并认为它有 regularizer (正则化)的作用。
3.1.8ResNet
ResNet 在 2015 年由微软的何凯明博士提出,并于同年 ImageNet LSVRC 分类竞赛中获得了冠军,同时也在ImageNet detection、ImageNet localization、COCO detection和COCO segmentation等任务中均获得了第一名,此外还获得了 CVPR2016 最佳论文奖,论文链接。
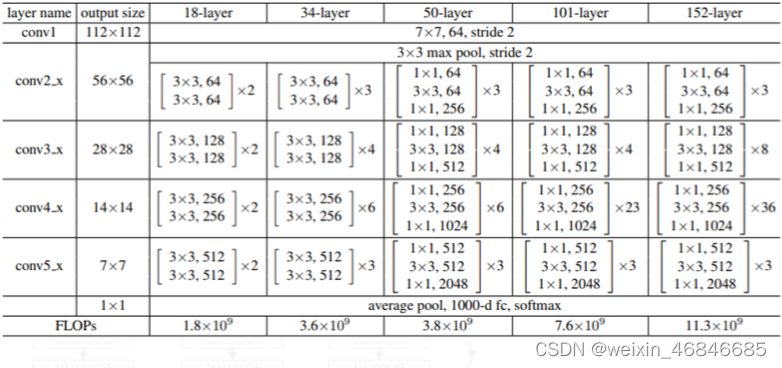
在竞赛中 ResNet 一共使用了 152层网络,其深度比 GoogLeNet 高了七倍多 ,并且错误率为 3.6%,而人类在 ImageNet 的错误率为 5.1%,已经达到小于人类的错误率的程度。
下图为 ResNet 不同层数的网络架构,可以看到第一层为 7x7 的卷积层,接上 3x3 Maxpooling,接着再使用大量的 Residual Block,最后使用全域平均池化 (Global Average Pooling) 并传入全连接层进行分类。
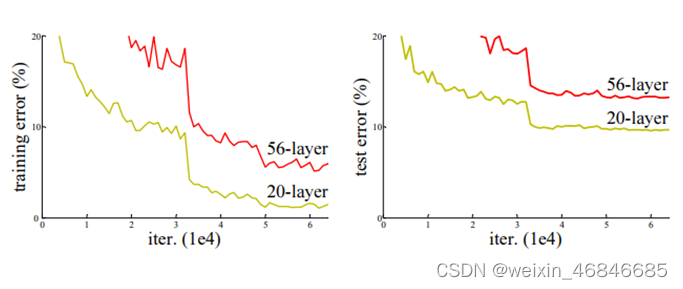
在 ResNet 问世之前,神经网络一直无法做更深层的训练,因为随着网络层数的增加达到一定的程度时,反而会降低训练准确率。由下图就可以看出 56 层的网络表現比 20层还差,但这不是因为过拟合的问题,而是深层网络的退化问题 (Degradation)。
Degradation 就是指当网络层数越来越高时,梯度在做反向传播的过程中消失,导致梯度无法传递对参数进行更新,以至于越深的网络训练效果越差。
小结:
1.ResNet使用了 Shortcut Connection 的结构,一共有两个分支:一个是将输入的 跨层传递,而另一个就是 F(x)。将这两个分支相加再送到激活函数中,这样的方式称作 Residual Learning,可以解決模型退化的问题 (Degradation)。
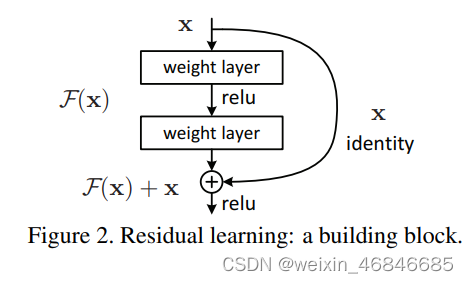
由 Residual Learning 我们可以知道输出为 F(x) + x,首先令这个式子等于 H(x),也就是输出值为 H(x) = F(x) + x。
当网络训练达到饱和的時候,F(x) 容易被优化成 0,这时只剩下 x,此时 H(x) = x,这样的情況就是 Identify mapping (恒等映射)。因此再深的网络也能保证准确率不会下降。
2.Residual 一样采用模组化的方式,针对不同深度的 ResNet,作者提出了两种Residual Block。
下图 (a)为基本的 Residual Block,使用连续的两个 3x3卷积层,并每两个卷积层进行一次 Shortcut Connection,用于ResNet-34。
下图 (b) 则是针对较深的网络所做的改进,称为 bottleneck。因为层数越高,导致训练成本变高,因此为了要降低维度,再送入 3x3 卷积层之前,会先通过 1x1卷积层降低维度,最后再通过 1x1 卷积层恢复原本的维度。用于 ResNet-50、ResNet-101、ResNet-152。
3.1.9GBD-Net
2016的ILSVRC竞赛是由中国的CUImage(商汤科技和港中文)提出的GBD-Net拿下,事实上,该年度ILSVRC其余类型的所有竞赛也都是由中国队伍所囊括。GBD-Net是基于ResNet-269进行扩充修改,虽然贵为2016的状元,但由于仅仅较前一年的ResNet提升了2.2%,且也无值得称颂的创新概念与亮点,因此GBD-Net无法如同历届其它model一样成为经典之作,论文链接。
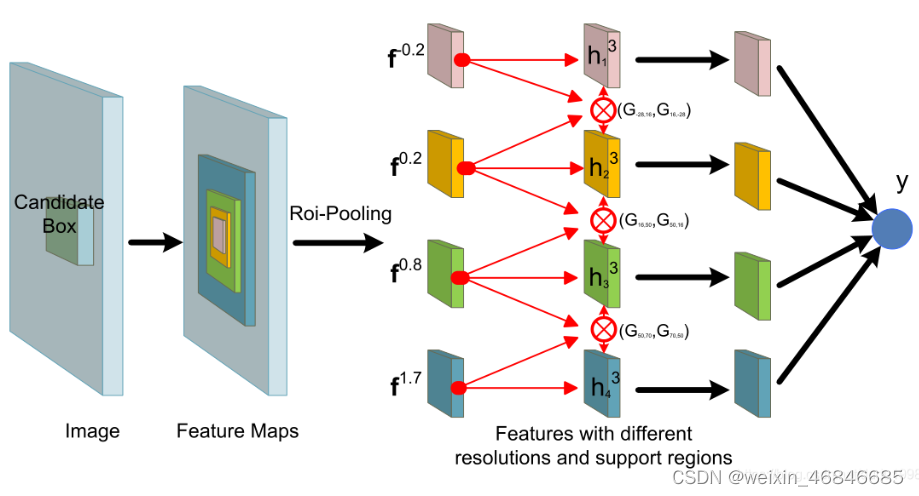
论文提出了一种门控双向神经网络(GBD网络),用于在特征学习和特征提取的过程中在来自不同proposal的特征之间传递信息。这种信息传递可以通过两个方向上相邻的proposal之间的卷积来实现,并且可以在不同层之中进行。

在不同分辨率的proposal之间根据不同的图像实例来控制传递信息是非常必要的,蓝色框代表GT,红色框是候选框,由于(a)中相似的局部特征和(b)中对遮挡区域的忽略,很难对proposal进行分类。
论文的思路就是来自不同分辨率和proposal的特征验证彼此的存在,例如兔子耳朵在局部区域的存在有助于加强兔子头的存在,而兔子上半身在更大的context区域存在也有助于验证兔子头的存在,因此作者建议具有不同分辨率和proposal的特征应该在多个层中互相传递信息,以便于在特征学习和特征提取过程中共同验证。
3.1.10Inception V4、Inception-ResNet-v1与Inception-ResNet-v2
InceptionV4, Inception-ResNet-v1, Inception-ResNet-v2 来自于同一篇论文,作者讨论了两种方式改善网络架构: 纯粹使用 Inception 架构、将 Inception 与 ResNet 结合,并比较其性能,论文链接。
首先讨论 InceptionV4 的架构,由好几个 Inception module 组成,并且在最后 softmax 输出之前加入了 Dropout (keep设定值为0.8),防止过拟合。

接着来看 Inception 与 ResNet 结合后的网络架构,作者讨论了两种架构 Inception-ResNet-v1、Inception-ResNet-v2,两者的整体结构一样,差別在于module 结构不太一样。
以下是 Inception 与 ResNet 结合的整体架构:
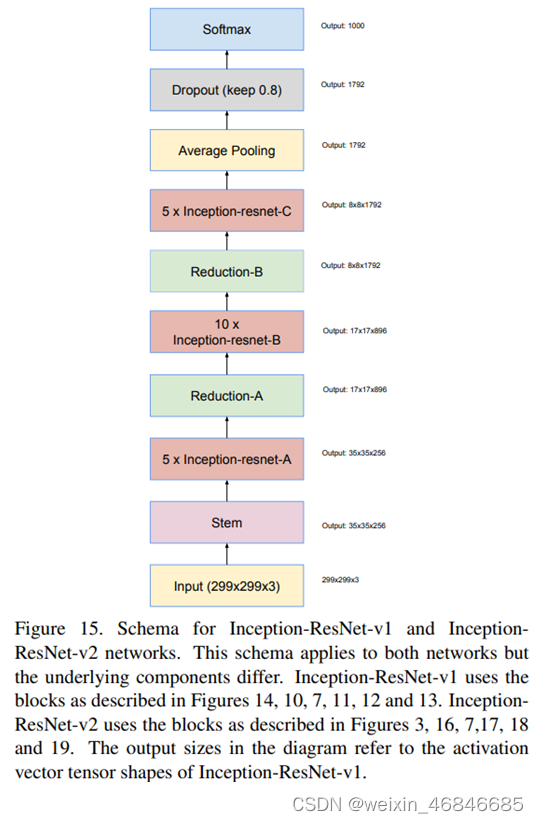
Inception-ResNet module就是将Inception 与 ResNet 结合,而且比 InceptionV4 更多数量,分別有 5 个 Inception-ResNet-A、10 个 Inception-ResNet-B、5 个 Inception-ResNet-C,并且在每一个Inception-ResNet module 前都加入 Batch Normalization 层。
从图中可以发现 Inception 部分的结构一样使用不对称卷积层、1x1 卷积层,但比之前精简,然后在最后一层使用 1x1 卷积层用来处理维度不一致的问题。

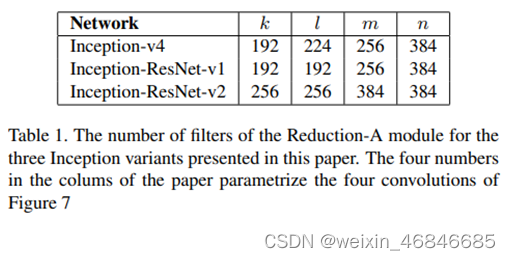
Inception-ResNet-v2 中 Stem、Reduction-A 使用跟 InceptionV4 一样的架构,其中 Reduction-A 的参数数量不同,下表为InceptionV4、Inception-ResNet-v1、Inception-ResNet-v2 中的Reduction-A 个别参数所使用的数量:
Inception-ResNet-v2 中Inception-ResNet module大致架构与 Inception-ResNet-v1 差不多,差別在于维度不同:

另外,作者在使用 ResNet 时发现当 filter 的个数太多 (超过 1000) 时,网络除了会处于不稳定,也会在训练早期就产生了网络输出为0的状态,就算降低学习率或是增加 Batch Normalization 层都沒办法解决。
因此作者在 ResNet 最后的相加之前使用 activation scaling,将输出做缩放后再做相加,可以使网络在训练过程中更稳定,其中 activation scaling 的值设定为 0.1~0.3。
小结:
1.InceptionV3 与 Inception-ResNet-v1 的准确率相当,同时两者的计算量也差不多;而 InceptionV4 与 Inception-ResNet-v2 的准确率也很接近,两者的计算量也是差不多的,但是 Inception-ResNet-v1 跟 Inception-ResNet-v2 的收敛速度比 InceptionV3, InceptionV4 要快。

2.InceptionV4 与 Inception-ResNet-v2的准确率比起InceptionV3 与 Inception-ResNet-v1 有了明显提升。此外,将 Inception 与 ResNet 结合能夠加快收敛速度,使用的更深、层数更多的模型架构計算量跟纯粹只有 Inception 的模型差不多。
3.1.11SENet
SENet的全称是Squeeze-and-Excitation Networks,中文可以翻译为压缩和激励网络。 Squeeze-and-Excitation(SE) block 并不是一个完整的网络结构,而是一个子结构,可以嵌到其他分类或检测模型中,论文采用 SENet block 和 ResNeXt结合的方式,在 ILSVRC 2017 的分类项目中拿到第一,在ImageNet数据集上将 top-5 error 降低到 2.251%,原先的最好成绩是 2.991%,论文链接。
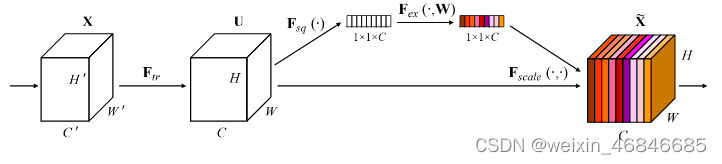
对于CNN网络来说,其核心计算是卷积算子,其通过卷积核从输入特征图学到新特征图。从本质上讲,卷积是对一个局部区域进行特征融合,这包括空间上(W和H维度)以及通道间(C 维度)的特征融合,而对于卷积操作,很大一部分工作是提高感受野,即空间上融合更多特征,或者是提取多尺度空间信息,而SENet网络的创新点在于关注 channel 之间的关系,希望模型可以自动学到不同 channel 特征的重要程度。为此,SENet 提出了 Squeeze-and-Excitation(SE)模块。
中心思想:对于每个输出 channel,预测一个常数权重,对每个 channel 加权一下,本质上,SE模块是在 channel 维度上做 attention 或者 gating 操作,这种注意力机制让模型可以更加关注信息量最大的 channel 特征,而抑制那些不重要的 channel 特征。SENet 一个很大的优点就是可以很方便地集成到现有网络中,提升网络性能,并且代价很小。
如下就是 SENet的基本结构:
小结:
1.SENet构造非常简单,而且很容易被部署,不需要引入新的函数或者层。除此之外,它还在模型和计算复杂度上具有良好的特性。在现有网络架构中嵌入 SE 模块而导致额外的参数和计算量的增长微乎其微。
2.提升很大,并且代价很小,通过对通道进行加权,强调有效信息,抑制无效信息,注意力机制,并且是一个通用的方法,应该在 Inception,Inception-ResNet, ResNeXt, ResNet 都能有所提升,适用范围很广。
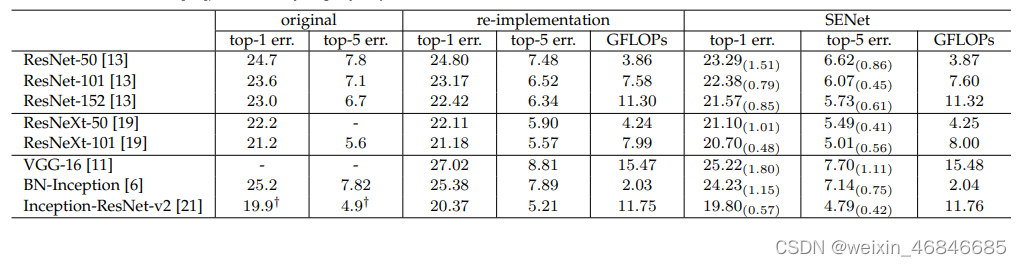
下表分别展示了 ResNet-50,ResNet-101,ResNet-152和嵌入SE模型的结果。从下表可以看出,SE-ResNets 在各种深度上都远远超过其对应的没有 SE 的结构版本的精度,这说明无论网络的深度如何,SE模块都能够给网络带来性能上的增益。值得一提的是,SE-ResNet-50 可以达到和 ResNet-101 一样的精度;更甚,SE-ResNet-101 远远地超过了更深的 ResNet-152。
未完待续
本计划继续介绍目标识别、语义分割等检测任务使用的一些网络模型,但写至3.1节时文章内容已经很长,因此先发布出本章,后续内容会继续更新。
参考文档
机器学习模型评价(Evaluating Machine Learning Models)-主要概念与陷阱
ILSVRC 歷屆的深度學習模型
Dataset之COCO数据集:COCO数据集的简介、下载、使用方法之详细攻略
[Note] COCO dataset #1
目标检测数据集PASCAL VOC简介
COCO 和 CityScapes 数据集的标注格式和使用
图像分类中的深度学习网络汇总
机器之心——LeNet
深度学习饱受争议的局部响应归一化(LRN)详解
卷積神經網絡 CNN 經典模型 — LeNet、AlexNet、VGG、NiN with Pytorch code
揭开CNN的神秘面纱——ZFNet
经典卷积神经网络 之 ZFNet
深度学习经典卷积神经网络之GoogLeNet(Google Inception Net)
GoogleNet: Inception的演進
Inception-v2 / BN-Inception (Batch Normalization) — The 2nd to Surpass Human-Level Performance in ILSVRC 2015 (Image Classification)
Inception 系列 — InceptionV2, InceptionV3
卷積神經網絡 CNN 經典模型 — GoogleLeNet、ResNet、DenseNet with Pytorch code
【每日一网】Day22:Crafting GBD-Net for Object Detection简单理解
Inception 系列 — InceptionV4, Inception-ResNet-v1, Inception-ResNet-v2
SeNet论文详解
卷积神经网络学*笔记——SENet
21秒看尽ImageNet屠榜模型,60+模型架构同台献艺
目标检测顶会论文速览(CVPR、ECCV、NIPS、ICCV )