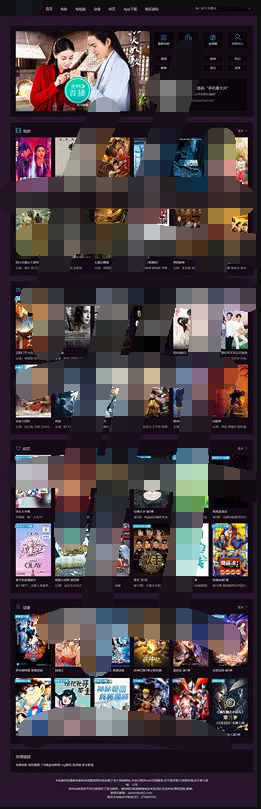
这次爬取网站为:‘http://www.agri.cn/kj/syjs/zzjs/’
程序大致分为六步:
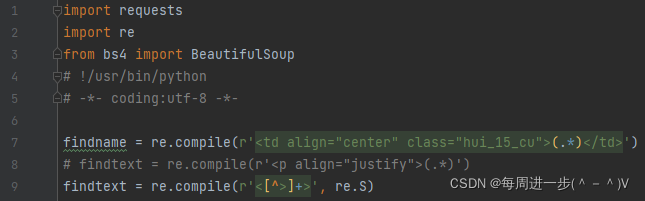
1、引入相关的库和设置两个正则表达式规则
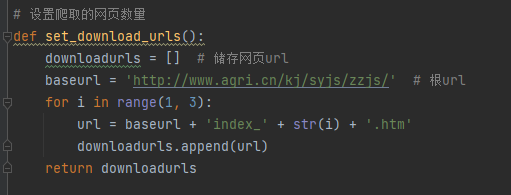
2、设置爬取的网页数量
3、设置网页中包含文章的HTML部分
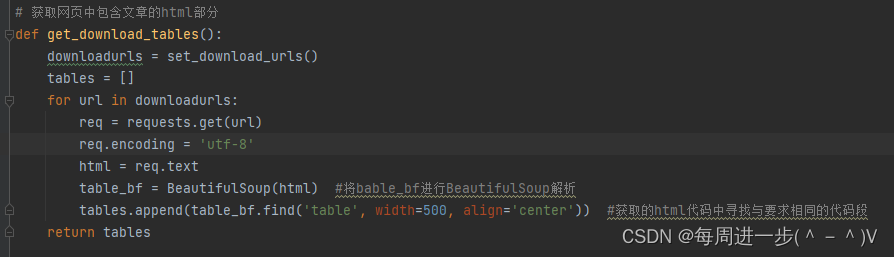
4、在获取的部分中提取包含文章连接的HTML语言
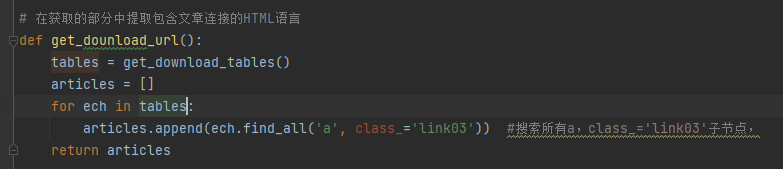
5、获取文章连接
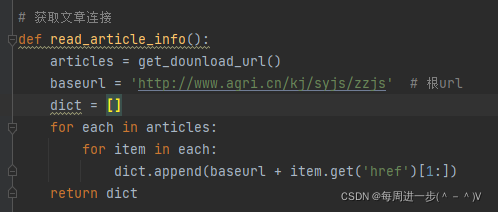
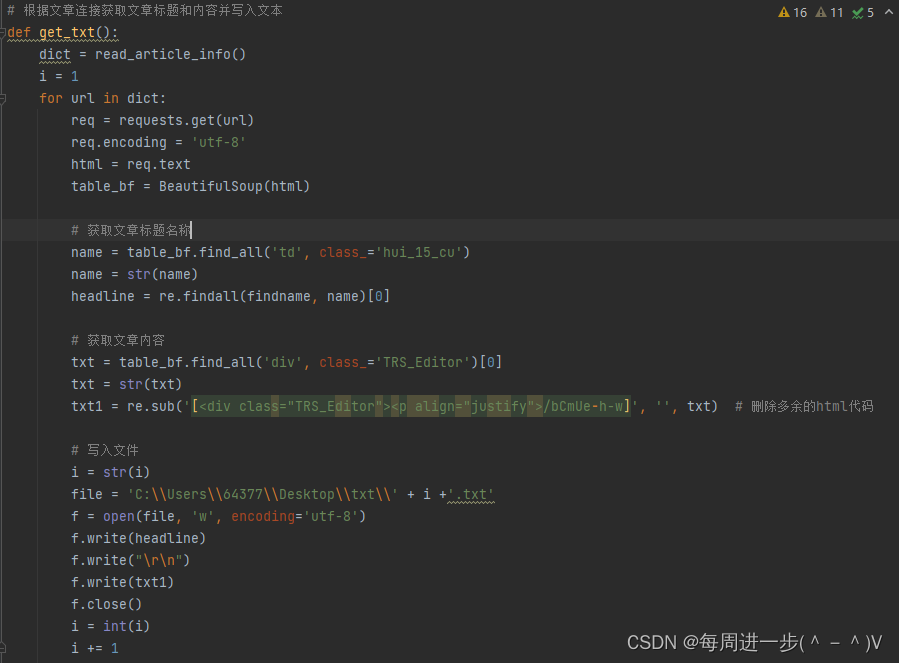
6、根据文章连接获取文章标题和内容并写入文本
结果演示:
将每一篇文章保存为txt一共爬取了30篇文章
所有代码:
import requests
import re
from bs4 import BeautifulSoup
# !/usr/bin/python
# -*- coding:utf-8 -*-findname = re.compile(r'<td align="center" class="hui_15_cu">(.*)</td>')
# findtext = re.compile(r'<p align="justify">(.*)')
findtext = re.compile(r'<[^>]+>', re.S)# 设置爬取的网页数量
def set_download_urls():downloadurls = [] # 储存网页urlbaseurl = 'http://www.agri.cn/kj/syjs/zzjs/' # 根urlfor i in range(1, 3):url = baseurl + 'index_' + str(i) + '.htm'downloadurls.append(url)return downloadurls# 获取网页中包含文章的html部分
def get_download_tables():downloadurls = set_download_urls()tables = []for url in downloadurls:req = requests.get(url)req.encoding = 'utf-8'html = req.texttable_bf = BeautifulSoup(html) #将bable_bf进行BeautifulSoup解析tables.append(table_bf.find('table', width=500, align='center')) #获取的html代码中寻找与要求相同的代码段return tables# 在获取的部分中提取包含文章连接的HTML语言
def get_dounload_url():tables = get_download_tables()articles = []for ech in tables:articles.append(ech.find_all('a', class_='link03')) #搜索所有a,class_='link03'子节点,return articles# 获取文章连接
def read_article_info():articles = get_dounload_url()baseurl = 'http://www.agri.cn/kj/syjs/zzjs' # 根urldict = []for each in articles:for item in each:dict.append(baseurl + item.get('href')[1:])return dict# 根据文章连接获取文章标题和内容并写入文本
def get_txt():dict = read_article_info()i = 1for url in dict:req = requests.get(url)req.encoding = 'utf-8'html = req.texttable_bf = BeautifulSoup(html)# 获取文章标题名称name = table_bf.find_all('td', class_='hui_15_cu')name = str(name)headline = re.findall(findname, name)[0]# 获取文章内容txt = table_bf.find_all('div', class_='TRS_Editor')[0]txt = str(txt)txt1 = re.sub('[<div class="TRS_Editor"><p align="justify">/bCmUe-h-w]', '', txt) # 删除多余的html代码# 写入文件i = str(i)file = 'C:\\Users\\64377\\Desktop\\txt\\' + i +'.txt'f = open(file, 'w', encoding='utf-8')f.write(headline)f.write("\r\n")f.write(txt1)f.close()i = int(i)i += 1
get_txt()
参考文章:https://www.cnblogs.com/liesun/p/10255045.html
最后有什么疑问欢迎扫描下方二维码提问!