单选题
浮点数的表示范围和精度取决于
浮点数的取值范围由阶码的位数决定,而浮点数的精度由尾数的位数决定
响应中断请求的条件是
A.外设提出中断;
B.外设工作完成和系统允许时;
C.外设工作完成和中断标记触发器为“1”时;
D.CPU提出中断。
计算器浮点运算速度为85.0167PFLOPS,这说明该计算器每秒完成的浮点操作次数约为()次?
K-M-G-T-P-E-Z,都是乘以103的递增关系,P=1015。85.0167PFLOPS=每秒8.5*10^16次浮点操作
find
Python中find()函数的语法格式如下:
string_object.find(sub, start, end)
sub:必选参数。指定要检索的字符串,可以直接使用字符串具体的值或字符串变量;
start:可选参数。检查搜索开始的索引,默认为0;
end:可选参数。检查搜索停止的索引,默认为字符串string_object的长度。
注意,find()函数在执行检查搜索时,start处的字符将会被检查,而end是停止检索的索引,所以end索引处的字符不会参与检查搜索。
如果字符串string_object中包含sub,则返回sub在string_object中起始的位置索引,否则返回-1.
str1 = “exam is example”
str2 = “exam”
print(str1.find(str2)) #结果为:8
print(str1.find(str2, 7)) #结果为:8
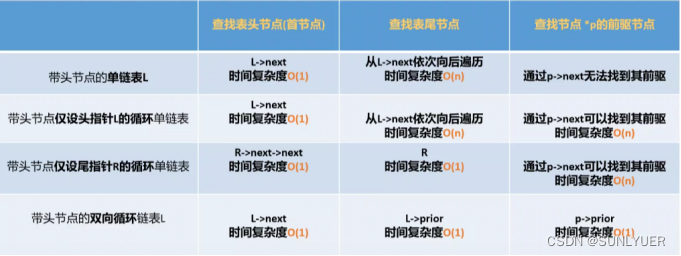
链表
在一个具有n个结点的有序单链表中插入一个新结点并仍然有序的时间复杂度是( )。
A. O(1)
B. O(n)
C. O(n2)
D. O(nlog2n)
optimizer
下列关于optimizer的说法中,错误的是
当目标函数为凸函数时,使用梯度下降法可以得到全局最优解
AdaGrad会随着时间的推移使得学习率越来越小
Adam本质上是带有动量项的RMSprop
RMSprop不需要设置全局的学习率
下列算法中通常以自底向上的方式求解最优解的是( )
备忘录法
动态规划法
贪心法
回溯法
梯度爆炸
梯度爆炸与梯度消失类似,当每层的偏导数值都大于1时,经过多层的权重更新之后,梯度就会以指数形式增加,即为梯度爆炸。
产生原因:
网络层数较深
权重初始值太大
训练样本有误
解决方法
逐层训练加微调
该方法由 Geoffrey Hinton 于2006年提出,具体流程为每次只训练一层神经网络,待权重稳定之后,再使用该层网络的输出进行后一层网络的输入,重复该步骤至训练所有网络层。最后再对整个模型进行finetune,得到最优的模型。
梯度剪切
梯度剪切这个方案主要是针对梯度爆炸提出的,其思想是设置一个梯度剪切阈值,然后更新梯度的时候,如果梯度超过这个阈值,那么就将其强制限制在这个范围之内。这可以防止梯度爆炸。
权重正则化
比较常见的是L1正则,和L2正则,在各个深度框架中都有相应的API可以使用正则化。
relu、leakrelu、elu等激活函数
Relu: 如果激活函数的导数为1,那么就不存在梯度消失爆炸的问题了,每层的网络都可以得到相同的更新速度,relu就这样应运而生。
batchnorm
batchnorm全名是batch normalization,简称BN,即批规范化,通过规范化操作将输出信号x规范化到均值为0,方差为1,保证网络的稳定性。
残差结构
残差结构中的 shortcut 有效地避免了梯度消失与爆炸问题。
LSTM
LSTM全称是长短期记忆网络(long-short term memory networks),是不那么容易发生梯度消失的,主要原因在于LSTM内部复杂的“门”(gates),如下图,LSTM通过它内部的“门”可以接下来更新的时候“记住”前几次训练的”残留记忆“,因此,经常用于生成文本中。
请问以下能为神经网络引入了非线性能力的是?
随机梯度下降
ReLU
卷积
以上都不是
已知二叉树的先序遍历序列为“ABDECFG”
后序遍历是DEBGFCA
文本相似度问题
余弦相似,w2v,发生率
下列选项中,描述浮点数操作速度指标的是
A. MIPS
B. CPI
C. IPC
D. MFLOPS
transformer
Q来自于上一个decoder的输出,而K,V则来自于encoder的输出
假定有一个栈, 输入的顺序为”QUDIAN”,那么输出的顺序不可能是?
QUDIAN
NAIDUQ
DIANUQ
DIANQU
训练集和验证集比例
对于大规模样本集(百万级以上),只要验证集和测试集的数量足够即可,例如有 100w 条数据,那么留 1w 验证集,1w 测试集即可。1000w 的数据,同样留 1w 验证集和 1w 测试集。
一个问题可用动态规划算法或贪心算法求解的关键特征是问题的( )
A. 重叠子问题
B. 最优子结构性质
C. 贪心选择性质
D. 定义最优解
假设我们有一个5层的神经网络,这个神经网络在使用一个4GB显存显卡时需要花费3个小时来完成训练。而在测试过程中,单个数据需要花费2秒的时间。 如果我们现在把架构变换一下,当评分是0.2和0.3时,分别在第2层和第4层添加Dropout,那么新架构的测试所用时间会变为多少?
少于2s
大于2s
仍是2s
说不准
在架构中添加Dropout这一改动仅会影响训练过程,而并不影响测试过程。
混沌度(Perplexity)是一种常见的应用在使用深度学习处理NLP问题过程中的评估技术,关于混沌度,哪种说法是正确的?
混沌度没什么影响
混沌度越低越好
混沌度越高越好
混沌度对于结果的影响不一定
使Cache命中率最高的替换算法是什么?
A、先进先出 B、随机算法 C、先进后出算法 D、替换最近最少使用的块算法求解答:可以说明原因吗?
近期最少使用法(LRU法) 近期最少使用(Least Recently Used,LRU)算法。这种方法是将近期最少使用的Cache中的信息块替换出去。该算法较先进先出算法要好一些。但此法也不能保证过去不常用将来也不常用。 LRU法是依据各块使用的情况, 总是选择那个最近最少使用的块被替换。这种方法虽然比较好地反映了程序局部性规律,但是这种替换方法需要随时记录Cache中各块的使用情况,以便确定哪个块是近期最少使用的块。LRU算法相对合理,但实现起来比较复杂,系统开销较大。通常需要对每一块设置一个称为计数器的硬件或软件模块,用以记录其被使用的情况。 实现LRU策略的方法有多种。 下面简单介绍计数器法、寄存器栈法及硬件逻辑比较对法的设计思路。 计数器方法:缓存的每一块都设置一个计数器,计数器的操作规则是: (1) 被调入或者被替换的块, 其计数器清“0”,而其它的计数器则加“1”。 (2) 当访问命中时,所有块的计数值与命中块的计数值要进行比较,如果计数值小于命中块的计数值,则该块的计数值加“1”;如果块的计数值大于命中块的计数值,则数值不变。最后将命中块的计数器清为0。 (3) 需要替换时,则选择计数值最大的块被替换。
在其他条件不变的前提下,以下哪种做法容易引起机器学习中的过拟合问题()
A. 增加训练集量
B. 减少神经网络隐藏层节点数
C. 删除稀疏的特征 S
D. SVM算法中使用高斯核/RBF核代替线性核
答案为:D
朴素贝叶斯有个前提的假设:每个条件(属性)互相之间是独立的。
sigmode 导数为
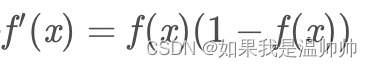
下列不是SVM核函数的是()
多项式核函数
Logistic核函数
径向基核函数
Sigmoid核函数
训练神经网络,最初的几个 epochs 没有下降,原因是

机器学习训练时,Mini-Batch 的大小优选为2个的幂,如 256 或 512。它背后的原因是什么?
Mini-Batch 为偶数的时候,梯度下降算法训练的更快
Mini-Batch 设为 2 的 幂,是为了符合 CPU、GPU 的内存要求,利于并行化处理
不使用偶数时,损失函数是不稳定的
其他说法都不对
python的数据类型
基本的数据类型:数字型、字符串、元祖、列表、字典、集合
不可变数据类型:数字型、字符串、元祖
可变数据类型:列表、字典、集合
整数int 字符串str 浮点数float 布尔型bool 列表list 字典dict 集合set 元组tuple
斐波那契数列用动态规划
解决过拟合方法
防止神经网络过度拟合的最常见方法:
获取更多训练数据
减少网络层数( capacity of the network)
添加权重正则化( weight regularization/weight decay)
添加dropout
数据增强(data-augmentation)
批量标准化(batch normalization)
提前终止(early stoping)
下面哪个模型不是判别模型?
逻辑回归
条件随机场
支持向量机
深度信念网络
常见的生成模型有:隐马尔科夫模型,混合高斯模型,朴素贝叶斯模型和深度信念网络
正负样本不平衡问题如何解决
1、过采样、欠采样的方式对不平衡的正负样本进行采样。
2、正负样本各自在进行训练时,设置不用的惩罚系数。
3、集成的方式:例如,在数据集中的正、负样本分别为100和10000,比例为1:100。此时可以将负样本(类别中的大量样本集)随机分为100份(当然也可以更多),每份100条数据;然后每次形成训练集时使用所有的正样本(100条)和随机抽取的负样本(100)条形成新的数据集。如此反复可以得到100个训练集和对应的训练模型。
4、若极其不平衡,可以考虑把任务转换成异常检测问题。
5、在评价指标上,选用ROC,AUC等可以无视样本不平衡问题的指标。
多选题
过拟合和欠拟合
过拟合的根本原因:特征维度过多,模型假设过于复杂,参数过多,训练数据过少,噪声过多,导致拟合的函数完美的预测训练集,但对新数据的测试集预测结果差。 过度的拟合了训练数据,而没有考虑到泛化能力。因此需要减少特征维度,或者正则化降低参数值。
欠拟合的根本原因:特征维度过少,模型过于简单,导致拟合的函数无法满足训练集,误差较大; 因此需要增加特征维度,增加训练数据。
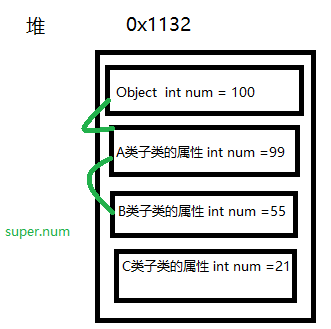
堆和栈的区别
1.申请方式:
栈由系统自动分配和管理,堆由程序员手动分配和管理。
2.效率:
栈由系统分配,速度快,不会有内存碎片。
堆由程序员分配,速度较慢,可能由于操作不当产生内存碎片。
3.扩展方向
栈从高地址向低地址进行扩展,堆由低地址向高地址进行扩展。
4.程序局部变量是使用的栈空间,new/malloc动态申请的内存是堆空间,函数调用时会进行形参和返回值的压栈出栈,也是用的栈空间。
栈的效率高的原因:栈是操作系统提供的数据结构,计算机底层对栈提供了一系列支持:分配专门的寄存器存储栈的地址,压栈和入栈有专门的指令执行;而堆是由C/C++函数库提供的,机制复杂,需要一些列分配内存、合并内存和释放内存的算法,因此效率较低。