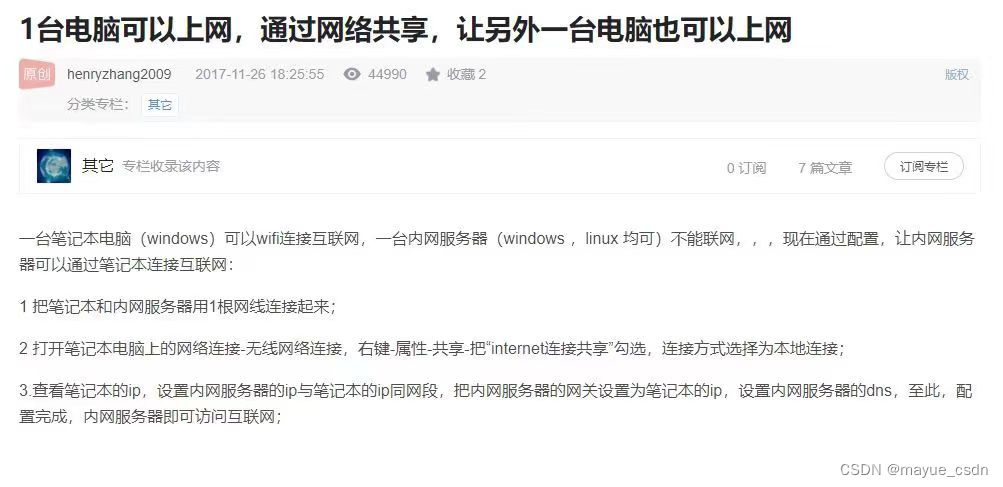
A Survey of Large Language Model
- Abstract
- INTRODUCTION
- OVERVIEW
- 背景
- LLM的新兴能力
- LLM的关键技术
- GPT 系列模型的技术演进
- 大语言模型资源
- 公开可用的模型检查点或 API
- 常用语料库
- 代码库资源
- 预训练
- 数据收集
- 架构
论文标题:A Survey of Large Language Model
论文地址:https://arxiv.org/abs/2303.18223
github:https://github.com/RUCAIBox/LLMSurvey
中文版本:https://github.com/RUCAIBox/LLMSurvey/blob/main/assets/LLM_Survey_Chinese.pdf
Abstract
自20世纪50年代图灵测试提出以来,人类就开始探索机器掌握语言智能。语言本质上是一个受语法规则控制的复杂的人类表达系统。开发强大的人工智能 (AI) 算法来理解和掌握语言提出了重大挑战。作为一种主要方法,语言建模在过去二十年中被广泛研究用于语言理解和生成,从统计语言模型发展到神经语言模型。最近,通过在大规模语料库上预训练 Transformer 模型提出了预训练语言模型(PLM),在解决各种自然语言处理(NLP)任务方面表现出了强大的能力。由于研究人员发现模型缩放可以带来性能提升,因此他们通过将模型大小增加到更大来进一步研究缩放效果。有趣的是,当参数规模超过一定水平时,这些扩大的语言模型不仅实现了显着的性能提升,而且还表现出了一些小规模语言模型(例如 BERT)中不存在的特殊能力(例如上下文学习) 。
为了区分参数规模的差异,研究界为规模较大(例如包含数百或数千亿个参数)的 PLM 创建了术语“大型语言模型”(LLM)。近年来,学术界和工业界对LLMs的研究取得了很大进展,其中一个显着进展是ChatGPT(基于LLMs开发的强大AI聊天机器人)的推出,引起了社会的广泛关注。 LLMs的技术演变对整个人工智能社区产生了重要影响,这将彻底改变我们开发和使用人工智能算法的方式。考虑到这种快速的技术进步,在本次调查中,我们通过介绍背景、主要发现和主流技术来回顾LLMs的最新进展。我们特别关注LLMs的四个主要方面,即预训练、适应调优、利用和容量评估。此外,我们还总结了开发LLMs的可用资源,并讨论了未来方向的剩余问题。这项调查提供了有关LLMs文献的最新综述,这对研究人员和工程师来说都是有用的资源。
INTRODUCTION
语言是人类表达和交流的一种重要能力,在幼儿期发展并在一生中不断发展[1, 2]。而对于机器来说,除非配备强大的人工智能(AI)算法,否则它们无法自然地掌握以人类语言形式进行理解和交流的能力。为了实现这一目标,使机器能够像人类一样阅读、写作和交流一直是一项长期的研究挑战[3]。从技术上讲,语言建模(LM)是提高机器语言智能的主要方法之一。一般来说,LM 的目标是对单词序列的生成可能性进行建模,从而预测未来(或缺失)标记的概率。 LM的研究受到文献的广泛研究关注,大致可分为四个主要发展阶段:
- 统计语言模型(Statistical language models SLM): SLM [4-7] 是基于 20 世纪 90 年代兴起的统计学习方法开发的。基本思想是基于马尔可夫假设构建单词预测模型,例如根据最近的上下文预测下一个单词。具有固定上下文长度 n 的 SLM 也称为 n-gram 语言模型,例如二元模型和三元模型。 SLM 已被广泛应用于提高信息检索 (IR) [8, 9] 和自然语言中的任务处理(NLP)[10–12]。然而,它们经常遭受维数灾难:由于需要估计指数数量的转移概率,因此很难准确估计高阶语言模型。因此,引入了专门设计的平滑策略,例如退避估计[13]和Good-Turing估计[14]来缓解数据稀疏问题。
- 神经语言模型(Neural language models NLM):NLM [15-17] 通过神经网络(例如循环神经网络(RNN))来表征单词序列的概率。作为一个显着的贡献,[15]中的工作引入了单词的分布式表示的概念,并通过聚合相关的分布式单词向量来建模上下文表示。通过扩展学习单词或句子的有效特征的思想,开发了一种通用的神经网络方法来为各种 NLP 任务构建统一的解决方案 [18]。此外,word2vec [19, 20] 被提议构建一个简化的浅层神经网络来学习分布式单词表示,这被证明在各种 NLP 任务中非常有效。这些研究开创了使用语言模型进行表征学习(超越词序列建模),对 NLP 领域产生了重要影响。
- 预训练语言模型(Pre-trained language models PLM):作为早期的尝试,ELMo [21] 被提出通过首先预训练双向 LSTM (biLSTM) 网络(而不是学习固定的单词表示)并微调 biLSTM 网络来捕获上下文感知的单词表示。根据具体的下游任务。此外,基于具有自注意力机制的高度并行化的Transformer架构[22],通过在大规模未标记语料库上使用专门设计的预训练任务来预训练双向语言模型,提出了BERT[23]。这些预先训练的上下文感知单词表示作为通用语义特征非常有效,这在很大程度上提高了 NLP 任务的性能标准。这项工作启发了大量的后续工作,它设定了“预训练和微调”的学习范式。遵循这一范式,已经开展了大量关于 PLM 的研究,引入了不同的架构 [24, 25](例如 GPT-2 [26] 和 BART [24])或改进的预训练策略 [27-29] 。在此范例中,通常需要微调 PLM 以适应不同的下游任务。
- 大型语言模型( Large language models LLM):研究人员发现,扩展 PLM(例如扩展模型大小或数据大小)通常会提高下游任务的模型能力(即遵循扩展定律 [30])。许多研究通过训练更大的 PLM(例如 175B 参数 GPT-3 和 540B 参数 PaLM)来探索性能极限。尽管缩放主要在模型大小上进行(具有相似的架构和预训练任务),但这些大型 PLM 显示出与小型 PLM(例如 330M 参数 BERT 和 1.5B 参数 GPT-2)不同的行为,并显示出令人惊讶的能力(称为解决一系列复杂任务的新兴能力[31])。例如,GPT-3 可以通过上下文学习解决小样本任务,而 GPT-2 则不能做得很好。因此,研究界为这些大型 PLM 创造了术语“大型语言模型 (LLM)”1 [32-35]。 LLM 的一个显着应用是 ChatGPT2,它改编了 GPT 系列的 LLM 进行对话,呈现出惊人的与人类对话的能力。
在现有文献中,PLM 已被广泛讨论和调查[36-39],而 LLM 却很少得到系统的综述。为了激发我们的调查兴趣,我们首先强调 LLM 和 PLM 之间的三个主要区别。
- 首先,LLM展示了一些令人惊讶的新兴能力,这些能力在以前的小型 PLM 中可能无法观察到。这些能力是语言模型在复杂任务上表现的关键,使人工智能算法变得前所未有的强大和有效。
- 其次,LLM彻底改变了人类开发和使用人工智能算法的方式。与小型 PLM 不同,访问 LLM 的主要方法是通过提示界面(例如 GPT-4 API)。人们必须了解LLM如何工作,并以LLM可以遵循的方式安排他们的任务。
- 第三,LLM的发展不再明确区分研究和工程。LLM的培养需要丰富的大规模数据处理和分布式并行训练的实践经验。为了培养有能力的LLM,研究人员必须解决复杂的工程问题,与工程师合作或成为工程师。
尽管取得了进展和影响,LLM的基本原则仍然没有得到很好的探索。
- 首先,为什么新兴能力出现在 LLM 中,而不是较小的 PLM 中,这仍然是个谜。作为一个更普遍的问题,目前仍然缺乏对影响LLM能力的关键因素进行深入、细致的调查。研究LLM何时以及如何获得这种能力非常重要[47]。尽管关于这个问题有一些有意义的讨论 [31, 47],但需要进行更有原则的调查来揭开LLM的“秘密”。
- 其次,为研究界培养有能力的LLM很困难。由于模型预训练成本巨大,研究界很难进行重复性、消融性的研究。事实上,LLM主要由行业培训,许多重要的培训细节(例如数据收集和清理)并未向公众透露。
- 第三,让LLM与人类价值观或偏好保持一致非常具有挑战性。尽管有能力,LLM也可能产生有毒、虚构或有害的内容。它需要有效且高效的控制方法来消除使用LLM的潜在风险[46]。
机遇与挑战并存,LLM的研究与发展需要更多的关注。为了让大家对LLM有一个基本的了解,本次调查从预训练(如何预训练一个有能力的LLM)、适应调优(如何有效地调优预训练)四个主要方面对LLM的最新进展进行了文献综述。从有效性和安全性)、利用性(如何利用LLM解决各种下游任务)和能力评估(如何评估LLM的能力和现有的实证结果)两个角度来训练LLM。我们彻底梳理文献并总结LLM的主要发现、技术和方法。对于本次调查,我们还通过收集LLM的支持资源创建了一个 GitHub 项目网站。
我们还知道一些关于 PLM 或 LLM 的相关评论文章 [32,36,38,39,43,48–54]。这些论文要么讨论 PLM,要么讨论 LLM 的一些特定(或一般)方面。与它们相比,我们重点关注开发和使用LLM的技术和方法,对LLM的重要方面提供了相对全面的参考。
OVERVIEW
在本节中,我们介绍了LLM的背景以及关键术语、能力和技术。
背景
通常,大型语言模型(LLM)是指包含数千亿(或更多)参数5的语言模型,这些模型是在海量文本数据上训练的[32],例如GPT-3 [55]、PaLM [56]、Galatica [35]和LLaMA[57]。具体来说,LLM 是建立在 Transformer 架构 [22] 的基础上的,其中多头注意力层堆叠在一个非常深的神经网络中。现有的LLM主要采用类似的模型架构(即Transformer)和预训练目标(即语言建模)作为小语言模型。主要区别是,LLM在很大程度上扩展了模型大小、预训练数据和总计算(放大数量级)。他们可以更好地理解自然语言并根据给定的上下文(即提示)生成高质量的文本。这种容量的提高可以通过缩放定律来部分描述,其中性能大致遵循模型大小的大幅增加[30]。然而,根据缩放定律,某些能力(例如上下文学习[55])是不可预测的,只有当模型大小超过一定水平时才能观察到(如下所述)。
LLM的新兴能力
在文献[31]中,LLM的涌现能力被正式定义为“小模型中不存在但在大模型中出现的能力”,这是LLM区别于以往PLM的最显着特征之一。当涌现能力出现时,它还引入了一个显着的特征:当规模达到一定水平时,性能显着高于随机水平。以此类推,这种涌现模式与物理学中的相变现象有着密切的联系[31, 58]。原则上,涌现能力也可以根据一些复杂的任务来定义[31, 59],而我们更关心的是可以应用于解决多个任务的一般能力。在这里,我们简要介绍一下LLM具有代表性的三种新兴能力,描述如下。
现有文献中,对于LLM的最小参数范围尚未达成正式共识。在本次调查中,我们主要集中讨论模型大小大于10B的LLM。
- In-context learning 情境学习: GPT-3[55]正式引入了上下文学习能力:假设语言模型已经提供了自然语言指令和/或多个任务演示,它可以通过完成以下任务来生成测试实例的预期输出:输入文本的单词序列,不需要额外的训练或梯度更新6。
- Instruction following 遵循指示: 通过对通过自然语言描述(即指令)格式化的多任务数据集的混合进行微调,LLM 在以指令形式描述的看不见的任务上表现良好 [28,61,62]。有了这种能力,指令调优使得LLM能够通过理解任务指令来执行新的任务,而不需要使用显式的例子,这可以很大程度上提高泛化能力。
- Step-by-step reasoning逐步推理: 对于小型语言模型,通常很难解决涉及多个推理步骤的复杂任务,例如数学文字问题。而通过思想链推理策略[33],LLM可以利用涉及中间推理步骤来得出最终答案的提示机制来解决此类任务。据推测,这种能力可能是通过代码训练获得的 [33, 47]。
LLM的关键技术
LLM经历了很长的路才发展成为目前的状态:一般和有能力的学习者。在开发过程中,提出了许多重要技术,极大地提高了LLM的能力。在这里,我们简要列出了(可能)导致LLM成功的几种重要技术,如下所示:
- Scaling扩展:扩展是提高LLM模型能力的关键因素。作为初步尝试,GPT-3首先将模型规模增加到175B参数的极大规模。随后,PaLM进一步将参数规模提升至540B的新纪录。如前所述,大模型尺寸对于新兴能力至关重要。同时,缩放不仅与模型大小有关,还与数据大小和总计算有关[34, 63]。最近的一项研究[34]讨论了在给定固定预算的情况下模型大小、数据大小和总计算三个方面的最佳调度。此外,预训练数据的质量对于实现良好的性能起着关键作用,因此在扩展预训练语料库时,数据收集和清理策略非常重要。
- Training 训练:由于模型规模庞大,成功培养一名有能力的LLM非常具有挑战性。需要分布式训练算法来学习LLM的网络参数,其中常常联合使用各种并行策略。为了支持分布式训练,已经发布了多个优化框架来促进并行算法的实现和部署,例如 DeepSpeed [64] 和 Megatron-LM [65]。此外,优化技巧对于训练稳定性和模型性能也很重要,例如,用训练损失尖峰重新启动[56]和混合精度训练[66]。GPT-4 [46] 提出开发特殊的基础结构和优化方法,用更小的模型来可靠地预测大模型性能。
- Ability eliciting能力引导:在大规模语料库上预训练之后,LLM 具备了作为通用任务求解器的潜在能力。然而,当 LLM 执行一些特定任务时,这些能力可能不会显式地展示出来。作为技术手段,设计合适的任务指令或具体的 ICL 策略可以激发这些能力。例如,通过包含中间推理步骤,CoT 提示已被证明对解决复杂的推理任务有效。此外,我们还可以使用自然语言表达的任务描述对 LLM 进行指令微调,以提高 LLM 在未见任务上的泛化能力。然而,这些技术主要对应于 LLM 的涌现
能力,可能对小语言模型的效果不同。
• Alignment tuning对齐微调:由于 LLM 被训练用来捕捉预训练语料库的数据特征(包括高质量和低质量的数据),它们可能会为人类生成有毒、偏见甚至有害的内容。因此,有必要使 LLM 与人类价值观保持一致,例如有用性、诚实性和无害性。为此,
InstructGPT [61] 设计了一种有效的微调方法,使 LLM 能够按照期望的指令进行操作,其中利用了基于人类反馈的强化学习技术 [61, 70]。它将人类纳入训练循环中,采用精心设计的标注策略。ChatGPT 实际上采用类似于 InstructGPT 的技术,在产生高质量、无害的回答(例如拒绝回答侮辱性问题)方面表现出很强的对齐能力。
• Tools manipulation工具操作:从本质上讲,LLM 是基于海量纯文本语料库进行文本生成训练的,因此在那些不适合以文本形式表达的任务上表现不佳(例如数字计算)。此外,它们的能力也受限于预训练数据,例如无法获取最新信息。为了解决这些问题,最近提出了一种技术,即利用外部工具来弥补 LLM 的不足 [71, 72]。例如,LLM 可以利用计算器进行准确计算 [71],利用搜索引擎检索未知信息 [72]。最近,ChatGPT 已经实现了使用外部插件(现有或新创建的应用程序)的机制,这类似于 LLM 的“眼睛和耳朵”。这种机制可以广泛扩展 LLM 的能力范围。
此外,许多其他因素(例如硬件升级)也对 LLM 的成功做出了贡献。但是,我们主要讨论在开发 LLM 方面的主要技术方法和关键发现。
已发现中文版本,因此不再一一翻译 [中文版本],github上不去的话可在本用户下载资源中此处下载
GPT 系列模型的技术演进
OpenAI 对 LLM 的研究可以大致分为以下几个阶段:
- 早期探索:根据对 Ilya Sutskever(OpenAI 联合创始人兼首席科学家)的一次采访11,在 OpenAI 的早期,已经探索了使用语言模型来实现智能系统的想法,但当时是尝试使用循环神经网络(RNN)[73]。随着 Transformer 的出现,OpenAI开发了两个初始的 GPT 模型,即 GPT-1[74] 和 GPT-2[26],它们可以看作是后来更强大模型(如 GPT-3 和 GPT-4)的基础。
- GPT-1:2017 年,Google 引入了 Transformer 模型 [22],OpenAI 团队迅速使用这种新的神经网络架构进行语言建模工作。他们在 2018 年发布了第一个 GPT 模型,即 GPT-1[74],并将 GPT 作为模型名称的缩写,代表生成式预训练
(Generative Pre-Training)。GPT-1 是基于生成型的、仅解码器的Transformer 架构开发的,并采用了无监督预训练和有监督微调的混合方法。GPT-1 为 GPT 系列模型建立了核心架构,并确立了对自然语言文本进行建模基本原则,即预测下一个单词。 - GPT-2:GPT-2[26] 采用了与 GPT-1 类似的架构,将参数规模增加到了 15 亿,并使用大规模的网页数据集 WebText进行训练。正如 GPT-2 的论文所述,它旨在通过无监督语言建模来执行任务,而无需使用标记数据进行显式微调。为了推动这种方法,他们引入了多任务求解的概率形式,即(output|input, task)(类似的方法已在 [75] 中采用),它在给定输入和任务信息的条件下预测输出。为了对该条件概率建模,自然语言文本可以自然地用作为格式化输入、输出和任务信息的统一方式。通过这种方式,解决任务的过程可以被视为生成解决方案文本的单词预测问题。
- GPT-3: GPT-3 [55] 于 2020 年发布,将模型参数扩展 到了更大的规模,达到了 1750 亿。GPT-3 的论文正式介绍了 ICL 的概念,它是以小样本或零样本的方式使用 LLM。ICL 可以指导 LLM 理解以自然语言文本的形式给出的任务。LLM 的预训练和使用在 ICL 下有着相同的语言建模范式:预训练预测给定上下文条件下的后续文本序列,而 ICL 预测正确的任务解决方案,该解决方案可以被格式化为给定任务描述和示范下的文本序列。总体而言,GPT-3 可以被视为从 PLM 到 LLM 进化过程中的一个重要里程碑。它通过实证证明,将神经网络扩展到大的规模可以大幅增加模型的能力。
ICL代表的是"Information Maximization and Contrastive Learning",即信息最大化和对比学习。尽管在GPT-2的论文中没有明确提及ICL这个术语,但是ICL的概念在GPT-2的无监督任务学习中起到了重要的作用。
信息最大化是指通过最大化模型对输入数据的预测能力来学习数据的有用表示。在GPT-2中,模型通过从上下文中预测下一个单词或一段文本的方式来学习语言的表示。这样的预测任务迫使模型学习捕捉句子中的上下文依赖关系和语义信息。
对比学习是指通过将正样本与负样本进行对比,使得模型能够更好地区分它们之间的差异。在GPT-2中,对比学习通过在预测任务中引入掩码机制(masking)来实现。模型被要求根据上下文来预测被掩盖的单词,这样可以使模型更好地理解上下文信息,同时学习到单词之间的关联性。
能力增强:由于其强大的能力,GPT-3 已经成为 OpenAI 开发更强大 LLM 的基础模型。总体而言,OpenAI 探索了两种主要方法来进一步改进 GPT-3 模型,即使用代码数据进行训练以及与人类偏好的对齐。
- 使用代码数据进行训练:原始的 GPT-3模型(在纯文本上进行预训练)的一个主要限制在于缺乏复杂任务的推理能力,例如完成代码和解决数学问题。实际上,GPT-3.5 模型是在基于代码的 GPT模型(code-davinci-002)的基础上开发的,这表明使用代码数据进行训练是改善 GPT模型能力(尤其是推理能力)的一种非常有用的实践。此外,还有一种猜测称使用代码数据进行训练可以极大地增加 LLM 的CoT 提示能力 [46],尽管这仍然需要更全面的验证。
- 与人类对齐: 近端策略优化 (Proximal PolicyOptimization, PPO) 的论文在 2017 年 7 月发表 [81],现在已经成为从人类偏好中学习的基础 RL 算法 [61]。InstructGPT[61] 在 2022 年 1月提出,以改进 GPT-3 模型的与人类对齐能力,正式建立了一个三阶段的基于人类反馈的强化学习(RLHF)算法。除了提高指令遵循能力之外,RLHF 算法对于缓解有害或有毒内容的生成问题十分有效,这对于 LLM 在实践中的安全部署至关重要。OpenAI 在一篇技术文章中描述了他们在对齐研究中的方法 [83],总结了三个有前途的方向:“训练 AI 系统使用人类反馈,协助人类评估以及做对齐研究”。
语言模型的重要里程碑:基于所有的探索工作,OpenAI 取得了两个重要的里程碑:ChatGPT [84] 和 GPT-4 [45]
- ChatGPT:在 2022 年 11 月,OpenAI 发布了对话语言模型 ChatGPT,它是基于 GPT 模型(GPT-3.5 和 GPT-4)开发。正如官方博文所述 [84],ChatGPT 是以类似 InstructGPT的方式进行训练的(在原始文章中称为“InstructGPT 的姊妹模型”),但专门针对对话能力进行了优化。在 ChatGPT和 InstructGPT 的数据收集上,他们指出了一个不同之处:ChatGPT 训练数据是通过将人类生成的对话(扮演用户和AI 两个角色)与 InstructGPT 数据集结合起来以对话形式生成。ChatGPT 在与人类的交流中表现出卓越的能力:拥有丰富的知识库,擅长解决数学问题,准确追踪多轮对话中的上下文,并与人类的价值观保持一致以确保被安全使用。随后,ChatGPT 支持了插件机制,进一步通过已有工具或应用扩展了 ChatGPT 的功能。到目前为止,它是 AI 历史上最强大的聊天机器人。ChatGPT 的发布对未来的 AI 研究产生了重大影响,为探索类似人类的 AI 系统提供了新的方向。
- GPT-4:作为另一重要的进展,GPT-4 [45] 于 2023 年3 月发布,将文本输入扩展到多模态信号。由于经过为期六个月的迭代对齐(在 RLHF 训练中加入了额外的安全奖励信号),GPT-4 对于具有恶意或挑衅的提问的响应更加安全。在技术报告中,OpenAI 强调了如何安全开发 GPT-4,并采用了多种干预策略来减轻语言模型的可能问题,如幻觉、隐私和过度依赖。例如,他们引入了一种称为红队评估(redteaming)的机制 [85] 来减少有害或生成有毒内容的可能性。作为另一个重要方面,GPT-4 是在成熟的深度学习基础上开发的,采用了改进的优化方法。他们引入了一种称为可预测扩展(predictable scaling)的新机制,可以使用模型训练期间一小部分的计算量来准确预测最终性能。

大语言模型资源
此处链接众多,建议参看原文
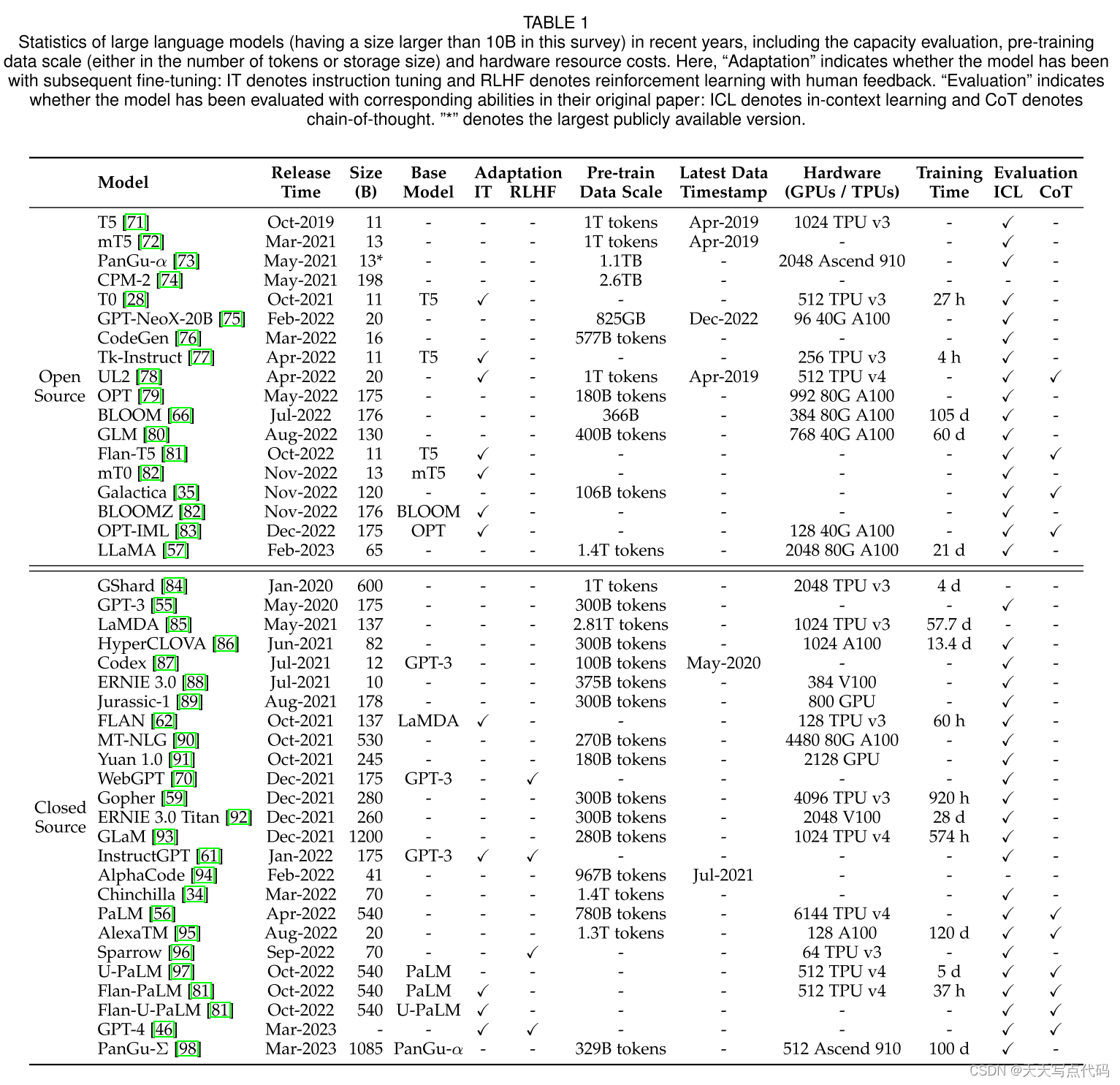
考虑到技术问题的挑战和计算资源的巨大需求,开发或复现LLM 绝非易事。一种可行的方法是在现有的 LLM 的基础上进行开发,即重复使用公开可用的资源进行增量开发或实验研究。在本节中,我们简要整理了用于开发 LLM 的公开可用的资源,包括公开的模型检查点(或 API)、语料库和代码库。3.1 公开可用的模型检查点或 API考虑到模型预训练的巨大成本,训练良好的模型检查点对于研究组织开展 LLM 的研究和开发至关重要。由于参数规模是使用 LLM 时需要考虑的关键因素,为了帮助用户根据其资源预算确定适当的研究内容,我们将这些公开模型分为两个规模级别(百亿参数量级别和千亿参数量级别)。此外,也可以直接使用公开的 API 执行推理任务,而无需在本地运行模型。接下来,我们对公开可用的模型检查点和 API 进行介绍。
公开可用的模型检查点或 API
- 百亿参数量级别的模型:这类模型的参数规模除了 LLaMA(最大版本 650 亿参数)和 NLLB(最大版本 545 亿参数),大多在 100 亿至 200 亿之间。这一参数范围内的模型包括 mT5 [88]、PanGu-α [89]、T0 [28]、GPT-NeoX-20B [92]、CodeGen [91]、UL2 [94]、Flan-T5 [64] 和 mT0 [98] 等。作为最近发布的模型,LLaMA(65B)[57] 在与指令遵循相关的任务中展现了卓越的性能。
- 千亿参数量级别的模型:在这类模型中,只有少数几个模型进行了公开发布。其中,OPT [95]、OPT-IML [99]、BLOOM [69]和 BLOOMZ [98] 的参数量几乎与 GPT-3(175B)大致相同,而 GLM [97] 和 Galactica [34] 的参数数量分别为 1300 亿和1200 亿。
- 大语言模型的公共 API:相较于直接使用模型副本,API提供了一种更方便的方式供普通用户使用 LLM,使得用户无需在本地运行模型。作为使用 LLM 的代表性接口,GPT 系列模型的 API [45, 55, 61, 78] 已经广泛应用于学术界和工业界16。OpenAI 提供了七个主要的 GPT-3 系列模型接口:ada、babbage、curie、davinci(GPT-3 系列中最强大的版本)、text-ada-001、text-babbage-001 和text-curie-001。
常用语料库
与早期的小型 PLM 不同,LLM 有着规模极大的参数量,需要更大量且内容广泛的训练数据。为满足这种需求,越来越多的可用于研究的训练数据集被发布到公共社区中。在本节,我们将简要总结一些常用于训练 LLM 的语料库。基于它们的内容类型,我们将这些语料库分为六个组别进行介绍:Books、CommonCrawl、Reddit Links、Wikipedia、Code、Others。
- Books: BookCorpus [122] 是之前小规模模型(如 GPT [74]和 GPT-2 [26])中常用的数据集,包括超过 11,000 本电子书,涵盖广泛的主题和类型(如小说和传记)。
- CommonCrawl: CommonCrawl [132] 是最大的开源网络爬虫数据库之一,能力达到了百万亿字节级别,已经被广泛运用于训练 LLM。由于整个数据集非常大,因此现有的研究主要在特定时间段内从中提取网页子集。然而,由于网络数据中存在大量的噪音和低质量信息,因此使用前需要进行数据预处理。目前有四个较为常用的基于 CommonCrawl的过滤数据集:C4 [87],CC-Stories [124],CC-News [27],和 RealNews [125]。
- Reddit Links:Reddit 是一个社交媒体平台,用户可以在上面提交链接和帖子,其他人可以通过“赞同”或“反对”投票。高赞的帖子通常被认为对多数用户是有帮助的,可以用来创建高质量的数据集。WebText [26] 就是一个著名的基于 Reddit 的语料库,它由 Reddit 上高赞的链接组成,但尚未公开。作为替代,有一个易于获取的开源替代品叫做 OpenWebText [126]。另一个从 Reddit 中提取的语料库是 PushShift.io [127],它是一个实时更新的数据集,包括自 Reddit 创建以来的历史数据。
- Wikipedia: Wikipedia [128] 是一个在线百科全书,包含大量高质量的文章,涵盖各种主题。
- Code:为了收集代码数据,现有工作主要是从互联网上爬取有开源许可证的代码。代码数据有两个主要来源:包括开源许可证的公共代码库(例如 GitHub)和与代码相关的问答平台(例如 StackOverflow)。
- Others: The Pile [130] 是一个大规模、多样化、开源的文本数据集,有超过 800GB 数据,内容包括书籍、网站、代码、科学论文和社交媒体平台等。它由 22 个多样化的高质量子集构成。
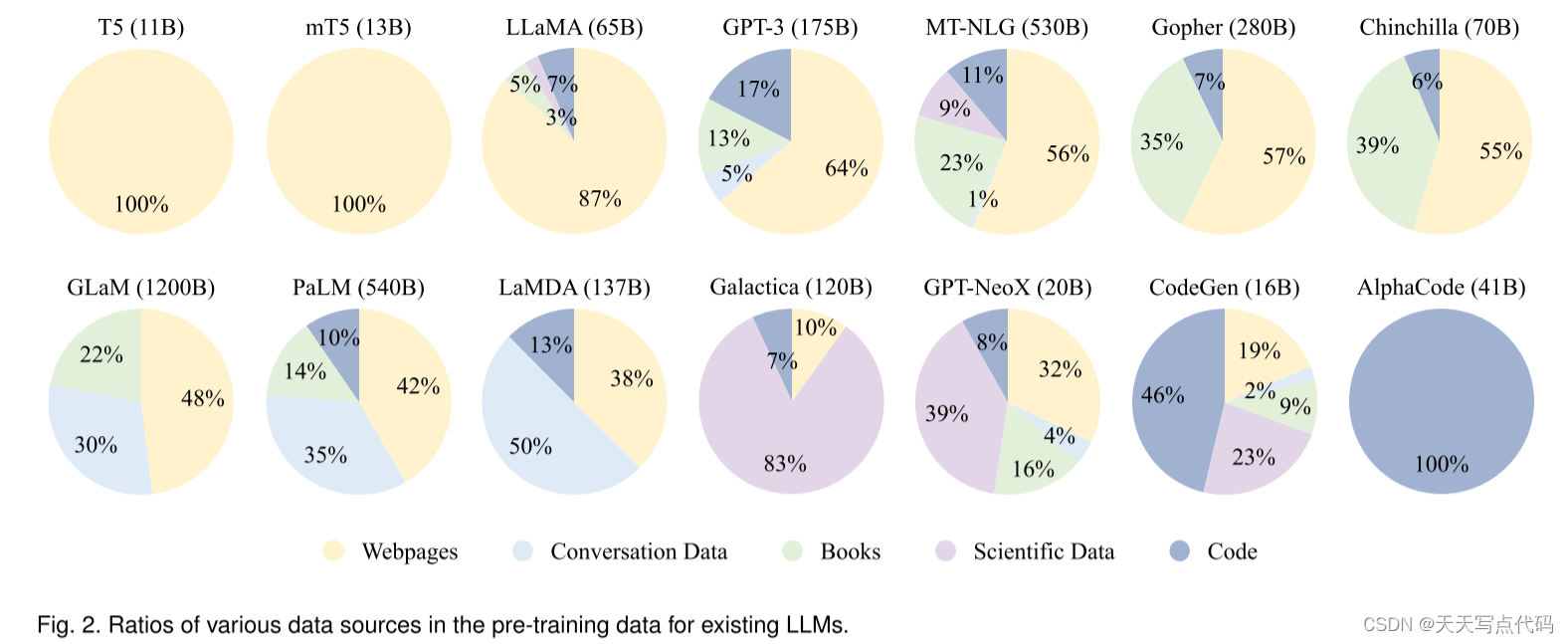
实际上,为了预训练 LLM,通常需要混合使用不同的数据源(见图 2),而不是单一的语料库。因此,现有的研究通常混合几个现成的数据集(如 C4、OpenWebText 和 the Pile等),然后进行进一步的处理以获取预训练语料库。此外,为了训练适用于特定应用的 LLM,从相关源(如 Wikipedia 和BigQuery)提取数据以丰富预训练数据中的相应信息也很重要。为了快速了解现有 LLM 使用的数据来源,我们介绍三个代表性 LLM 的预训练语料库:
- GPT-3(175B)[55] 是在混合数据集(共 3000 亿 token)上进行训练的,包括 CommonCrawl [132]、WebText2 [55]、Books1 [55]、Books2 [55] 和 Wikipedia [128]。
- PaLM(540B)[56] 使用了一个由社交媒体对话、过滤后的网页、书籍、Github、多语言维基百科和新闻组成的预训练数据集,共包含 7800 亿 token。•
- LLaMA [57] 从多个数据源中提取训练数据,包括CommonCrawl、C4 [87]、Github、Wikipedia、书籍、ArXiv和 StackExchange。LLaMA(6B)和 LLaMA(13B)的训练数据大小为 1.0 万亿 token,而 LLaMA(32B)和 LLaMA(65B)使用了 1.4 万亿 token。
代码库资源
Transformers [135] 是一个使用 Transformer 架构构建模型的开源 Python 库,由 Hugging Face 开发和维护。
DeepSpeed [65] 是由 Microsoft 开发的深度学习优化库(与 PyTorch 兼容)。
Megatron-LM [66–68] 是由 NVIDIA 开发的深度学习库,用于训练 LLM。
…
预训练
预训练为 LLM 的能力奠定了基础。通过在大规模语料库上进行预训练,LLM 可以获得基本的语言理解和生成能力 [55, 56]。在这个过程中,预训练语料库的规模和质量对于 LLM 获得强大的能力至关重要。此外,为了有效地预训练 LLM,也需要设计好模型架构、加速方法和优化技术。
数据收集
预训练语料库的来源可以广义地分为两种类型:通用文本数据和专用文本数据。
在收集大量文本数据后,对数据进行预处理,特别是消除噪声、冗余、无关和潜在有害的数据 [56, 59],对于构建预训练语料库是必不可少的,因为这些数据可能会极大地影响 LLM的能力和性能。
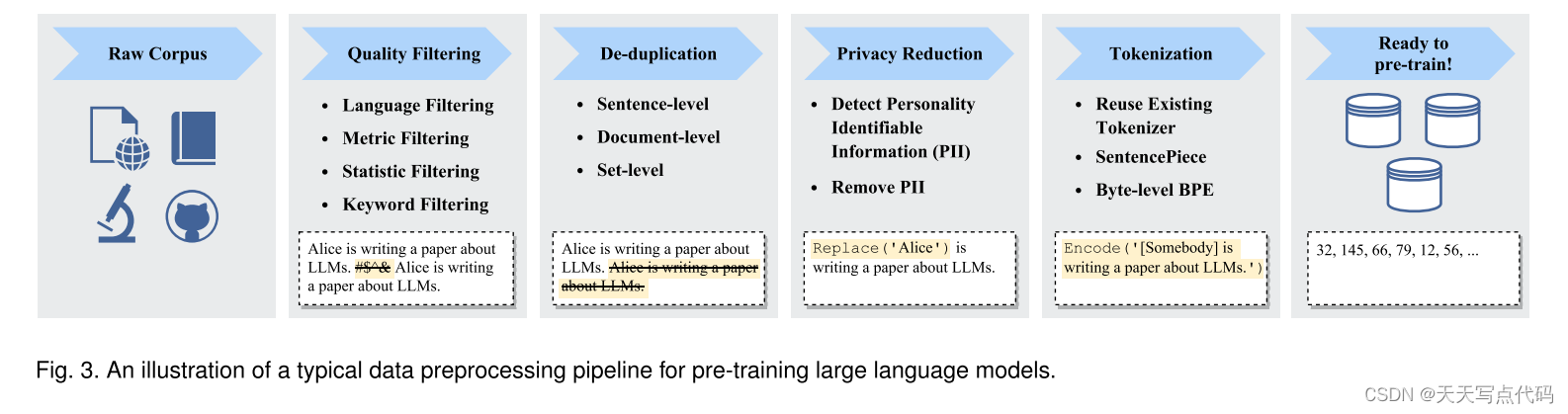
与小规模的 PLM 不同,由于对计算资源的巨大需求,通常不可能对 LLM 进行多次预训练迭代。因此,在训练 LLM 之前构建一个准备充分的预训练语料库尤为重要.
架构
本节中,我们将回顾 LLM 的架构设计,包括主流架构、预训练目标和详细配置。
一般来说,现有 LLM 的主流架构可以大致分为三种类型,即编码器-解码器、因果解码器和前缀解码器。
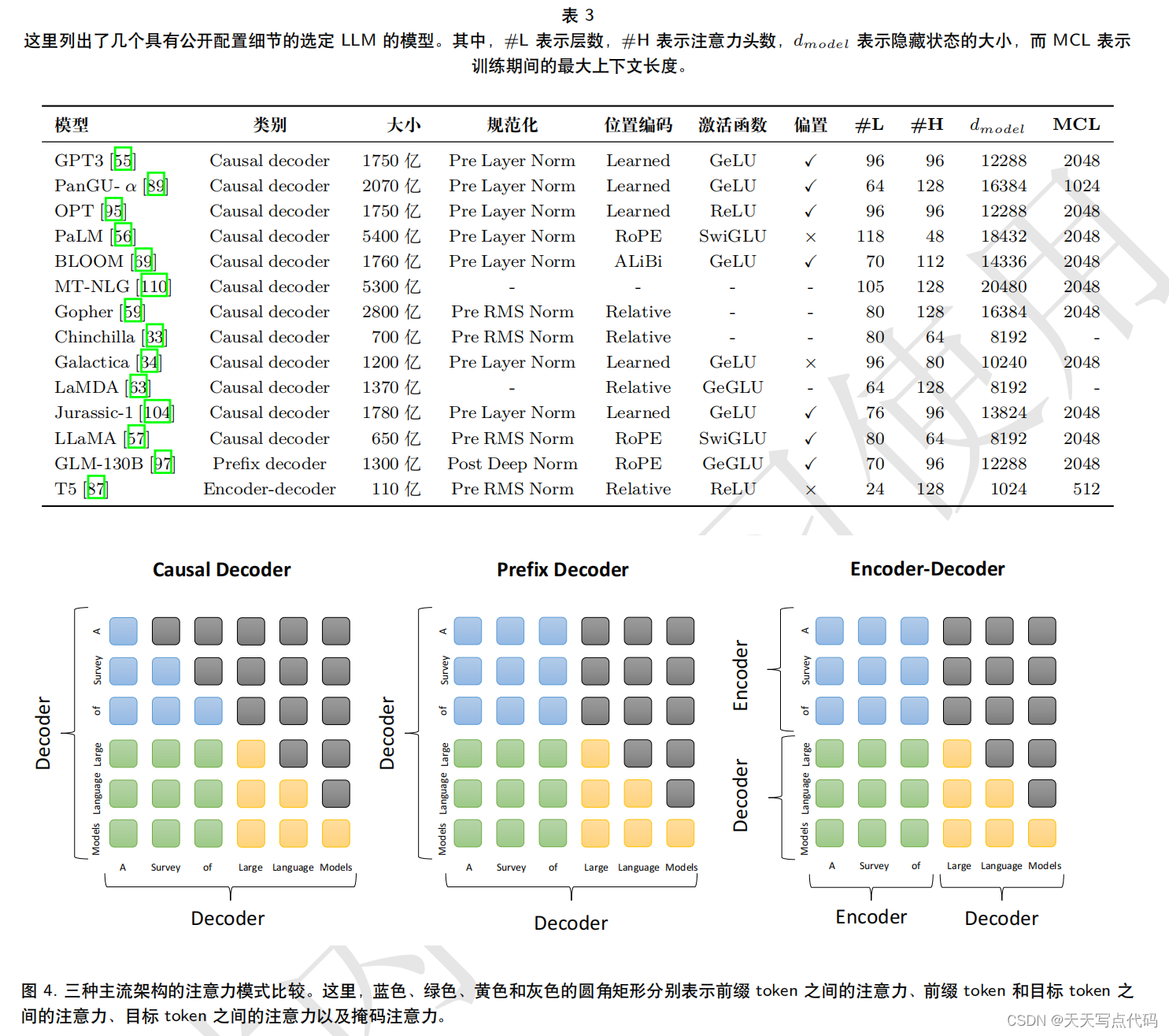
更新中