一、爬取数据
①qiancheng.py

②pipelines.py

③sitting

④items

二、数据储存
1、把MongoDB数据导出为csv文件
在E:\MongoDB\bin下cmd
mongoexport.exe --csv -f _id,name,salary,gongsi,didian,jingyan,xueli,neirong,jineng -d qiancheng -c Table -o Test.csv


2、上传数据
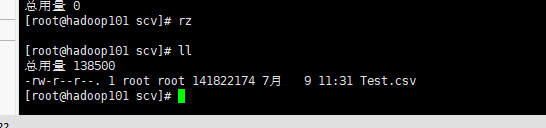
3、利用flume收集日志
(1)创建agent-hdfs.conf文件
vi agent-hdfs.conf
(2)配置agent-hdfs.conf文件

(3)查看日志
在这里执行目录下执行命令

./bin/flume-ng agent --conf ./conf/ --name a2 --conf-file ./conf/agent_hdfs.conf -Dflume.root.logger=DEBUG,console


三、数据分析
1、导入数据
(1)创建数据库
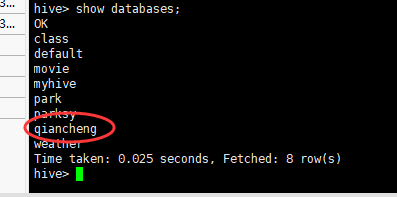
(2)创建表
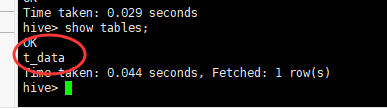
(3)导入数据到t_data表中
(4)查看数据
select * from t_data;

2、岗位薪资分析
(1)数据分析岗位
①模糊匹配:条件为数据分析、万/月,提取name和salary字段存入sjfx1表中
create table sjfx1 as select name, salary from t_data where name like '%数据分析%' and salary like '%万/月%';
查看sjfx1中是否有数据
select * from sjfx1 limit 10;

②分割薪资,求出每个岗位的最高、最低、平均工资
create table sjfx2 as select name, regexp_extract(salary,'([0-9]+)-',1) as salary1_min, regexp_extract(salary,'-([0-9]+)',1) as salary1_max, (regexp_extract(salary,'([0-9]+)-',1) + regexp_extract(salary,'-([0-9]+)',1))/2 as salary1_avg from sjfx1;
查看sjfx2中是否有数据
select * from sjfx2 limit 10;

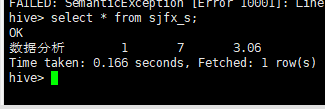
③计算所有数据分析岗位的最大 、最小、平均工资
create table sjfx_s as select "数据分析" as name, min(int(salary1_min)) as salary1_min, max(int(salary1_max)) as salary1_max, regexp_extract(avg(salary1_avg),'([0-9]+.[0-9]?[0-9]?)',1) as salary1_avg from sjfx2;
查看sjfx_s表中数据
(2)大数据开发工程师
①模糊匹配:条件为大数据开发工程师、万/月,提取name和salary字段存入kfgc1表中
create table kfgc1 as select name, salary from t_data where name like '%大数据开发%' and salary like '%万/月%';
查看kfgc1中是否有数据
select * from kfgc1 limit 10;

②分割薪资,求出每个岗位的最高、最低、平均工资
create table kfgc2 as select name, regexp_extract(salary,'([0-9]+)-',1) as salary2_min, regexp_extract(salary,'-([0-9]+)',1) as salary2_max, (regexp_extract(salary,'([0-9]+)-',1) + regexp_extract(salary,'-([0-9]+)',1))/2 as salary2_avg from kfgc1;
查看kfgc2中是否有数据
select * from kfgc2 limit 10;

③计算所有大数据开发工程师的最大 、最小、平均工资
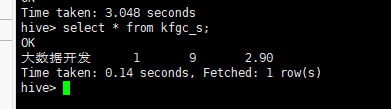
create table kfgc_s as select "大数据开发" as name, min(int(salary2_min)) as salary2_min, max(int(salary2_max)) as salary2_max, regexp_extract(avg(salary2_avg),'([0-9]+.[0-9]?[0-9]?)',1) as salary2_avg from kfgc2;
查看kfgc_s表中数据
select * from kfgc_s;
(3)数据采集岗位
①模糊匹配:条件为数据采集、万/月,提取name和salary字段存入sjcj1表中
create table sjcj1 as select name, salary from t_data where name like '%数据采集%' and salary like '%万/月%';
查看kfgc1中是否有数据
select * from sjcj1 limit 10;

②分割薪资,求出每个岗位的最高、最低、平均工资
create table sjcj2 as select name, regexp_extract(salary,'([0-9]+)-',1) as salary3_min, regexp_extract(salary,'-([0-9]+)',1) as salary3_max, (regexp_extract(salary,'([0-9]+)-',1) + regexp_extract(salary,'-([0-9]+)',1))/2 as salary3_avg from sjcj1;
查看sjcj2中是否有数据

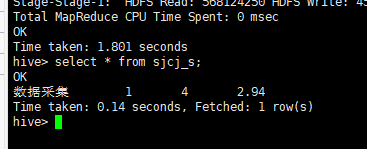
③计算所有大数据开发工程师的最大 、最小、平均工资
create table sjcj_s as select "数据采集" as name, min(int(salary3_min)) as salary3_min, max(int(salary3_max)) as salary3_max, regexp_extract(avg(salary3_avg),'([0-9]+.[0-9]?[0-9]?)',1) as salary3_avg from sjcj2;
查看sjcj_s表中数据
(4)把三个岗位表合并。
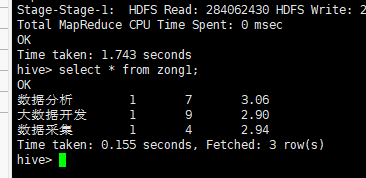
①创建一个zong表,并插入sjfx_s、kfgc_s、sjcj_s的数据
create table zong1(name string, min int, max int, avg string);
insert into table zong1 select * from sjfx_s;
insert into table zong1 select * from kfgc_s;
insert into table zong1 select * from sjcj_s;
查看zong1表数据
select * from zong1;
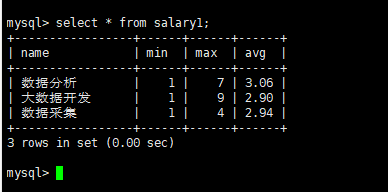
5、将hive分析结果利用sqoop存储到mysql数据库中。
在sqoop目录下运行
利用sqoop导入数据hive到mysql出现乱码,是编码的问题
将--connect jdbc:mysql://hadoop:3306/sj_fx 改为--connect "jdbc:mysql://hadoop:3306/qflap?useUnicode=true&characterEncoding=utf-8"
bin/sqoop export --connect "jdbc:mysql://hadoop:3306/sj_fx?useUnicode=true&characterEncoding=utf-8" --username root --password password --table salary1 --export-dir /user/hive/warehouse/qiancheng.db/zong1 --input-null-string "\\\\N" --input-null-non-string "\\\\N" --input-fields-terminated-by "\001" --input-lines-terminated-by "\\n" -m 1;

查看数据
6、岗位数分析
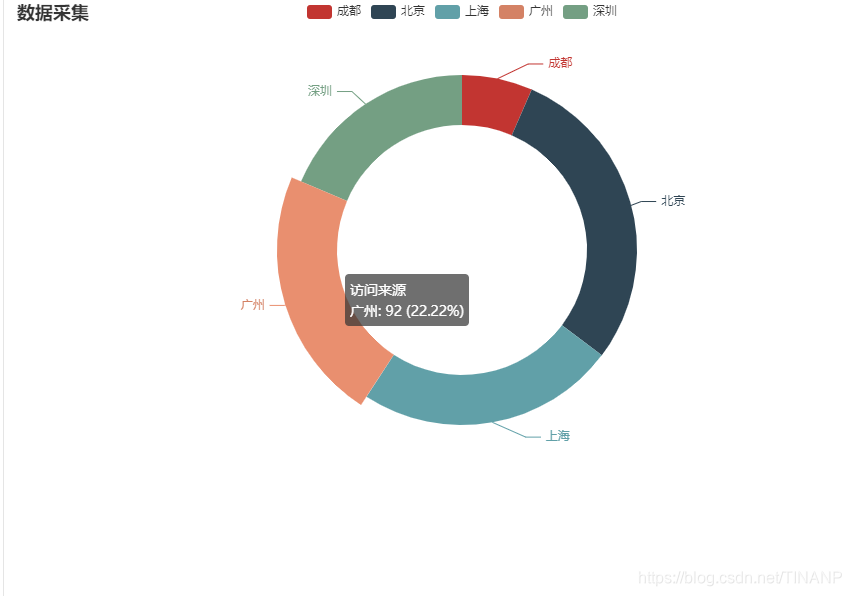
分析岗位:数据分析、大数据开发工程师、数据采集。
地点:成都、北京、上海、广州、深圳。
(1)成都地区
创建chengdu表
create table chengdu(name string, num int);
向表中插入数据
①数据分析岗位
insert into table chengdu select '数据分析', count(*) from t_data where name like '%数据分析%' and jobplace like '%成都%';
②大数据开发工程师岗位
insert into table chengdu select '大数据开发工程师', count(*) from t_data where name like '%大数据开发工程师%' and didian like '%成都%';
③数据采集岗位
insert into table chengdu select '数据采集', count(*) from t_data where name like '%数据采集%' and didian like '%成都%';
查看表chengdu表的数据
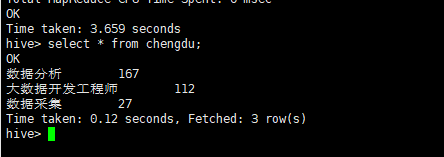
(2)北京地区
创建beijing表
create table beijing(name string, num int);
向表中插入数据
①数据分析岗位
insert into table beijing select '数据分析', count(*) from t_data where name like '%数据分析%' and didian like '%北京%';
②大数据开发工程师岗位
insert into table beijing select '大数据开发工程师', count(*) from t_data where name like '%大数据开发工程师%' and didian like '%北京%';
③数据采集岗位
insert into table beijing select '数据采集', count(*) from t_data where name like '%数据采集%' and didian like '%北京%';
查看beijing表数据
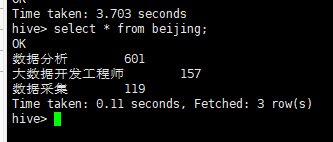
(3)上海地区
创建shanghai表
create table shanghai(name string, num int);
向表中插入数据
①数据分析岗位
insert into table shanghai select '数据分析', count(*) from t_data where name like '%数据分析%' and didian like '%上海%';
②大数据开发工程师岗位
insert into table shanghai select '大数据开发工程师', count(*) from t_data where name like '%大数据开发工程师%' and didian like '%上海%';
③数据采集岗位
insert into table shanghai select '数据采集', count(*) from t_data where name like '%数据采集%' and didian like '%上海%';
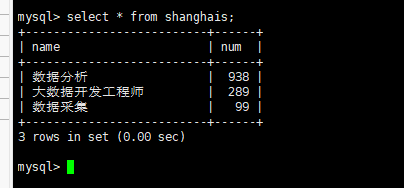
查看shanghai表数据
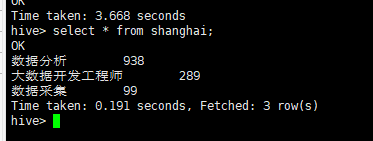
(4)广州地区
创建guangzhou表
create table guangzhou(name string, num int);
向表中插入数据
①数据分析岗位
insert into table guangzhou select '数据分析', count(*) from t_data where name like '%数据分析%' and didian like '%广州%';
②大数据开发工程师岗位
insert into table guangzhou select '大数据开发工程师', count(*) from t_data where name like '%大数据开发工程师%' and didian like '%广州%';
③数据采集岗位
insert into table guangzhou select '数据采集', count(*) from t_data where name like '%数据采集%' and didian like '%广州%';
查看guangzhou表数据
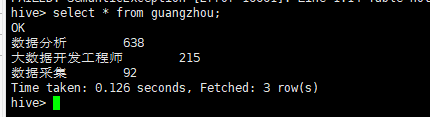
(5)深圳地区
创建shenzhen表
create table shenzhen(name string, num int);
向表中插入数据
①数据分析岗位
insert into table shenzhen select '数据分析', count(*) from t_data where name like '%数据分析%' and didian like '%深圳%';
②大数据开发工程师岗位
insert into table shenzhen select '大数据开发工程师', count(*) from t_data where name like '%大数据开发工程师%' and didian like '%深圳%';
③数据采集岗位
insert into table shenzhen select '数据采集', count(*) from t_data where name like '%数据采集%' and didian like '%深圳%';
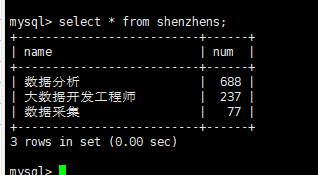
查看shenzhen表数据
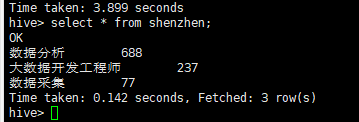
(5)将hive分析结果利用sqoop存储到mysql数据库中。
在mysql中创建chengdus、beijings、shanghais、guangzhous、shenzhens五个表
create table chengdus(name varchar(20), num int) charset utf8 collate utf8_general_ci;
create table beijings(name varchar(20), num int) charset utf8 collate utf8_general_ci;
create table shanghais(name varchar(20), num int) charset utf8 collate utf8_general_ci;
create table guangzhous(name varchar(20), num int) charset utf8 collate utf8_general_ci;
create table shenzhens(name varchar(20), num int) charset utf8 collate utf8_general_ci;
①导入chengdu表数据
在sqoop目录下运行
bin/sqoop export --connect "jdbc:mysql://hadoop:3306/sj_fx?useUnicode=true&characterEncoding=utf-8" --username root --password password --table chengdus --export-dir /user/hive/warehouse/qiancheng.db/chengdu --input-null-string "\\\\N" --input-null-non-string "\\\\N" --input-fields-terminated-by "\001" --input-lines-terminated-by "\\n" -m 1;

②导入beijing表数据
bin/sqoop export --connect "jdbc:mysql://hadoop:3306/sj_fx?useUnicode=true&characterEncoding=utf-8" --username root --password password --table beijings --export-dir /user/hive/warehouse/qiancheng.db/beijing --input-null-string "\\\\N" --input-null-non-string "\\\\N" --input-fields-terminated-by "\001" --input-lines-terminated-by "\\n" -m 1;
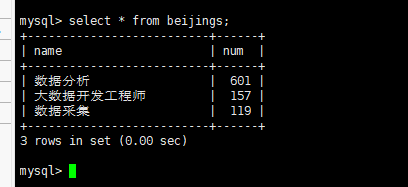
③导入shanghai表数据
bin/sqoop export --connect "jdbc:mysql://hadoop:3306/sj_fx?useUnicode=true&characterEncoding=utf-8" --username root --password password --table shanghais --export-dir /user/hive/warehouse/qiancheng.db/shanghai --input-null-string "\\\\N" --input-null-non-string "\\\\N" --input-fields-terminated-by "\001" --input-lines-terminated-by "\\n" -m 1;
④导入guangzhou表数据
bin/sqoop export --connect "jdbc:mysql://hadoop:3306/sj_fx?useUnicode=true&characterEncoding=utf-8" --username root --password password --table guangzhous --export-dir /user/hive/warehouse/qiancheng.db/guangzhou --input-null-string "\\\\N" --input-null-non-string "\\\\N" --input-fields-terminated-by "\001" --input-lines-terminated-by "\\n" -m 1;

⑤导入shenzhen表数据
bin/sqoop export --connect "jdbc:mysql://hadoop:3306/sj_fx?useUnicode=true&characterEncoding=utf-8" --username root --password password --table shenzhens --export-dir /user/hive/warehouse/qiancheng.db/shenzhen --input-null-string "\\\\N" --input-null-non-string "\\\\N" --input-fields-terminated-by "\001" --input-lines-terminated-by "\\n" -m 1;
7、分析大数据相关岗位1-3年工作经验的薪资水平
(1)、提取出大数据相关岗位,并有1、2、3 、1-3年工作经验的数据
create table xzsp_dsj as select name, salary, jingyan from t_data where name like '%大数据%' and salary like '%万/月%' group by name, salary, jingyan having jingyan='1年经验' or jingyan='2年经验' or jingyan='3年经验' or jingyan='1-3年经验';
查看xzsp_dsj表数据

(2)、分割薪资,求出每个岗位的最高、最低、平均工资
create table xzsp_dsj1 as select name, int(regexp_extract(salary,'([0-9]+)-',1)) as min, int(regexp_extract(salary,'-([0-9]+)',1)) as max, (int(regexp_extract(salary,'([0-9]+)-',1)) + int(regexp_extract(salary,'-([0-9]+)',1)))/2 as avg from xzsp_dsj;
查看xzsp_dsj1表数据

(3)、计算所有大数据岗位的最大 、最小、平均工资
create table xzsp_dsj_s as select "大数据" as name, min(min) as min, max(max) as max, regexp_extract(avg(avg),'([0-9]+.[0-9]?[0-9]?)',1) as avg from xzsp_dsj1;
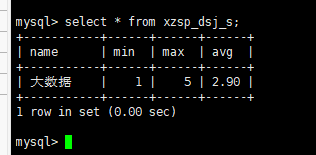
查看xzsp_dsj_s数据
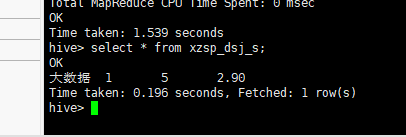
(4)将hive分析结果利用sqoop存储到mysql数据库中。
在mysql上创建xzsp_dsj_s表
create table xzsp_dsj_s (name varchar(20), min int, max int, avg varchar(10)) charset utf8 collate utf8_general_ci;
导入数据,在sqoop目录下运行代码
bin/sqoop export --connect "jdbc:mysql://hadoop:3306/sj_fx?useUnicode=true&characterEncoding=utf-8" --username root --password password --table xzsp_dsj_s --export-dir /user/hive/warehouse/qiancheng.db/xzsp_dsj_s --input-null-string "\\\\N" --input-null-non-string "\\\\N" --input-fields-terminated-by "\001" --input-lines-terminated-by "\\n" -m 1;
查看xzsp_dsj_s表数据
8、可视化
①岗位工资分析图


②岗位数分析图

数据分析岗位

大数据开发工程师岗位

数据采集岗位图