文章目录
- 一、Prompt Engineering(怎么去提问大模型)
- 1)环境准备
- 2)交互代码的参数备注
- 3)交互代码
- 二、LangChain(一个框架去使用大模型)
- 1)LangChain核心介绍:I/O模块、数据链接模块、记忆模块
- 2)I/O模块(Prompts、Language models、Output parsers)
- 3)数据链接模块(Data connection)
- 4)记忆模块(针对多轮对话强相关,这种大模型有个特点:都是话痨)
- 三、Fine-tuning(如果在自己领域中改变大模型)
- 1)from scratch:从头训练
- 2)finetune:微调/接着别人的训练
- (1)全参数 fine tune
- (2)小参数fine tune
- (3)小参数的LoRA原理解析:
- (4)训练大模型
一、Prompt Engineering(怎么去提问大模型)
1)环境准备
①安装OpenAI库
pip install --upgrade openai
- 附加
安装来源
python setup.py install
②生成API key
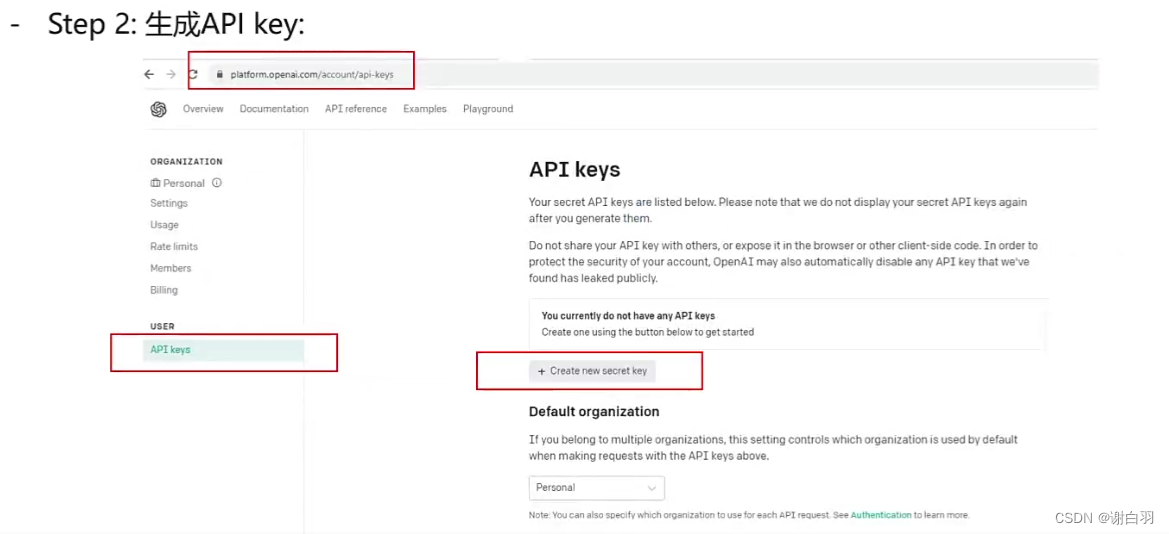
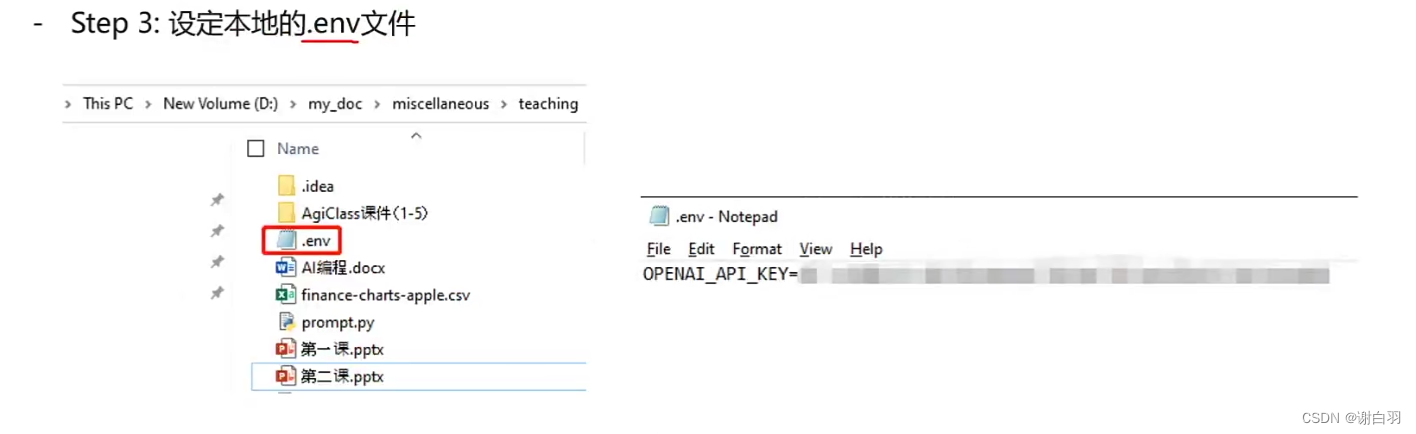
③设定本地的环境变量
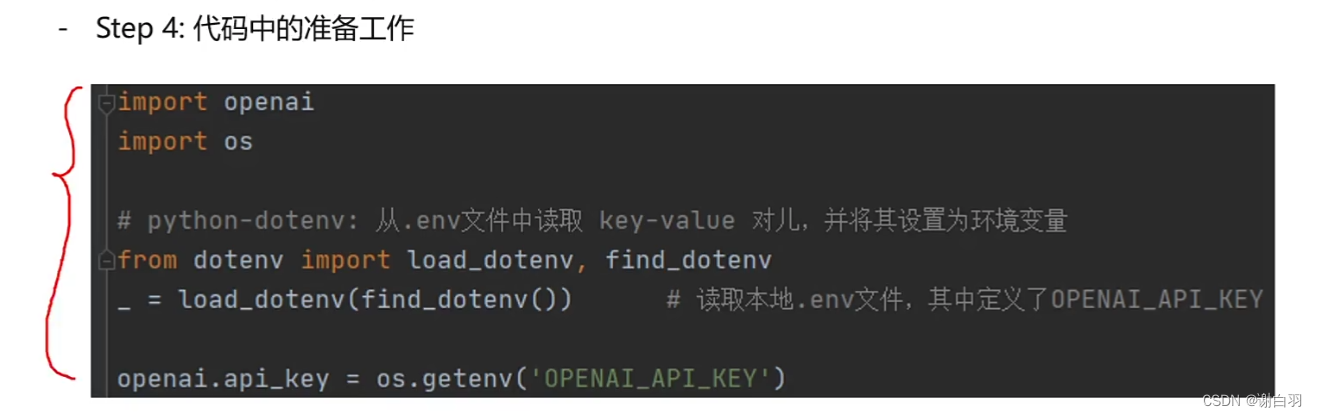
④代码的准备工作
⑤在代码运用prompt(简单提问和返回)
2)交互代码的参数备注
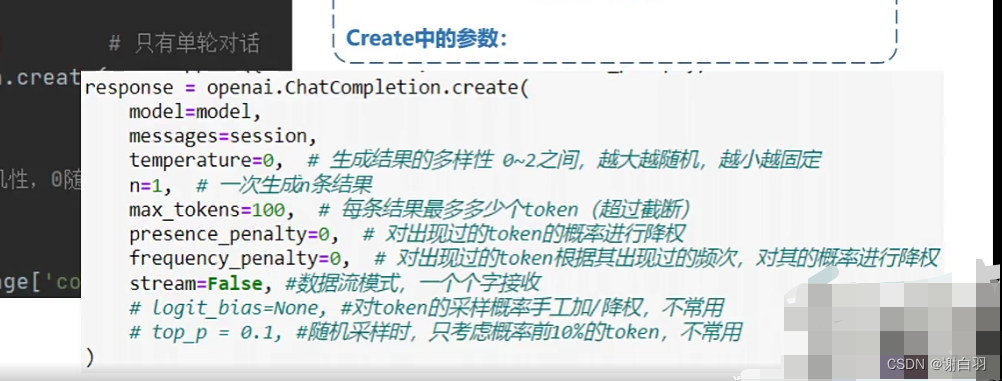
temperature:随机性(从0到2可以调节,回答天马行空变化大可以选2)
model:跟什么类型的model互动
role:(定义交互中的角色)
①user:交互中的我
②assistant:交互中的model
③system:交互中的大环境(需要预先设定。比如告诉模型,你是一个AI专家,在接下来的互动中,回答尽量用专业术语)
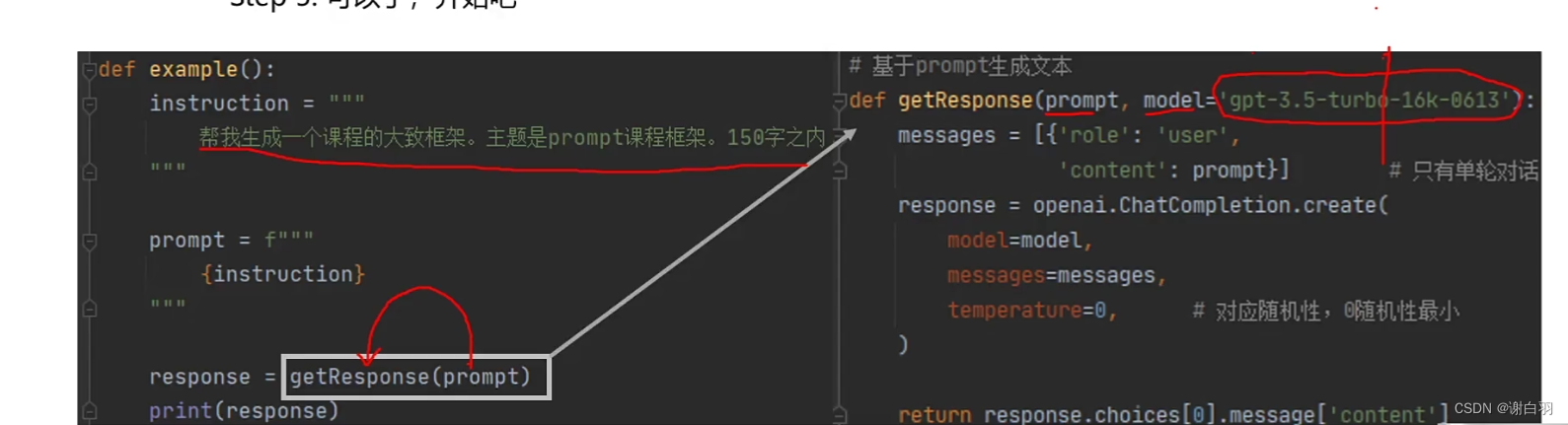
3)交互代码
- 单论交互代码
import openai
import os#从.env文件中读取 key-value键值对,并将其设置为环境变量
from dotenv import load_dotenv,find_dotenv
_ = load_dotenv(find_dotenv())#获取OPENAI_API_KEY对应键值对数据
openai.api_key = os.getenv('OPENAI_API_KEY')def getResponse(prompt,model='gpt-3.5-turbo-16k-0613'):messages = [{'role':'user','content':prompt}] #只有单论对话response = openai.ChatCompletion.create(model = model,messages = messages,temperature = 0, #对应随机性,0随机性最小)def example():instruction = """帮我生成一个课程的大概框架,主题是prompt的框架,150字之内"""prompt = f"""{instruction}"""response = getResponse(prompt)print(response)return response.choices[0].messages['content']二、LangChain(一个框架去使用大模型)
- 介绍
通过输入自己的知识库来定制化自己的大语言模型
1)LangChain核心介绍:I/O模块、数据链接模块、记忆模块
-
备注
这篇文章主讲I/O模块、数据链路模块、记忆模块(时间关系讲的少) -
模块主题可以完整拆分为6部分
①I/O模块
②数据链路模块
③记忆模块
④链(Chain)模块
⑤智能体(Agent)模块
⑥Callbacks
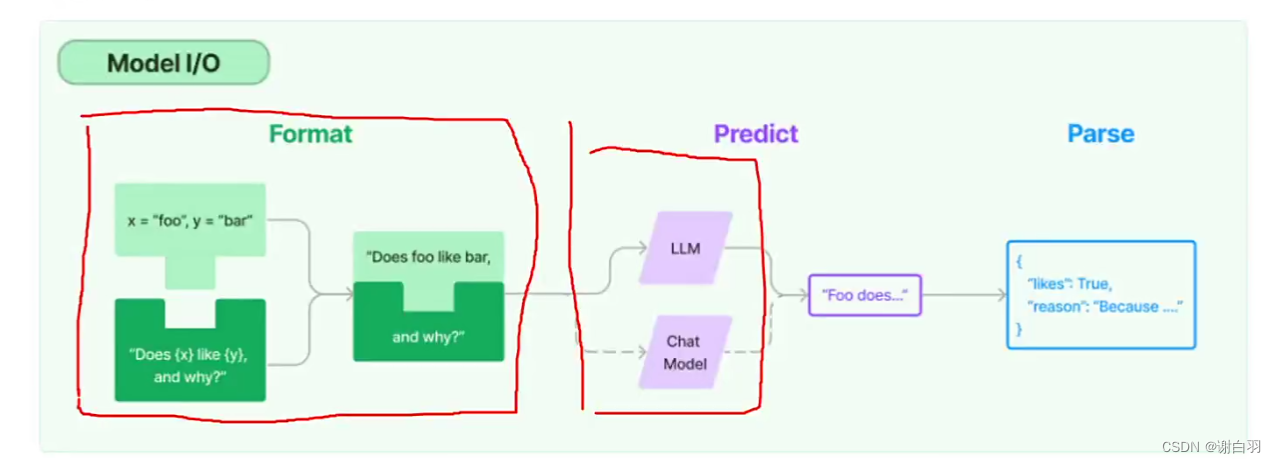
2)I/O模块(Prompts、Language models、Output parsers)
①Prompts:主要管理/协助构送入model的输入

②Language models:用哪种model
1)LLM:普通的model(大语言模型)
from langchain.llms import OpenAI
llm = OpenAI() #默认是text-davinci-003 模型
print(llm.predict("Hello, "))
2)chat_models:对话式model
from langchain.chat_models import ChatOpenAI
chat_model = ChatOpenAI() #默认是gpt-3.5-turbo
print(chat_model.predict("Hello, "))
③Output parsers:解析输出结果
3)数据链接模块(Data connection)
- 整体流程图
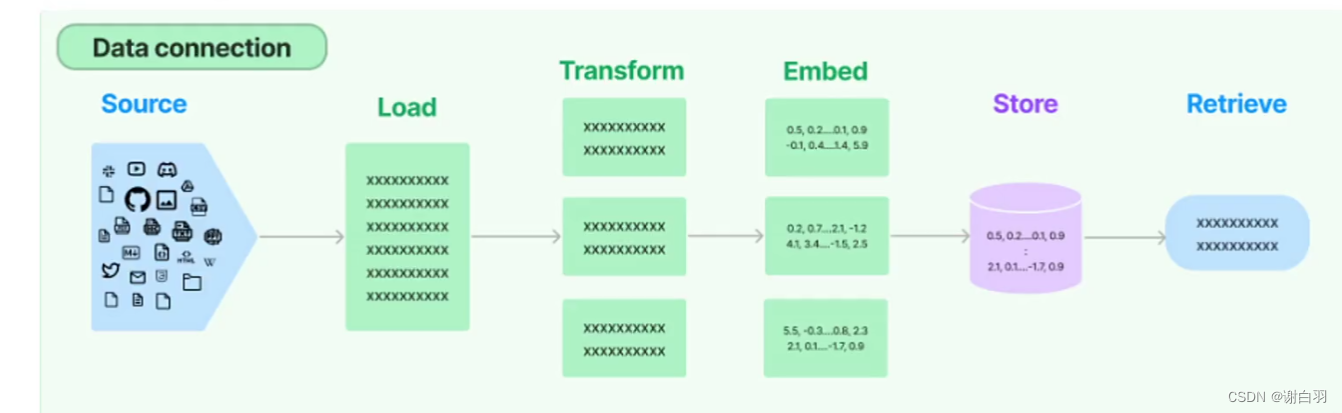
- 流程解释
①source:数据源
②load:加载器
这里介绍一个文件加载器 Document loaders,能加载CSV\HTML\JASON\Markdown\PDF
from langchain.document_loaders import PyPDFLoader
loader = PyPDFLoader(""WhatisChatGPT.pdf")
pages = loader.load_and_split()print(pages[0].page_content)
③Transfrom (数据转换,也就是对数据的预处理)
1)splitters:将数据按照要求切开成数据块,如按text,按character
2)translate:将数据翻译
translator = DoctraTextTranslator(openai_api_model = "gpt-3.5-turbo",language="chinese") # 定义translate
translated_document = await translator.atransform_documents(pages) # 使用translate
print(translated_document[0],page_content)
④embed操作
这里的translate就是将人类语言的数据转成模型认识的特征(feature)(所谓特征:在数学上就是一组张量,也就是一组数字)
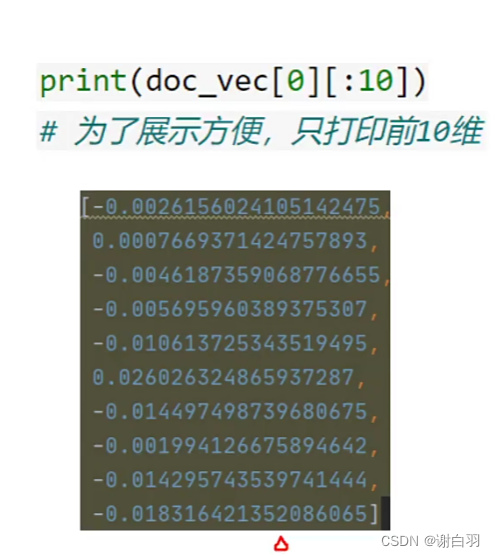

⑤store储存和retirve
看哪个数据最合适,比对之后从store的地方拿出来
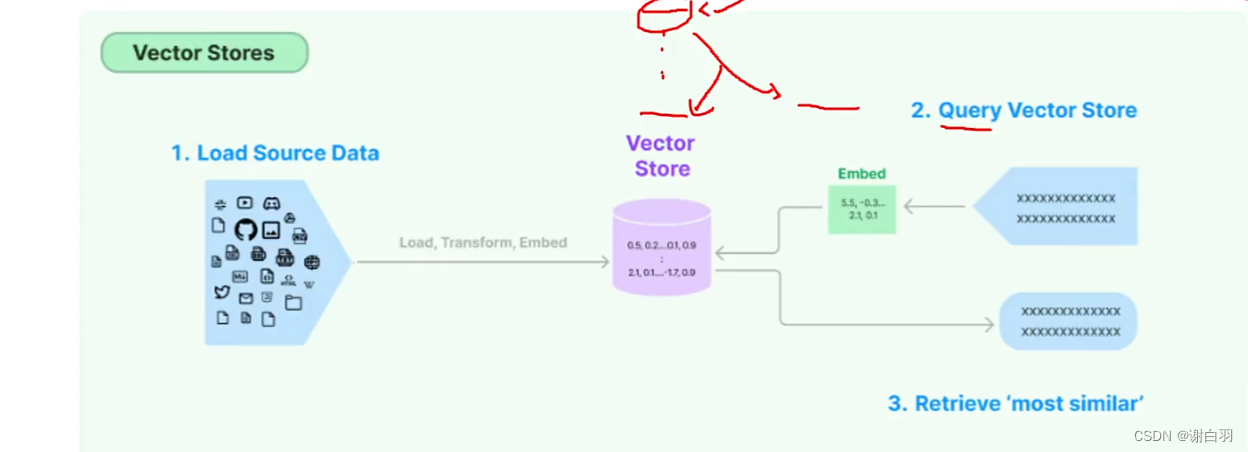
- 向量和向量之间如何比对?
1)常用的方式:余弦举例(看向量之间的夹角越小越进)
2)最直接:欧式距离(看坐标点距离)

# 1)存储
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.vectorstores import FAISS# 2)embedding
embeddings = OpenAIEmbeddings()
db = FAISS.from_documents(paragraphs,embeddings)# 3)比对
query = "What can ChatGPT do?"
docs = db.similarity_search(query)
print(docs[0].page_content)
4)记忆模块(针对多轮对话强相关,这种大模型有个特点:都是话痨)
①基本原理构造
从之前的提问数据写回去,再提问的时候丢给Prompt(这里回答的内容是你也好啊和你又好啊)
from langchain.memory import ConversationBufferMemoryhistory = ConversationBufferMemory()
history.save_context({"input":"你好啊"},{"output":"你也好啊"}) #保存字符串
# 打印保存的字符串
print(history.load_memory_variables({}))history.save_context({"input":"你再好啊"},{"output":"你又也好啊"}) #保存字符串
# 打印保存的字符串
print(history.load_memory_variables({}))

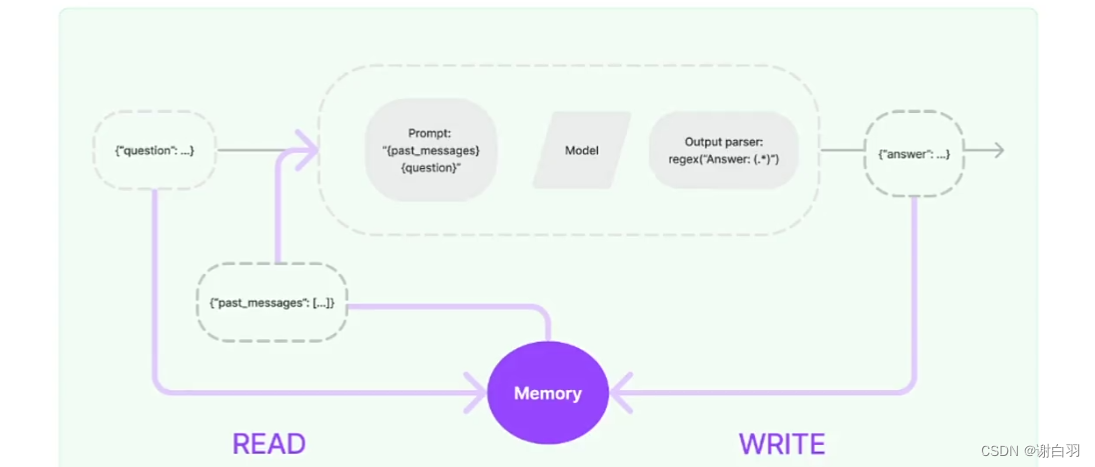
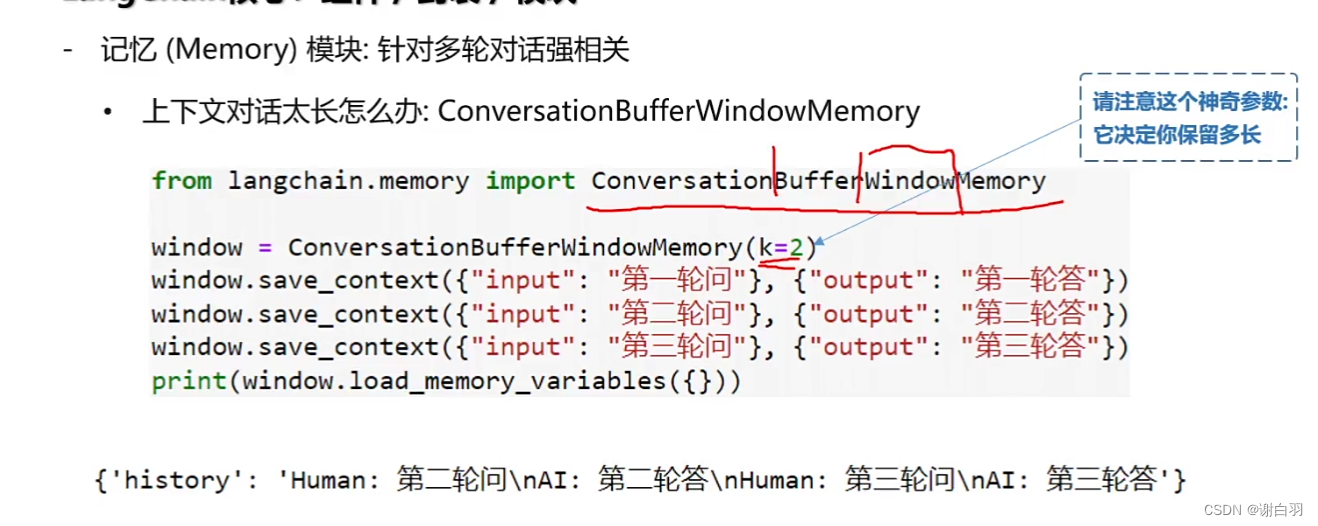
②如果上下文太长怎么办?(给定特定参数)
from langchain.memory import ConversationBufferWindowMemorywindow = ConversationBufferWindowMemory(k=2) #k值参数决定保留多长参数
window.save_context()
③或是自动对历史信息取最摘要(ConversationSummaryMemory)
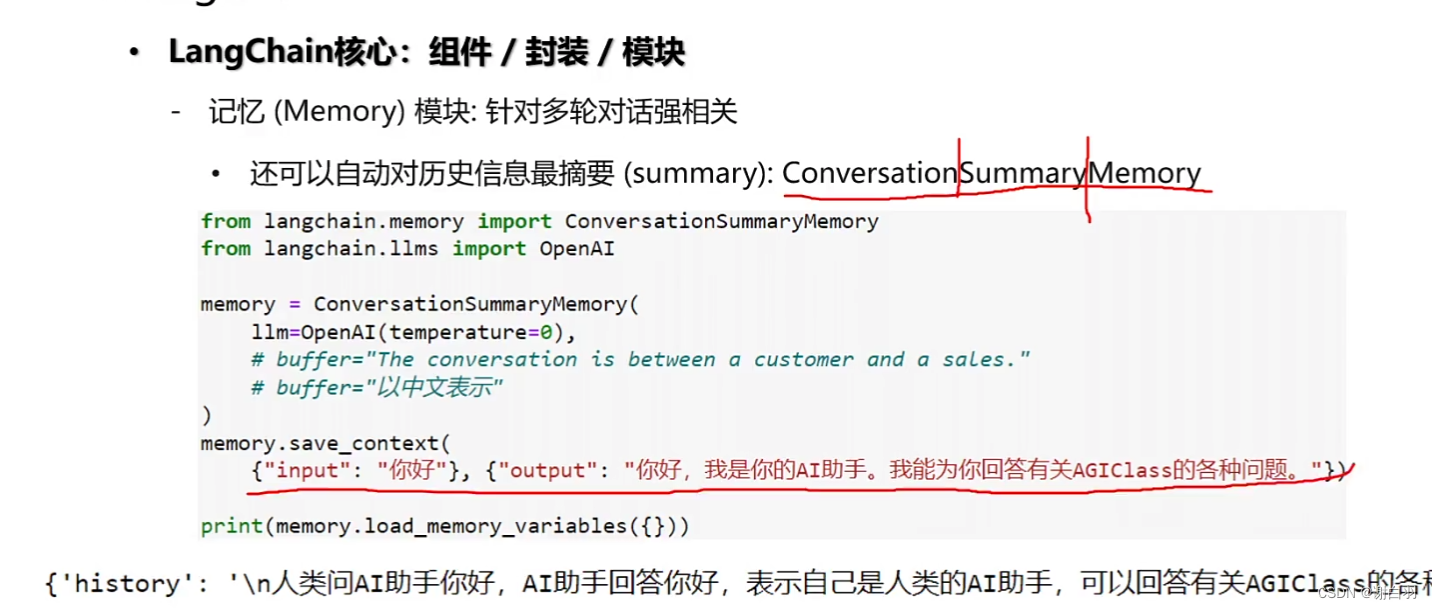
三、Fine-tuning(如果在自己领域中改变大模型)
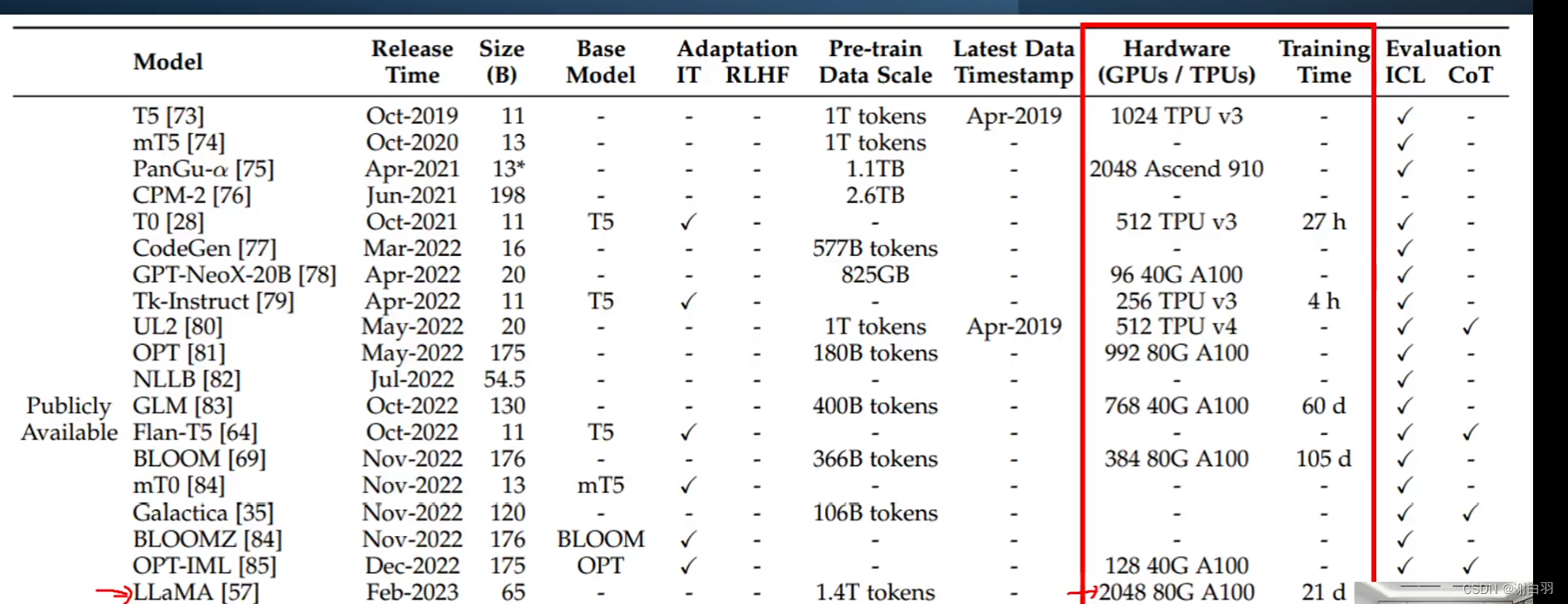
- 训练成本
可以看到LLaMA这个模型,训练一轮需要21天,没个几百万不行,包括存储数据的成本
1)from scratch:从头训练
2)finetune:微调/接着别人的训练
(1)全参数 fine tune
- 备注
全部参数都参与调试
(2)小参数fine tune
- 备注
小部分参数加入调试 - 举例
①Adapter
②prompt tuning
③LoRA
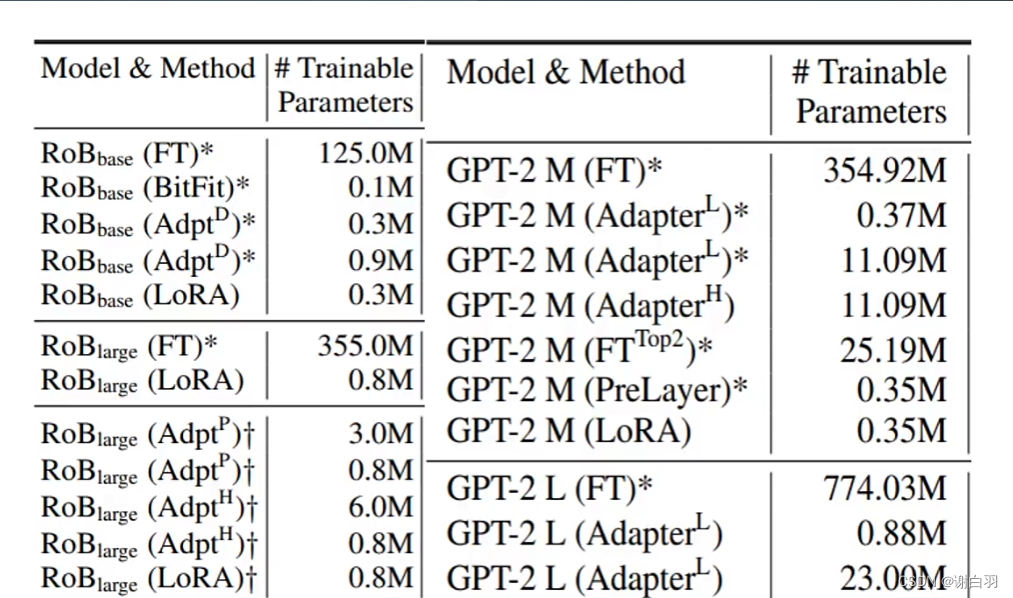
(3)小参数的LoRA原理解析:
原始模型量:R(dxd),比如 4096x406,这个是LLaMA的真实参数量(神经网络的d乘d阶乘)
Efficient模型量:R(dxr),比如 r=8,这个是真实实验数值
-
代码库

-
代码

-
参数解释

(4)训练大模型
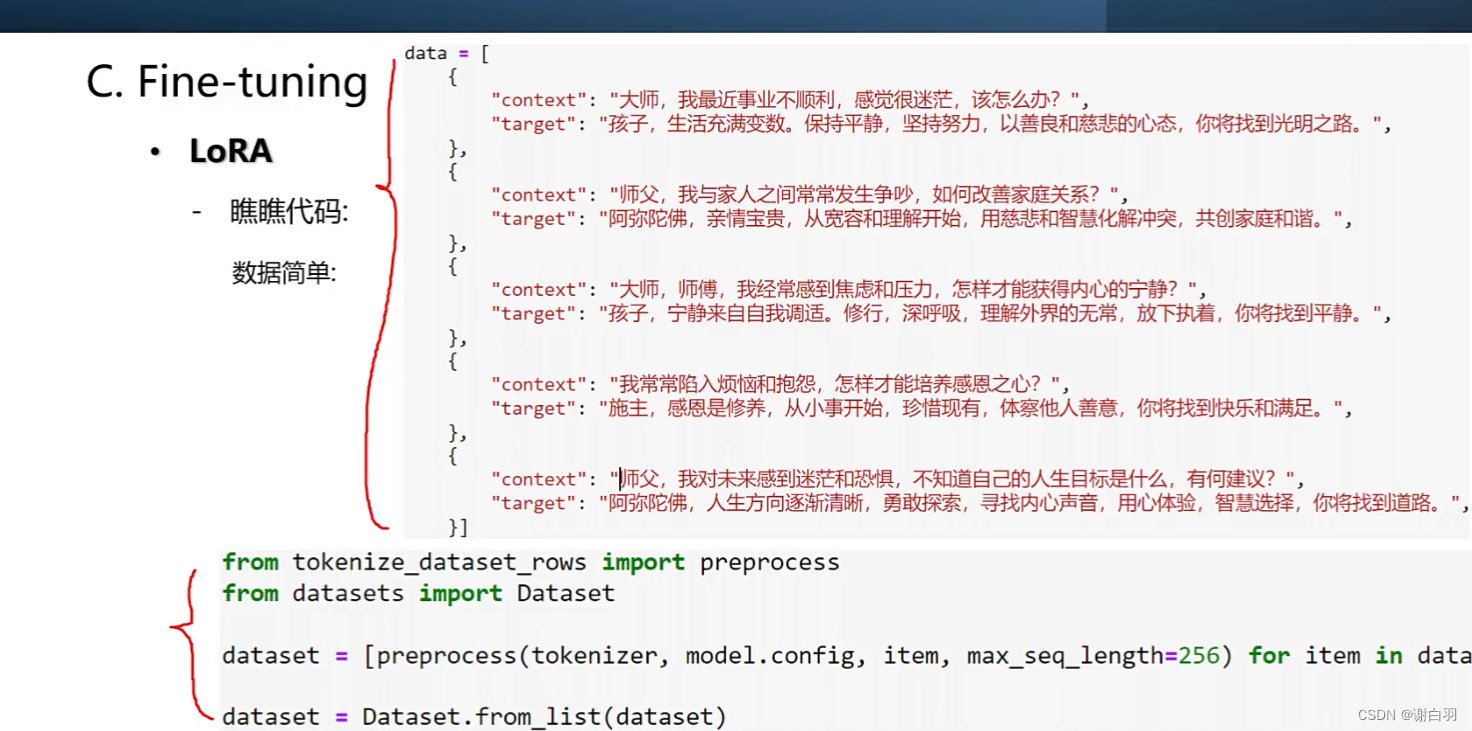
创建训练器trainer

- 提供训练数据
①context:我说了啥
②target:我期待模型返回给我什么

![[足式机器人]Part2 Dr. CAN学习笔记-Advanced控制理论 Ch04-17 串讲](https://img-blog.csdnimg.cn/direct/d133933db11248f5a59dae0d309219fa.png#pic_center)



![[自动驾驶算法][从0开始轨迹预测]:二、自动驾驶系统中常用的坐标系及相应的转换关系](https://img-blog.csdnimg.cn/direct/8f775186530c4a2891335c73f900dada.png#pic_center)