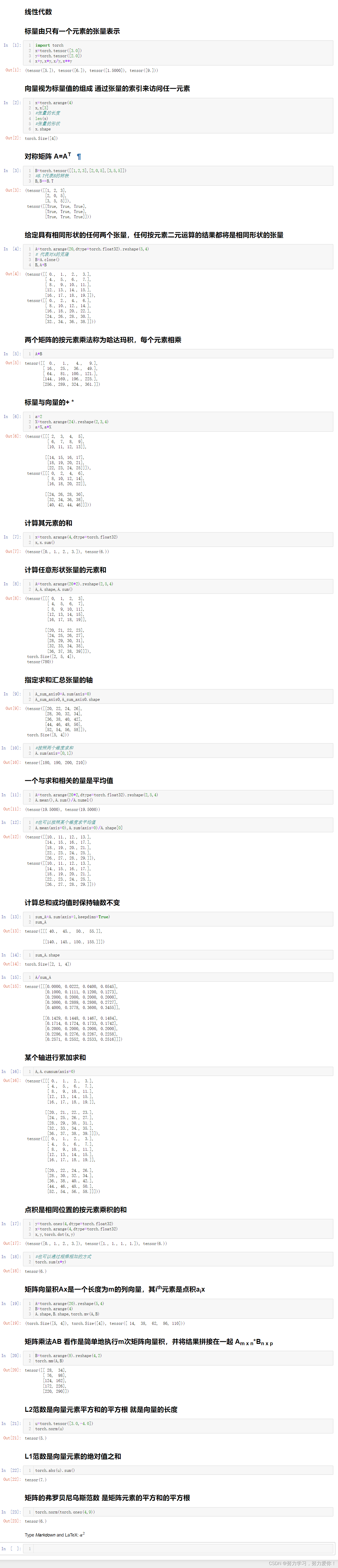
import torch
x= torch. tensor( [ 3.0 ] )
y= torch. tensor( [ 2.0 ] )
x+ y, x* y, x/ y, x** y
x= torch. arange( 4 )
x, x[ 3 ]
len ( x)
x. shape
B= torch. tensor( [ [ 1 , 2 , 3 ] , [ 2 , 0 , 5 ] , [ 3 , 5 , 5 ] ] )
B, B== B. T
A= torch. arange( 20 , dtype= torch. float32) . reshape( 5 , 4 )
B= A. clone( )
B, A+ B
A* B
a= 2
X= torch. arange( 24 ) . reshape( 2 , 3 , 4 )
a+ X, a* X
x= torch. arange( 4 , dtype= torch. float32)
x, x. sum ( )
A= torch. arange( 20 * 2 ) . reshape( 2 , 5 , 4 )
A, A. shape, A. sum ( )
A_sum_axis0= A. sum ( axis= 0 )
A_sum_axis0, A_sum_axis0. shape
A= torch. arange( 20 * 2 , dtype= torch. float32) . reshape( 2 , 5 , 4 )
A. mean( ) , A. sum ( ) / A. numel( )
A. mean( axis= 0 ) , A. sum ( axis= 0 ) / A. shape[ 0 ]
sum_A= A. sum ( axis= 1 , keepdims= True )
sum_A
sum_A. shape
A/ sum_A
A, A. cumsum( axis= 0 )
y= torch. ones( 4 , dtype= torch. float32)
x= torch. arange( 4 , dtype= torch. float32)
x, y, torch. dot( x, y)
torch. sum ( x* y)
A= torch. arange( 20 ) . reshape( 5 , 4 )
B= torch. arange( 4 )
A. shape, B. shape, torch. mv( A, B)
B= torch. arange( 8 ) . reshape( 4 , 2 )
torch. mm( A, B)
u= torch. tensor( [ 3.0 , - 4.0 ] )
torch. norm( u)
torch. abs ( u) . sum ( )
torch. norm( torch. ones( 4 , 9 ) )
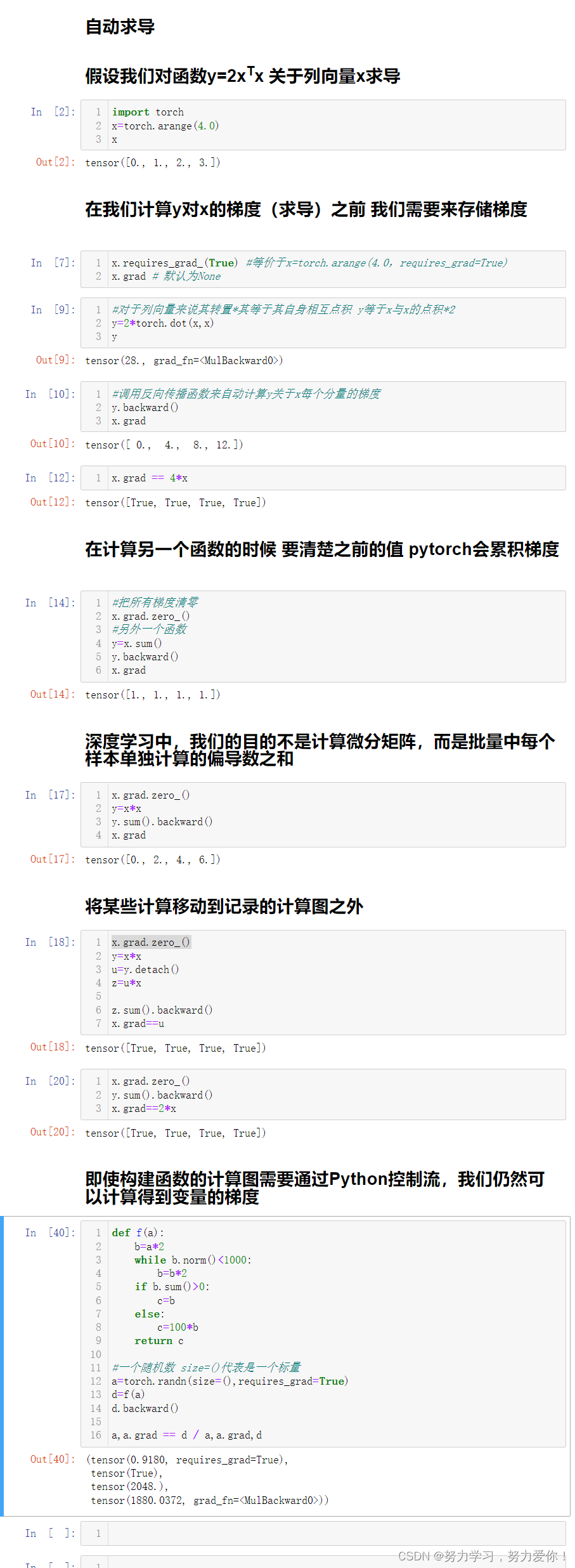
import torch
x= torch. arange( 4.0 )
x
x. requires_grad_( True )
x. grad
y= 2 * torch. dot( x, x)
y
y. backward( )
x. grad
x. grad == 4 * x
x. grad. zero_( )
y= x. sum ( )
y. backward( )
x. grad
x. grad. zero_( )
y= x* x
y. sum ( ) . backward( )
x. grad
x. grad. zero_( )
y= x* x
u= y. detach( )
z= u* xz. sum ( ) . backward( )
x. grad== ux. grad. zero_( )
y. sum ( ) . backward( )
x. grad== 2 * x
def f ( a) : b= a* 2 while b. norm( ) < 1000 : b= b* 2 if b. sum ( ) > 0 : c= belse : c= 100 * breturn c
a= torch. randn( size= ( ) , requires_grad= True )
d= f( a)
d. backward( )
a. grad== d/ a
如有问题,欢迎指正!