题目:VastGaussian: Vast 3D Gaussians for Large Scene Reconstruction
来源:清华大学;华为诺亚;中国科学院
链接:https://vastgaussian.github.io/
总结:VastGaussian:基于3D GS的分块优化重建:引入了渐进式数据划分策略,允许独立的单元优化和无缝合并,获得具有足够三维高斯分布的完整场景。解耦外观建模消除了训练图像中的外观变化,实现了不同视图之间的一致渲染
文章目录
- 摘要
- 一、前言
- 二、相关工作
- 2.1 大场景重建
- 2.2 变化的外观建模
- 2.3 准备工作
- 三、Method
- 3.1 渐进式数据划分
- 3.2 解耦外观建模
- 3.3 无缝合并
- 四、实验
- 4.1 实验设置
- 4.2 结果分析
- 4.3 消融实验
- 总结
摘要
基于NeRF的重建方法,在大型场景中的渲染质量和速度较差。虽然最近的3D Gaussian Splatting在小规模和以对象为中心的场景上效果很好,但由于有限的视频内存、优化时间长和明显的外观变化,难以扩展到大场景。本文提出 VastGaussian,基于三维GS的大场景高质量重建和实时渲染的高斯方法:提出了一种渐进划分策略,将场景划分为多个单元,其中训练摄像机和点云以空域感知可见性准则适当分布。在并行优化后,单元格被合并成一个完整的场景。还在优化过程中引入了解耦的外观建模,以减少渲染图像中的外观变化。实验在多个大场景数据上验证。
一、前言
大型场景重建对于许多应用都是必不可少的,包括自动驾驶、空中测量和虚拟现实,需要视觉质量和实时渲染。 Mega-nerf、Block-nerf、Switch-nerf、Bungeenerf 将神经辐射场(NeRF)扩展到大规模的场景中,但它们仍然缺乏细节或渲染缓慢。最近,3DGS 在1080p分辨率下逼真和实时渲染,并应用于动态场景重建[28,51,55,56]和三维内容生成[12,42,59],但是侧重于小规模和以对象为中心的场景。当应用于大规模环境时,存在几个scalability的问题。首先,三维高斯数的数量受到一个给定的视频内存的限制,而一个大场景的丰富细节需要大量的三维高斯数。简单地将3DGS应用于一个大规模的场景,将会导致低质量的重建或内存不足的错误。为了直观的解释, 一个32 GB的GPU可以用来优化大约1100万个3D高斯,而在Mip-NeRF 360数据集中,面积小于100平方米的小花园场景已经需要大约580万3D高斯来进行高保真重建。其次,它需要足够的迭代来优化整个大型场景作为一个整体,这可能会很耗时,而且由于没有良好的正则化而不稳定。第三,大场景中,光照通常不均匀,捕获的图像有明显的外观变化,如图2(a).所示3DGS倾向于产生具有低混浊度的大的三维高斯分布,以弥补不同视图之间的这些差异。例如,明亮的blob往往与高曝光的图像接近相机,而黑暗的blob与低曝光的图像有关。从新的角度观察到,这些blob变成了空中的floater,如图2(b, d)所示
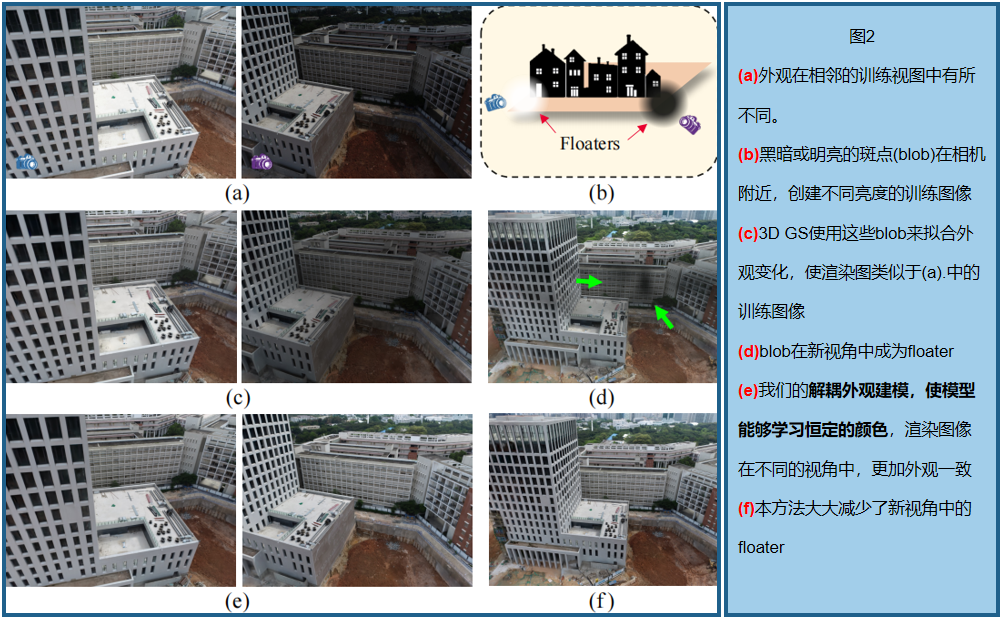
为了解决这些问题,VastGaussian以分而治之的方式重建一个大场景:将一个大场景划分为多个单元,独立优化每个单元,最后将它们合并为一个完整的场景。由于这些单元具有更精细的空间尺度和更小的数据大小,因此更容易优化这些单元。一种自然而简单的划分策略是根据它们的位置在地理上分布训练数据。由于常见的摄像机很少,这可能会导致两个相邻单元之间的边界伪影,并可能在没有足够监督的情况下在空气中产生 floaters。因此提出了基于可见性的数据选择,以逐步合并更多的训练摄像机和点云,以确保无缝合并,并消除floater。每个单元格包含较少的三维高斯分布,这减少了内存需求和优化时间,特别是当与多个gpu并行优化时。合并场景中包含的三维高斯数据总数大大超过了整体训练的场景,提高了重建质量。此外,我们还可以通过合并新的单元格来扩展场景,或者微调一个特定的区域,而无需对整个大场景进行再训练。
为了减少外观变化引起的floater,基于nerf提出了具有外观嵌入[29]的生成潜在优化(GLO)[5]。这种方法通过ray marching 对点采样,并将点特征与外观嵌入一起输入一个MLP,以获得最终的颜色。它不适合3DGS,因为渲染是通过没有mlp的frame-wise 的栅格化来完成的。因此,我们提出了一种新的解耦外观建模(仅用于优化)。我们将一个外观嵌入到渲染图像上,并将其输入CNN,以获得用于对渲染图像应用外观调整的变换图。我们惩罚渲染图像和地面真实之间的结构差异来学习恒定信息,而在调整后的图像上计算光度损失以拟合训练图像中的外观变化。我们需要的是只有一致的渲染,所以在优化后可以丢弃这个外观建模模块,从而不会减慢实时渲染速度
贡献如下:
1.提出了VastGaussian,基于三维GS的大场景高保真重建和实时渲染
2.提出了一种渐进的数据划分策略,将训练视图和点云分配给不同的单元格,从而实现并行优化和无缝合并。
3.在优化过程中引入了解耦外观建模,抑制了外观变化导致的floater。优化后可以丢弃该模块,以获得实时的渲染速度。
二、相关工作
2.1 大场景重建
一些工作 [ Photo tourism等,1,16,23,34,38,39,62] 遵循运动结构(SfM)管道来估计相机pose和稀疏点云。[17,19]从基于多视图立方体(MVS)的SfM输出中产生一个密集的点云或三角形网格。近年来,随着NeRF [31]成为一种流行的逼真新视角合成的三维表示,人们提出了许多变体来提高质量[2-4,24,45,47-49,57],提高速度[8,9,11,14,20,32,36,37,40,43,46,58,60],扩展到动态场景[7,15,18,25,27,50],等等。一些方法是通过[41,44,52,53,61]将其缩放到大型场景中。BlockNeRF [41]将一个城市划分为多个街区,并根据其位置分发训练视图。Mega-NeRF [44]使用基于网格的划分,并将图像中的每个像素分配给其光线通过的不同网格。与这些启发式划分策略不同,Switch-NeRF [61]引入了一个nerf-专家的混合框架来学习场景分解。Grid-NeRF [53]不执行场景分解,而是使用基于NeRF和基于网格的方法的集成。虽然这些方法的渲染质量比传统方法有了显著的提高,但它们仍然缺乏细节,渲染速度缓慢。最近,3D Gaussian splitting[21]引入了一种表达式显式3D表示,具有1080p分辨率的高质量实时渲染。
2.2 变化的外观建模
在光照变化或不同的相机设置下,如自动曝光、自动白平衡和调压等,外观变化是图像重建中常见的问题。NRW [30]以数据驱动的方式训练外观编码器,它以 deferred-shading deep buffer作为输入,并产生外观嵌入(AE)。NeRF-W [29]在ray marching过程中,将AEs附加到点特征上,并将它们输入MLP以获得最终的颜色,这成为许多基于nerf的方法[41,44,61]的标准实践。Ha-NeRF [10]使AE成为一个跨不同视图的全局表示,并通过一个视图一致的丢失来学习它。VastGaussian 将AEs与渲染图像连接起来,将它们输入CNN以获得变换映射,并使用变换映射来调整渲染图像以适应外观变化。
2.3 准备工作
3DGS通过一组三维高斯分布 G 来表示几何形状和外观。每个三维高斯分布都具有其位置、各向异性协方差、不透明度和与视图相关的颜色的球谐系数。在渲染过程中,每个三维高斯都以二维高斯的形式投影到图像空间。投影的二维高斯分布被分配到不同的贴图tiles上,并以基于点的体渲染方式进行排序和α-blend加权到渲染图像中。
用于优化场景的数据集包含一个稀疏点云 P 和训练视图 V= { (Ci, Li) },Ci 是第i个摄像机,Li是对应的图像。由运动结构SfM估计得到。P用于初始化三维高斯,V用于三维高斯的可微渲染和基于梯度优化。对于相机 Ci,渲染图像 Lir = R(G, Ci) 由可微分光栅化器得到。三维高斯分布的属性由 Lir 和 Li 之间的损失函数优化:
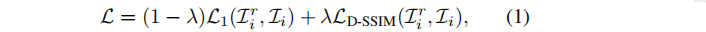 该过程与自适应点稠密化交织,当点的累积梯度达到一定阈值时触发。
该过程与自适应点稠密化交织,当点的累积梯度达到一定阈值时触发。
三、Method
本文将3DGS扩展到大型场景中,以实现实时和高质量的渲染。在4.1节,引入了一种基于空域感知可见性计算的渐进式数据分区策略。4.2节详细说明了如何优化单个cell,以及解耦外观建模,捕获图像中的外观变化。最后4.3节描述了如何合并这些cell。
3.1 渐进式数据划分
将一个大场景划分为多个单元,并将部分点云P和视图V分配给这些单元来优化。每个单元格包含较少的三维高斯分布(较低内存,更少优化时间)。渐进式数据划分策略如图3:
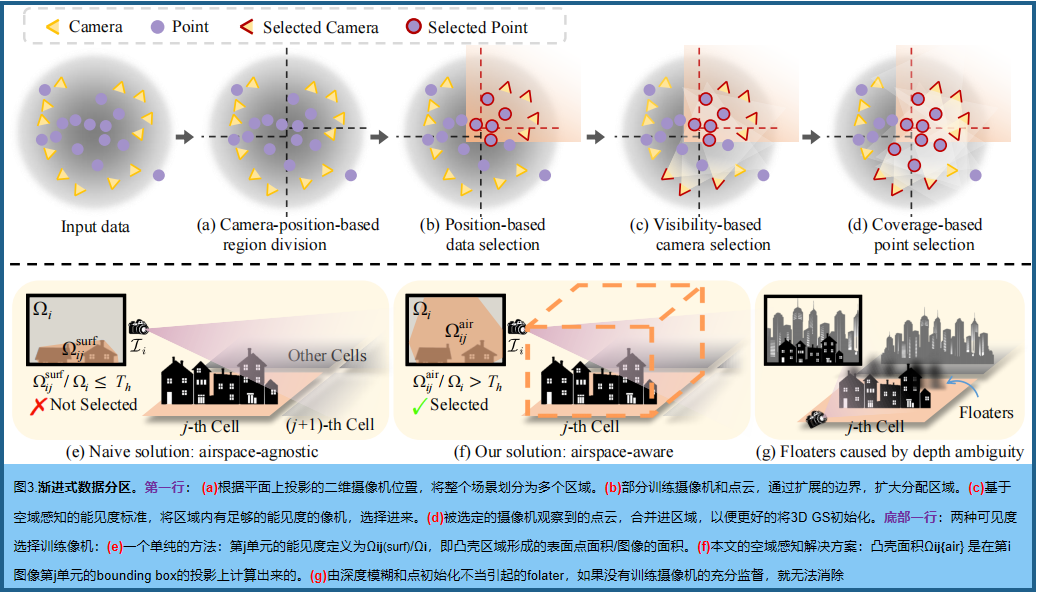
a.基于相机位置的区域划分
如图3(a),根据平面上投影的像机位置,对场景进行分割,使每个单元包含相似数量的训练视图(确保平衡优化)。在通用情况下,假设m×n个单元的网格很好地适应相关场景。首先沿一个轴将基 ground plane划分为m个部分,每个部分包含大约|V|/m视图。然后,每一段沿着另一个轴进一步细分为n个段,每个段包含大约 |V|/(m×n) 视图。数据划分策略也适用于其他geography-based的划分方法,如sectorization和quadtrees。
b.基于位置的数据选择
如图3(b),在扩展每个单元的边界后,将部分训练视图V和点云P分配给每个单元。具体地说,让第j个区域有界为 ℓjh×ℓjw 矩形;原边界扩展一定的百分比(如20%),得到一个更大的矩形(ℓjh+0.2ℓjh)×(ℓjw+0.2ℓjw)。根据扩展边界,将训练视图V划分为 {Vj}j=1m×n ,并以同样的方法将点云P分割为{Pj}。
c.基于可见度的相机选择
在上一步中选择的摄像机不足以进行高保真度重建,导致较差的细节或浮动伪影。VastGaussian根据可见性准则,增加更多的相关摄像机,如图3©.所示给定一个尚未选择的相机Ci,设Ωij 为图像 Li 中第j个单元的投影面积,设Ωi为Li的面积;可见性定义为 Ωij/Ωi。选择能见度值大于预定义阈值Th的相机。
不同的Ωij 计算方法会导致不同的相机选择。如图3(e)所示,一个自然的和朴素的解是基于分布在物体表面上的三维点。它们被投影在Li 上,形成一个区域Ωijsurf 的凸包。这个计算是与空中空间无关的,因为它只考虑了表面。因此,在本次计算中,由于其对第j个单元的能见度较低,因此没有选择一些相关的摄像机,导致对空域的监督不足,无法抑制空中的伪影。 VastGaussian引入了一个空域感知的能见度计算,如图3(f)所示 。具体来说,由第j个单元格中的点云形成一个轴对齐的边界框,其高度被选择为最高点与ground 平面之间的距离。将边界框投影到Li 上,得到了一个凸包面积 Ωijair。这种空域感知解决方案考虑了所有可见空间,从而确保给定适当的能见度阈值,选择对优化有重要贡献的视图,并为空域提供足够的监督。
d.基于覆盖的点选择
在第j单元的摄像机集 Vj 中添加更多相关的摄像机后,将Vj中所有视图所覆盖的点添加到Pj中,如图3(d)。新选择的点可以为该单元格的优化提供更好的初始化。 图3(g)显示,在 Vj 中的一些视图可以捕获第j个单元外的一些对象,由于没有适当初始化的深度模糊,在错误的位置生成新的三维高斯函数来拟合这些对象。然而,通过添加这些对象点进行初始化,可以很容易地在正确的位置创建新的三维高斯数来适应这些训练视图,而不是在第j个单元格中产生floater。 注意,单元外生成的三维高斯分布在单元优化后被移除。
3.2 解耦外观建模
在不均匀光照下拍摄的图像有明显的外观变化,3DGS倾向于产生floater,以补偿不同视图中的这些变化,如图2。为了解决这个问题,一些基于nerf的方法[29,41,44,61]将外观嵌入到像素级行进的基于点的特征上,并将它们输入辐射MLP以获得最终的颜色。这不适用于3DGS,它的渲染是通过没有mlp的帧级栅格化来执行的。 VastGaussian引入解耦的外观建模,它会生成一个变换映射来调整渲染的图像,以适应训练图像中的外观变化,如图4所示。

具体的,首先对渲染的图像Lir 进行降采样 (不仅可以防止变换图学习高频细节,而且还可以减少计算负担和内存消耗)然后,将长度为m的外观嵌入ℓi,拼接到三通道下采样图像中的每个像素上,得到一个3个+m通道的二维图像Di,输入CNN逐步上采样,生成与Lir具有相同分辨率的Mi。最后,利用Mi 对Lir 进行像素级变换T,获得外观变化图像Lia:
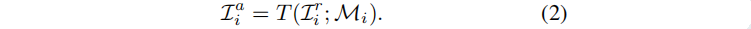
修改等式1,利用三维高斯模型对外观嵌入和CNN函数进行优化:
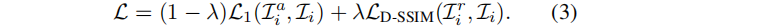
LD-SSIM主要惩罚结构差异,应用于Lir 和真实标签 Li,使结构信息接近;外观信息由嵌入向量 ℓi和CNN学习。训练后,Lir 被期望与其他图像外观一致(三维高斯模型可以学习到所有输入视图的平均外观和正确的几何形状)。这种外观建模可以在优化后被丢弃,不影响渲染速度。
3.3 无缝合并
独立优化所有单元格之后,删除原始区域外的三维高斯分布(否则可能会在其他单元中变成伪影),合并以得到一个完整的场景。合并后的场景,在外观和几何形状上都是无缝的,没有明显的边界伪影(因为VastGaussian的数据分区,一些训练视图在相邻的单元格之间是common的)。因此,不需要像Block-NeRF那样进行进一步的外观调整。合并场景中包含的三维高斯大大超过整体训练的场景中的GS,从而提高了重建质量。
四、实验
4.1 实验设置
实施。 实验用8个单元来评估模型。可见性阈值为25%。渲染的图像在与长度为64的外观嵌入连接之前被降采样32次。每个单元格都被优化了60,000次迭代。稠密化从第1000次迭代开始,到第30000次迭代结束,间隔为200次迭代。其他设置与3DGS [21]的设置相同。外观嵌入和CNN都使用了0.001的学习率。我们执行曼哈顿世界对齐,使世界的y轴坐标垂直于ground
plane.
数据集。 实验在五个大尺度的场景上进行:来自Mill-19数据集[44]的废墟和建筑,以及来自Rubble and Building数据集[26]的校园、住宅和科学艺术。每个场景都包含数千张高分辨率的图像。我们对图像进行了4次降采样以进行训练和验证,按照之前的方法[44,61]进行公平比较。
指标。 三个定量指标 SSIM、PSNR和基于alexnet的LPIPS。光照变化使评估变得困难,因为它不确定应该复制哪种光度条件。为了解决这个问题,我们遵循Mip-NeRF 360 [3],在评估所有方法的指标之前,对渲染图像进行颜色校正,这解决了每幅图像的最小二乘问题,以对齐渲染图像与其对应的地面真实值之间的RGB值。我们还报告了在1080p分辨率下的渲染速度,平均训练时间,和视频内存消耗
对比方法。 比较了四种方法: Mega-NeRF ,Switch-NeRF ,GridNeRF ,和3DGS 。对于3DGS,我们需要增加优化迭代,以使其在我们的主要实验中具有可比性,但天真地这样做会导致内存不足的错误。因此,我们相应地增加了稠密化间隔,以建立一个可行的基线(称为修改的3DGS)。其他配置与原来的3DGS论文相同。对于Grid-NeRF,由于其机密性要求,它的代码发布时没有渲染的图像和仔细调整的配置文件。这些不可用的文件对其性能至关重要,这使得其结果不可复制。因此,我们使用它的代码来评估它的训练时间、内存和渲染速度,而质量指标是从论文中复制的。
4.2 结果分析
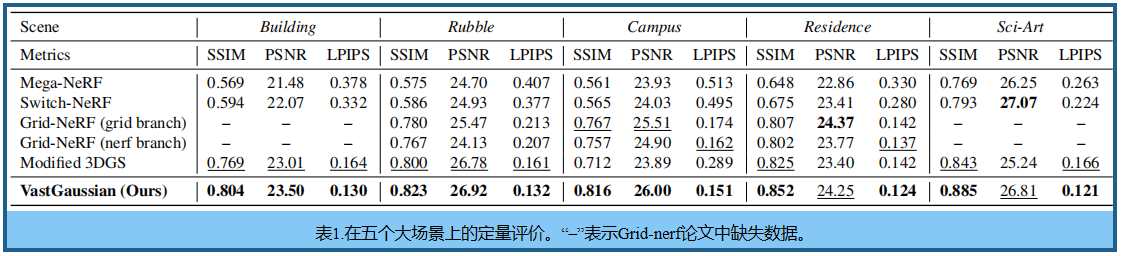
重建质量。 表1 报告了每个场景中的平均SSIM、PSNR和LPIPS指标。 图5 中显示了视觉比较。 基于NeRF的方法缺乏细节,并产生模糊的结果。修改后的3DGS具有更清晰的渲染效果,但会产生不愉快的floater。VastGaussian实现了干净和视觉上令人愉快的渲染。需要注意的是,由于在一些测试图像中明显的过度曝光或欠曝光,VastGaussian表现出略低的PSNR值,但产生明显更好的视觉质量,有时甚至比地面真相更清晰,如图5中第3行的例子。其高质量部分归功于它大量的三维高斯分布。以校园场景为例,修正3DGS中的3D高斯数为8.9 million,而虚拟高斯数为27.4million。

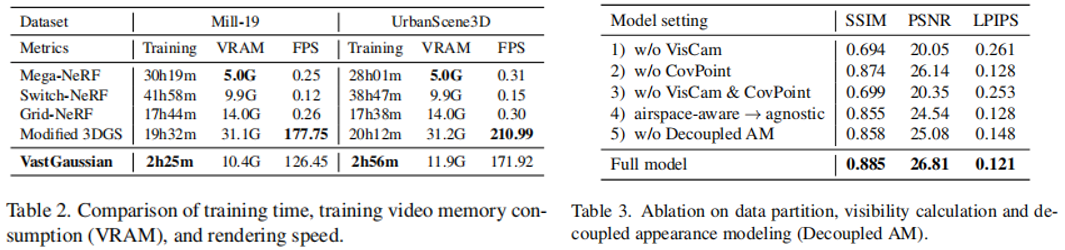
效率和内存。 表2报告了训练时间、优化过程中的视频内存消耗和渲染速度。Mega-NeRF、Switch-neRF和VastGaussian在8个Tesla V100 GPU上进行训练,而GridNeRF和修改的3DGS在单个V100 GPU上进行训练,因为它们不进行场景分解。渲染速度在一个RTX 3090 GPU上进行了测试。我们的快速高斯分布需要更短的时间来重建一个场景与逼真的渲染。与改进的3DGS相比,虚拟高斯算法大大降低了单个GPU上的视频内存消耗。由于Vast高斯数据在合并场景中比修改后的3DGS拥有更多的3D高斯数据,其渲染速度略慢于修改后的3DGS,但仍然比基于nerf的方法快得多,从而实现了1080p分辨率的实时渲染。
4.3 消融实验
在Sci-Art scene数据集上进行消融实验
数据分区。如图6和表3,基于可见性的相机选择(VisCam)和基于覆盖物的点选择(CovPoint)都可以提高视觉质量。如果没有每一种或两者,就可以在细胞的空域产生folater,以适应细胞外观察区域的视图。
空域感知能见度计算。如表3的第4行和图8,基于空域感知能见度计算选择的摄像机为单元的优化提供了更多的监督,因此不会产生以空域不可知的方式计算能见度时呈现的floater
解耦外观建模。如图2和表3第5行,解耦外观建模减少了渲染图像中的外观变化。因此,三维高斯模型可以从具有外观变化的训练图像中学习一致的几何形状和颜色,而不是创建floater来补偿这些变化。也请参见附录中的视频。
单元数量消融。如表4、更多的cell在VastGaussian中重建更好的细节,使cell的SSIM和LPIPS值更好,并使cell并行优化时的训练时间更短。然而,当cell数量达到16或更大时,质量的改善变得边缘,PSNR略有下降,因为在距离遥远的cell的渲染图像中,亮度可能会逐渐变化。

总结
本文中提出了第一个高质量重建和高斯实时渲染方法。引入的渐进式数据划分策略允许独立的单元优化和无缝合并,获得具有足够的三维高斯分布的完整场景。我们的解耦外观建模解耦了训练图像中的外观变化,并支持在不同视图之间的一致呈现。该模块可以在优化后被丢弃,以获得更快的渲染速度。虽然VastGaussian可以应用于任何形状的空间分割,但我们没有提供一个最优的分割解决方案,应该考虑场景布局,单元数和训练摄像机的分布。此外,当场景很大时,会有很多三维高斯分布,这可能需要很大的存储空间,并显著降低渲染速度。
d \sqrt{d} d 1 0.24 \frac {1}{0.24} 0.241 x ˉ \bar{x} xˉ x ^ \hat{x} x^ x ~ \tilde{x} x~ ϵ \epsilon ϵ
ϕ \phi ϕ






![[Electron]中的Notification通知](https://img-blog.csdnimg.cn/direct/ad88aacfcb8241429ad3ad2f8b59b618.png)