目录
1.开篇
2.nodejs文件操作
3.stream
4.stream演示
5.写日志
6.拆分日志
7.分析日志介绍
8.readline
1.开篇
日志:
- 系统没有日志,就等于人没有眼睛——抓瞎
- 第一,访问日志 access log ( server端最重要的日志)
- 第二,自定义日志(包括自定义事件、错误记录等)
开发的话自然是打印在控制台,而上线了当然是要把日志保存到文件中。 如果不用 stream 的话,直接操作文件会很大的消耗 cpu 和内存。
目录
- nodejs文件操作,nodejs stream
- 日志功能开发和使用
- 日志文件拆分,日志内容分析
日志文件很大自然不可能放到 redis(占超级多内存而且也是异步的,没必要马上记日志)mysql 的话需要表结构(B树)才比较合适(而且文件每个地方都可以访问,不必要安 装 mysql 文件)。
nodejs文件操作
- 日志要存储到文件中
- 为何不存储到mysql中?
- 为何不存储到redis中?
2.nodejs文件操作
先看怎么写入文件,定义写入的文件,定义 option(flag 为 a 代表 append 追加写入,而 w 是直接覆盖)。然后就可以调用 writeFile(包含四个参数:要被写入的文件、写入的内容、 选项、回调函数)。同理,写入也是有耗费性能的情况(每次写入一行都 writeFile,一直 writeFile,就不停的打开文件,而且也很难写入非常大的数据)。再看看另一个,判断文件是否存在,调用 exists 方法,接收文件名和回调,会返回一个布尔值,注意也是异步。
const fs = require('fs' )
const path = require( 'path')const fileName = path.resolve(_dirname, 'data.txt') //拿到要操作的文件//读取文件
fs.readFile(fileName,(err ,data) => {if (err) {console. log(err)return
}console. log(data.tostring()) //注意拿到的是二进制文件,需要转换成字符串!
})//写入文件
const content ='三星阿卡丽\n' //随便写入点东西
const opt =flag:'a'
} //定义写入的形式,a代表追加写入
fs .writeFile(fileName, content, opt, (err) => {if (err) {console.log(err) return
}
})
3.stream
IO操作的性能瓶颈:
- IO包括"网络IO”和"文件IO"
- 相比于CPU计算和内存读写, IO的突出特点就是:慢!
- 如何在有限的硬件资源下提高I0的操作效率?

4.stream演示
var fs = require('fs')
var path = require( 'path')//两个文件名
var fileName1 = path.resolve(_dirname,
data. txt')var fileName2 = path.resolve(_dirname, 'data-
bak. txt')//读取文件的stream 对象
var readStrekm = fs. createReadStream( fi leName1)
//写入文件的stream 对象
var writeStream = fs.createWr iteSt ream(f i LeName2 )
//执行拷贝,通过pipe
readSt ream. pipe (writeSt ream )
//数据读取完成,即拷贝完成
readStream. on( 'end', function () {
console. log('拷贝完成')
})
//直接返Erequest数据
const http = require( http' )
const server = http .createserver((req, res) => {if (req.method === 'POST') {req.pipe(res) //从我们发送的request波到传回来的response,显示在返回结果那里
}
})
server.listen(8008)
//复制文件
const fs = require('fs' )
const path = require('path')const fileName1 = path.resolve(_ dirname, 'data.txt' )
const fileName2 = path. resolve(_ dirname, 'data-bak.txt')const readstream = fs .createReadstream(fileName1)
const writestream = fs.createwritestream(fileName2) //拿到对应的文件且创建读写对象readstream.pipe(writestream) //将读到的文件流入写入的文件(也就是拷贝了)readstream.on('data', chunk => { console. log(chunk.tostring())
})
readstream.on('end', () => { //监听拷贝完成
console.log('copy done ' )
})
// http请求 文件
const fs = require('fs' )
const path = require('path')
const http = require('http')
const fileName1 = path.resolve(_dirname,'data.txt')
const readstream = fs .createReadstream(fileName1 )const server = http.createserver((req, res) => {if (req.method === 'GET') {readstream.pipe(res) //直接将读取到的文件一点点传到返回值那里
}
})
server.listen(8000 )
5.写日志
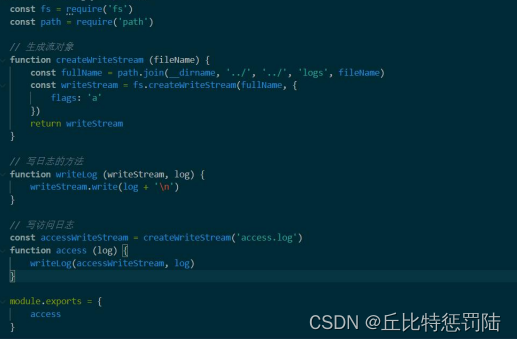
6.拆分日志
- 日志内容会慢慢积累,放在一个文件中不好处理
- 按时间划分日志文件,如2019-02-10.access.log
- 实现方式: linux的crontab命令,即定时任务
这个由于服务器基本都是 Linux 和类 Linux 的,定时任务的话 windows 可能没办法实现,所以这一块可以了解下即可,主 要是运维的搞。 解释一下*代表什么意思,第一个*代表分钟(如果不写具体 的值保持*就代表忽略,比如 1 * * * *就代表每天的第一分钟执行这个命令)第二个*代表小时(12***代表每天的第二个小时的第 1 分钟执行)第三个是日期第四个是月份第五个是 星期。command 就是一个 shell 脚本。
crontab:
- 设置定时任务,格式: **** * command
- 将access.log拷贝并重命名为2019-02-10.access.log
- 清空access.log文件,继续积累日志
7.分析日志介绍
日志分析:
- 如针对access.log日志,分析chrome的占比
- 日志是按行存储的, - -行就是一条日志
- 使用nodejs的readline ( 基于stream , 效率高)
通过 readline 可以一行行的去查看日志,我们先去不同浏览器运行下不同的地址,创造出不一样的 logs。
8.readline
const fs = require( ' fs' )
const path = require( 'path' )
const readline = require('readline')//创建流对象(读取)
const fileName = path. join(__ dirname, '../', ' ../', 'logs' , access.log' )
const readstream = fs.createReadstream( fileName)//创建readLine对象
const rl = readline.Interface({input: readstream
})//定义存放浏览器类型的变量
let chromeNum = 0
letsum=e