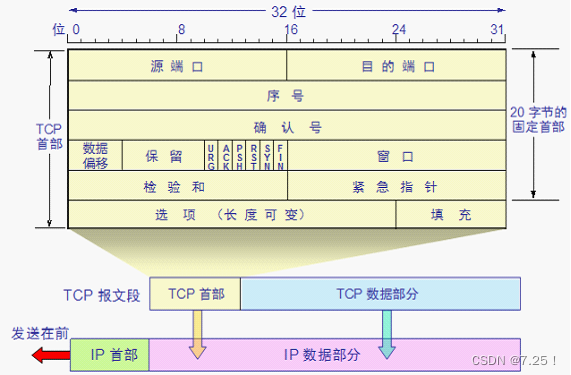
Pytorch系列
文章目录
- Pytorch系列
- 前言
- 一、DDP是什么
- 二、DPP原理
- terms、nodes 和 ranks等相关术语解读
- DDP 的局限性
- 为什么要选择 DDP 而不是 DP
- 代码演示
- 1. 在一个单 GPU 的 Node 上进行训练(baseline)
- 2. 在一个多 GPU 的 Node 上进行训练
- 临门一脚: 在多个 Node 上进行训练
- 4 使用集群 (SLURM)
前言
随着近几年大模型的问世,传统的单机单卡模式已经无法满足超大模型进行训练的要求,如何更好地、更轻松地利用多个 GPU 资源进行模型训练成为了人工智能领域的热门话题。我们今天为大家带来的这篇文章详细介绍了一种名为 DDP(Distributed Data Parallel)的并行训练技术,作者认为这项技术既高效又易于实现。
(1) DDP 的核心思想是将模型和数据复制到多个 GPU 上并行训练,然后汇总平均梯度。
(2) DDP 比传统的 DP 模式更加高效,可以轻松扩展到多节点,同时也介绍了 DDP 的局限性。
(3) DDP 的 Python 实现非常简洁,主要分为进程初始化、设置 Distributed DataLoader(分布式数据加载器)和模型训练与测试三步。
(4) 文中还解析了 DDP 中 Node、Master Node、Local Rank、Global Rank 等关键术语的具体含义。
(5) 提供了从单 GPU 到单节点多 GPU 再到多节点场景的 DDP 应用案例源代码.
DDP 要求将整个模型加载到一个GPU上,这使得大模型的训练需要使用额外复杂的设置进行模型分片。期待未来有更多简单、高效、易用,还能满足大模型场景的模型训练并行技术出现!
一、DDP是什么
本文将介绍一种名为 DDP (Distributed Data Parallel)的技术,使用这种技术可以实现同时在多个 GPU 上训练模型。我上学的时候只能用云服务平台的 GPU 进行训练。然而,当我进入企业上班后,情况就不同了。如果你所在的公司在人工智能领域投入了大量资源,特别是如果你在一家科技巨头公司工作,那么很可能你可以随时使用大量的GPU集群。本教程旨在让读者掌握如何同时利用多个GPU,实现快速高效的训练。而且,也许会让你惊讶的是,这种技术比你想象的还要简单!在你继续阅读本文之前,建议先去充分了解 PyTorch(一种机器学习框架)相关内容,包括其核心组件,如Datasets、 DataLoaders、Optimizers、CUDA 和 Training loop。一开始,我也认为 DDP 是一种复杂的、几乎无法实现的技术,认为它需要一个庞大的技术团队来建立必要的基础设施。不过,我向你们保证,DDP不仅直观易懂,而且简洁明了,只需要几行代码就可以实现。让我们一起踏上这段充满启迪的旅程吧!
二、DPP原理
分布式数据并行(DDP)是一个简单明了的概念。假如我们拥有一个由 4 个 GPU 组成的 GPU 集群。在DDP中,我们将相同的模型复制到每个GPU上进行训练。每个GPU都有自己的优化器,用于更新模型的参数。重点在于数据的划分。(译者注:通常情况下,我们将训练数据划分为多个 mini-batches,然后将这些 mini-batches 分配给多个GPU进行并行处理。每个GPU独立地计算梯度和更新参数,然后将结果同步到其他GPU上。)
如果你对深度学习比较熟悉,应该会知道 DataLoader,这是一种将数据集划分成不同 batches 的工具。通常情况下,我们会将整个数据集分成多个 batches ,模型在每个 batch 上进行计算,并根据计算结果更新模型参数。DDP 进一步细化了这一过程,将每个 batch 划分为 “sub-batches”。实质上,每个模型副本都会处理 primary batch 的一个部分,从而让每个 GPU 都能独立地计算梯度,并根据其处理的数据片段来更新模型的参数。在DDP中,我们通过一种名为 DistributedSampler 的工具将 batch 分成 sub-batches ,如下图所示:

在将每个 sub-batch 分配给各个GPU后,每个GPU都会独立地对其所处理的数据进行计算,并计算出自己独特的梯度(gradient)。
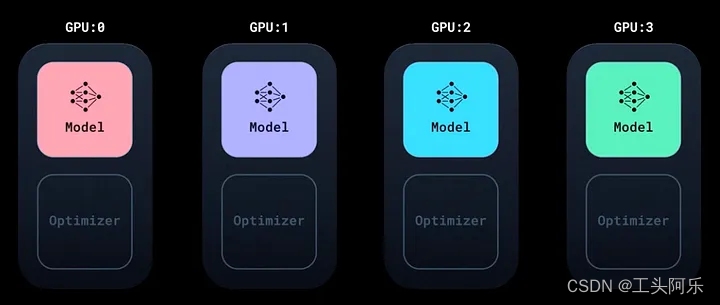
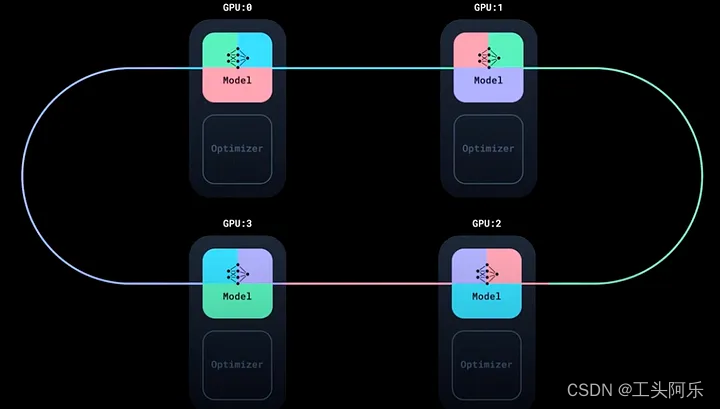
这就是 DDP 的神奇之处。在更新模型参数之前,需要汇总每个 GPU 计算出的梯度,以便每个 GPU 都能获得整个数据 batch 上计算出的平均梯度。具体做法是将所有 GPU 的梯度之和取平均值。例如,如果有 4 个 GPU,那么某个特定模型参数的平均梯度就是 4 个 GPU 上该参数的梯度之和除以 4。DDP 使用 NCCL 或 Gloo 后端(NCCL 针对英伟达(NVIDIA) GPU 进行了优化,而 Gloo 则更为通用)来高效地在 GPU 之间进行通信和将梯度平均。
terms、nodes 和 ranks等相关术语解读
在深入代码之前,先了解 DDP 技术相关术语的含义十分重要。来解释一下这些术语的含义:
Node:可将 Node 视为一台配备了多个 GPU 的高性能计算机。集群(cluster)并不是简单地将一堆 GPU 拼凑在一起。相反,它们被组织成 Groups 或 Nodes。例如,一个 Node 可以容纳 8 个 GPU。
Master Node:在 multi-node(多节点)环境中,通常需要有一个 Node 负责协调工作。这个“Master Node”处理诸如同步、启动模型复制、监控模型加载和管理日志条目等任务。如果没有 Master Node ,每个 GPU 都会独立生成日志,从而导致混乱。
Local Rank:术语“ Rank ” 可以类比为 ID 或位置。Local Rank 指的是 GPU 在其特定 Node(或计算机)中的位置或 ID。它是“ Local ”的,因为它仅限于这台特定的设备。
Global Rank:从全局角度来看,Global Rank 是指 GPU 在所有可用 Node 中的标识。这是一个唯一的标识符,与设备无关。World Size:所有 Node 上可用的所有 GPU 数量。简单来说,就是节点数和每个节点中GPU数量的乘积。从这个角度来看,如果只使用一台机器,情况就会简单明了,因为 Local Rank 等同于 Global Rank。可以用一张图片来说明这一点:


DDP 的局限性
分布式数据并行(DDP)在许多深度学习工作流中都起到了变革性的作用,但了解其局限性也很重要。DDP 的局限性主要在于其内存消耗。使用 DDP 时,每个 GPU 都会加载模型副本、优化器和对应 batch 的数据副本。GPU 的内存大小通常从几 GB 到 80GB 不等。对于较小的模型,使用单个 GPU 都不是问题。但是,当涉及大语言模型(LLM)领域或类似于 GPT 的架构时,单个 GPU 的内存可能就不够用了。在计算机视觉领域,虽然有大量轻量级模型,但当 batch sizes 增加时,特别是在涉及三维图像或物体检测任务的场景下,就会面临挑战。全分片数据并行(Fully Sharded Data Parallel,FSDP)应运而生了。FSDP不仅将数据分布到不同的GPU上,还将模型和优化器的状态也分散到各个 GPU 的内存中。虽然这种方法看起来很好,但 FSDP 增多了 GPU 之间的通信,可能会降低训练速度。
总之:如果您的模型及其相应的 batch 使用单个 GPU 的内存即可满足需求,那么 DDP 技术就是您的最佳选择,因为它的特点是速度快。对于需要使用更多内存的大型模型,FSDP 是更合适的选择。不过,它是通过牺牲速度来换取内存的。
为什么要选择 DDP 而不是 DP
在 PyTorch 的介绍网页中,其实是有两个选项的: DP 和 DDP。但本文此处提及这一内容只是为了避免读者迷失或混淆: 实践中只需使用 DDP,它更快速,而且不局限于单个 Node。

代码演示
实现分布式深度学习比我们想象的要更简单。它的美妙之处在于,我们不再需要被复杂的GPU配置或梯度分布所困扰。
可以在以下链接找到所有的代码模板和脚本:github
下面是详细步骤分解:
- 进程初始化: 这包括指定 master node 、指定端口和设置 world_size。
- 设置 Distributed DataLoader(分布式数据加载器): 这一步的关键是在可用的 GPU 上对每个batch进行分区。需要确保数据均匀分布,没有任何重叠。
- 模型训练/测试: 本质上,这一步与仅使用单 GPU 的操作流程基本保持不变。
1. 在一个单 GPU 的 Node 上进行训练(baseline)
首先,编写下面这段代码,在单 GPU 上加载数据集、创建模型并进行end-to-end(端到端)的训练。这是项目的起点:
作者:Baihai IDP
链接:https://www.zhihu.com/question/348839533/answer/3324079602
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。import torch
import torch.nn.functional as F
from torch.utils.data import Dataset, DataLoader
from sklearn.datasets import load_wine
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
import numpy as npclass WineDataset(Dataset):def __init__(self, data, targets):self.data = dataself.targets = targetsdef __len__(self):return len(self.data)def __getitem__(self, idx):return torch.tensor(self.data[idx], dtype=torch.float), torch.tensor(self.targets[idx], dtype=torch.long)class SimpleNN(torch.nn.Module):def __init__(self):super(SimpleNN, self).__init__()self.fc1 = torch.nn.Linear(13, 64)self.fc2 = torch.nn.Linear(64, 3)def forward(self, x):x = F.relu(self.fc1(x))x = self.fc2(x)return xclass Trainer():def __init__(self, model, train_data, optimizer, gpu_id, save_every):self.model = modelself.train_data = train_dataself.optimizer = optimizerself.gpu_id = gpu_idself.save_every = save_everyself.losses = []def _run_batch(self, source, targets):self.optimizer.zero_grad()output = self.model(source)loss = F.cross_entropy(output, targets)loss.backward()self.optimizer.step()return loss.item()def _run_epoch(self, epoch):total_loss = 0.0num_batches = len(self.train_data)for source, targets in self.train_data:source = source.to(self.gpu_id)targets = targets.to(self.gpu_id)loss = self._run_batch(source, targets)total_loss += lossavg_loss = total_loss / num_batchesself.losses.append(avg_loss)print(f"Epoch {epoch}, Loss: {avg_loss:.4f}")def _save_checkpoint(self, epoch):checkpoint = self.model.state_dict()PATH = f"model_{epoch}.pt"torch.save(checkpoint, PATH)print(f"Epoch {epoch} | Model saved to {PATH}")def train(self, max_epochs):self.model.train()for epoch in range(max_epochs):self._run_epoch(epoch)if epoch % self.save_every == 0:self._save_checkpoint(epoch)def load_train_objs():wine_data = load_wine()X = wine_data.datay = wine_data.target# Normalize and splitX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)scaler = StandardScaler().fit(X_train)X_train = scaler.transform(X_train)X_test = scaler.transform(X_test)train_set = WineDataset(X_train, y_train)test_set = WineDataset(X_test, y_test)print("Sample from dataset:")sample_data, sample_target = train_set[0]print(f"Data: {sample_data}")print(f"Target: {sample_target}")model = SimpleNN()optimizer = torch.optim.Adam(model.parameters(), lr=0.001)return train_set, model, optimizerdef prepare_dataloader(dataset, batch_size):return DataLoader(dataset, batch_size=batch_size, pin_memory=True, shuffle=True)def main(device, total_epochs, save_every, batch_size):dataset, model, optimizer = load_train_objs()train_data = prepare_dataloader(dataset, batch_size)trainer = Trainer(model, train_data, optimizer, device, save_every)trainer.train(total_epochs)main(device=torch.device("cuda:0" if torch.cuda.is_available() else "cpu"), total_epochs=100, save_every=50, batch_size=32)
2. 在一个多 GPU 的 Node 上进行训练
现在,我们将在一个 Node 上使用所有 GPU,步骤如下:
导入分布式训练所需的库。
初始化分布式环境:特别是设置 MASTER_ADDR 和 MASTER_PORT。
使用DistributedDataParallel(DDP)将模型进行封装(译者注:DDP 会自动将模型的参数分布到各个 GPU 上,并在训练过程中进行同步)。
使用 Distributed Sampler 确保数据集以分布式方式划分到各个 GPU 上。
通过调整主函数的方式来生成多个进程,每个进程负责在不同的 GPU 上执行训练任务。
对于所需的库,我们可以通过以下操作导入:
import torch.multiprocessing as mp
from torch.utils.data.distributed import DistributedSampler
from torch.nn.parallel import DistributedDataParallel as DDP
from torch.distributed import init_process_group, destroy_process_group
import os
如果在一个 Node 上有8个GPU,我们将会调用以下函数 8 次,为每个GPU设置一个单独的进程,并且为每个进程指定正确的local_rank参数。
def ddp_setup(rank, world_size):"""Set up the distributed environment.Args:rank: The rank of the current process. Unique identifier for each process in the distributed training.world_size: Total number of processes participating in the distributed training."""# Address of the main node. Since we are doing single-node training, it's set to localhost.os.environ["MASTER_ADDR"] = "localhost"# Port on which the master node is expected to listen for communications from workers.os.environ["MASTER_PORT"] = "12355"# Initialize the process group. # 'backend' specifies the communication backend to be used, "nccl" is optimized for GPU training.init_process_group(backend="nccl", rank=rank, world_size=world_size)# Set the current CUDA device to the specified device (identified by rank).# This ensures that each process uses a different GPU in a multi-GPU setup.torch.cuda.set_device(rank)
关于该函数的一些解释:
MASTER_ADDR是运行主进程(或rank为0的进程)的机器的主机名。在这里是localhost,表示在本地运行。MASTER_PORT:指定主进程用于监听来自工作进程或其他进程连接的端口。12355是任意选择的端口号。只要这个端口号在系统中没有被其他服务使用,并且在防火墙规则中被允许,你可以选择任何未使用的端口号。torch.cuda.set_device(rank):这行代码确保每个进程使用其对应的GPU。然后需要对 Trainer 类稍作更改。
我们只需用 DDP 函数对模型进行封装即可:
class Trainer():def __init__(self, model, train_data, optimizer, gpu_id, save_every):self.model = model.to(gpu_id)self.train_data = train_dataself.optimizer = optimizerself.gpu_id = gpu_idself.save_every = save_everyself.losses = []# This changesself.model = DDP(self.model, device_ids=[gpu_id])
Trainer 类的其他部分都是一样的,amazing!
这种情况下需要调整数据加载器(dataloader),以便在多GPU训练中正确地将批次数据分发到每个GPU上进行处理。
def prepare_dataloader(dataset: Dataset, batch_size: int):return DataLoader(dataset,batch_size=batch_size,pin_memory=True,shuffle=False,sampler=DistributedSampler(dataset))
现在,我们可以修改 main 函数,每个进程都将调用该函数(本文这种情况是调用 8 次):
def main(rank: int, world_size: int, save_every: int, total_epochs: int, batch_size: int):"""Main training function for distributed data parallel (DDP) setup.Args:rank (int): The rank of the current process (0 <= rank < world_size). Each process is assigned a unique rank.world_size (int): Total number of processes involved in the distributed training.save_every (int): Frequency of model checkpoint saving, in terms of epochs.total_epochs (int): Total number of epochs for training.batch_size (int): Number of samples processed in one iteration (forward and backward pass)."""# Set up the distributed environment, including setting the master address, port, and backend.ddp_setup(rank, world_size)# Load the necessary training objects - dataset, model, and optimizer.dataset, model, optimizer = load_train_objs()# Prepare the data loader for distributed training. It partitions the dataset across the processes and handles shuffling.train_data = prepare_dataloader(dataset, batch_size)# Initialize the trainer instance with the loaded model, data, and other configurations.trainer = Trainer(model, train_data, optimizer, rank, save_every)# Train the model for the specified number of epochs.trainer.train(total_epochs)# Cleanup the distributed environment after training is complete.destroy_process_group()
最后,在执行脚本时,我们将需要启动8个进程。这可以通过使用mp.spawn()函数来实现(译者注:mp.spawn()函数是PyTorch提供的用于在多个进程中启动训练任务的功能,它可以方便地启动多个进程,并为每个进程分配相应的GPU和其他资源。):
if __name__ == "__main__":import argparseparser = argparse.ArgumentParser(description='simple distributed training job')parser.add_argument('total_epochs', type=int, help='Total epochs to train the model')parser.add_argument('save_every', type=int, help='How often to save a snapshot')parser.add_argument('--batch_size', default=32, type=int, help='Input batch size on each device (default: 32)')args = parser.parse_args()world_size = torch.cuda.device_count()mp.spawn(main, args=(world_size, args.save_every, args.total_epochs, args.batch_size), nprocs=world_size)
临门一脚: 在多个 Node 上进行训练
恭喜您到达了最后一步!这一步是在不同 Node 上调用所有可用的 GPU。如果您理解了前文所做的工作,这一步就非常容易了。在跨多个 Node 进行扩展时,关键区别在于从 local_rank 到 global_rank 的转变。这一点十分重要,因为每个进程都需要一个唯一的标识符。例如,如果使用两个 Node ,每个 Node 有 8 个 GPU,那么进程 0 和进程 8 的 local_rank 都是 0。
global_rank 的计算公式非常直观:global_rank = node_rank * world_size_per_node + local_rank
因此,我们首先要修改 ddp_setup 函数:
def ddp_setup(local_rank, world_size_per_node, node_rank):os.environ["MASTER_ADDR"] = "MASTER_NODE_IP" # <-- Replace with your master node IPos.environ["MASTER_PORT"] = "12355" global_rank = node_rank * world_size_per_node + local_rankinit_process_group(backend="nccl", rank=global_rank, world_size=world_size_per_node*torch.cuda.device_count())torch.cuda.set_device(local_rank)
还需要调整主函数,该函数现在需要接受world_size_per_node作为参数。
def main(local_rank: int, world_size_per_node: int, save_every: int, total_epochs: int, batch_size: int, node_rank: int):ddp_setup(local_rank, world_size_per_node, node_rank)# ... (rest of the main function)
最后,我们还调整了 mp.spawn() 函数的 world_size_per_node 值:
if __name__ == "__main__":import argparseparser = argparse.ArgumentParser(description='simple distributed training job')parser.add_argument('total_epochs', type=int, help='Total epochs to train the model')parser.add_argument('save_every', type=int, help='How often to save a snapshot')parser.add_argument('--batch_size', default=32, type=int, help='Input batch size on each device (default: 32)')parser.add_argument('--node_rank', default=0, type=int, help='The rank of the node in multi-node training')args = parser.parse_args()world_size_per_node = torch.cuda.device_count()mp.spawn(main, args=(world_size_per_node, args.save_every, args.total_epochs, args.batch_size, args.node_rank), nprocs=world_size_per_node)
4 使用集群 (SLURM)
现在您已经准备好将训练任务发送到集群上。非常简单,你只需调用所需的节点数即可。
以下是 SLURM 脚本的模板:
#!/bin/bash
#SBATCH --job-name=DDPTraining # Name of the job
#SBATCH --nodes=$1 # Number of nodes specified by the user
#SBATCH --ntasks-per-node=1 # Ensure only one task runs per node
#SBATCH --cpus-per-task=1 # Number of CPU cores per task
#SBATCH --gres=gpu:1 # Number of GPUs per node
#SBATCH --time=01:00:00 # Time limit hrs:min:sec (1 hour in this example)
#SBATCH --mem=4GB # Memory limit per GPU
#SBATCH --output=training_%j.log # Output and error log name (%j expands to jobId)
#SBATCH --partition=gpu # Specify the partition or queuesrun python3 your_python_script.py --total_epochs 10 --save_every 2 --batch_size 32 --node_rank $SLURM_NODEID
现在您可以使用以下命令从终端启动训练:sbatch train_net.sh 2 # for using 2 nodes
祝贺你,你成功了!
感谢阅读!
https://www.youtube.com/watch?v=Cvdhwx-OBBo
https://www.youtube.com/watch?v=KaAJtI1T2x4
https://pytorch.org/tutorials/beginner/ddp_series_theory.html
https://towardsdatascience.com/a-comprehensive-guide-of-distributed-data-parallel-ddp-2bb1d8b5edfb


![寻找两个正序数组的中位数[困难]](https://img-blog.csdnimg.cn/direct/b120198f26d8457c8da11e00c4382c54.jpeg)