深度学习之“制作自定义数据”–torch.utils.data.DataLoader重写构造方法。
前言:
本文讲述重写torch.utils.data.DataLoader类的构造方法,对自定义图片制作类似MNIST数据集格式(image, label),用于自己的Pytorch神经网络模型运行,代码已整理打包上传网盘,文末下载。tensor数据格式(N,C,H,W)
-
N:Batch,批处理大小,表示一个batch中的图像数量
-
C:Channel,通道数,表示一张图像中的通道数
-
H:Height,高度,表示图像垂直维度的像素数
-
W:Width,宽度,表示图像水平维度的像素数
-
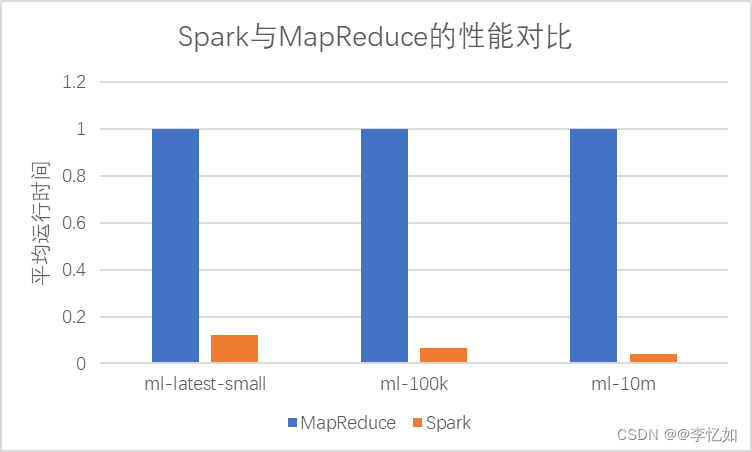
例如下图输出一个批次的训练集数据就是一批次64张图片(N),3维通道数(C),一张图片高度32像素(H),一张图片宽度32像素(W)

步骤一
对图片整理分类(python代码os库进行对文件夹创建和图片的移动到文件夹),以文件夹名为图片的种类名,如下图所示:

步骤二
对所有种类文件夹进行遍历读入,将每个(图片的文件路径 )和(对应的标签)写入到txt文本中,结果为trian.txt 和 test.txt,作为训练集合测试集的数据准备。代码为CreateDataset01.py
# -*- coding: utf-8 -*-
# @Time : 2023/1/26/026 18:48
# @Author : LeeSheel
# @File : CreateDataset01.py
# @Project : 深度学习'''
生成训练集和测试集,保存在txt文件中本地电脑,只选取出3000张图片为训练集进行模型运行数据
'''import os
import random
train_ratio = 0.6
test_ratio = 1-train_ratio
train_list, test_list = [],[] #创建两个个列表,里面存放 图片路径+‘\t’+图片标签
data_list = []rootdata = r"D:\FreeDesk\大创项目\手写藏文字母识别\手写藏文字母数据\总数据"for root,dirs,files in os.walk(rootdata):# print(root)# print(dirs)# print(files)#拼接每个图片的绝对文件路径:for i in range(int(len(files)*train_ratio)):# print(files[i])#输出的是每个图片的名称# print(root+"---"+files[i]) #shu输出每个每个图片的文件夹路径----图片名称# print(os.path.join(root, files[i])) #拼接路径,# print(str(root).split("/")[-1]) #dui对root进行字符串切割,获得最后一个元素,代表每个图片的标签。class_flag = str(root).split("\\")[-1] #biaoqain标签data = os.path.join(root, files[i]) + '\t' + str(class_flag) + '\n'train_list.append(data)for i in range(int(len(files) * train_ratio),len(files)):# print(i)class_flag = str(root).split("\\")[-1] # biaoqain标签# print(class_flag)# print(files[i])data = os.path.join(root, files[i]) + '\t' + str(class_flag) + '\n'test_list.append(data)# print(train_list)
random.shuffle(train_list)
random.shuffle(test_list)with open('train.txt','w',encoding='UTF-8') as f:for train_img in train_list:f.write(str(train_img))with open('test.txt','w',encoding='UTF-8') as f:for test_img in test_list:f.write(test_img)## 随机抽取3000个作为本地train.txt 以及1000个作为本地test.txt# from random import sample
#
# print(sample(train_list, 30000)) # 随机抽取5个元素
# local_train_list = sample(train_list, 30000)
# print("dsdfsdfs")
# print(len(local_train_list))
# local_test_list = sample(test_list, 10000)
#
# with open('localtrain.txt','w',encoding='UTF-8') as f:
# for train_img in local_train_list:
# f.write(str(train_img))
#
# with open('localtest.txt','w',encoding='UTF-8') as f:
# for test_img in local_test_list:
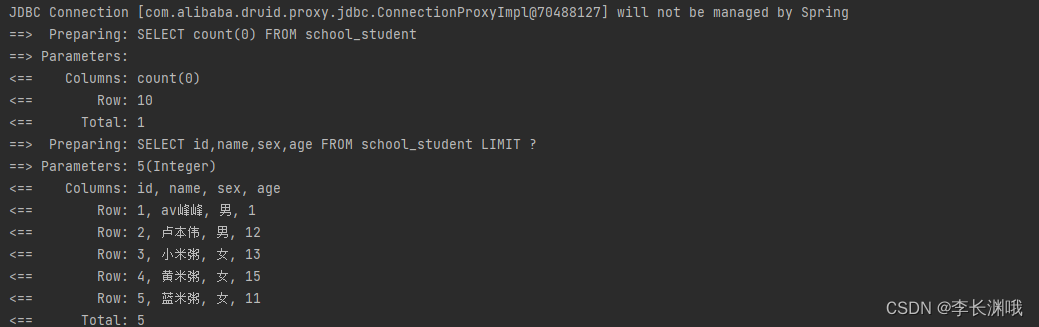
# f.write(test_img)得到txt结果:(文件路径与标签以空格隔开):

步骤三
将步骤二得到的train.txt 和 test.txt 转化为train_loader 和 test_loader,重写LoadData类的构造方法,将train.txt文本转为train_dataset ,将test.txt转为test_dataset,最后再使用torch.utils.data.DataLoader()进行转为train_loader 和 test_loader: 就可以用于调用模型训练了。
train_loader = torch.utils.data.DataLoader(dataset=train_dataset,batch_size=64,shuffle=True)
test_loader = torch.utils.data.DataLoader(dataset=test_dataset,batch_size=64,shuffle=True)重写LoadData类的构造方法代码(这里的transforms.Normalize()图像标准化,可以使用下文的python代码求出mean和std,填入标准化数值。),步骤三代码为 CreateDataloader02.py:
# -*- coding: utf-8 -*-
# @Time : 2023/1/26/026 18:56
# @Author : LeeSheel
# @File : CreateDataloader02.py
# @Project : 深度学习
import torch
from PIL import Image
import torchvision.transforms as transforms
from PIL import ImageFile
ImageFile.LOAD_TRUNCATED_IMAGES = True
from torch.utils.data import Datasetclass LoadData(Dataset):def __init__(self, txt_path, train_flag=True):self.imgs_info = self.get_images(txt_path)self.train_flag = train_flagself.train_tf = transforms.Compose([# 随机旋转图片transforms.RandomHorizontalFlip(),# 将图片尺寸resize到32x32transforms.Resize((32, 32)),# 将图片转化为Tensor格式transforms.ToTensor(),# 正则化(当模型出现过拟合的情况时,用来降低模型的复杂度)transforms.Normalize((0.96934927, 0.9696228, 0.9695143), (0.124204025, 0.12326231, 0.12356147)) # 图像标准化])self.val_tf = transforms.Compose([# 将图片尺寸resize到32x32transforms.Resize((32, 32)),transforms.ToTensor(),transforms.Normalize((0.96934927, 0.9696228, 0.9695143), (0.124204025, 0.12326231, 0.12356147))])def get_images(self, txt_path):with open(txt_path, 'r', encoding='utf-8') as f:imgs_info = f.readlines()imgs_info = list(map(lambda x:x.strip().split('\t'), imgs_info))return imgs_infodef __getitem__(self, index):img_path, label = self.imgs_info[index]img = Image.open(img_path)img = img.convert('RGB')if self.train_flag:img = self.train_tf(img)else:img = self.val_tf(img)label = int(label)return img, labeldef __len__(self):return len(self.imgs_info)train_dataset = LoadData("train.txt", True)print("训练接数据个数:", len(train_dataset))
train_loader = torch.utils.data.DataLoader(dataset=train_dataset,batch_size=64,shuffle=True)
for image, label in train_loader:print(image.shape)print(image)# img = transform_BZ(image)# print(img)print(label)breaktest_dataset = LoadData("test.txt", False)
print("测试集数据个数:", len(test_dataset))
test_loader = torch.utils.data.DataLoader(dataset=test_dataset,batch_size=64,shuffle=True)
求图片标准化transforms.Normalize()参数 代码
# -*- coding: utf-8 -*-
# @Time : 2023/1/31/031 18:18
# @Author : LeeSheel
# @File : 计算std和mea.py
# @Project : 深度学习
import numpy as np
import cv2
import os# img_h, img_w = 32, 32
img_h, img_w = 32, 32 # 经过处理后你的图片的尺寸大小
means, stdevs = [], []
img_list = []imgs_path = "D:\\0" # 数据集的路径采用绝对引用
imgs_path_list = os.listdir(imgs_path)len_ = len(imgs_path_list)
i = 0
for item in imgs_path_list:img = cv2.imread(os.path.join(imgs_path, item))img = cv2.resize(img, (img_w, img_h))img = img[:, :, :, np.newaxis]img_list.append(img)i += 1print(i, '/', len_)imgs = np.concatenate(img_list, axis=3)
imgs = imgs.astype(np.float32) / 255.for i in range(3):pixels = imgs[:, :, i, :].ravel() # 拉成一行means.append(np.mean(pixels))stdevs.append(np.std(pixels))# BGR --> RGB , CV读取的需要转换,PIL读取的不用转换
means.reverse()
stdevs.reverse()print("normMean = {}".format(means))
print("normStd = {}".format(stdevs))
代码下载:
链接:https://pan.baidu.com/s/1fa_gdLYXagu65P2uYpepqA?pwd=xx78
提取码:xx78