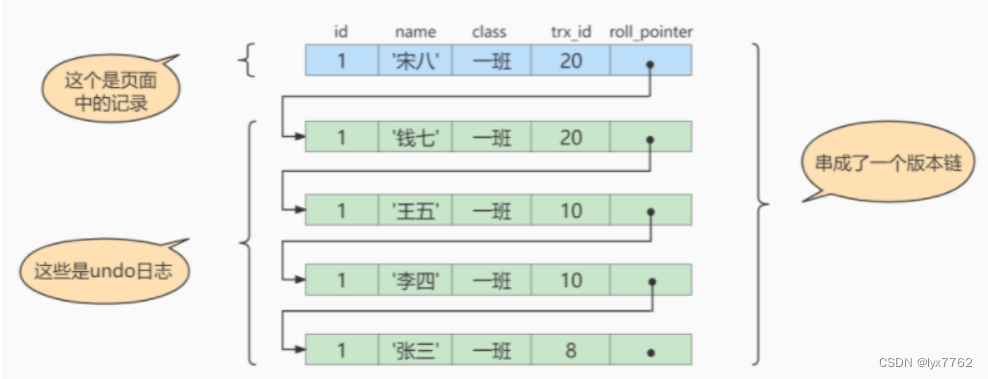
1 大数据亚线性空间算法
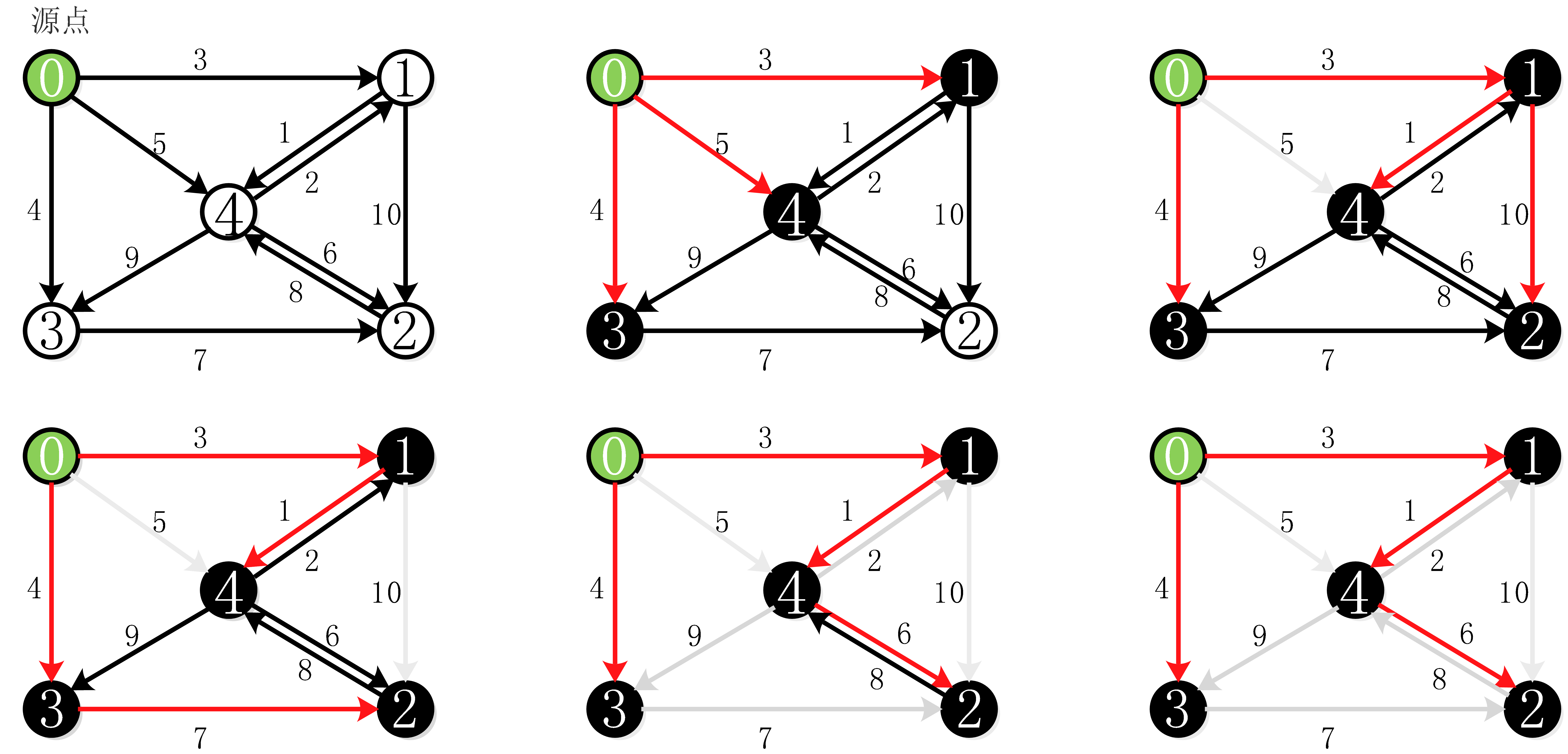
1.1 流模型的计数问题
问题定义?用什么算法?算法步骤?(提示:三层递进)
切比雪夫不等式?怎么证明?期望,方差,空间复杂度?
极其有限的空间存储极大的数目
morris,morris+,morris++
1/(2X)1/(2^X)1/(2X) => f^=(2X−1)\hat{f}=(2^X-1)f^=(2X−1)
E[γ]=NE[γ]=NE[γ]=N
D[γ]=N2−N2kD[γ]=\frac{N^2−N}{2k}D[γ]=2kN2−N。
P[∣γ−N∣≥ϵ]⩽N2−N2kϵ2P[|γ−N|≥ϵ]⩽\frac{N^2−N}{2kϵ^2}P[∣γ−N∣≥ϵ]⩽2kϵ2N2−N
1.2 不重复元素数
问题定义?用什么算法?算法步骤?
(提示:存储实数:三层递进 + 无法存储实数:1+1)
怎么证明?期望,方差,空间复杂度?
统计一个数据流的不重复元素数
FM,FM+
h:[n]↦[0,1]h:[n]↦[0,1]h:[n]↦[0,1] => z=min{z,h(i)}z=min\{z,h(i)\}z=min{z,h(i)} => 1z−1\frac{1}{z}-1z1−1
E[Z]=1d+1E[Z]=\frac{1}{d+1}E[Z]=d+11
var[Z]⩽2(d+1)(d+2)1q<2(d+1)(d+1)1qvar[Z]⩽\frac{2}{(d+1)(d+2)}\frac{1}{q}<\frac{2}{(d+1)(d+1)}\frac{1}{q}var[Z]⩽(d+1)(d+2)2q1<(d+1)(d+1)2q1
P[∣X−d∣>ϵ′d]<2q(2ϵ′+1)2P[|X−d|>ϵ'd]<\frac{2}{q}(\frac{2}{ϵ'}+1)^2P[∣X−d∣>ϵ′d]<q2(ϵ′2+1)2
FM’+
维护当前看到的最小的k个哈希值,返回kzk\frac{k}{z_k}zkk
PracticalFM
如果zeros(h(j))>zzeros(h(j))>zzeros(h(j))>z:z=zeros(h(j))z=zeros(h(j))z=zeros(h(j))
返回d^=2z+12\hat{d}=2^{z+\frac{1}{2}}d^=2z+21
E[Yr]=d2rE[Y_{r}] = \frac{d}{2 ^ r}E[Yr]=2rd
var[Yr]≤d2rvar[Y_{r}] \leq \frac{d}{2^r}var[Yr]≤2rd。
最终正确的概率应该大于1−22C1 - \frac{2\sqrt{2} }{C}1−C22。
BJKST
若zeros(h(j))>zzeros(h(j))>zzeros(h(j))>z
- B=B∪(g(j),zeros(h(j)))B=B∪(g(j),zeros(h(j)))B=B∪(g(j),zeros(h(j)))
- 若∣B∣>cϵ2|B| > \frac{c}{\epsilon^2}∣B∣>ϵ2c
- z=z+1z=z+1z=z+1
- 从B中删除(α,β)(α,β)(α,β),其中β<zβ<zβ<z
return d^=∣B∣2z\hat{d}=|B|2^zd^=∣B∣2z
1.3 点查询
问题定义?用什么算法?算法步骤?
空间复杂度?
计算流中所有的元素出现次数
Misra_Gries
维护一个集合A,其中的元素是(i,fi^)(i,\hat{f_{i} })(i,fi^)
A←∅A←∅A←∅
对每一个数据流中的元素e
if e∈A,令(e,fe^)→(e,fe^+1)(e,\hat{f_{e} }) \rightarrow (e,\hat{f_{e} } + 1)(e,fe^)→(e,fe^+1)
else if ∣A∣<1ϵ|A| < \frac{1}{\epsilon}∣A∣<ϵ1:将(e,1)插入A
else
- 将所有A中计数减1
- if fj^=0\hat{f_{j} } = 0fj^=0:从A中删除(j,0)
对于查询 i,如果i∈Ai∈Ai∈A,返回fi^\hat{f_{i} }fi^,否则返回0
空间代价是O(ϵ−1logn)O(\epsilon^{-1}logn)O(ϵ−1logn)
Metwally
- 对每一个数据流中的元素e
- if e∈A:令(e,fi^)←(e,fi^+1)(e,\hat{f_i})←(e,\hat{f_i}+1)(e,fi^)←(e,fi^+1)
- else if ∣A∣<1ϵ|A| < \frac{1}{\epsilon}∣A∣<ϵ1:将(e,1)插入A
- else 将(e,MIN+1)插入A,并删除一个满足fe^=MIN\hat{f_{e} } = MINfe^=MIN
- 查询 i,如果i∈Ai∈Ai∈A,返回fi^\hat{f_i}fi^,否则返回MIN
空间代价是O(ϵ−1logn)O(\epsilon^{-1}logn)O(ϵ−1logn)
Count-Min
随机选择 t 个2−wise独立哈希函数 hi:[n]→[k]h_i:[n]→[k]hi:[n]→[k]
对每一个出现的更新(j,c)进行如下操作
for i=1 to t
C[i][hi(j)]=C[i][hi(j)]+cC[i][h_{i}(j)] = C[i][h_{i}(j)] + cC[i][hi(j)]=C[i][hi(j)]+c
针对对于a的查询,返回 fa^=min1≤i≤tC[i][hi(a)]\hat{f_{a} } = \min_{1 \leq i \leq t}{C[i][h_{i}(a)]}fa^=min1≤i≤tC[i][hi(a)]
Count-Median(min变median)
Count Sketch
随机选择1个2−wise独立哈希函数h:[n]→[k]h:[n]→[k]h:[n]→[k]
随机选择1个2−wise独立哈希函数g:[n]→−1,1g:[n]→{−1,1}g:[n]→−1,1
对于每一个更新(j,c)
C[h(j)]=C[h(j)]+c∗g(j)C[h(j)] = C[h(j)] + c * g(j)C[h(j)]=C[h(j)]+c∗g(j)
针对查询a,返回f^=g(a)∗C[h(j)]\hat{f} = g(a) * C[h(j)]f^=g(a)∗C[h(j)]
Count Sketch+
(相当于是将Count Sketch算法运行了t次,最后取了中值)
随机选择1个2−wise独立哈希函数 hi:[n]→[k]h_i:[n]→[k]hi:[n]→[k]
随机选择1个2−wise独立哈希函数 gi:[n]→{−1,1}g_i:[n] \rightarrow \{-1,1\}gi:[n]→{−1,1}
对于每一个更新(j,c)
对于i:1→ti:1→ti:1→t
C[hi(j)]=C[hi(j)]+c∗gi(j)C[h_i(j)] = C[h_i(j)] + c * g_i(j)C[hi(j)]=C[hi(j)]+c∗gi(j)
返回f^=median1≤i≤tgi(a)C[i][hi(a)]\hat f=median_{1≤i≤t}g_i(a)C[i][h_i(a)]f^=median1≤i≤tgi(a)C[i][hi(a)]
1.4 频度矩估计
问题定义?用什么算法?算法步骤?
期望,方差,空间复杂度?
略
1.5 固定大小采样
问题定义?用什么算法?算法步骤?
期望,方差,空间复杂度?
水库抽样算法
- 使用数据流的前s个元素对抽样数组进行初始化
A[1,...,s],m←sA[1,...,s],m\leftarrow sA[1,...,s],m←s- 对于每一个更新x
- x以sm+1\frac{s}{m + 1}m+1s概率随机替换A中的一个元素
- m++
1.6 Bloom Filter
问题定义?用什么算法?算法步骤?
大数据集中划出一个小数据集,抽一个数,猜它是否属于小数据集
近似哈希
- 令H是一族通用哈希函数:[U]→[m],m=nδ[U]→[m],m = \frac{n}{\delta}[U]→[m],m=δn
- 随机选择 h∈H,并维护数组A[m],S的大小是n
- 对每一个 i∈S,A[h(i)]=1A[h(i)]=1A[h(i)]=1
- 给定查询q,返回yes当且仅当A[h(i)]=1A[h(i)]=1A[h(i)]=1
Bloom Filter
令H是一族独立的理想哈希函数:[U]→[m]
随机选取h1,...,hd∈Hh_1,...,h_d \in Hh1,...,hd∈H,并维护数组A[m]
对于每一个i∈S
对于每一个j∈[1,d]
A[hj(i)]=1A[h_j(i)] = 1A[hj(i)]=1
给定查询q,返回yes当且仅当∀j∈[d],A[hj(q)]=1\forall j \in [d],A[h_j(q)] = 1∀j∈[d],A[hj(q)]=1
2 大数据亚线性时间算法
2.1 求连通分量的数目
问题定义?用什么算法?算法步骤?
计算公式?时间复杂度?
如果搜索到的点的个数少于2ϵ\frac{2}{\epsilon}ϵ2就继续搜索,否则直接返回2ϵ\frac{2}{\epsilon}ϵ2。
从节点集合中随机选出r=b/ϵ2r = b/{\epsilon}^2r=b/ϵ2个节点构成节点U,对每个节点应用这个算法
最终的C^=nr∑u∈U1nu^\hat{C} = \frac{n}{r} \sum_{u \in U}{\frac{1}{\hat{n_u} } }C^=rn∑u∈Unu^1,时间复杂度为O(d/ϵ3)O(d/{\epsilon}^3)O(d/ϵ3)
2.2 近似最小支撑树
问题定义?用什么算法?算法步骤?
计算公式?时间复杂度?
G的子图G(i)=(V,E(i))G^{(i)}=(V,E^{(i)})G(i)=(V,E(i)),E(i)={(u,v)∣wuv≤i}E(i)=\{(u,v)|w_{uv}≤i\}E(i)={(u,v)∣wuv≤i},连通分量的个数为C(i)
M为所有这样的子图的连通分量的数目的和:M=n−w+∑i=1w−1C(i)M=n-w+\sum_{i=1}^{w-1}{C^{(i)} }M=n−w+∑i=1w−1C(i)
M=∑i=1wi⋅αi=∑i=1wαi+∑i=2wαi+⋯+∑i=wwαi=C(0)−1+C(1)−1+⋯+C(w−1)−1=n−1+C(1)−1+⋯+C(w−1)−1=n−w+∑i=1w−1C(i)\begin{align*} M &= \sum_{i=1}^{w}{i \cdot \alpha_i}=\sum_{i=1}^{w}{\alpha_i} + \sum_{i=2}^{w}{\alpha_i} + \dots + \sum_{i=w}^{w}{\alpha_i}\\ &= C^{(0)}-1 + C^{(1)}-1 + \dots + C^{(w-1)}-1\\ &= n-1+C^{(1)}-1 + \dots + C^{(w-1)}-1\\ &= n-w+\sum_{i=1}^{w-1}{C^{(i)} } \end{align*} M=i=1∑wi⋅αi=i=1∑wαi+i=2∑wαi+⋯+i=w∑wαi=C(0)−1+C(1)−1+⋯+C(w−1)−1=n−1+C(1)−1+⋯+C(w−1)−1=n−w+i=1∑w−1C(i)
2.3 求点集合的直径
问题定义?用什么算法?算法步骤?
计算公式?时间复杂度?
The Indyk’s Algorithm
- 任选k∈[1,m]k∈[1,m]k∈[1,m]
- 选出lll,使得∀i,Dki≤Dkl\forall i,D_{ki} \leq D_{kl}∀i,Dki≤Dkl
- 返回(k,l),Dkl(k,l),D_{kl}(k,l),Dkl
2.4 计算图的平均度算法
Alg III
- 从V中抽取样本S,∣S∣=O~(Lρϵ2),L=poly(lognϵ),ρ=1tϵ4⋅αn|S| = \tilde{O}(\frac{L}{\rho\epsilon^2}),L=poly(\frac{log\ n}{\epsilon}),\rho = \frac{1}{t}\sqrt{\frac{\epsilon}{4}\cdot \frac{\alpha}{n} }∣S∣=O~(ρϵ2L),L=poly(ϵlog n),ρ=t14ϵ⋅nα
- Si←S∩BiS_i \gets S \cap B_iSi←S∩Bi
- fori∈{0,…,t−1}do\boldsymbol{for}\ i \in \{0,\dots,t-1\}\ \boldsymbol{do}for i∈{0,…,t−1} do
- if∣Si∣≥θρthen\boldsymbol{if}\ |S_i| \geq \theta_\rho\ \boldsymbol{then}if ∣Si∣≥θρ then
- ρi←∣Si∣∣S∣\rho_i \gets \frac{|S_i|}{|S|}ρi←∣S∣∣Si∣
- estimateΔiestimate\ \Delta_iestimate Δi
- else\boldsymbol{else}else
- ρi←0\rho_i\gets 0ρi←0
- returndˉ^=∑i=0t−1(1+Δi)ρi(1+β)i\boldsymbol{return}\ \hat{\bar{d} } = \sum_{i=0}^{t-1}(1+\Delta_i)\rho_i(1+\beta)^{i}return dˉ^=∑i=0t−1(1+Δi)ρi(1+β)i
Alg IV
- α←n\alpha \gets nα←n
- dˉ^<−∞\hat{\bar{d} } < -\inftydˉ^<−∞
- whiledˉ^<αdo\boldsymbol{while}\ \hat{\bar{d} } < \alpha\ \boldsymbol{do}while dˉ^<α do
- α←α/2\alpha \gets \alpha/2α←α/2
- ifα<1nthen\boldsymbol{if}\ \alpha < \frac{1}{n}\ \boldsymbol{then}if α<n1 then
- return0;\boldsymbol{return}\ 0;return 0;
- dˉ^←AlgIII∼α\hat{\bar{d} } \gets AlgIII_{\sim \alpha}dˉ^←AlgIII∼α
- returndˉ^\boldsymbol{return}\ \hat{\bar{d} }return dˉ^
算法相关指标
近似比:(1+ϵ)(1 + \epsilon)(1+ϵ)
运行时间:O~(n)⋅poly(ϵ−1logn)n/dˉ\tilde{O}(\sqrt{n})\cdot poly(\epsilon^{-1}log\ n)\sqrt{n/\bar{d} }O~(n)⋅poly(ϵ−1log n)n/dˉ
3 并行计算算法
3.1 构建倒排索引
问题定义?Map函数做什么?Reduce函数做什么?
给定一组文档,统计每一个单词出现在哪些文件中
map:<docID,content>→<word,docID><docID,content> \rightarrow <word,docID><docID,content>→<word,docID>
reduce:<word,docID>→<word,listofdocID><word,docID> \rightarrow <word,list\ of\ docID><word,docID>→<word,list of docID>
3.2 单词计数
问题定义?Map函数做什么?Reduce函数做什么?
给定一组文档,统计每一个单词出现的次数
- Map函数:<docID,content>→<word,1>
- Reduce函数:<word,1>→<word,count>
3.3 检索
问题定义?
给定行号和相应的文档内容,统计指定单词出现的位置
- Map函数:<lineID,word>→<word,lineID><lineID,word>→<word,lineID><lineID,word>→<word,lineID>
- Reduce函数:<word,lineID>→<word,listoflineID>><word,lineID>→<word,list~of~ lineID>><word,lineID>→<word,list of lineID>>
3.4 矩阵乘法
问题定义?
两种算法:Map函数做什么?Reduce函数做什么?
- 矩阵乘法1
- Map:
- ((A,i,j),aij)→(j,(A,i,aij))
- ((B,j,k),bjk)→(j,(B,k,bjk))
- Reduce:(j,(A,i,aij)),(j,(B,k,bjk))→((i,k),aij∗bjk)
- Map:nothing(identity)
- Reduce:((i,k),(v1,v2,…))→((i,k),∑vi)
- 矩阵乘法2
Map函数:
- ((A,i,j),aij)→((i,x),(A,j,aij)) for all x∈[1,n]
- ((B,j,k),bjk)→((y,k),(B,j,bjk)) for all y∈[1,m]
Reduce函数:((i,k),(A,j,aij))∧((i,k),(B,j,bjk))→((i,k),∑aij∗bjk)
3.5 排序算法
Map函数做什么?Reduce函数做什么?解决问题的一个关键?
使用p台处理器,输入<i,A[i]><i,A[i]><i,A[i]>
Map:<i,A[i]>→<j,((i,A[i]),y)><i,A[i]> \rightarrow <j,((i,A[i]),y)><i,A[i]>→<j,((i,A[i]),y)>
输出<i%p,((i,A[i]),0)><i\%p,((i,A[i]),0)><i%p,((i,A[i]),0)>
以概率T/n为所有j∈[0,p−1]j ∈ [0, p − 1]j∈[0,p−1]输出<j,((i,A[i]),1)><j,((i,A[i]),1)><j,((i,A[i]),1)>
否则输出<j,((i,A[i]),0)><j,((i,A[i]),0)><j,((i,A[i]),0)>
Reduce:
- 将y=1的数据收集为S并排序
- 构造(s1,s2,...,sp−1)(s_1,s_2,...,s_{p−1})(s1,s2,...,sp−1),sks_ksk为S中第k⌈∣S∣p⌉k\left \lceil \frac{|S|}{p} \right \rceilk⌈p∣S∣⌉
- 将y=0的数据收集为D
- 对任意(i,x)∈D满足sk<x≤sk+1s_k < x \leq s_{k+1}sk<x≤sk+1,输出<k,(i,x)>
Map:nothing(identity)
Reduce:$ <j, ((i, A[i]), . . . )>$
- 将所有(i,A[i])(i, A[i])(i,A[i])根据$ A[i]$排序并输出
3.6 计算最小支撑树(生成树)
主要思想?Map函数做什么?Reduce函数做什么?
利用图划分算法,将图G划分成k个子图,在每个子图中计算最小生成树
算法的本质就是先在局部算好生成树,然后用剩余的连接这些生成树的边组成一个新的图,并求出这个新的图的最小生成树作为最总的结果
- Map:input:<(u,v),NULL>
- 转化<(h(u),h(v));(u,v)>
- 针对上述转化数据,如果h(u)=h(v),则对所有 j∈[1,k],输出<(h(u),j);(u,v)>
- Reduce:input:<(i,j);Eij>
- 令Mij=MSF(Gij)
- 对Mij中的每条边e=(u,v)输出<NULL;(u,v)>
- Map:nothing(identity)
- Reduce:M=MST(H)
4 外存模型算法
4.1 外存模型
在I/O模型中,内存的大小为___,页面大小为___,外存大小___。连续读取外存上的N个数据,需要多少次I/O?
M,B,无限,N/B
4.2 计算矩阵乘法
输入两个大小为N×N的矩阵X和Y
- 将矩阵分为大小为___的块
- 考虑X×Y矩阵中的每个块,显然共有___个块需要输出
- 每个块需要扫描___对输入块
- 每次内存计算需要___次I/O
- 共计___次I/O
M/2×M/2\sqrt{M}/2\times\sqrt{M}/2M/2×M/2
O((NM)2)O((\frac{N}{\sqrt{M} })^2)O((MN)2)
NM\frac{N}{\sqrt{M} }MN
O(M/B)
O((NM)3⋅M/B)O((\frac{N}{\sqrt{M} })^3\cdot M/B)O((MN)3⋅M/B)
4.3 数据结构
4.3.1 外存栈
内存维护大小为___的数组,实现内存栈结构,外存中存储其余数据
怎么压栈(push)?
怎么弹栈(pop)?
I/O代价分析:
▷ 最坏情况代价:O(1)次I/O
▷ 均摊代价(amortized analysis):___,最优
2B
没满就压,满了就外写后压
不空就弹,空了就读了再弹
O(1/B)
4.3.2 外存链表
队列(Queue)
▷ 内存维护2个大小为B的数组A和B,一个用于出队,一个用于入队
▷ A和B中分别存储?
▷ 外存中存储其余数据
如何处理队列操作?
▷ 入队(insert)?
▷ 出队(remove)?
I/O代价分析:
▷ 最坏情况代价:O(1)次I/O
▷ 均摊代价(amortized analysis):___,最优
k个队头数据和k′个队尾数据
B没满就入内存,满了就外写后再入内存
A没空就弹,空了就读了再弹
O(1/B)
4.3.3 链表
进行三种操作:insert(x,p),remove§,traverse(p,k)
-
想法二:块“半满”⇒数据至少B/2;
在外存模型下,将一个链表中连续的元素放在一个大小为B的块中。同时,令每个块大小至少为B/2:
▷ remove: 什么情况下合并?什么情况下均分?
▷ insert: 什么情况下均分?
▷ traverse: ___,insert和remove最坏情况代价为O(1)▷ 均摊代价:N次连续插入___,连续删除___
小于B/2,则与邻居块合并,合并后大于B则均分
大于B,平均划分
O(2k/B)
N次连续插入O(2N/B),连续删除O(log2B⋅N/B)O(log_2 B · N/B)O(log2B⋅N/B)
-
想法三:连续的两个块至少包含2B/3个数据;
连续的两个块至少包含2B/3个数据;内存维护大小为B缓冲区
▷ remove: 什么情况下合并?什么情况下均分?
▷ insert: 什么情况下合并?什么情况下均分?
▷ traverse: ___▷ 均摊代价:N次连续插入___,连续删除___
▷ 均摊代价:N次连续更新___
删除并检查是否有相邻块使得数据量 ≤ 2B/3,有则合并
若当前块满,向邻居插入;邻居均满,均分当前块
O(3k/B)
O(2N/B),O(3N/B)
O(12N/B)
4.4 搜索结构
进行三种操作:insert(x),remove(x),query(x)
(a,b)−tree:(a,b)-tree:(a,b)−tree: a与b的关系
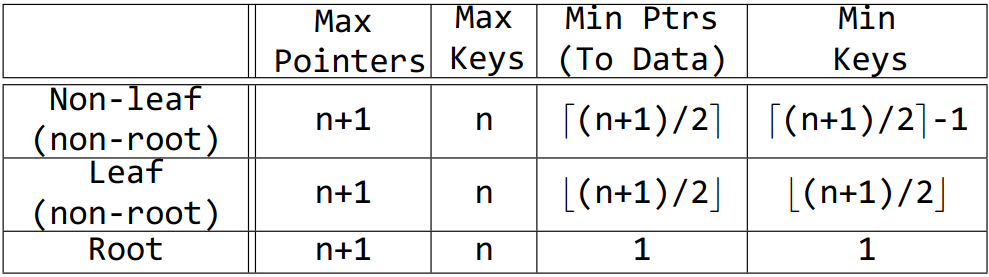
类似二分查找树⇒(p0,k1,p1,k2,p2,...,kc,pc)\Rightarrow (p_0, k_1, p_1, k_2, p_2, . . . , k_c, p_c)⇒(p0,k1,p1,k2,p2,...,kc,pc)
root节点有__个孩子;每个非叶子节点的孩子数目__:
- remove:怎么操作?
- insert:怎么操作?
- query:时间复杂度?
2 ≤ a ≤ (b + 1)/2
根节点有0或≥ 2个孩子,其它非叶子节点的孩子数目∈ [a, b]
删除后若小于a,与邻接块合并,合并后若大于b,平均划分
插入后若大于b,均分
$ O(log_a(N/a))$
插入操作
假设插入的键值为K,首先找到对应的叶结点L
-
如果L中有空闲空间,那么直接插入,结束;
-
否则将叶结点分裂为两个结点,并且把其中的键分到这两个新结点中,使得键个数满足最小要求;
-
当分裂叶结点N时:
▷创建一个新结点M,让M为N的右侧兄弟,将键排序,前⌈(n+1)/2⌉⌈(n+1)/2⌉⌈(n+1)/2⌉个留在N中,其他键‐指针放入M中。
-
当分裂非叶结点N时:
▷将键‐指针排序,前⌈(n+2)/2⌉⌈(n+2)/2⌉⌈(n+2)/2⌉个指针留在N中,剩下的⌊(n+2)/2⌋⌊(n+2)/2⌋⌊(n+2)/2⌋个指针放入M中。
▷前⌈n/2⌉⌈n/2⌉⌈n/2⌉个键留在N中,后⌊n/2⌋⌊n/2⌋⌊n/2⌋个键放入M中,中间那个键留出来,插入到上一层结点中,该键指针指向M。
-
删除操作
假设删除的键值为K,首先找到对应的叶结点L。
-
如果L中删除K后仍然具有满足最小要求的键个数,停止
-
否则需要做如下处理:
▷尝试与L的相邻兄弟节点之一合并(合并后仍能放入同一节点),合并后,相当于在上层结点删除了一个键值,那么递归处理;
▷否则,考虑L的相邻兄弟
- 假设其中一个能够提供L一个键‐指针,并且去除该键‐指针后该兄弟结点仍然满足键数的最小要求,那么L从该兄弟处借得一对键‐指针,并更新父节点的对应键值;
- 如果两个兄弟都无法提供一个键‐指针,那么必然是如下情况:L的键数少于最小数,L兄弟M的键数恰好为最小数,那么两个结点可以合并。
B+树–性能
结点中指针数目的最大值:n,记录条数:N
B+Tree的插入操作:O(log⌈n/2⌉(N))O(log_{⌈n/2⌉}(N))O(log⌈n/2⌉(N))
B+Tree的删除操作:O(log⌈n/2⌉(N))O(log_{⌈n/2⌉}(N))O(log⌈n/2⌉(N))
4.5 外存排序
▷ 给定__个数据
▷ 分成大小为__的组,每组可在内存排序,需要__次I/O
▷ 排好序的分组,进行归并(Merge)
▷ 每次可以归并__个分组
▷ I/O代价:
▷ 画图理解
N
O(M),O(M/B)
O(M/B)
O(N/B⋅logM/BNB)O(N/B · log_{M/B} \frac{N}{B} )O(N/B⋅logM/BBN)或O(N/B⋅logM/BNM)O(N/B · log_{M/B} \frac{N}{M} )O(N/B⋅logM/BMN)(存疑)
4.6 List Ranking
问题定义?(两个问题)
算法?(四个步骤)
给定大小为N的邻接链表L,L存储在数组(连续的外存空间)中,计算每个节点的rank(在链表中的序号)
输入大小为N的外存链表L
- 寻找L中的一个顶点独立集 X
- 将X中的节点“跳过”,构建新的、更小的外存链表L′
- 递归地求解L′
- 将X中的节点“回填”,根据L′的rank构建L的rank