前言
在网络爬虫中,有些网站会设置反爬虫措施,服务器会检测某个IP在单位时间内的请求次数,如果超过了这个阈值,就会直接拒绝服务,返回一些错误信息,例如 403 Forbidden,“您的IP访问频率过高”这样的提示,这就是IP被封禁了,这种情况下就需要进行IP伪装。
代理的基本原理
代理实际上指的是代理服务器(proxy server),它的功能是代理网络用户去去的网络信息,是网络信息的中转站,一般情况下,请求访问网站时,是先发送请求给Web服务器,Web服务器再把响应传回给我们,如下图:

如果设置了代理服务器,实际上是在本机和服务器之间建立了一个桥梁,此时本机不是直接向Web服务器发起请求,而是向代理服务器发出请求,请求会发送给代理服务器,然后由代理服务器再发送给Web服务器,接着由代理服务器再把Web服务器返回的响应转发给本机,图解如下,这样同样可以正常访问网页,但这个过程中Web服务器识别出的真实IP就不再是我们本机的IP了,就成功实现了IP伪装,这就是代理的基本原理。

代理的作用
- 突破自身IP访问限制,访问一些平时不能访问的站点
- 访问一些单位或团体内部资源
- 提高访问速度:通常代理服务器都设置一个较大的硬盘缓冲区,当有外界信息通过时,同时也将其保存到缓冲区中,当其他用户再访问相同的信息时,则直接由缓冲区中取出信息,传给用户,以提高访问速度
- 隐藏真实IP,当作防火墙保护自身网络安全,在爬虫中可以防止自身的IP被封锁
代理分类
1. 根据协议区分
- FTP 代理服务器:主要用于访问FTP服务器,一般有上传、下载以及缓存功能,端口一般为 21、2121等
- HTTP 代理服务器:主要用于访问网页,一般有内容过滤和缓存功能,端口一般为 80、8080、3128等
- SSL/TLS 代理:主要用于访问加密网站,一般有 SSL 或 TLS 加密功能(最高支持128位加密强度),端口一般为 443
- RTSP 代理:主要用于访问Real流媒体服务器,一般有缓存功能,端口一般为 554
- Telnet 代理:主要用于 telnet 远程控制(黑客入侵计算机时常用于隐藏身份),端口一般为 23
- POP3/SMTP 代理:主要用于 POP3/SMTP 方式收发右键,一般有缓存功能,端口一般为 110/25
- SOCKS 代理:只是单纯传递数据包,不关心具体协议和用法,所以速度很快,一般有缓存功能,端口一般为 1080 。SOCKS 代理协议又分为 SOCK4 和 SOCK5,SOCK4 只支持TCP,而后者支持 TCP 和 UDP,还支持各种身份验证机制、服务器端域名解析等。
2. 根据匿名程度区分
- 高度匿名代理:会将数据包原封不动的转发,在服务端看来就好像真的是一个普通客户端在访问,而记录的IP是代理服务器的IP
- 普通匿名代理:会在数据包上做一些改动,服务端上有可能发现这是个代理服务器,也有一定几率追查到客户端的真实IP。代理服务器通常会加入的HTTP头有 HTTP_VIA 和 HTTP_X_FORWORD_FOR
- 透明代理:不但改动了数据包,还会告诉服务器客户端的真实IP。这种代理除了能用缓存技术提高浏览速度,能用内容过滤提高安全性之外,并无其他显著作用,最常见的例子是内网中的硬件防火墙
- 间谍代理:指组织或个人创建的用于记录用户传输的数据,然后进行研究、监控等目的的地理服务器
常见代理设置
- 使用网上的免费代理:最好使用高匿代理,这里将在下面爬取代理网站中所有代理
- 使用付费代理服务:付费代理会比免费代理更为稳定,效果更好,按需求选择
- ADSL 拨号:拨一次号换一次 IP,稳定性高
爬取代理网站IP
1. 定位所需网页元素节点,获取内容
以云代理网站为例,网站地址:云代理 - 高品质http代理ip供应平台/每天分享大量免费代理IP
这里我选择的是用Xpath解析库进行匹配爬取,在使用之前,需要确保安装好了 lxml 库,lxml 是 Python 的一个解析库,支持 HTML 和 XML 解析,支持 Xpath 解析方式,而且解析效率非常高,安装方式为:
pip3 install lxml如果没报错,则安装成功,若出现报错,例如缺少 libxml2 库等信息,可以采用 wheel 方式安装,推荐链接:https://www.lfd.uci.edu/~gohlke/pythonlibs/#lxml,下载对应的 wheel 文件,找到本地安装 Python 版本和系统对应的 lxml 版本,例如 Windows 64 位、python 3.6,就选择如下方式下载到本地:
pip3 install lxml-3.8.0-cp36-cp36m-win_amd64.whl

如图可以看出,我们所需要的信息全都在 <tr> 标签中的 <td> 里,这就能写出 Xpath 表达式:
# 将 html 字符串转换为 _ELEMENT 对象
html = etree.HTML(html)
result = html.xpath("//div[@id='list']//tr/td/text()")可以通过浏览器插件 Xpath Helper 来验证是否正确,相关插件的安装及使用方式,可以参考博文:
selenium中如何配置使用浏览器插件 及 xpath-helper、chropath下载方式_Yy_Rose的博客-CSDN博客_xpath 插件

2. 连接 MySQL 数据库,创建表格
import pymysql# 获取数据库连接
db = pymysql.connect(host='localhost', user='root', passwd='123456', port=3306, db='proxy')
# 获取游标
cursor = db.cursor()
# 若无 proxy 数据库可执行如下操作
# cursor.execute("create database proxy default character set utf8")
# 删除之前创建的表格,不然新的数据会直接添加在旧数据之后,造成数据冗余
cursor.execute("drop table proxy_pool")
create_sql = "create table if not exists proxy_pool(" \"代理IP地址 varchar(255) not null," \"端口 int not null," \"匿名度 text not null," \"类型 varchar(255) not null," \"支持 varchar(255) not null," \"位置 text not null," \"响应速度 text not null," \"最后验证时间 varchar(255) not null)engine=innodb default charset=utf8;"
cursor.execute(create_sql)3. 写入本地 txt
proxy_dir = 'proxy_pool.txt'
# 以追加模式写入
with open(proxy_dir, 'a', encoding='utf-8') as f:# json.dumps序列化时对中文默认使用的ascii编码,想输出真正的中文需要指定ensure_ascii=Falsef.write(json.dumps(content, ensure_ascii=False) + '\n')4. 测试获取到的IP是否可用
代理IP样式为:代理IP地址 :端口,所以需要先获取相关内容,存入标准代理样式列表:
ip_and_port.append(proxy_infos[0].text.strip() + ':' + proxy_infos[1].text.strip())以请求访问百度为例,传入获取到的代理IP,若网站返回状态码为 200 则说明此代理IP有效,将有效的代理IP存入相应的可用代理列表中并输出显示,若出现其他情况则判断该代理IP无效,并显示该代理IP。
def ip_test(ip_and_port_list, usable_ip_list):url = "https://www.baidu.com/"try:for ip in ip_and_port_list:try:response = requests.get(url, proxy={'https': ip},headers=headers, timeout=0.5)if response.status_code == 200:usable_ip_list.append(ip)print("该代理ip有效:" + ip)else:print("该代理ip无效:" + ip)except:print("该代理ip无效:" + ip)except:return None完整代码
# @Author : Yy_Rose
import requests
from lxml import etree
import json
from requests.exceptions import RequestException
import time
import pymysql# 获取数据库连接
db = pymysql.connect(host='localhost', user='root', passwd='123456', port=3306, db='proxy')
# 获取游标
cursor = db.cursor()
# 若无 proxy 数据库可执行如下操作
# cursor.execute("create database proxy default character set utf8")
# 删除之前创建的表格,不然新的数据会直接添加在旧数据之后,造成数据冗余
cursor.execute("drop table proxy_pool")
create_sql = "create table if not exists proxy_pool(" \"代理IP地址 varchar(255) not null," \"端口 int not null," \"匿名度 text not null," \"类型 varchar(255) not null," \"支持 varchar(255) not null," \"位置 text not null," \"响应速度 text not null," \"最后验证时间 varchar(255) not null)engine=innodb default charset=utf8;"
# 执行数据库操作
cursor.execute(create_sql)# 构建请求头
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64)'' AppleWebKit/537.36 (KHTML, like Gecko)'' Chrome/86.0.4240.198 Safari/537.36','Cookie': 'Hm_lvt_c4dd741ab3585e047d56cf99ebbbe102=1640671968,''1641362375;'' Hm_lpvt_c4dd741ab3585e047d56cf99ebbbe102=1641362386'
}# 获取 HTTPResponse 类型的对象
def get_one_page(url):try:response = requests.get(url, headers=headers)if response.status_code == 200:# 编码response.encoding = 'gbk'return response.textreturn Noneexcept RequestException:return None# 解析获取内容
def parse_one_page(proxy_pool, html, ip_and_port):# 将 html 字符串转换为 _ELEMENT 对象content = etree.HTML(html)# 第一行为 th 标签内容,故从第二行开始tr_cnotent_list = content.xpath("//div[@id='list']//tr")[1:]for proxy_infos in tr_cnotent_list:# strip() 方法用于移除字符串头尾指定的字符(默认为空格或换行符)或字符序列proxy_pool.append([proxy_infos[0].text.strip(),proxy_infos[1].text.strip(),proxy_infos[2].text.strip(),proxy_infos[3].text.strip(),proxy_infos[4].text.strip(),proxy_infos[5].text.strip(),proxy_infos[6].text.strip(),proxy_infos[7].text.strip()])ip_and_port.append(proxy_infos[0].text.strip() + ':' + proxy_infos[1].text.strip())ip = proxy_infos[0].text.strip()port = proxy_infos[1].text.strip()anonymity = proxy_infos[2].text.strip()ip_type = proxy_infos[3].text.strip()support_type = proxy_infos[4].text.strip()position = proxy_infos[5].text.strip()response_speed = proxy_infos[6].text.strip()verify_time = proxy_infos[7].text.strip()# 将获取到的数据插入到数据库中insert_into = ("INSERT INTO proxy_pool(代理IP地址,端口,匿名度,类型,支持,位置,响应速度,最后验证时间)""VALUES(%s,%s,%s,%s,%s,%s,%s,%s);")data_into = (ip, port, anonymity, ip_type, support_type, position,response_speed,verify_time)cursor.execute(insert_into, data_into)# 将 insert 语句提交给数据库db.commit()# 写入本地 txt
def wirte_to_txt(content):proxy_dir = 'proxy_pool.txt'# 以追加模式写入with open(proxy_dir, 'a', encoding='utf-8') as f:# json.dumps序列化时对中文默认使用的ascii编码,想输出真正的中文需要指定ensure_ascii=Falsef.write(json.dumps(content, ensure_ascii=False) + '\n')# 打印内容到控制台
def print_list(proxy_list):for i in range(10):print(proxy_list[i])wirte_to_txt(proxy_list[i])# 测试IP是否可用
def ip_test(ip_and_port_list, usable_ip_list):url = "https://www.baidu.com/"try:for ip in ip_and_port_list:try:response = requests.get(url, proxy={'https': ip},headers=headers, timeout=0.5)if response.status_code == 200:usable_ip_list.append(ip)print("该代理ip有效:" + ip)else:print("该代理ip无效:" + ip)except:print("该代理ip无效:" + ip)except:return Nonedef main(offset):# 分页爬取url = 'http://www.ip3366.net/?stype=1&page=' + str(offset)html = get_one_page(url)proxy_pool = []usable_ip = []ip_port = []parse_one_page(proxy_pool, html, ip_port)print("以下为查询到的数据:")print_list(proxy_pool)print('=' * 50)ip_test(ip_port, usable_ip)print('=' * 50)print("有效的代理ip为:")# 判断列表是否为空if usable_ip:for usable in usable_ip:print(usable, end=' ')else:print(f"很遗憾,第{offset}页的代理IP全都无效")print('=' * 50)if __name__ == '__main__':num = int(input("请输出想查询多少页ip:"))# 共10页,100条记录,range()为左闭右开for page in range(1, num + 1):main(offset=page)time.sleep(2)
控制台打印:

代理IP测试:

本地 txt:

数据库效果:
写项目过程中的报错
pymysql.err.ProgrammingError: (1064, "You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near 'get/post支持 varchar(255) not null,位置 text not null,响应速度 text not ' at line 1")
原因:创建表格的字段名与MySQL关键字冲突,get/post 支持改为支持即可
TypeError: not all arguments converted during string formatting
原因:并非所有参数都在字符串格式化期间转换
insert_into = ("INSERT INTO proxy_pool(代理IP地址,端口,匿名度,类型,支持,位置,响应速度,最后验证时间)""VALUES(?,?,?,?,?,?,?,?);")分析可能性一:
一开始使用的是 ?占位符, 其可使用参数的位置,标识变量,用于变量传值,支持和最后验证时间列不止一个元素,?无法完全匹配,导致参数数量不对应
更改为 %s 就好了,%s 表示 str(),字符串可以包含空格、特殊字符,能一一匹配到完整元素
insert_into = ("INSERT INTO proxy_pool(代理IP地址,端口,匿名度,类型,支持,位置,响应速度,最后验证时间)""VALUES(%s,%s,%s,%s,%s,%s,%s,%s);")分析可能性二:
import sqlite3
在SQLite数据库中,可以直接使用第一种方法插入一条或多条数据,经测试成功插入
import pymysql
在MySQL数据库中,不支持第一种插入方法
pymysql.err.InterfaceError: (0, '')
原因:数据库连接在创建表格后就关闭了,导致无法进行数据库操作,插入数据操作时报错

pymysql.err.DataError: (1366, "Incorrect string value: '\\xE9\\xAB\\x98\\xE5\\x8C\\xBF...' for column '匿名度' at row 1")
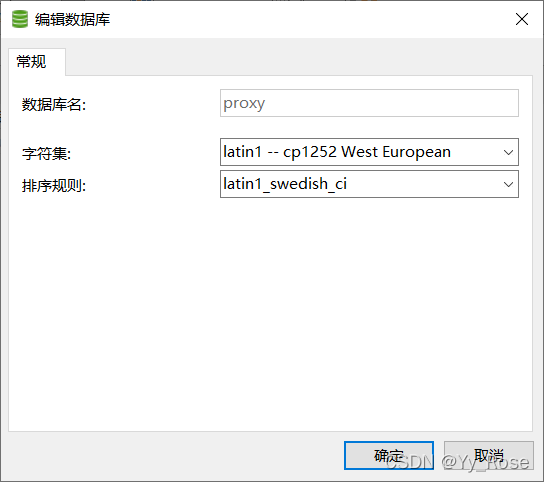
原因:创建数据库时未将字符集设置为 utf-8 格式,更改为 utf8 -- UTF-8 Unicode 即可,以下为之前导致报错的样式:
总结
免费的代理 IP 大部分都是无效的,不稳定的,以上为代理的相关知识及如何爬取代理网站代理 IP 列表的相关介绍,欢迎评论指正交流~