本文的源代码摘自编译器龙书《Compilers : principles, techniques, and tools》第二版的附录A“一个完整的前端”(A Complete Front End)。
上述书中的编译器是在Unix系统中,主体代码与书中相同,只是对字符串处理不同;本例中使用Java类将文本文件内容读取到一个字符串中,然后进行语法分析和代码生成。
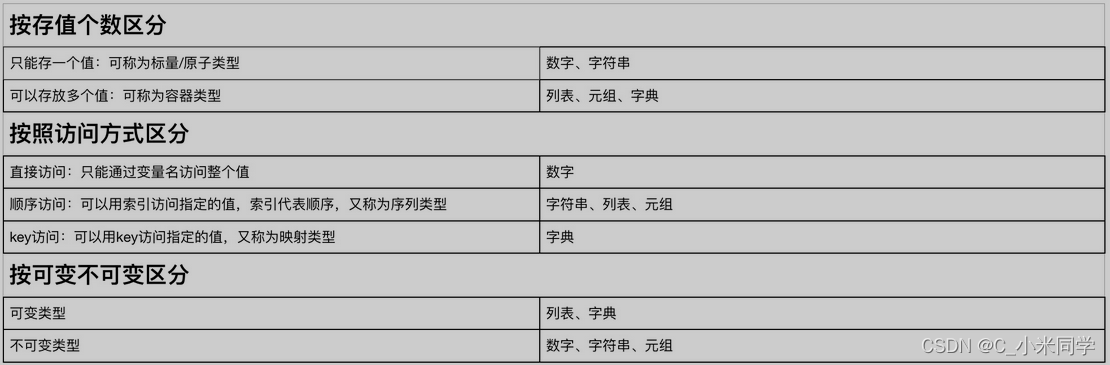
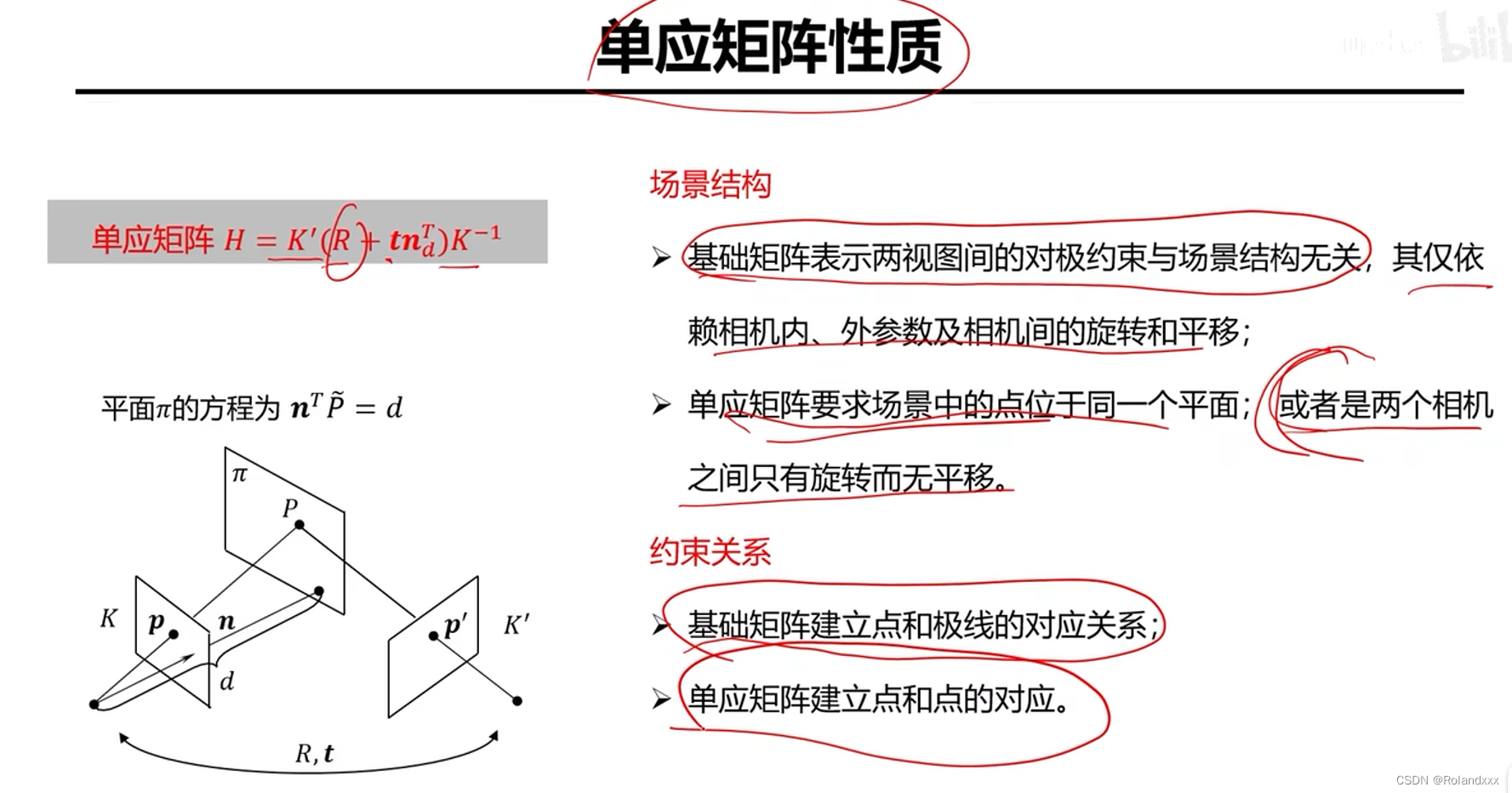
源语言的产生式



Main.java (主程序)
package main ; // File Main.java
import lexer.*; import parser.*;
import java.io.File;
import java.io.IOException;
import java.util.Scanner;
public class Main
{
public static void main(String [] args) throws IOException {
if(args.length == 0){
System.out.println("need a file name.");
return;
}
String fileName = args[0];
Scanner sc = new Scanner(new File(fileName));
String input;
StringBuffer sb = new StringBuffer();
while (sc.hasNextLine()) {
input = sc.nextLine();
sb.append(input+'\n');
}
//System.out.println("Contents of the file are: "+sb.toString());
System.out.println("create a Lexer");
Lexer lex = new Lexer() ;
lex.setCodes(sb.toString()); // 设置源代码字符串.
System.out.println("create a Parser");
Parser parse = new Parser(lex) ;
System.out.println("run parse.program()\n");
parse.program() ;
System.out.write('\n');
}
}
词法分析器包
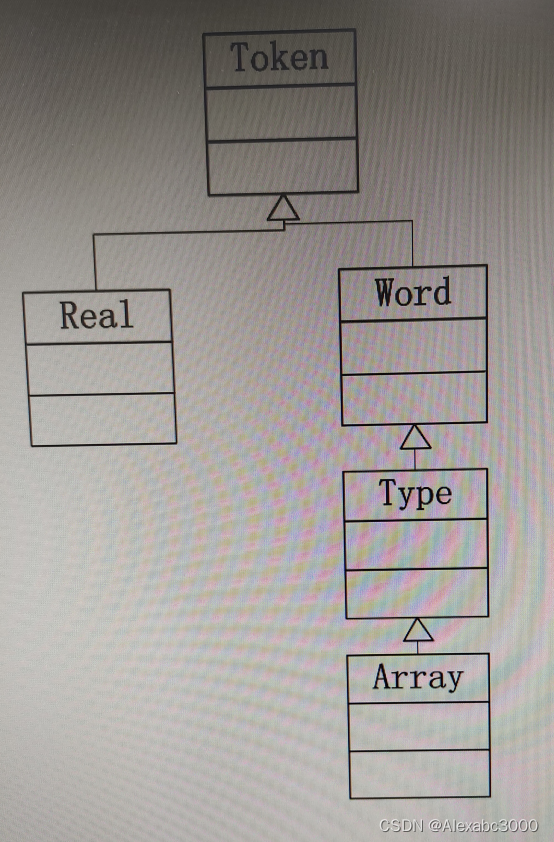
词法分析器以源代码作为输入,逐字符(一个字符一个字符地)分析源程序,将源程序转换为记号(token)流(也可成为记号集合、或者记号序列),每一个都应该属于一个类,有一个值(大部分记号都有值,也有部分记号没有值,比如加法或减法等运算符就没有值)。
Tag.java(标签类)
package lexer ; // File Tag.java
public class Tag {
public final static int
AND = 256 , BASIC = 257, BREAK = 258, DO = 259 , ELSE = 260 ,
EQ = 261 , FALSE = 262, GE = 263 , ID = 264 , IF = 265 ,
INDEX = 266,LE = 267, MINUS = 268 , NE = 269 , NUM = 270 ,
OR = 271, REAL = 272, TEMP = 273 , TRUE = 274 , WHILE = 275 ;
}
Token.java(记号类)
package lexer ; // File Token.java
public class Token{
public final int tag; // 记号所属类别的编号.
public Token(int t) { tag = t; }
public String toString() {return "" + ( char) tag;}
}
Num.java(数字记号类)
package lexer; // File Num.java
public class Num extends Token {
public final int value; // 数字记号的值(即token的值).
public Num(int v) { super(Tag.NUM); value = v; }
public String toString() { return "" + value; }
}
Word.java(单词记号类)
package lexer; // File Word.java
public class Word extends Token {
public String lexeme = ""; // 词素
// s相当于token(记号)的值,tag相当于token所属的类别的编号.
public Word(String s, int tag) { super(tag); lexeme = s; }
public String toString() { return lexeme; }
public static final Word
and = new Word( "&&", Tag.AND ), or = new Word( "||", Tag.OR ),
eq = new Word( "==" , Tag.EQ ), ne = new Word ( "!=" , Tag.NE ),
le = new Word ( "<=" , Tag.LE ), ge = new Word( ">=" , Tag.GE ),
minus = new Word ( "minus", Tag.MINUS ),
True = new Word ( "true" , Tag.TRUE ),
False = new Word( "false" , Tag.FALSE ),
temp = new Word( "t" , Tag.TEMP );
}
Real.java(实数记号类)
package lexer ; // File Real.java
public class Real extends Token {
public final float value;
public Real(float v) { super (Tag.REAL); value = v; }
public String toString(){ return "" + value;}
}
Lexer.java(词法分析器类)
package lexer; // File Lexer.java
import java.io.*;
import java.nio.file.Files;
import java.util.*;
import symbols.*;
public class Lexer {
public static int line = 1;
char peek = ' ';
// (单词)记号表(词法分析器的输出)
Hashtable<String, Word> words = new Hashtable<String, Word>();
// 源代码.
String codes;
int codeIndex = 0;
// 设置源代码字节
public void setCodes(String s){
codes = s+'#'; // 使用‘#’替代文件结束符.
codeIndex = 0;
}
// 向单词记号表中添加一个单词记号. 以单词的词素作为哈希表的键
void reserve (Word w) {words.put(w.lexeme, w) ; }
public Lexer() {
// 初始化时向记号表中添加若干关键字
reserve ( new Word("if" , Tag.IF));
reserve ( new Word("else" , Tag.ELSE));
reserve ( new Word( "while", Tag.WHILE) ) ;
reserve ( new Word ("do", Tag.DO));
reserve ( new Word ("break" , Tag.BREAK));
reserve ( Word.True); reserve ( Word.False ) ;
reserve ( Type.Int); reserve ( Type.Char);
reserve ( Type.Bool ) ; reserve ( Type.Float);
}
//void readch() throws IOException {peek = (char)System.in.read(); }
void readch() throws IOException {
peek = codes.charAt(codeIndex++);
//System.out.println(codeIndex-1 + ": peek is " + peek);
}
boolean readch( char c) throws IOException {
readch();
if ( peek != c ) return false ;
peek = ' ' ;
return true ;
}
public Token scan() throws IOException {
for( ; ; readch() ){// 处理空白字符
if ( peek == ' ' || peek == '\t' ) continue;
else if ( peek == '\n' ) line = line + 1;
else break;
}
switch ( peek ){// 处理双字符运算符
case '&' :
if (readch('&')) return Word.and ; else return new Token ('&');
case '|':
if (readch('|')) return Word.or; else return new Token ('|');
case '=' :
if (readch('=')) return Word.eq; else return new Token ('=');
case '!' :
if (readch('=')) return Word.ne; else return new Token ('!');
case '<' :
if (readch('=')) return Word.le; else return new Token ('<');
case '>' :
if (readch('=')) return Word.ge; else return new Token ('>');
}
if (Character.isDigit(peek)){ // 处理数字
int v = 0;
do{
v = 10*v + Character.digit(peek , 10); readch( );
}while( Character.isDigit(peek));
if ( peek != '.' ) return new Num(v);
float x = v; float d = 10;
for( ; ; ) {
readch();
if ( !Character.isDigit(peek) ) break;
x = x + Character.digit(peek , 10)/d; d = d*10;
}
return new Real(x) ;
}
if(Character.isLetter(peek)){// 处理标识符符(单词)
StringBuffer b = new StringBuffer( );
do{
b.append(peek); readch();
}while ( Character.isLetterOrDigit(peek));
String s = b.toString();
Word w = (Word)words.get(s);// 在哈希表(单词记号表)中查找s对应的单词
if ( w != null ) return w; // 若找到则返回w,否则添加新的单词.
w = new Word(s , Tag.ID) ;
words.put(s, w);
return w;
}
// 剩余的字符作为标记返回.
Token tok = new Token(peek) ; peek = ' ';
return tok;
}
}
将原书中的
Hashtable words = new Hashtable ( ) ;
改为
Hashtable<String, Word> words = new Hashtable<String, Word>();
目的是为了消除Java编译器的警告信息:“警告: [unchecked] 对作为原始类型Hashtable的成员的put(K,V)的调用未经过检查”。
Symbol Tables and Types(符号表与类型包)
Env.java(环境类)
package symbols ; // File Env.java
import java.util.*; import lexer.*; import inter.*;
public class Env {
private Hashtable<Token, Id> table;
protected Env prev;
public Env(Env n) {table = new Hashtable<Token, Id>(); prev = n;}
public void put(Token w, Id i) { table.put(w, i); }
public Id get(Token w){
for(Env e = this ; e != null ; e = e.prev ) {
Id found = (Id)(e.table.get (w));
if ( found != null ) return found;
}
return null ;
}
}
Type.java(类型类)
package symbols ; // File Type.java
import lexer.*;
public class Type extends Word{ // 类型类是单词记号类的子类
public int width = 0; // width is used for storage allocation. 类型所占字节数
public Type(String s, int tag , int w) { super(s, tag) ; width = w; }
public static final Type
Int = new Type ( "int", Tag.BASIC , 4 ), // 基本类型
Float = new Type ( "float", Tag.BASIC , 8 ) ,
Char = new Type ( "char" , Tag.BASIC , 1 ),
Bool = new Type ( "bool" , Tag.BASIC , 1 );
public static boolean numeric(Type p){// p是否是数字类型的实例
if(p == Type.Char || p == Type.Int || p == Type.Float) return true;
else return false ;
}
public static Type max(Type p1, Type p2 ){// 占用空间的最大值
if ( !numeric(p1) || !numeric (p2) ) return null;
else if ( p1 == Type.Float || p2 == Type.Float ) return Type.Float;
else if ( p1 == Type.Int || p2 == Type.Int ) return Type.Int;
else return Type.Char ;
}
}
Array.java(数组类型)
package symbols ; // File Array.java
import lexer.*;
public class Array extends Type{
public Type of; // array *of* type
public int size = 1; // number of elements
public Array(int sz, Type p) {
super ( "[]", Tag.INDEX , sz*p.width) ; size = sz ; of = p;
}
public String toString(){ return "[" + size + "] " + of.toString(); }
}
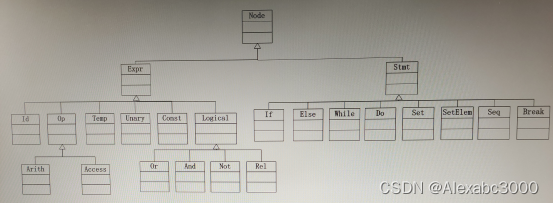
Intermediate Code for Expressions(表达式中间码)
Node.java(结点类)
package inter ; // File Node.java
import lexer.*;
public class Node {
int lexline = 0;
Node() { lexline = Lexer.line; }
void error (String s) { throw new Error("near line " + lexline + ": " + s); }
static int labels = 0;
public int newlabel() { return ++labels; }
public void emitlabel(int i) { System.out.print ( "L" + i + ":" ); }
public void emit (String s) { System.out.println( "\t" + s) ; }
}
Expr.java(表达式结点类)
package inter ; // File Expr.java
import lexer.*; import symbols.*;
public class Expr extends Node {
public Token op;
public Type type;
Expr(Token tok , Type p) { op = tok ; type = p; }
public Expr gen(){ return this; }
public Expr reduce() { return this; }
public void jumping(int t, int f){ emitjumps(toString(), t, f ); }
public void emitjumps(String test , int t, int f) {
if( t != 0 && f != 0 ){
emit ("if " + test + " goto L" + t ) ;
emit ("goto L" + f );
}
else if (t != 0 ) emit("if " + test + " goto L" + t ) ;
else if (f != 0 ) emit (" iffalse " + test + " goto L" + f ) ;
else ; // nothing s ince both t and f fall through
}
public String toString() { return op.toString() ; }
}
Id.java(标识符结点类)
package inter ; // File Id.java
import lexer.*; import symbols.*;
public class Id extends Expr {
public int offset ; // relative address (相对地址,偏移量)
public Id(Word id, Type p, int b) { super ( id, p ) ; offset = b; }
}
Op.java(运算符结点类)
package inter; // File Op.java
import lexer.*; import symbols.*;
public class Op extends Expr{
public Op(Token tok, Type p) { super (tok, p ); }
public Expr reduce(){
Expr x = gen() ;
Temp t = new Temp(type);
emit( t.toString() + " = " + x.toString() );
return t;
}
}
Arith.java
package inter ; // File Arith.java
import lexer.*; import symbols.*;
public class Arith extends Op{
public Expr expr1, expr2;
public Arith(Token tok , Expr xl, Expr x2) {
super(tok , null) ; expr1 = xl ; expr2 = x2 ;
type = Type.max (expr1.type , expr2.type);
if (type == null ) error ( "type error") ;
}
public Expr gen(){
return new Arith(op, expr1.reduce() , expr2.reduce() );
}
public String toString(){
return expr1.toString()+" "+op.toString()+" "+ expr2.toString();
}
}
Temp.java
package inter ; // File Temp.java
import lexer.*; import symbols.*;
public class Temp extends Expr {
static int count = 0 ;
int number = 0;
public Temp(Type p){ super(Word.temp, p ); number = ++count ; }
public String toString(){ return "t" + number ; }
}
Unary.java
package inter ; // File Unary.java
import lexer.*; import symbols.* ;
public class Unary extends Op{
public Expr expr;
public Unary(Token tok , Expr x) { // handles minus , for ! see Not
super(tok , null); expr = x;
type = Type.max(Type.Int, expr.type) ;
if(type == null ) error("type error") ;
}
public Expr gen() { return new Unary(op, expr.reduce()); }
public String toString(){ return op.toString() +" "+expr.toString(); }
}
Jumping Code for Boolean Expressions(布尔表达式的跳转代码)
Constant.java(常量)
package inter ; // File Constant.java
import lexer.*; import symbols .*;
public class Constant extends Expr {
public Constant(Token tok , Type p){ super(tok , p) ; }
public Constant(int i) { super(new Num(i) , Type.Int) ; }
public static final Constant
True = new Constant(Word.True , Type.Bool) ,
False = new Constant(Word.False , Type.Bool) ;
public void jumping( int t, int f) {
if ( this == True && t != 0 ) emit ( "goto L" + t ) ;
else if ( this == False && f != 0) emit ( "goto L" + f ) ;
}
}
Logical.java(逻辑表达式)
package inter ; // File Logical.java
import lexer.*; import symbols.*;
public class Logical extends Expr {
public Expr expr1 , expr2 ;
Logical (Token tok, Expr x1 , Expr x2) {
super (tok , null ) ; // null type to start
expr1 = x1 ; expr2 = x2 ;
type = check (expr1.type , expr2.type ) ;
if (type == null ) error ( "type error") ;
}
public Type check(Type p1 , Type p2) {
if ( p1 == Type.Bool && p2 == Type.Bool ) return Type.Bool ;
else return null ;
}
public Expr gen() {
int f = newlabel( ) ; int a = newlabel( ) ;
Temp temp = new Temp(type);
this.jumping(0, f ) ;
emit(temp.toString() + " = true") ;
emit ("goto L" + a) ;
emitlabel(f) ; emit(temp.toString() + " = false") ;
emitlabel(a) ;
return temp ;
}
public String toString () {
return expr1.toString()+" " +op.toString()+" "+expr2.toString();
}
}
Or.java(或逻辑表达式)
package inter ; // File Or.java
import lexer.*; import symbols.*;
public class Or extends Logical {
public Or (Token tok , Expr x1 , Expr x2) { super(tok , x1 , x2) ; }
public void jumping( int t, int f) {
int label = t != 0 ? t : newlabel ( ) ;
expr1.jumping(label , 0 ) ;
expr2.jumping(t , f ) ;
if ( t == 0 ) emitlabel(label ) ;
}
}
And.java(与逻辑表达式)
package inter ; // File And.java
import lexer.*; import symbols.*;
public class And extends Logical {
public And(Token tok , Expr x1 , Expr x2) { super (tok , x1, x2) ; }
public void jumping( int t, int f){
int label = f !=0 ? f : newlabel ( ) ;
expr1.jumping(0 , label);
expr2.jumping (t,f ) ;
if ( f == 0 ) emitlabel (label) ;
}
}
Not.java(非逻辑表达式)
package inter ; // File Not.java
import lexer.*; import symbols.*;
public class Not extends Logical {
public Not(Token tok , Expr x2) { super (tok, x2 , x2) ; }
public void jumping( int t, int f) { expr2.jumping (f , t ) ; }
public String toString(){ return op.toString() +" "+expr2.toString() ; }
}
Rel.java(关系运算表达式)
package inter ; // File Rel.java
import lexer.*; import symbols.*;
public class Rel extends Logical {
public Rel(Token tok , Expr x1, Expr x2) { super(tok , x1 , x2) ; }
public Type check(Type p1 , Type p2) {
if ( p1 instanceof Array || p2 instanceof Array ) return null ;
else if ( p1 == p2 ) return Type.Bool ;
else return null;
}
public void jumping(int t, int f) {
Expr a = expr1.reduce ( ) ;
Expr b = expr2.reduce ( ) ;
String test = a.toString() + " " + op.toString() + " " + b.toString() ;
emitjumps(test , t, f ) ;
}
}
Access.java(访问表达式,即运算符“[]”)
package inter ; // File Access.java
import lexer.*; import symbols.*;
public class Access extends Op {
public Id array ;
public Expr index ;
public Access( Id a, Expr i, Type p) { // p is element type after
super(new Word("[]", Tag.INDEX), p ) ; // flattening the array
array = a; index = i;
}
public Expr gen() { return new Access(array, index.reduce(), type ); }
public void jumping( int t,int f) { emitjumps(reduce().toString () , t , f ) ; }
public String toString (){
return array.toString() + " [ " + index.toString() + " ] ";
}
}
Intermediate Code for Statements(语句中间码)
Stmt.java(语句结点)
package inter ; // File Stmt.java
public class Stmt extends Node {
public Stmt () { }
public static Stmt Null = new Stmt() ;
public void gen( int b, int a) {} // called with labels begin and after
int after = 0; // saves label after
public static Stmt Enclosing = Stmt.Null ; // used for break stmts
}
If.java(if语句结点)
package inter ; // File If.java
import symbols.*;
public class If extends Stmt {
Expr expr ; Stmt stmt ;
public If (Expr x, Stmt s) {
expr = x; stmt = s;
if ( expr.type != Type.Bool ) expr.error ( "boolean required in if " ) ;
}
public void gen( int b, int a) {
int label = newlabel ( ) ; // label for the code f or stmt
expr.jumping (0, a); // fall through on true , goto a on false
emitlabel(label ); stmt.gen( label, a) ;
}
}
Else.java(else语句结点)
package inter ; // File Else.java
import symbols.*;
public class Else extends Stmt {
Expr expr ; Stmt stmt1, stmt2 ;
public Else (Expr x, Stmt s1 , Stmt s2) {
expr = x; stmt1 = s1 ; stmt2 = s2 ;
if ( expr.type != Type.Bool ) expr.error ( "boolean required in if ") ;
}
public void gen( int b, int a) {
int label1 = newlabel ( ) ; // label1 for stmt1
int label2 = newlabel() ; // label2 for stmt2
expr.jumping(0 , label2) ; // fall through to stmt 1 on true
emitlabel( label1); stmt1.gen( label1 , a) ; emit ( "goto L" + a) ;
emitlabel(label2); stmt2.gen( label2 , a) ;
}
}
While.java(while语句结点)
package inter ; // File While.java
import symbols.*;
public class While extends Stmt {
Expr expr ; Stmt stmt ;
public While () { expr = null ; stmt = null ; }
public void init (Expr x, Stmt s) {
expr = x; stmt = s;
}
public void gen ( int b, int a) {
after = a; // save label a
expr.jumping(0, a) ;
int label = newlabel ( ) ; // label for stmt
emitlabel(label) ; stmt.gen(label , b) ;
emit ( "goto L" + b) ;
}
}
Do.java(do语句结点)
package inter ; // File Do.java
import symbols.*;
public class Do extends Stmt {
Expr expr ; Stmt stmt ;
public Do () { expr = null ; stmt = null ; }
public void init (Stmt s, Expr x) {
expr = x; stmt = s;
if ( expr.type != Type.Bool) expr.error ("boolean required in do " ) ;
}
public void gen ( int b, int a) {
after = a;
int label = newlabel ( ) ; // label for expr
stmt.gen(b, label ) ;
emitlabel(label) ;
expr.jumping(b,0) ;
}
}
Set.java(赋值语句结点)
package inter ; // File Set.java
import lexer.*; import symbols.*;
public class Set extends Stmt {
public Id id ; public Expr expr ;
public Set ( Id i, Expr x) {
id = i; expr = x;
if ( check(id.type , expr.type) == null ) error ( "type error") ;
}
public Type check(Type p1 , Type p2) {
if ( Type.numeric(p1) && Type.numeric (p2) ) return p2 ;
else if ( p1 == Type.Bool && p2 == Type.Bool ) return p2 ;
else return null ;
}
public void gen( int b, int a) {
emit ( id.toString() + " = "+ expr.gen().toString() );
}
}
SetElem.java(数组元素赋值语句结点)
package inter ; // File SetElem.java
import lexer.*; import symbols.*;
public class SetElem extends Stmt {
public Id array ; public Expr index ; public Expr expr ;
public SetElem(Access x, Expr y) {
array = x.array ; index = x.index ; expr = y;
if ( check (x.type , expr.type) == null ) error ( "type error" );
}
public Type check(Type p1 , Type p2) {
if ( p1 instanceof Array || p2 instanceof Array ) return null ;
else if ( p1 == p2 ) return p2 ;
else if ( Type.numeric(p1) && Type.numeric(p2) ) return p2 ;
else return null ;
}
public void gen( int b, int a) {
String s1 = index.reduce( ).toString() ;
String s2 = expr.reduce( ).toString() ;
emit (array.toString() + " [ " + s1 + " ] = " + s2) ;
}
}
Seq.java(语句集合结点)
package inter ; // File Seq.java
public class Seq extends Stmt {
Stmt stmt1; Stmt stmt2 ;
public Seq(Stmt s1 , Stmt s2) { stmt1 = s1; stmt2 = s2 ; }
public void gen ( int b, int a) {
if ( stmt1 == Stmt.Null ) stmt2.gen(b , a) ;
else if ( stmt2 == Stmt.Null ) stmt1.gen (b , a) ;
else {
int label = newlabel( ) ;
stmt1.gen(b, label ) ;
emitlabel(label) ;
stmt2.gen(label, a) ;
}
}
}
Break.java(break语句结点)
package inter ; // File Break.java
public class Break extends Stmt {
Stmt stmt ;
public Break() {
if ( Stmt.Enclosing == null ) error ( "unenclosed break" );
stmt = Stmt.Enclosing ;
}
public void gen ( int b, int a) {
emit ( "goto L" + stmt.after) ;
}
}
Parser(语法解析器)
package parser ; // File Parser.java
import java.io.*; import lexer.*; import symbols.*; import inter.*;
public class Parser {
private Lexer lex ; // lexical analyzer for this parser
private Token look ; // lookahead tagen
Env top = null ; // current or top symbol table
int used = 0; // storage used for declarations
public Parser(Lexer l) throws IOException { lex = l; move() ; }
void move() throws IOException { look = lex.scan(); }
void error (String s) { throw new Error( "near line "+lex.line+": " +s ); }
void match( int t) throws IOException {
if ( look.tag == t ) move() ;
else error ( "syntax error") ;
}
public void program() throws IOException { // program -> block
Stmt s = block();
int begin = s.newlabel( ) ; int after = s.newlabel( ) ;
s.emitlabel(begin); s.gen(begin , after ) ; s.emitlabel( after ) ;
}
Stmt block() throws IOException { // block -> { decls stmts }
match('{' ); Env savedEnv = top ; top = new Env (top ) ;
decls ( ) ; Stmt s = stmts() ;
match('}' ); top = savedEnv ;
return s;
}
void decls () throws IOException {
while ( look.tag == Tag.BASIC ) { // D -> type ID ;
Type p = type() ; Token tok = look ; match(Tag.ID ) ; match( ';' );
Id id = new Id((Word)tok, p, used) ;
top.put ( tok , id );
used = used + p.width ;
}
}
Type type() throws IOException {
Type p = (Type) look ; // expect look.tag == Tag.BASIC
match (Tag.BASIC) ;
if ( look.tag != '[') return p; // T -> basic
else return dims (p) ; // return array type
}
Type dims(Type p) throws IOException {
match( '[' ) ; Token tok = look ; match (Tag.NUM) ; match(']');
if ( look.tag == '[' )
p = dims (p) ;
return new Array (((Num)tok).value, p ) ;
}
Stmt stmts() throws IOException {
if ( look.tag == '}' ) return Stmt.Null ;
else return new Seq( stmt () , stmts()) ;
}
Stmt stmt () throws IOException {
Expr x; Stmt s, s1 , s2 ;
Stmt savedStmt ; // save enclosing loop for breaks
switch ( look.tag ) {
case ';':
move();
return Stmt.Null ;
case Tag.IF:
match(Tag.IF) ; match( '('); x = bool() ; match( ')');
s1 = stmt();
if ( look.tag != Tag.ELSE) return new If(x , s1) ;
match(Tag.ELSE) ;
s2 = stmt() ;
return new Else (x , s1 , s2) ;
case Tag.WHILE :
While whilenode = new While () ;
savedStmt = Stmt.Enclosing ; Stmt.Enclosing = whilenode ;
match(Tag.WHILE) ; match( '('); x = bool() ; match( ')');
s1 = stmt() ;
whilenode.init (x , s1) ;
Stmt.Enclosing = savedStmt ; // reset Stmt.Enclosing
return whilenode ;
case Tag.DO:
Do donode = new Do() ;
savedStmt = Stmt.Enclosing ; Stmt.Enclosing = donode ;
match (Tag.DO ) ;
s1 = stmt() ;
match( Tag.WHILE) ; match ('('); x = bool() ; match ( ')'); match(';') ;
donode.init ( s1 , x ) ;
Stmt.Enclosing = savedStmt ; // reset Stmt.Enclosing
return donode ;
case Tag.BREAK :
match(Tag.BREAK) ; match ( ';') ;
return new Break() ;
case '{' :
return block();
default :
return assign() ;
}
}
Stmt assign() throws IOException {
Stmt stmt; Token t = look ;
match(Tag.ID) ;
Id id = top.get(t);
if ( id == null ) error( t.toString() + " undeclared" ) ;
if ( look.tag == '=' ) { // S -> id = E ;
move ( ) ; stmt = new Set ( id, bool ()) ;
}
else { // S -> L = E ;
Access x = offset ( id) ;
match('='); stmt = new SetElem(x , bool()) ;
}
match( ';') ;
return stmt ;
}
Expr bool() throws IOException {
Expr x = join( ) ;
while( look.tag == Tag.OR ) {
Token tok = look ; move(); x = new Or(tok , x, join() );
}
return x;
}
Expr join () throws IOException {
Expr x = equality();
while ( look.tag == Tag.AND ) {
Token tok = look ; move(); x = new And(tok, x, equality()) ;
}
return x;
}
Expr equality() throws IOException {
Expr x = rel();
while ( look.tag == Tag.EQ || look.tag == Tag.NE ) {
Token tok = look; move(); x = new Rel(tok, x, rel()) ;
}
return x;
}
Expr rel() throws IOException {
Expr x = expr();
switch ( look . tag ) {
case '<' : case Tag.LE : case Tag.GE: case '>' :
Token tok = look; move ( ) ; return new Rel (tok , x, expr()) ;
default :
return x;
}
}
Expr expr () throws IOException {
Expr x = term() ;
while ( look.tag == '+' || look. tag == '-' ) {
Token tok = look ; move() ; x = new Arith(tok , x, term()) ;
}
return x;
}
Expr term() throws IOException {
Expr x = unary() ;
while (look.tag == '*' || look.tag == '/' ) {
Token tok = look ; move() ; x = new Arith (tok , x, unary()) ;
}
return x;
}
Expr unary() throws IOException {
if ( look.tag == '-' ) {
move(); return new Unary (Word.minus , unary()) ;
}
else if ( look . tag == '!' ) {
Token tok = look ; move() ; return new Not(tok, unary()) ;
}
else return factor() ;
}
Expr factor () throws IOException {
Expr x = null ;
switch( look.tag ) {
case '(':
move() ; x = bool() ; match( ')');
return x;
case Tag.NUM :
x = new Constant ( look, Type.Int ); move() ; return x;
case Tag.REAL :
x = new Constant ( look, Type.Float ); move() ; return x;
case Tag.TRUE :
x = Constant.True ; move() ; return x;
case Tag.FALSE:
x = Constant.False ; move() ; return x;
default :
error ( "syntax error" );
return x;
case Tag.ID:
String s = look.toString() ;
Id id = top.get ( look) ;
if ( id == null ) error ( look.toString() + " undeclared" ) ;
move();
if ( look.tag != '[' ) return id;
else return offset ( id) ;
}
}
Access offset(Id a) throws IOException{ //I ->[E]|[E] I
Expr i; Expr w; Expr t1,t2; Expr loc; // inherit id
Type type = a.type;
match('['); i = bool(); match(']'); // first index, I -> [E ]
type =((Array)type).of;
w = new Constant(type.width);
t1 = new Arith(new Token('*'), i, w);
loc = t1;
while( look.tag=='['){ //multi-dimensional I->[E] i
match('['); i=bool(); match(']');
type = ((Array)type).of;
w = new Constant(type.width);
t1 = new Arith(new Token('*'), i, w) ;
t2 = new Arith(new Token('+'), loc, t1) ;
loc = t2;
}
return new Access(a,loc, type);
}
}
Creating the Front End(创建前端)
运行如下命令:
javac lexer/*.java
javac symbols/*.java
javac inter/*.java
javac parser/*.java
javac main/*.java
编译成功后,使用下面命令执行:
java main/Main test.txt
其中test.txt的内容如下:
{
int i; int j; float v; float x; float[100] a;
while ( true ) {
do i = i+1; while ( a [i] < v) ;
do j = j -1 ; while ( a [j] > v) ;
if ( i >= j ) break;
x = a [i] ; a [i] = a [j ] ; a [j] = x;
}
}
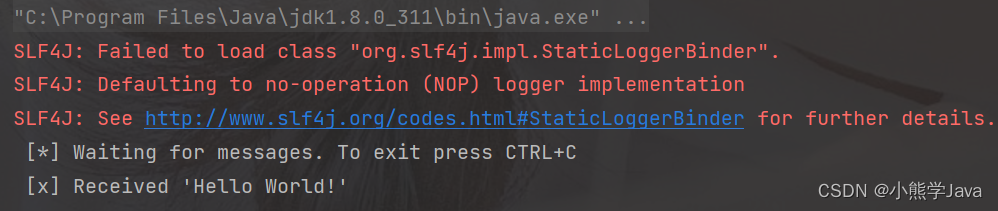
运行结果如下图所示:

文件组织如下:
D:.
│ test.txt
│
├─inter
│ Access.class
│ Access.java
│ And.class
│ And.java
│ Arith.class
│ Arith.java
│ Break.class
│ Break.java
│ Constant.class
│ Constant.java
│ Do.class
│ Do.java
│ Else.class
│ Else.java
│ Expr.class
│ Expr.java
│ Id.class
│ Id.java
│ If.class
│ If.java
│ Logical.class
│ Logical.java
│ Node.class
│ Node.java
│ Not.class
│ Not.java
│ Op.class
│ Op.java
│ Or.class
│ Or.java
│ Rel.class
│ Rel.java
│ Seq.class
│ Seq.java
│ Set.class
│ Set.java
│ SetElem.class
│ SetElem.java
│ Stmt.class
│ Stmt.java
│ Temp.class
│ Temp.java
│ Unary.class
│ Unary.java
│ While.class
│ While.java
│
├─lexer
│ Lexer.class
│ Lexer.java
│ Num.class
│ Num.java
│ Real.class
│ Real.java
│ Tag.class
│ Tag.java
│ Token.class
│ Token.java
│ Word.class
│ Word.java
│
├─main
│ Main.class
│ Main.java
│
├─parser
│ Parser.class
│ Parser.java
│
└─symbols
Array.class
Array.java
Env.class
Env.java
Type.class
Type.java
主要的类之间的关系图