摘要
我们研究了连续时间和空间环境下的强化学习( RL ),其目标是一个具有折扣的无限时域,其动力学由一个随机微分方程驱动。基于连续RL方法的最新进展,我们提出了占用时间(专门针对一个折现目标)的概念,并展示了如何有效地利用它来推导性能差异和局部近似公式。我们进一步扩展这些结果,以说明它们在PG (策略梯度)和TRPO / PPO (信赖域政策优化/近端政策优化)方法中的应用,这些方法在离散RL环境中是熟悉和强大的工具,但在连续RL中不发达。通过数值实验,我们证明了我们方法的有效性和优势。
受两个问题的启发
- 定义MDP (带有折扣的目标)中的访问频率为:
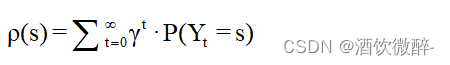 ,其中{ Yt }为状态空间为S:= { s }的马尔可夫链,γ∈( 0、1 )为折扣因子。它在许多MDP的RL算法中起着重要的作用。因此,一个自然的问题是,什么是ρ ( s )的连续对应物?
,其中{ Yt }为状态空间为S:= { s }的马尔可夫链,γ∈( 0、1 )为折扣因子。它在许多MDP的RL算法中起着重要的作用。因此,一个自然的问题是,什么是ρ ( s )的连续对应物? - 对于连续RL,如何表征两种策略之间的性能差异?具体来说,我们能否推导出类似于MDP情形中的性能差异公式?能否将高效的策略优化方法的思想和工具应用到连续的RL设置中?
主要贡献
1. 提供了一个统一的理论框架,用于连续时间和空间中的策略优化问题。
2. 引入了驻留时间/度量概念,解决了折扣目标下的策略优化问题。
3. 通过摄动分析推导了连续强化学习的性能差异公式。
4. 开发了策略梯度的连续对应项,以及性能度量的局部近似方法。
5. 提出了次优化-主优化算法,并推导了其性能上界。
6. 发展了信任区域策略优化/近端策略优化的连续对应项。
7. 展示了这些算法在连续时间和空间中的随机控制任务上的收敛性。
算法和实验
Sample-based Algorithms
超参数:
- 学习率α
- 轨迹截断参数(时间范围)T(需要足够大)
- 总样本量 N或采样间隔δt,其中 N·δt = T
- 从环境中观察到数据的时刻,记 ti:= i·δt,i = 0, . . . , N − 1
Continuous Policy Gradient (CPG)
为了从数据中估计策略梯度,首先采样一个独立的指数变量τexp(β) 以获得 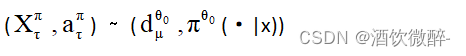 。如果存在 q 函数 oracle,则可以获得策略梯度的无偏估计(其收敛分析遵循)。由于缺少这样的预言,我们采用广义优势估计 (GAE) 技术 来获得 q(Xt, at)≈(Q∆t(Xt, at;π)−V (Xt;π)) /δt≈(rtδt + e−βδtV (Xt+δt)−V (Xt))/δt。这产生了策略梯度算法 1。
。如果存在 q 函数 oracle,则可以获得策略梯度的无偏估计(其收敛分析遵循)。由于缺少这样的预言,我们采用广义优势估计 (GAE) 技术 来获得 q(Xt, at)≈(Q∆t(Xt, at;π)−V (Xt;π)) /δt≈(rtδt + e−βδtV (Xt+δt)−V (Xt))/δt。这产生了策略梯度算法 1。

我们现在给出算法2,它是PPO的连续版本,也是3.3节中MM算法的近似。为此,我们需要更多的超参数:容忍度水平ε和KL散度半径δ。此外,令![]()
(经验地,我们发现对x取平均而不是取上确界,在减少计算负担的同时并不影响算法的性能,这与文献中在离散时间TRPO中观察到的情况类似。)

实验
考虑一个由具体线性动力学和二次奖励的SDE驱动环境。线性二次(LQ)控制问题不仅因为具有优雅简单的解决方案,还因为它可以近似更复杂、非线性的问题。
将 CPO 和 CPPO 的性能与直接离散化时间,然后应用经典离散时间 PG 和 PPO 算法的方法进行了比较。实验表明,我们提出的 CPO 和 CPPO 在样本效率方面具有可比性,并且在许多情况下,它们在各种时间离散化下优于离散时间算法。