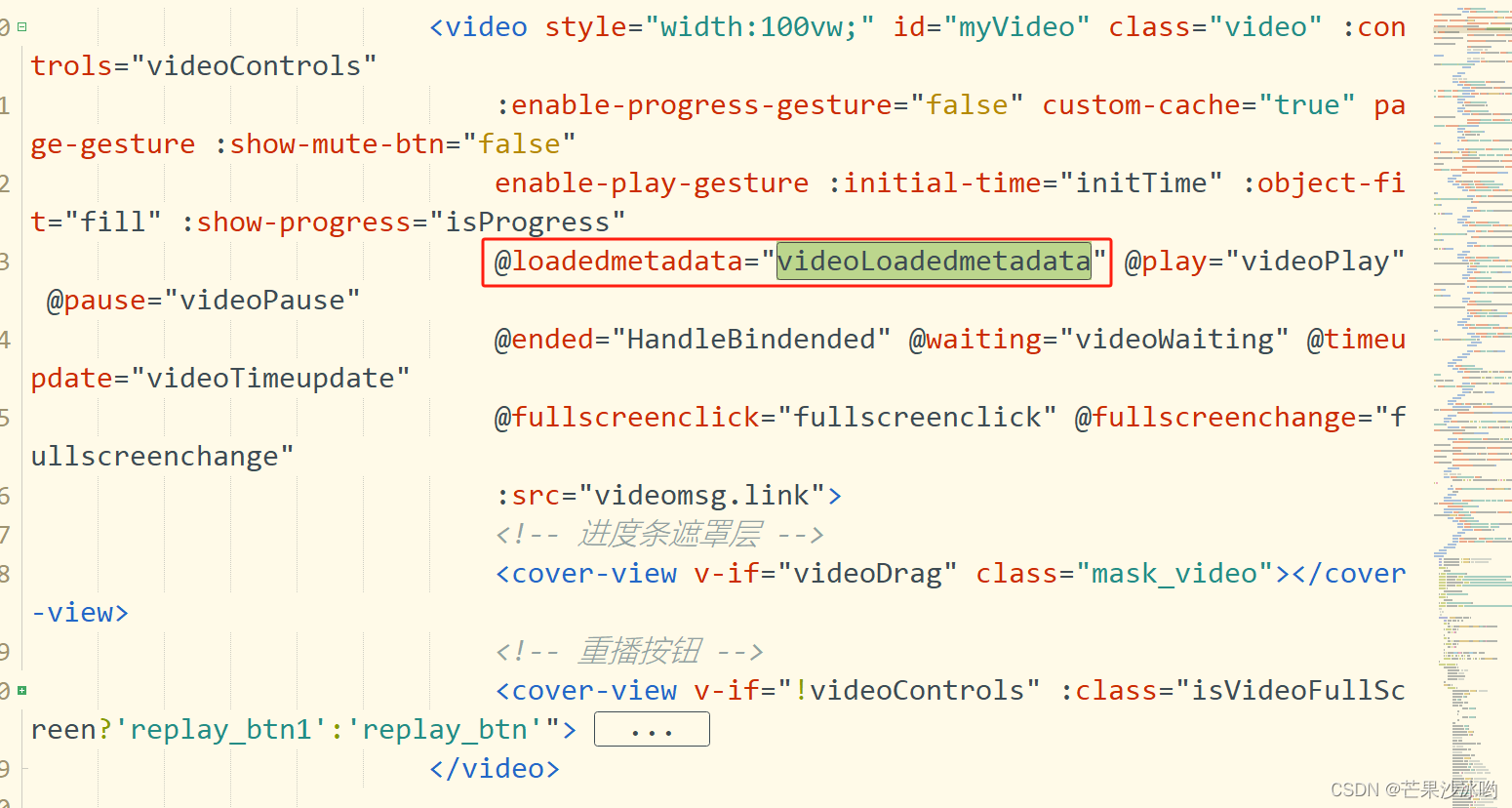
[机器学习]Day 1~3 数据预处理 第1步:导入库 第2步:导入数据集 第3步:处理丢失数据 第4步:解析分类数据 第5步:拆分数据集为训练集合和测试集合 第6步:特征量化 简单线性回归模型 第一步:数据预处理 第二步:训练集使用简单线性回归模型来训练 第三步:预测结果 第四步:可视化 多元线性回归 第1步: 数据预处理 导入库 导入数据集 将类别数据数字化 躲避虚拟变量陷阱 拆分数据集为训练集和测试集 第2步: 在训练集上训练多元线性回归模型 Step 3: 在测试集上预测结果
import numpy as np
import pandas as pd
// 随后一列是label
dataset = pd. read_csv( 'Data.csv' ) // 读取csv文件
X = dataset. iloc[ : , : - 1 ] . values// . iloc[ 行,列]
Y = dataset. iloc[ : , 3 ] . values // : 全部行 or 列;[ a] 第a行 or 列// [ a, b, c] 第 a, b, c 行 or 列
from sklearn. preprocessing import Imputer
imputer = Imputer( missing_values = "NaN" , strategy = "mean" , axis = 0 )
imputer = imputer. fit( X[ : , 1 : 3 ] )
X[ : , 1 : 3 ] = imputer. transform( X[ : , 1 : 3 ] )
from sklearn. preprocessing import LabelEncoder, OneHotEncoder
labelencoder_X = LabelEncoder( )
X[ : , 0 ] = labelencoder_X. fit_transform( X[ : , 0 ] )
onehotencoder = OneHotEncoder( categorical_features = [ 0 ] )
X = onehotencoder. fit_transform( X) . toarray( )
labelencoder_Y = LabelEncoder( )
Y = labelencoder_Y. fit_transform( Y)
from sklearn. cross_validation import train_test_split
X_train, X_test, Y_train, Y_test = train_test_split( X , Y , test_size = 0.2 , random_state = 0 )
from sklearn. preprocessing import StandardScaler
sc_X = StandardScaler( )
X_train = sc_X. fit_transform( X_train)
X_test = sc_X. transform( X_test)
import pandas as pd
import numpy as np
import matplotlib. pyplot as pltdataset = pd. read_csv( 'studentscores.csv' )
X = dataset. iloc[ : , : 1 ] . values
Y = dataset. iloc[ : , 1 ] . valuesfrom sklearn. model_selection import train_test_split
X_train, X_test, Y_train, Y_test = train_test_split( X, Y, test_size = 1 / 4 , random_state = 0 )
from sklearn. linear_model import LinearRegression
regressor = LinearRegression( )
regressor = regressor. fit( X_train, Y_train)
Y_pred = regressor. predict( X_test)
plt. scatter( X_train , Y_train, color = 'red' )
plt. plot( X_train , regressor. predict( X_train) , color = 'blue' )
plt. show( )
plt. scatter( X_test , Y_test, color = 'red' )
plt. plot( X_test , regressor. predict( X_test) , color = 'blue' )
plt. show( )
import pandas as pd
import numpy as np
dataset = pd. read_csv( '50_Startups.csv' )
X = dataset. iloc[ : , : - 1 ] . values
Y = dataset. iloc[ : , 4 ] . values
from sklearn. preprocessing import LabelEncoder, OneHotEncoder
labelencoder = LabelEncoder( )
X[ : , 3 ] = labelencoder. fit_transform( X[ : , 3 ] )
onehotencoder = OneHotEncoder( categorical_features = [ 3 ] )
X = onehotencoder. fit_transform( X) . toarray( )
X = X[ : , 1 : ]
from sklearn. model_selection import train_test_split
X_train, X_test, Y_train, Y_test = train_test_split( X, Y, test_size = 0.2 , random_state = 0 )
from sklearn. linear_model import LinearRegression
regressor = LinearRegression( )
regressor. fit( X_train, Y_train)
y_pred = regressor. predict( X_test)