文章目录
- 一、概述
- 二、Zookeeper on k8s 部署
- 1)添加源
- 2)修改配置
- 3)开始安装
- 4)测试验证
- 5)Prometheus监控
- 6)卸载
- 三、Kafka on k8s 部署
- 1)添加源
- 2)修改配置
- 3)开始安装
- 4)测试验证
- 1、创建Topic(一个副本一个分区)
- 2、查看Topic列表
- 3、生产者/消费者测试
- 4、查看数据积压
- 5、删除topic
- 5)Prometheus监控
- 6)卸载
一、概述
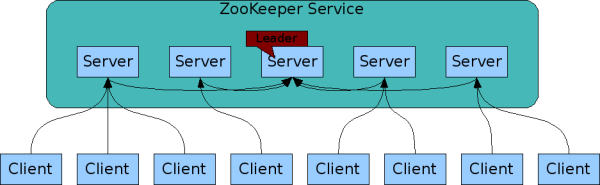
Apache ZooKeeper是一个集中式服务,用于维护配置信息、命名、提供分布式同步和提供组服务,ZooKeeper 致力于开发和维护一个开源服务器,以实现高度可靠的分布式协调,其实也可以认为就是一个分布式数据库,只是结构比较特殊,是树状结构。官网文档:https://zookeeper.apache.org/doc/r3.8.0/
,关于Zookeeper的介绍,也可以参考我之前的文章:分布式开源协调服务——Zookeeper
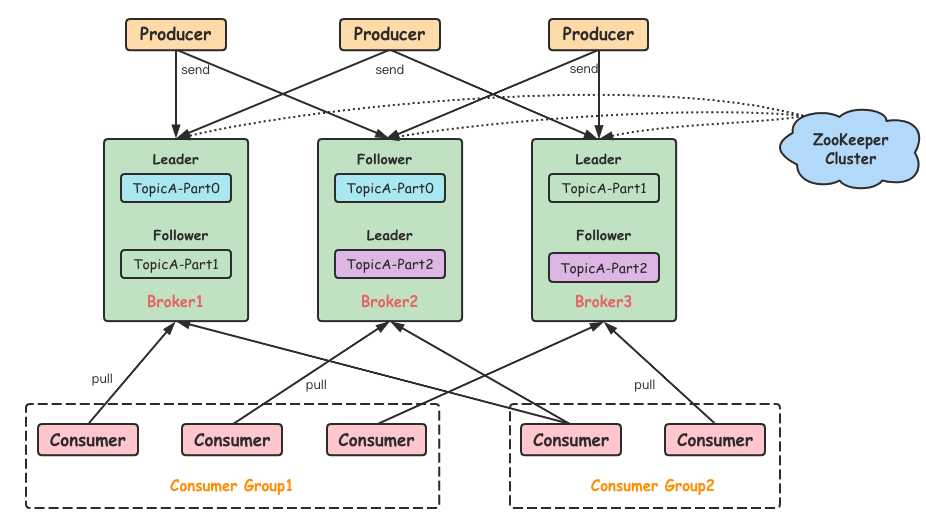
Kafka是最初由Linkedin公司开发,是一个分布式、支持分区的(partition)、多副本的(replica),基于zookeeper协调的分布式消息系统。官方文档:https://kafka.apache.org/documentation/关于Kafka的介绍,也可以参考我之前的文章:Kafka原理介绍+安装+基本操作
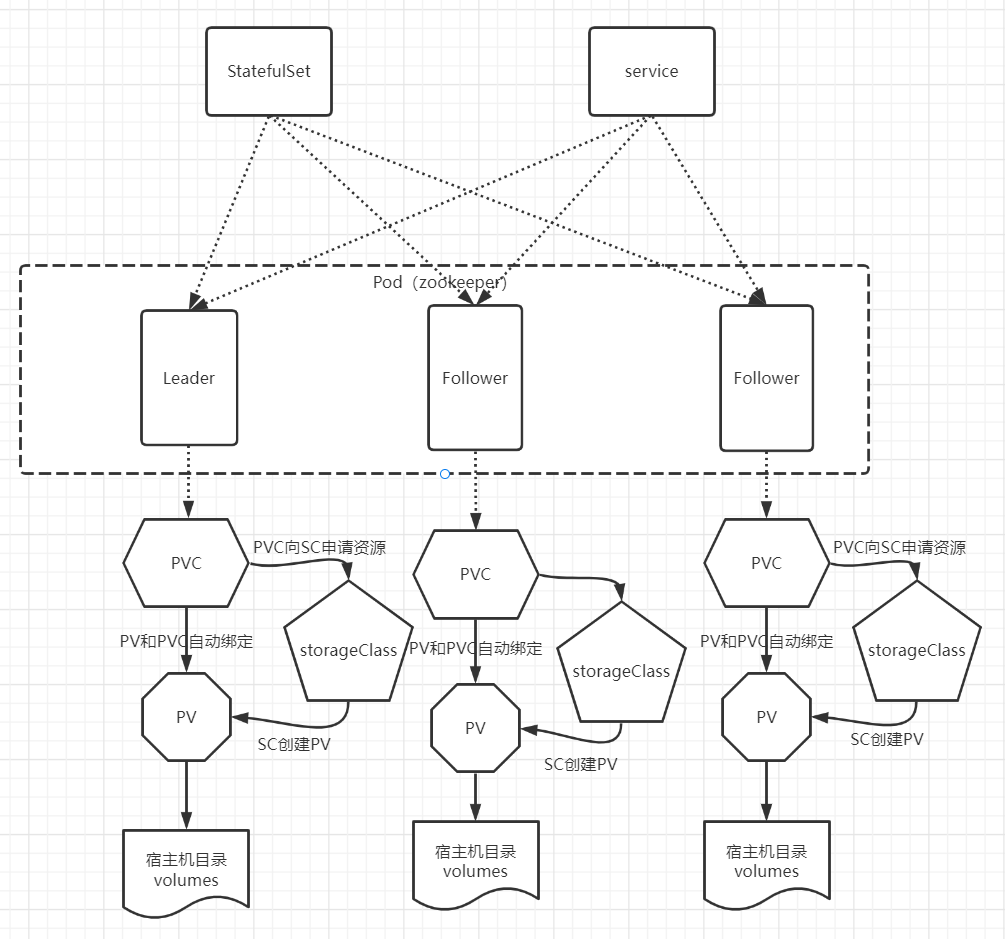
二、Zookeeper on k8s 部署
1)添加源
部署包地址:https://artifacthub.io/packages/helm/zookeeper/zookeeper
helm repo add bitnami https://charts.bitnami.com/bitnami
helm pull bitnami/zookeeper
tar -xf zookeeper-10.2.1.tgz
2)修改配置
- 修改
zookeeper/values.yaml
image:registry: myharbor.comrepository: bigdata/zookeepertag: 3.8.0-debian-11-r36
...replicaCount: 3...service:type: NodePortnodePorts:#NodePort 默认范围是 30000-32767client: "32181"tls: "32182"...persistence:storageClass: "zookeeper-local-storage"size: "10Gi"# 目录需要提前在宿主机上创建local:- name: zookeeper-0host: "local-168-182-110"path: "/opt/bigdata/servers/zookeeper/data/data1"- name: zookeeper-1host: "local-168-182-111"path: "/opt/bigdata/servers/zookeeper/data/data1"- name: zookeeper-2host: "local-168-182-112"path: "/opt/bigdata/servers/zookeeper/data/data1"...# Enable Prometheus to access ZooKeeper metrics endpoint
metrics:enabled: true
- 添加
zookeeper/templates/pv.yaml
{{- range .Values.persistence.local }}
---
apiVersion: v1
kind: PersistentVolume
metadata:name: {{ .name }}labels:name: {{ .name }}
spec:storageClassName: {{ $.Values.persistence.storageClass }}capacity:storage: {{ $.Values.persistence.size }}accessModes:- ReadWriteOncelocal:path: {{ .path }}nodeAffinity:required:nodeSelectorTerms:- matchExpressions:- key: kubernetes.io/hostnameoperator: Invalues:- {{ .host }}
---
{{- end }}- 添加
zookeeper/templates/storage-class.yaml
kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:name: {{ .Values.persistence.storageClass }}
provisioner: kubernetes.io/no-provisioner
3)开始安装
# 先准备好镜像
docker pull docker.io/bitnami/zookeeper:3.8.0-debian-11-r36
docker tag docker.io/bitnami/zookeeper:3.8.0-debian-11-r36 myharbor.com/bigdata/zookeeper:3.8.0-debian-11-r36
docker push myharbor.com/bigdata/zookeeper:3.8.0-debian-11-r36# 开始安装
helm install zookeeper ./zookeeper -n zookeeper --create-namespace
NOTES
NAME: zookeeper
LAST DEPLOYED: Sun Sep 18 18:24:03 2022
NAMESPACE: zookeeper
STATUS: deployed
REVISION: 1
TEST SUITE: None
NOTES:
CHART NAME: zookeeper
CHART VERSION: 10.2.1
APP VERSION: 3.8.0** Please be patient while the chart is being deployed **ZooKeeper can be accessed via port 2181 on the following DNS name from within your cluster:zookeeper.zookeeper.svc.cluster.localTo connect to your ZooKeeper server run the following commands:export POD_NAME=$(kubectl get pods --namespace zookeeper -l "app.kubernetes.io/name=zookeeper,app.kubernetes.io/instance=zookeeper,app.kubernetes.io/component=zookeeper" -o jsonpath="{.items[0].metadata.name}")kubectl exec -it $POD_NAME -- zkCli.shTo connect to your ZooKeeper server from outside the cluster execute the following commands:export NODE_IP=$(kubectl get nodes --namespace zookeeper -o jsonpath="{.items[0].status.addresses[0].address}")export NODE_PORT=$(kubectl get --namespace zookeeper -o jsonpath="{.spec.ports[0].nodePort}" services zookeeper)zkCli.sh $NODE_IP:$NODE_PORT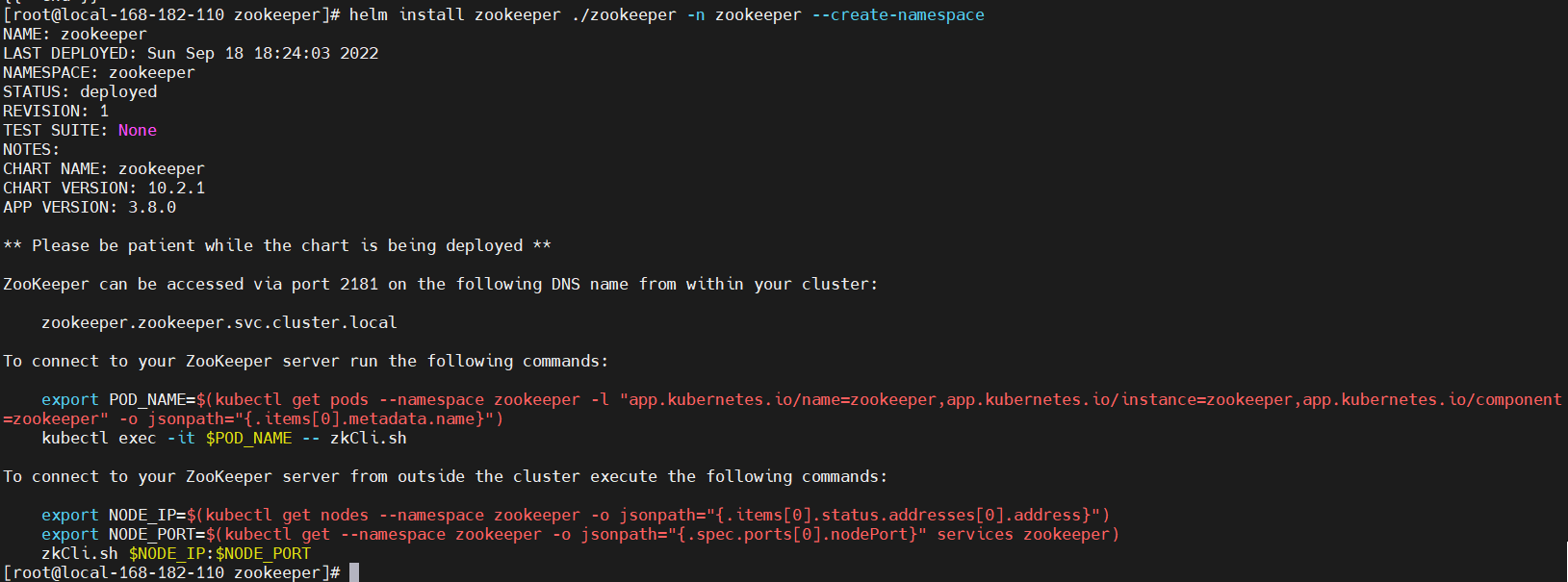
查看pod状态
kubectl get pods,svc -n zookeeper -owide

4)测试验证
# 登录zookeeper pod
kubectl exec -it zookeeper-0 -n zookeeper -- zkServer.sh status
kubectl exec -it zookeeper-1 -n zookeeper -- zkServer.sh status
kubectl exec -it zookeeper-2 -n zookeeper -- zkServer.sh statuskubectl exec -it zookeeper-0 -n zookeeper -- bash
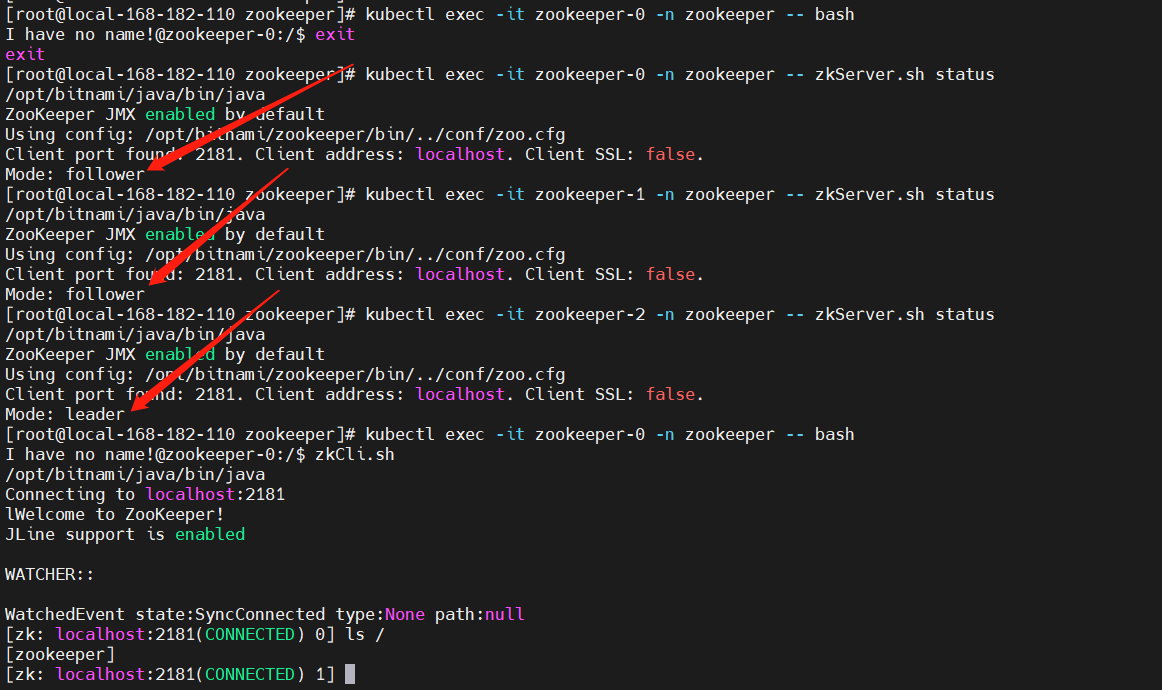
5)Prometheus监控
Prometheus:https://prometheus.k8s.local/targets?search=zookeeper
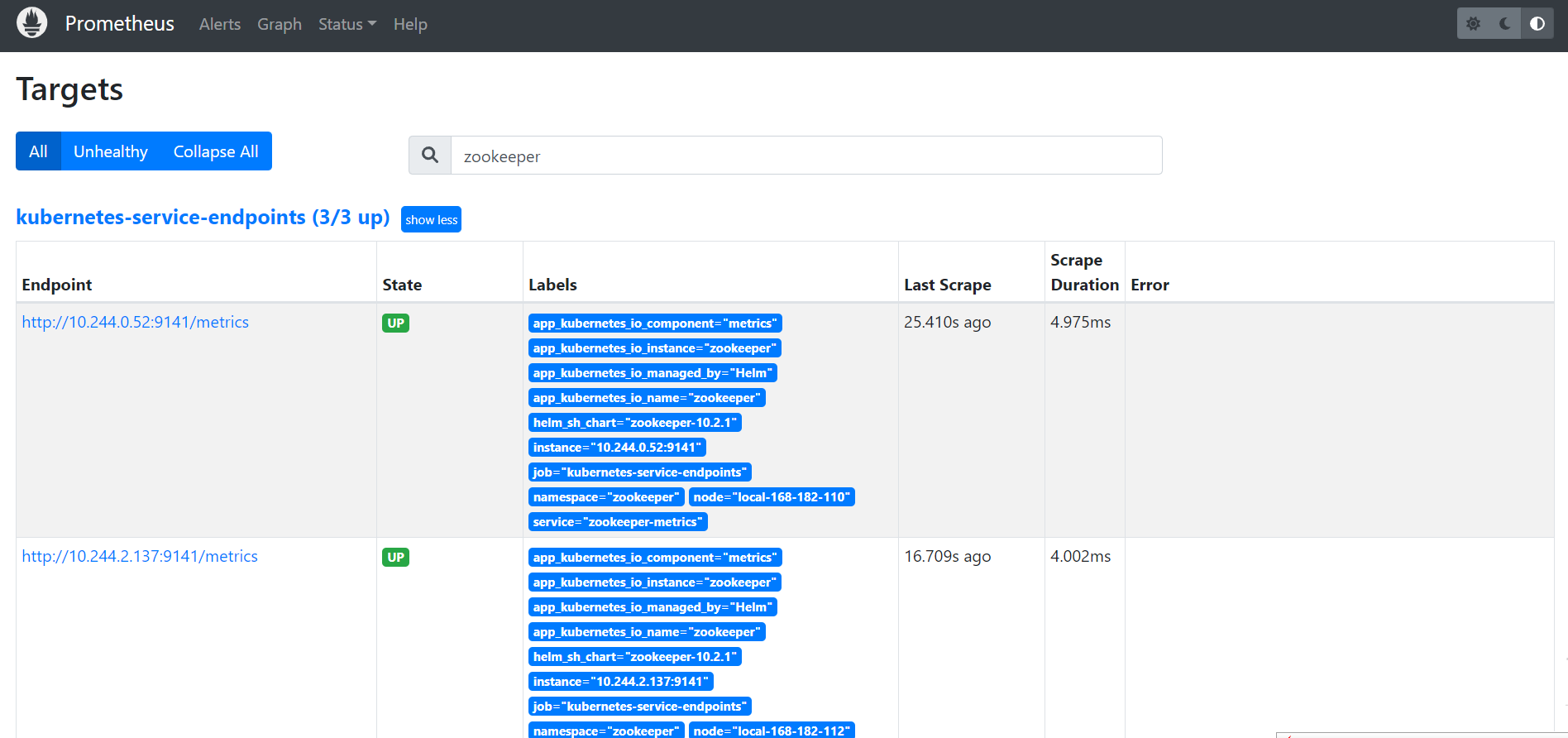
可以通过命令查看采集数据
kubectl get --raw http://10.244.0.52:9141/metrics
kubectl get --raw http://10.244.1.101:9141/metrics
kubectl get --raw http://10.244.2.137:9141/metrics
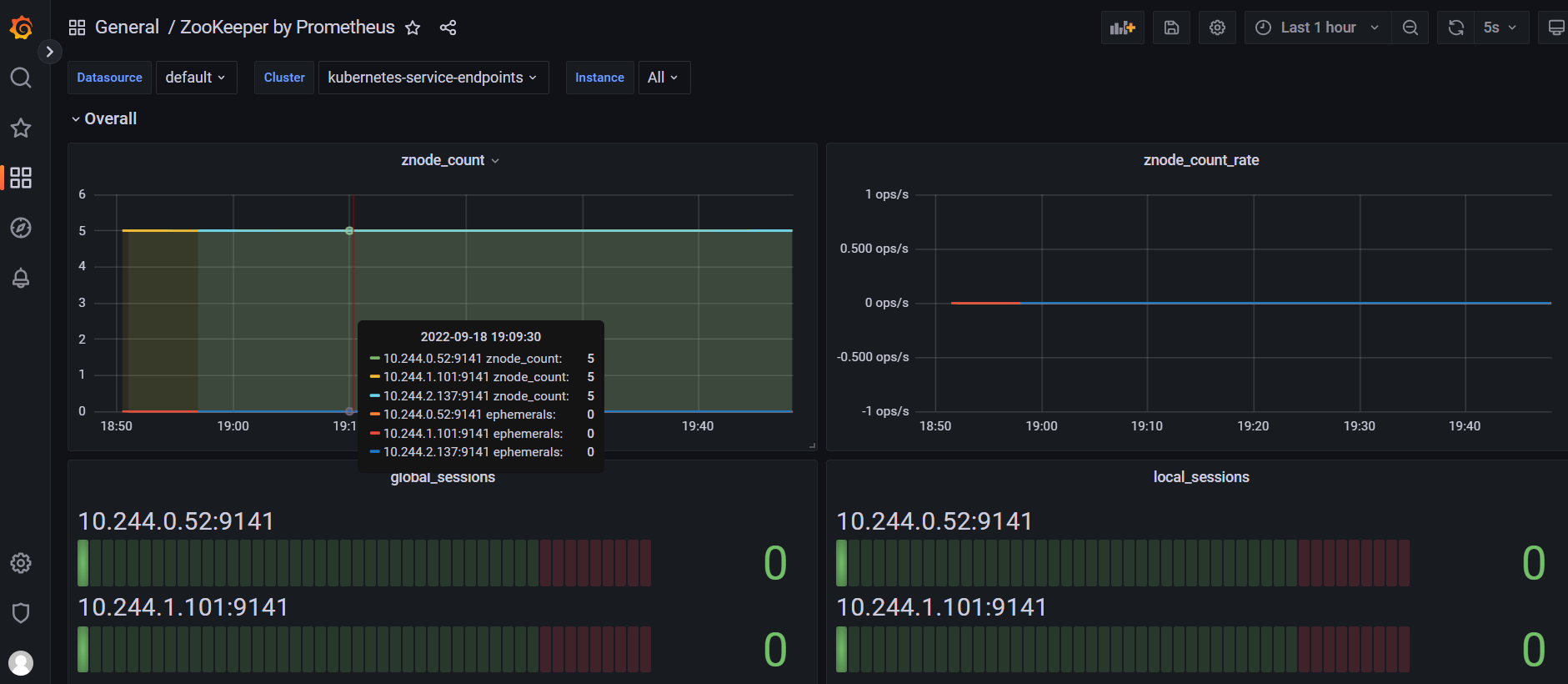
Grafana:https://grafana.k8s.local/
账号:admin,密码通过下面命令获取
kubectl get secret --namespace grafana grafana -o jsonpath="{.data.admin-password}" | base64 --decode ; echo
导入grafana模板,集群资源监控:10465
官方模块下载地址:https://grafana.com/grafana/dashboards/
6)卸载
helm uninstall zookeeper -n zookeeperkubectl delete pod -n zookeeper `kubectl get pod -n zookeeper|awk 'NR>1{print $1}'` --force
kubectl patch ns zookeeper -p '{"metadata":{"finalizers":null}}'
kubectl delete ns zookeeper --force
三、Kafka on k8s 部署
1)添加源
部署包地址:https://artifacthub.io/packages/helm/bitnami/kafka
helm repo add bitnami https://charts.bitnami.com/bitnami
helm pull bitnami/kafka
tar -xf kafka-18.4.2.tgz
2)修改配置
- 修改
kafka/values.yaml
image:registry: myharbor.comrepository: bigdata/kafkatag: 3.2.1-debian-11-r16...replicaCount: 3...service:type: NodePortnodePorts:client: "30092"external: "30094"...externalAccessenabled: trueservice:type: NodePortnodePorts:- 30001- 30002- 30003useHostIPs: true...persistence:storageClass: "kafka-local-storage"size: "10Gi"# 目录需要提前在宿主机上创建local:- name: kafka-0host: "local-168-182-110"path: "/opt/bigdata/servers/kafka/data/data1"- name: kafka-1host: "local-168-182-111"path: "/opt/bigdata/servers/kafka/data/data1"- name: kafka-2host: "local-168-182-112"path: "/opt/bigdata/servers/kafka/data/data1"...metrics:kafka:enabled: trueimage:registry: myharbor.comrepository: bigdata/kafka-exportertag: 1.6.0-debian-11-r8jmx:enabled: trueimage:registry: myharbor.comrepository: bigdata/jmx-exportertag: 0.17.1-debian-11-r1annotations:prometheus.io/path: "/metrics"...zookeeper:enabled: false...externalZookeeperservers:- zookeeper-0.zookeeper-headless.zookeeper- zookeeper-1.zookeeper-headless.zookeeper- zookeeper-2.zookeeper-headless.zookeeper
- 添加
kafka/templates/pv.yaml
{{- range .Values.persistence.local }}
---
apiVersion: v1
kind: PersistentVolume
metadata:name: {{ .name }}labels:name: {{ .name }}
spec:storageClassName: {{ $.Values.persistence.storageClass }}capacity:storage: {{ $.Values.persistence.size }}accessModes:- ReadWriteOncelocal:path: {{ .path }}nodeAffinity:required:nodeSelectorTerms:- matchExpressions:- key: kubernetes.io/hostnameoperator: Invalues:- {{ .host }}
---
{{- end }}
- 添加
kafka/templates/storage-class.yaml
kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:name: {{ .Values.persistence.storageClass }}
provisioner: kubernetes.io/no-provisioner
3)开始安装
# 先准备好镜像
docker pull docker.io/bitnami/kafka:3.2.1-debian-11-r16
docker tag docker.io/bitnami/kafka:3.2.1-debian-11-r16 myharbor.com/bigdata/kafka:3.2.1-debian-11-r16
docker push myharbor.com/bigdata/kafka:3.2.1-debian-11-r16# node-export
docker pull docker.io/bitnami/kafka-exporter:1.6.0-debian-11-r8
docker tag docker.io/bitnami/kafka-exporter:1.6.0-debian-11-r8 myharbor.com/bigdata/kafka-exporter:1.6.0-debian-11-r8
docker push myharbor.com/bigdata/kafka-exporter:1.6.0-debian-11-r8# JXM
docker.io/bitnami/jmx-exporter:0.17.1-debian-11-r1
docker tag docker.io/bitnami/jmx-exporter:0.17.1-debian-11-r1 myharbor.com/bigdata/jmx-exporter:0.17.1-debian-11-r1
docker push myharbor.com/bigdata/jmx-exporter:0.17.1-debian-11-r1#开始安装
helm install kafka ./kafka -n kafka --create-namespace
NOTES
NAME: kafka
LAST DEPLOYED: Sun Sep 18 20:57:02 2022
NAMESPACE: kafka
STATUS: deployed
REVISION: 1
TEST SUITE: None
NOTES:
CHART NAME: kafka
CHART VERSION: 18.4.2
APP VERSION: 3.2.1
---------------------------------------------------------------------------------------------WARNINGBy specifying "serviceType=LoadBalancer" and not configuring the authenticationyou have most likely exposed the Kafka service externally without anyauthentication mechanism.For security reasons, we strongly suggest that you switch to "ClusterIP" or"NodePort". As alternative, you can also configure the Kafka authentication.---------------------------------------------------------------------------------------------** Please be patient while the chart is being deployed **Kafka can be accessed by consumers via port 9092 on the following DNS name from within your cluster:kafka.kafka.svc.cluster.localEach Kafka broker can be accessed by producers via port 9092 on the following DNS name(s) from within your cluster:kafka-0.kafka-headless.kafka.svc.cluster.local:9092kafka-1.kafka-headless.kafka.svc.cluster.local:9092kafka-2.kafka-headless.kafka.svc.cluster.local:9092To create a pod that you can use as a Kafka client run the following commands:kubectl run kafka-client --restart='Never' --image docker.io/bitnami/kafka:3.2.1-debian-11-r16 --namespace kafka --command -- sleep infinitykubectl exec --tty -i kafka-client --namespace kafka -- bashPRODUCER:kafka-console-producer.sh \--broker-list kafka-0.kafka-headless.kafka.svc.cluster.local:9092,kafka-1.kafka-headless.kafka.svc.cluster.local:9092,kafka-2.kafka-headless.kafka.svc.cluster.local:9092 \--topic testCONSUMER:kafka-console-consumer.sh \--bootstrap-server kafka.kafka.svc.cluster.local:9092 \--topic test \--from-beginningTo connect to your Kafka server from outside the cluster, follow the instructions below:Kafka brokers domain: You can get the external node IP from the Kafka configuration file with the following commands (Check the EXTERNAL listener)1. Obtain the pod name:kubectl get pods --namespace kafka -l "app.kubernetes.io/name=kafka,app.kubernetes.io/instance=kafka,app.kubernetes.io/component=kafka"2. Obtain pod configuration:kubectl exec -it KAFKA_POD -- cat /opt/bitnami/kafka/config/server.properties | grep advertised.listenersKafka brokers port: You will have a different node port for each Kafka broker. You can get the list of configured node ports using the command below:echo "$(kubectl get svc --namespace kafka -l "app.kubernetes.io/name=kafka,app.kubernetes.io/instance=kafka,app.kubernetes.io/component=kafka,pod" -o jsonpath='{.items[*].spec.ports[0].nodePort}' | tr ' ' '\n')"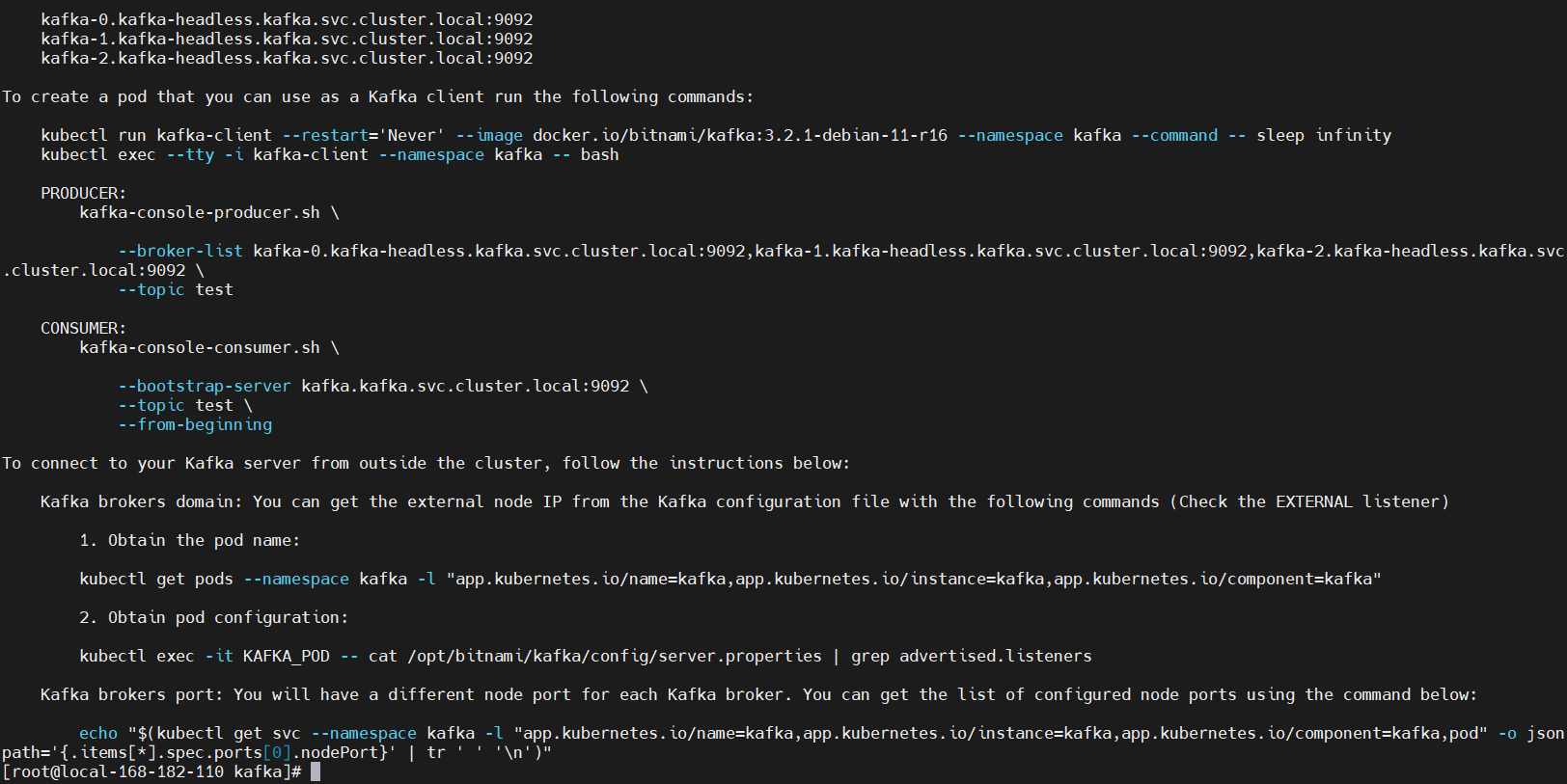
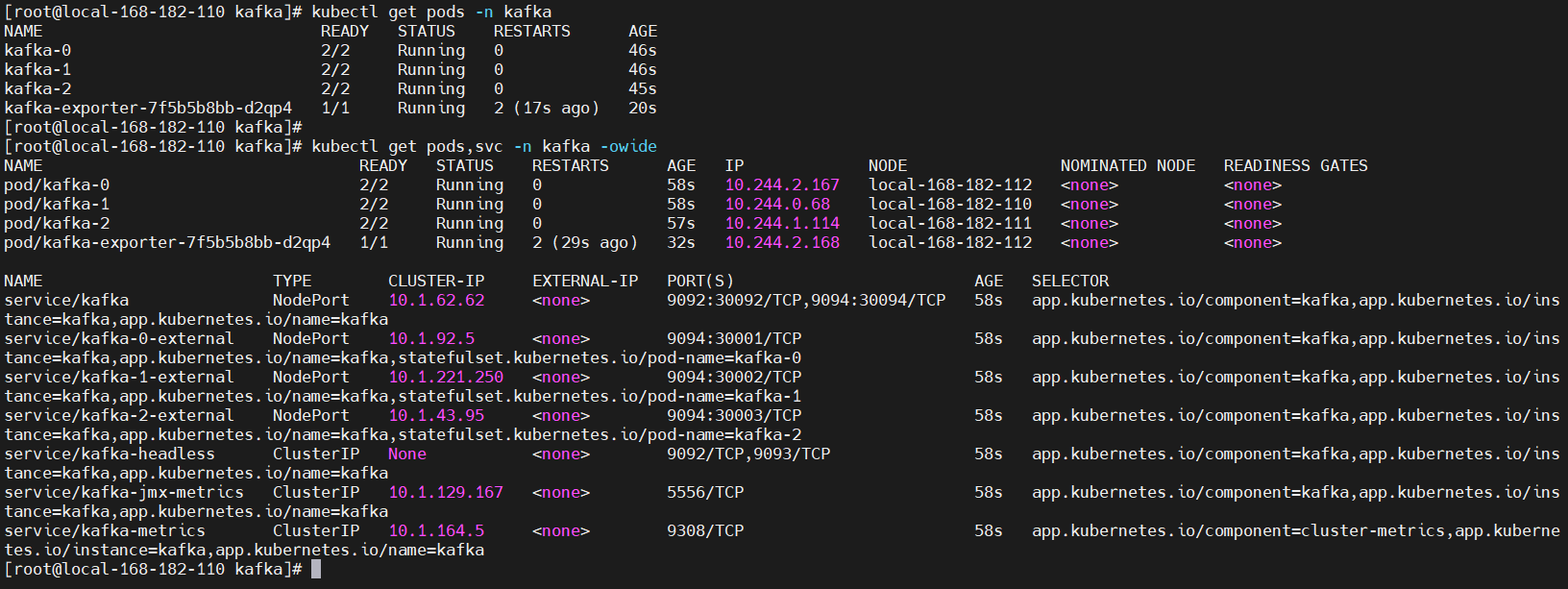
查看pod状态
kubectl get pods,svc -n kafka -owide
4)测试验证
# 登录zookeeper pod
kubectl exec -it kafka-0 -n kafka -- bash
1、创建Topic(一个副本一个分区)
--create: 指定创建topic动作--topic:指定新建topic的名称--bootstrap-server: 指定kafka连接地址--config:指定当前topic上有效的参数值,参数列表参考文档为: Topic-level configuration--partitions:指定当前创建的kafka分区数量,默认为1个--replication-factor:指定每个分区的复制因子个数,默认1个
kafka-topics.sh --create --topic test001 --bootstrap-server kafka.kafka:9092 --partitions 1 --replication-factor 1
# 查看
kafka-topics.sh --describe --bootstrap-server kafka.kafka:9092 --topic test001
2、查看Topic列表
kafka-topics.sh --list --bootstrap-server kafka.kafka:9092
3、生产者/消费者测试
【生产者】
kafka-console-producer.sh --broker-list kafka.kafka:9092 --topic test001{"id":"1","name":"n1","age":"20"}
{"id":"2","name":"n2","age":"21"}
{"id":"3","name":"n3","age":"22"}
【消费者】
# 从头开始消费
kafka-console-consumer.sh --bootstrap-server kafka.kafka:9092 --topic test001 --from-beginning
# 指定从分区的某个位置开始消费,这里只指定了一个分区,可以多写几行或者遍历对应的所有分区
kafka-console-consumer.sh --bootstrap-server kafka.kafka:9092 --topic test001 --partition 0 --offset 100 --group test001
4、查看数据积压
kafka-consumer-groups.sh --bootstrap-server kafka.kafka:9092 --describe --group test001
5、删除topic
kafka-topics.sh --delete --topic test001 --bootstrap-server kafka.kafka:9092
5)Prometheus监控
Prometheus:https://prometheus.k8s.local/targets?search=kafka
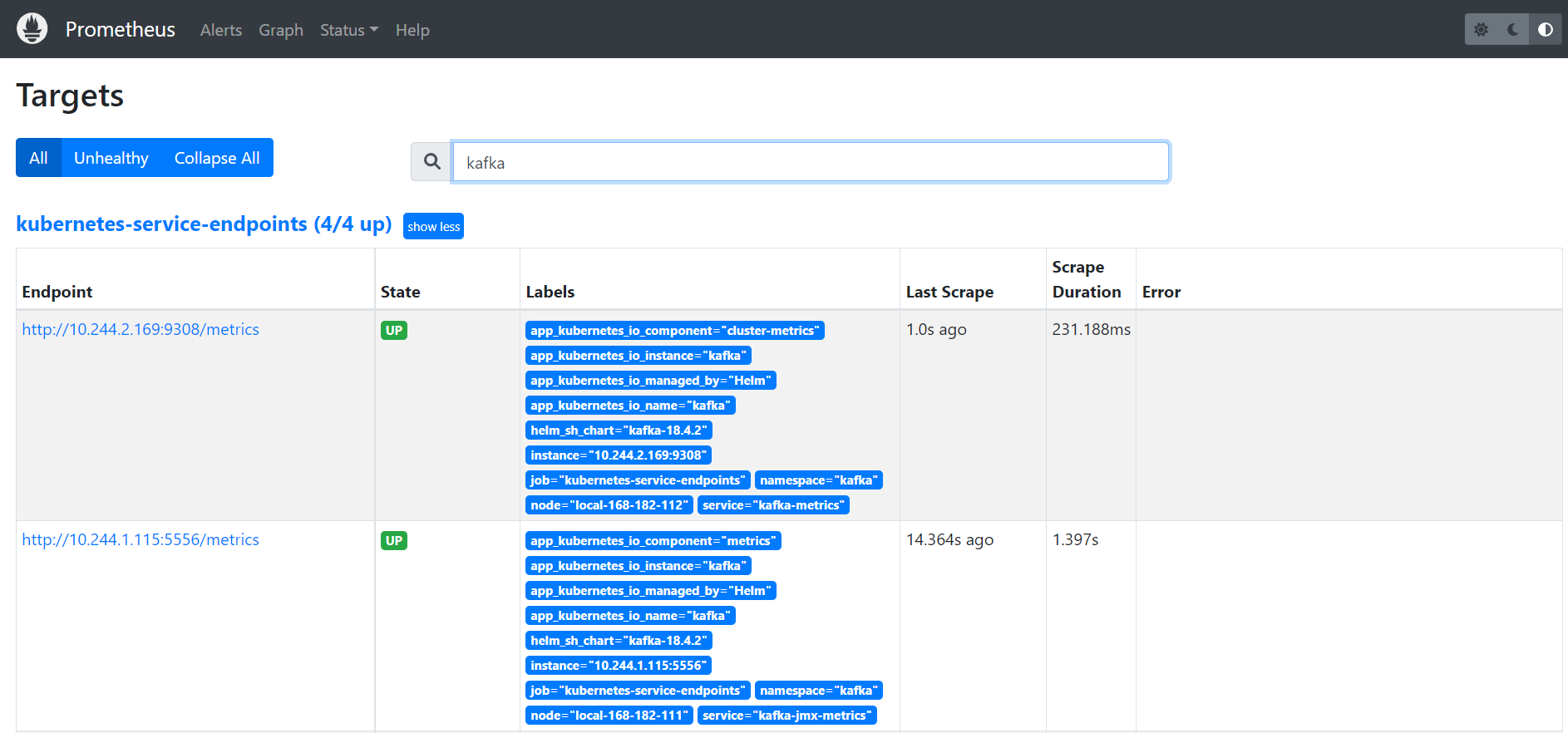
可以通过命令查看采集数据
kubectl get --raw http://10.244.2.165:9308/metrics
Grafana:https://grafana.k8s.local/
账号:admin,密码通过下面命令获取
kubectl get secret --namespace grafana grafana -o jsonpath="{.data.admin-password}" | base64 --decode ; echo
导入grafana模板,集群资源监控:11962
官方模块下载地址:https://grafana.com/grafana/dashboards/
6)卸载
helm uninstall kafka -n kafkakubectl delete pod -n kafka `kubectl get pod -n kafka|awk 'NR>1{print $1}'` --force
kubectl patch ns kafka -p '{"metadata":{"finalizers":null}}'
kubectl delete ns kafka --force
zookeeper + kafka on k8s 环境部署 就先到这里了,小伙伴有任何疑问,欢迎给我留言,后续会持续分享【云原生和大数据】相关的问题~