来自:http://www.jqpress.com/post/34.aspx
说是电子商务搜索架构方案,其实就是lucene.net的应用,公司庙小,人少,也就自己平时看看,以前做过一点例子,这样就被拉上去写架构方案了。我这个懒惰的家伙,在网上疯狂的搜集搜索架构方面的东西,因为做做架构,暂时没写代码,每天就看人家博客,结果两个星期了才弄了个大概的草图,这不清明节过后就要详细方案了,现在只能把我的草图分享一下,希望大家板砖伺候,闷在家里鼓捣比较郁闷啊,效率太低。
基于lucene的搜索方案
一、 Lucene 简介
Lucene是apache的一个顶级开源项目,由java实现的全文检索引擎,能基于各种文档格式的全文索引和检索,包括word、pdf,不包括图形类。
Lucene.net 是C#版的lucene 是由java的lucene翻译过来的,也被apache列为开源项目对外发布,功能和java的基本一样,但是由于缺乏良好的技术支持和社区活跃度,目前已被apache放入孵化器
Lucene写入:源文件经过analyzer处理,包括分词,权重处理、生成document记录,写入存储器(硬盘或者内存)。
Lucene 读出:对搜索关键词进行analyzer处理,包括分词、权重、范围匹配处理.源码结构图如下:

具体流程如下图:

数据流图如下:

二、常用推荐引擎算法问题
采用基于数据挖掘的算法来实现推荐引擎是各大电子商务网站、SNS社区最为常用的方法,推荐引擎常用Content-Based 推荐算法及协同过滤算法(Item-Based 、User-based)。但从实际应用来看,对于大部分中小型企业来说,要在电子商务系统完整采用以上算法还有很大的难度。
1)、相对成熟、完整、现成的开源解决方案较少
粗略分来,目前与数据挖掘及推荐引擎相关的开源项目主要有如下几类:
数据挖掘相关:主要包括Weka、R-Project、Knime、RapidMiner、Orange 等
文本挖掘相关:主要包括OpenNLP、LingPipe、FreeLing、GATE 、Carrot2 等,具体可以参考LingPipe’s Competition
推荐引擎相关:主要包括Apache Mahout、Duine framework、Singular Value Decomposition (SVD) ,其他包可以参考Open Source Collaborative Filtering Written in Java
搜索引擎相关:Lucene、Solr、Sphinx、Hibernate Search等
2)、常用推荐引擎算法相对复杂,入门门槛较高
3)、常用推荐引擎算法性能较低,并不适合海量数据挖掘
以上这些包或算法,除了Lucene/Sor相对成熟外,大部分都还处于学术研究使用,并不能直接应用于互联网规模的数据挖掘及推荐引擎引擎使用。
(以上都是基于java的,需要自己去研究实现,有很大难度)
备注:除了分类查找和主动搜索,推荐系统也是用户浏览商品的重要途径,能帮助用户发现类似并感兴趣的产品,增加商品的访问量,将访问者转化为购买者,引导用户购买。最终产生的价值是提升用户购物体验和用户粘度,提高订单量,如Amazon30%的订单来自推荐系统。
采用Lucene实现推荐引擎的优势
对很多众多的中小型网站而言,由于开发能力有限,如果有能够集成了搜索、推荐一体化的解决方案,这样的方案肯定大受欢迎。采用Lucene来实现推荐引擎具有如下优势:
1)、Lucene 入门门槛较低,大部分网站的站内搜索都采用了Lucene
2)、相对于协同过滤算法,Lucene性能较高
3)、Lucene对Text Mining、相似度计算等相关算法有很多现成方案
在开源的项目中,Mahout或者Duine Framework用于推荐引擎是相对完整的方案,尤其是Mahout 核心利用了Lucene,因此其架构很值得借鉴。只不过Mahout目前功能还不是很完整,直接用其实现电子商务网站的推荐引擎尚不是很成熟。只不过从Mahout实现可以看出采用Lucene实现推荐引擎是一种可行方案。
3、采用Lucene实现推荐引擎需要解决的核心问题
Lucene对于Text Mining较为擅长,在contrib包中提供了MoreLikeThis功能,可以较为容易实现Content-Based的推荐,但对于涉及用户协同过滤行为的结果(所谓的Relevance Feedback),Lucene目前并没有好的解决方案。需要在Lucene中内容相似算法中加入用户协同过滤行为对因素,将用户协同过滤行为结果转化为Lucene所支持的模型。
推荐引擎的数据源
电子商务网站与推荐引擎相关典型的行为:
购买本商品的顾客还买过
浏览本商品的顾客还看过
浏览更多类似商品
喜欢此商品的人还喜欢
用户对此商品的平均打分
因此基于Lucene实现推荐引擎主要要处理如下两大类的数据
1)、内容相似度
例如:商品名称、作者/译者/制造商、商品类别、简介、评论、用户标签、系统标签
2)、用户协同行为相似度
例如:打标签、购买商品、点击流、搜索、推荐、收藏、打分、写评论、问答、页面停留时间、所在群组等等
5、实现方案
5.1、内容相似度 基于Lucene MoreLikeThis实现即可。
5.2、对用户协同行为的处理
1)、用户每一次协同行为都使用lucene来进行索引,每次行为一条记录
2)、索引记录中包含如下重要信息:
商品名、商品id、商品类别、商品简介、标签等重要特征值、用户关联行为的其他商品的特征元素、商品缩略图地址、协同行为类型(购买、点击、收藏、评分等)、Boost值(各协同行为在setBoost时候的权重值)
3)、对评分、收藏、点击等协同行为以商品特征值(标签、标题、概要信息)来表征
4)、不同的协同行为类型(例如购买、评分、点击)设置不同的值setBoost
5)、搜索时候采用Lucene MoreLikeThis算法,将用户协同转化为内容相似度
以上方案只是基于Lucene来实现推荐引擎最为简单的实现方案,方案的准确度及细化方案以后再细说。
更为精细的实现,可以参考Mahout的算法实现来优化。
其他搜索引擎开源工具推荐:Sphinx,目前是基于出自俄罗斯的开源全文搜索引擎软件Sphinx,单一索引最大可包含1亿条记录,在1千万条记录情况下的查询速度为0.x秒(毫秒级)。Sphinx创建索引的速度为:创建100万条记录的索引只需3~4分钟,创建1000万条记录的索引可以在50分钟内完成,而只包含最新10万条记录的增量索引,重建一次只需几十秒。
Sphinx 是一个基于 GPL 2 协议颁发的免费开源的全文搜索引擎.它是专门为更好的整合脚本语言和SQL数据库而设计的.当前内置的数据源支持直接从连接到的 MySQL 或 PostgreSQL获取数据, 或者你可以使用 XML 通道结构(XML pipe mechanism , 一种基于 Sphinx 可识别的特殊xml格式的索引通道)
基于LAMP架构的应用很广泛,目前了解的商业应用有康盛的Discuz企业版。
、
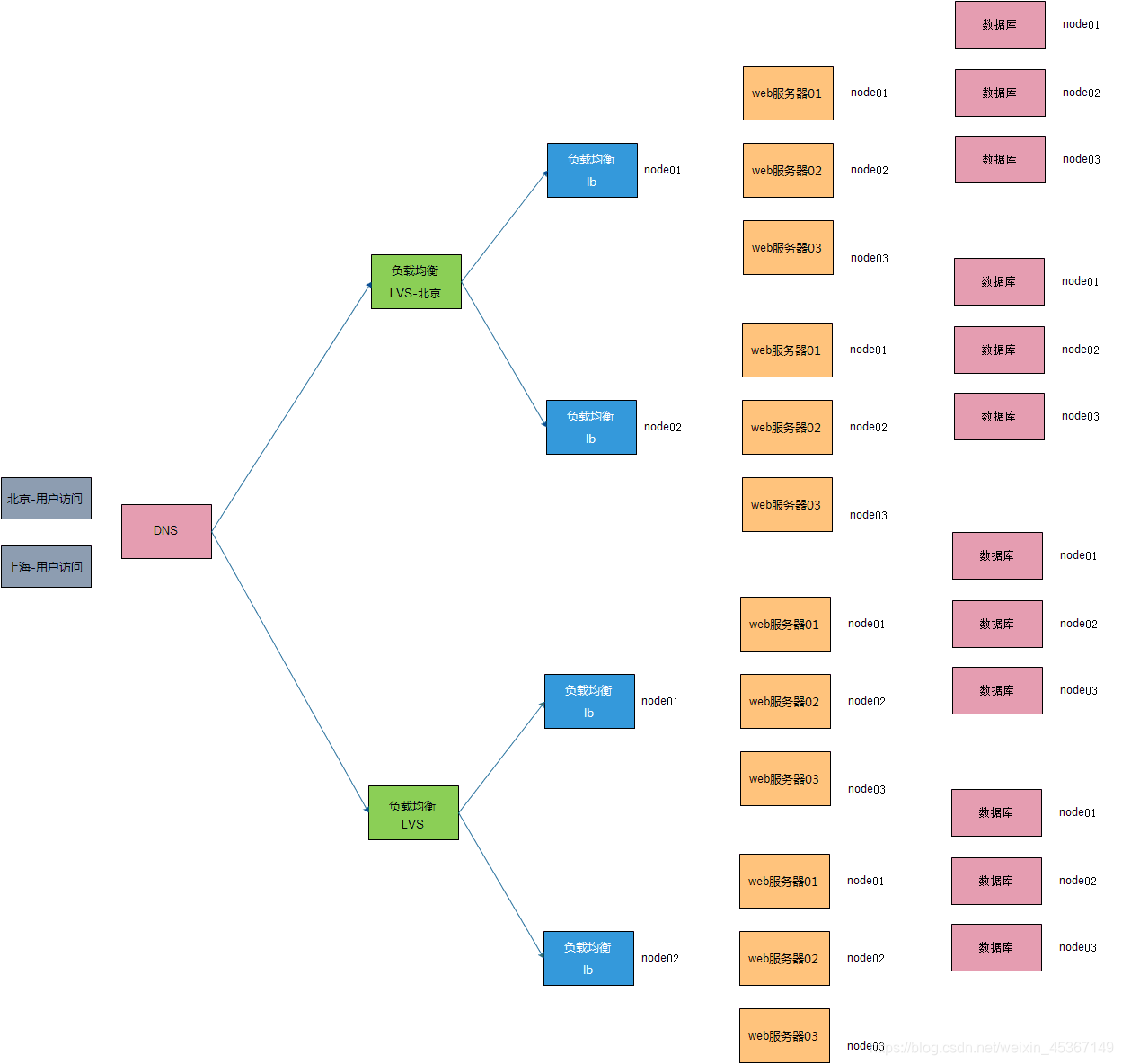
三、手机之家的搜索方案(参考用)
手机之家目前的Lucene应用,采用的是Lucene 2.4.1 + JDK 1.6(64 bit)的组合,运行在8 CPU, 32G内存的机器上,数据量超过3300万条,原始数据文件超过14G,每天需要支持超过35万次的查询,高峰时期QPS超过20。单看这些数据可能并没有大的亮点,但它的重建和更新都是自动化完成,而且两项任务可以同时运行,另一方面,在不影响服务可靠性的前提下,尽可能快地更新数据(如果两者发生冲突,则优先保证可用性,延迟更新),其中的工作量还是非常大的。
PPT连接 http://www.slideshare.net/tangfl/lucene-1752150
在大规模的应用中,Lucene更适合用于狭义的“搜索”,而不应当负责数据的存储。我们看看Lucene的源代码也可以知道,Document和Field的存储效率是不够好看的。手机之家的团队也发现了这一点,他们的办法是,用Lucene存放索引,用Memcache + Berkeley DB(Java Edition)负责存储。这样有两个好处,一是减轻了Lucene的数据规模,提高了程序的效率;另一方面,这套系统也可以提供某些类似SQL的查询功能。实际上,Lucene本身似乎也注意到了这个问题,在Store中新增了一个db的选项,其实也是利用的Berkeley DB。
在大规模应用中,Cache是非常重要的。PPT中也提到,可以在程序提供服务之前,进行几次”预热“搜索,填充Searcher的Cache。据我们(银杏搜索)的经验,也可以在应用程序中,再提供针对Document的Cache,这样对性能有较大的改善。Lucene自己似乎也注意到了这个问题,在2.4版本中提供了Cache,并提供了一个LRU Cache实现。不过据我们测试,在极端情况下,这个Cache可能会突破大小限制,一路膨胀最后吃光内存,甚至从网络上找的许多LRU Cache实现在极端条件下都有可能出现这样的问题,最终自己写了一个LRU Cache,并修改多次,目前来看是稳定的。
在编写Java服务程序的时候,记得设置退出的钩子函数(RunTime.getRunTime.addShutdownHook)是一个非常好的习惯。许多Java程序员都没有这种意识,或者有,也只是写一个finalize函数,结果程序非正常退出时,可能造成某些外部资源的状态不稳定。拿Lucene来说,之前的IndexWriter是默认autoCommit的,这样每添加一条记录,就提交一次,好处是如果中断,则之前添加的记录都是可用的,坏处则是,索引的速度非常低。在新版本中autoCommit默认为False,速度提升明显(我们测试的结果是,提高了大约8倍),但如果中途异常退出,则前功尽弃。如果我们添加了退出的钩子函数,捕获到退出信号则自动调用writer.close()方法,就可以避免这个问题。
目前的Lucene是兼容JDK 1.4的,它的binary版本也是JDK1.4编译的,如果对性能要求比较高,可以自行下载Lucene Source Code,用更新版本的JDK编译出.jar文件,据我测试,速度大约有30%的提升。
四、 XX网搜索方案
4.1 初步解决方案:
实现站内产品的分词搜索、推荐关键词和简单排序,定时自动更新,索引读写分离。
基于服务器的搜索压力大,用户的搜索体验不够有好,初步解决方案目标是解决服务器的搜索压力,实现初步的分词搜索,索引的自动定时维护。
4.1.1 数据库产品表分析:
l 大类基表
l 产品分类扩展基表
l 品牌基表,品牌系列表基表
l 产品基表(主表)
l 颜色基表
产品基表的数据大概在8万条左右,占用空间40m左右,单表数据量相对来书还是比较小的。
4.1.2 Lucene索引程序:
通过lucene的索引程序将库里的数据读入流,然后写入lucene自定义的索引文件,这个索引文件不进行搜索操作,需要完成后替换到搜索索引。在建立索引的过程中进行分词处理,分词组件采用eaglet开发的盘古分词组件(已基于apache开源协议开源,进一步功能需要自己二次开发)。
4.1.3 Lucene索引库:
基表的索引文件大概在100m左右,分为写入时的库和搜索时用的库,写入库完成后并入搜索库,考虑到新索引合覆盖就索引的瞬间可能产生的索引程序错误或者索引文件损坏,在覆盖的同时通过程序控制让搜索程序读取写索引里的文件。
l 搜索处理services:基于产品库的的搜索,如品牌,分类,价格区间。搜索程序依赖于接口,基于数据库的搜索和基于文件的搜索要按需要随时切换。搜索的同时需要利用分词组件分词处理,对分词后的结果进行检索,数据库检索的暂时不做分词处理。
l 查询处理:查询前台程序使用mvc,实现产品的分词高亮显示,按照类别分类查询,品牌分类查询,价格区间查询。

4.2 第二步关键词统计:
搜索关键词的搜集和搜索的联合处理,实现简单的搜索推荐功能。主要是对前台的搜索关键字进行统计分析,并与搜索的排序进行关联,关键词的处理和与主表的关联索引方案等初步处理完成后再做完整解决方案。

4.3 第三步优化完善:
实现索引文件的基于消息的增量自动更新,权重计算,推荐产品计算研究,实时搜索的研究。权重计算,需要重新开发自己的向量算法引擎,考虑当中。
实时搜索目前在学习当中。
4.3.1 权重计算
权重计算方法会将前台用户的统计数据和产品库进行关联开发一套天天网产品的权重排序计算方法,以下算法流程图只是一个构思。
 | |||
| |||
4.3.2 索引自动化更新
建立基于消息机制的一个索引更新与维护机制。
 | |||
| |||
作者:机器鸟
原文链接:http://www.jqpress.com/post/34.aspx
博客园同步更新:http://www.cnblogs.com/jqbird/
本文版权归作者博客和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。