出现OOM, 有两种处理方式:1. 主动Kill; 2. 被动Kill
例:HBase Region Server OOM定位问题复盘
现象
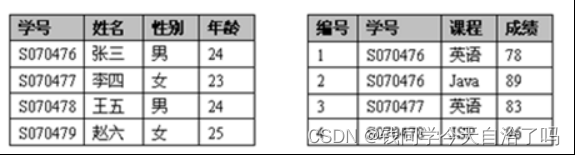
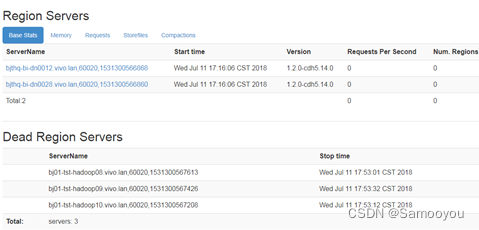
在HBase资源隔离项目中,对测试集群进行压测时,发现region server会出现崩溃的情况,单机请求量从>200到~50每秒都有可能出现。
当压测的同时,进行在rsgroup间转移server或者table时出现概率更高。
Region server死掉后,webUI上可见许多Region in Transition错误,重启region server及master后才能恢复。
经查,在CM的日志页没有任何日志,只显示unknown error。
登上物理机,查看region server的日志也没有发现。
系统日志(/var/log/messages)也看不到可能的OOM日志。
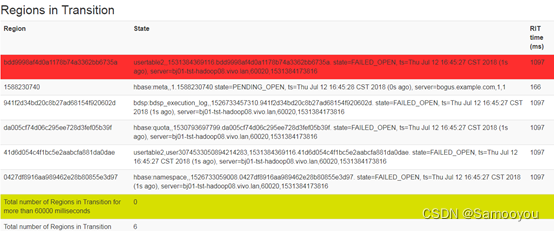
根本原因
最终发现还是因为OOM被干掉了,因为5台机器中有3台region server的heap size只设置了50M(后加入的两台是32G)

在/tmp下面生成了转储文件
![]()
改大到32G后,再进行压测没有出现崩溃问题了。
如何更好地发现?
之前因为没有日志,所以感觉无从下手,后来找到/tmp下的hprof文件才发现配置的问题。
进程崩溃,没有日志 –> 可以怀疑出现了OOM。
出现OOM, 有两种处理方式:1. 主动Kill; 2. 被动Kill
(1) 主动Kill
比如这次的场景就是,启动region server时告诉JVM内存限制是50M, 超过50M就主动kill掉。
这种情况不是系统kill, 是JVM的操作,所以不会记录到系统日志(/var/log/messages)中。
这种情况是会产生下面的日志的:
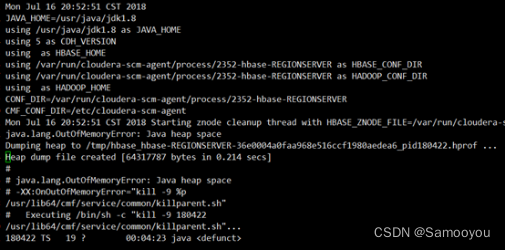
但是比较坑的是,上述日志不是出现在RegionServer的日志文件里,而是在out文件里。
又因为region server会自动拉起,CM页面上的out内容被新的进程冲掉,所以无法在CM上看到这些内容。
CDH把这些日志藏在这个路径里,很难找到:
/var/run/cloudera-scm-agent/process/*-hbase-REGIONSERVER/logs/stdout.log
其中的*为一个数字,不是挂掉的进程PID, 可以根据目录的时间戳和崩溃时间对应下。

(2) 被动Kill
如果是被系统杀掉,发生的场景会是RegionServer没有OOM,但是操作系统内存不够用了,于是OS会选择kill一些进程。
看/var/log/messages, 会发现如下日志:
kernel: Out of memory: Kill process 38551 (java) score 501 or sacrifice child
kernel: Killed process 38551, UID 483, (java) total-vm:17538500kB, anon-rss:16420056kB, file-rss:28kB
kernel: java invoked oom-killer: gfp_mask=0x201da, order=0, oom_adj=0, oom_score_adj=0
上述日志表明:RegionServer进程(38551)被kill了。
注意:total-vm:17538500kB, anon-rss:16420056kB应该是它占用的内存,而不是已经使用的内存。
如果没有搞清楚这个区别,你可能会以为RegionServer已经超过max-heap-size了,那么kill就应该变成主动了。
如何避免?
- 测试前检查核心配置

不能因为之前在用就掉以轻心。
总结
因为内存资源配置原因,导致hbase集群压测时出现崩溃异常,并且看不到有效日志。本文总结了OOM出现后的排查手段,以及避免方法。