1、前言
虽然一直干着运维的工作,但是对编程却有莫名的兴趣,于是就依仗着大学时的一些编程基础,在空闲时间自学了python、flask框架、bootstrap、jquery,html等。并用此写了一个看爽文的“工具”。
2、设计思路
通过爬虫爬取感兴趣的爽文,并将广告、飘窗过滤。
爬取后的爽文通过浏览器阅读,左边显示目录,通过点击目录,右边显示内容。
为了不占用个人电脑的空间暂时不保存爽文。
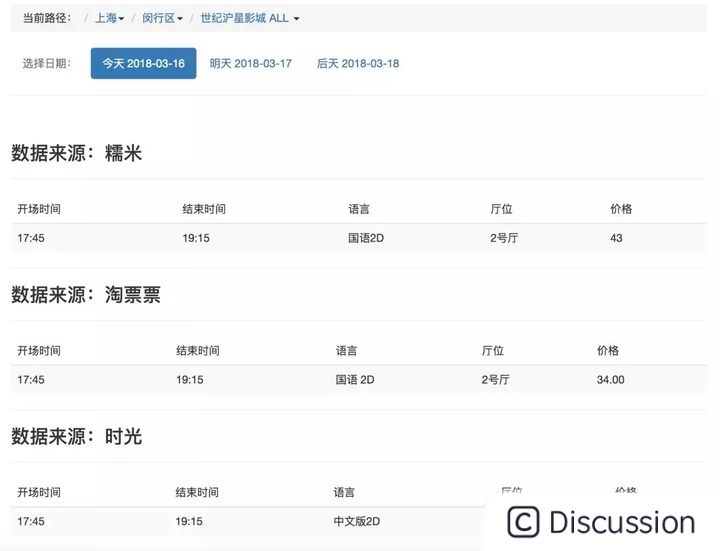
3、成品展示

4、撸码
4.1 构造flask
跳过按照flask,直接进入撸码
---------qqweb.py----------------
---------qqweb.py----------------
# -*-coding=utf-8 -*-
from flask import Flask,render_template,request
from flask import session
import os
import sys
reload(sys)
sys.setdefaultencoding("utf-8")
# 显示中文
os.environ['NLS_LANG'] = 'SIMPLIFIED CHINESE_CHINA.UTF8' app=Flask('__name__')
if __name__=='__main__':app.run(debug=True)
上面代码写完后,flask就跑起来了,,但是基本上什么功能都没有,这时,就要构建以下目录和代码。
4.2 flask目录结构
项目名称
----static #存放静态文件图片,css 等
----template #html 文件 配合flask jinja2使用
----novel #爽文爬取主程序目录
__init__.py
sw.py
qqweb.py
4.3 爽文爬虫类编写
约定:类函数和方法使用动词+名词小驼峰方式命名,如getCatalog
类名字大写。
--------sw.py
# -*- coding: utf-8 -*-
defaultencoding = 'utf-8'
import random
import time
import requests
import json
import datetime
import pickle
import threading
import schedule
from bs4 import BeautifulSoup #经典html分析库文件
import urllib2
import sys
import pandas
from selenium import webdriver #遇到一些要渲染的网站就靠它了
from selenium.webdriver.chrome.options import Options
import osreload(sys)
sys.setdefaultencoding(defaultencoding)class SW():#构建爬虫的头和初始化urldef __init__(self,swurl=None):self.url=swurlself.headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.103 Safari/537.36",'Content-Type': 'application/json'}def getCatalog(self):r = requests.request('get', self.url, headers=self.headers) #有get ,有post ,requests.post/get的变形r.encoding = 'UTF-8' #编码,防止乱码html = r.text # 获取html 源码文件,含有html标签print r.status_codebs = BeautifulSoup(html, "html5lib")taglist = bs.find_all("dd") #搜索文件里含有dd标签的块。cataloglist=[]
#遍历搜索结果,类型是bs下的tag,这个tag使用方法非常强大,你可以直接访问html tag的子tag ,属性、text
# 如dd tag下有一个a标签href的属性值,我们就可以用这个方式访问tag.a["href"]
#如dd tag下有一个a标签text的值(<a href='url'>qq </a>),我们就可以用这个方式访问tag.a.get_text() 就能得到qq的值。for tag in taglist:cataloglist.append((str(tag.a.text).strip()," http://www.xe.la"+tag.a["href"],chr(13)+chr(10)))return cataloglistdef saveCatalog(self,catalog):try:with open("../novel/sw.txt", 'w+') as f :for c in catalog:# print cf.write(c[0]+c[1]+c[2])return 1except Exception as e:print ereturn 0
#检查有没有更新def checkUpdate(self):with open("../novel/sw.txt", 'r') as f:oldcatalog=f.readlines()# print catalog# oldcatalog=catalog[-1]# oldcatalog=len(catalog)newcatalog=self.getCatalog()# oldlastchapter=oldcatalog.split()[0]# newlastchapter=newcatalog[-1][0].split()[0]diffcatalog=len(newcatalog)-len(oldcatalog)# print len(newcatalog),len(oldcatalog),diffcatalog# print newcatalog[1][0],oldcatalog[1].split()[0]if diffcatalog==0:print "无更新"return 0else:print "有%i更新"%(diffcatalog)self.saveCatalog(newcatalog)return 1
#获取章节内容,这里没有使用request去爬取,是因为网站好像使用了脚本做渲染,所以我需要使用浏览器渲染一下,这时使用了webdriver.Chrome,具体使用不细表。def getChapter(self,chapterurl):chrome_options = Options()chrome_options.add_argument('--headless') #无头浏览器的属性指定,所谓无头就是不弹出浏览器novel_chrome = webdriver.Chrome(chrome_options=chrome_options) novel_chrome.get(chapterurl) #输入网址发出请求html = novel_chrome.page_source #获取源码# print htmlnovel_chrome.close()novel_chrome.quit()# print htmlnovel_content = ""bs = BeautifulSoup(html, "html5lib")titles= bs.find_all("h1")for title in titles:novel_content = novel_content+title.get_text()novel_content = "<h1 align='center'>"+novel_content + "</h1>"tag_list = bs.find_all("div", attrs={"id": "content"}) #查找id=content的divfor tag in tag_list:novel_content = novel_content + tag.get_text()return novel_contentif __name__=='__main__':dmz=DaMengZhu("http://www.xb.la/1x/15xx7") #我脱敏了
爬虫写好了,调试一下就可以用了。
4.4 展示页面的设计
由于不太熟悉的前端设计工具、代码的使用这里大多数都是把自己想法放在度娘上搜索,然后copy paste代码。
template
-----sw.html
<!DOCTYPE html><html lang="en"><head><meta charset="UTF-8"><title>bootstrap测试</title><!-- 引用jquery bootstrap 等等。都是copy回来的,不求甚解 --><link rel="stylesheet" href="https://cdn.staticfile.org/twitter-bootstrap/4.1.0/css/bootstrap.min.css"><script src="https://cdn.staticfile.org/jquery/3.2.1/jquery.min.js"></script><script src="https://cdn.staticfile.org/popper.js/1.12.5/umd/popper.min.js"></script><script src="https://cdn.staticfile.org/twitter-bootstrap/4.1.0/js/bootstrap.min.js"></script></head><body><script>function get_news_alert(){alert("小说内容较多,请耐心等候!")}</script><!-- 倒入导航文件,不用重复copy,提升页面的简洁 -->{% include 'header.html' %}<!-- 使用div 标签进行页面布局,其中style 关键字可以以字典形式指定多种属性,如backgroud ; width :1400px; height等 --><!-- 这里的使用了一个div 嵌套了两个div --><div style="width:1400px"><!-- 要两个div 并排在一起,这里有一个重要属性float:left 和两个div的width不能大于外一层div的width overflow:scroll;滚动条的指定--><div class="form-group" style="overflow:scroll;height:2400px;width:150px;float:left" align="left" ><ul><!-- 一下是jinja2 的语法 不过多说明 -->{% for c in catalog %}<!-- 这里再说一下 a 标签和 iframe的联动,实现左边点击目录,右面显示内容,关键的key是target="指向iframe name属性的值" --><li> <a href="./content?dmzurl={{c[1].strip()}}" target="dmzcontent">{{c[0]}} </li>{%endfor%}</ul></div><div class="form-group" style="background:lightblue;width:1200px;float:left"><iframe src="" name="dmzcontent" style="width:1200px;height:2400px;border:0;frameborder:no" align="left"> </iframe></div></div></body></html>4.5 flask路由编码
在qqweb.py上添加下面的代码,看无广告的小爽文的工具就完成了。
from novel import sw@app.route('/sw',methods=['POST','GET'])def ShowDMZCatalog():html=""dmz=sw.SW("http://www.xb.la/15/15977")catalog=dmz.getCatalog()# 这里的catalog变量值赋予template 中sw.html 中的{{catalog}}return render_template('sw.html',catalog=catalog)@app.route('/dmz/content',methods=['POST','GET'])def ShowDMZContent():html=""dmz=damengzhu.DaMengZhu()# 如果是以get的方法提交参数,需要用request.args.get('参数名字',type=unicode 支持汉字编码)chapterurl=request.args.get('dmzurl',type=unicode)content=dmz.getChapter(chapterurl)# 关键white-space:pre-wrap;word-wrap:break-word自动换行return '<div style="word-wrap:break-word;"> <pre style="white-space:pre-wrap;word-wrap:break-word;font-size:18px">'+ content +'</pre> </div>'5、完成
完成,发布测试进行微调。
后续完成功能:
- 做一个定时任务,自动发现更新,然后拉取。
- 批量下载文件
- 尝试使用数据分析方法分析爽文人物性格和关系。
参考
推荐一个网站:
http://exploreflask.com/en/latest/blueprints.html