Centos下部署CodiMD
- 安装docker
- 安装docker-compose
- 安装git
- 部署CodiMD
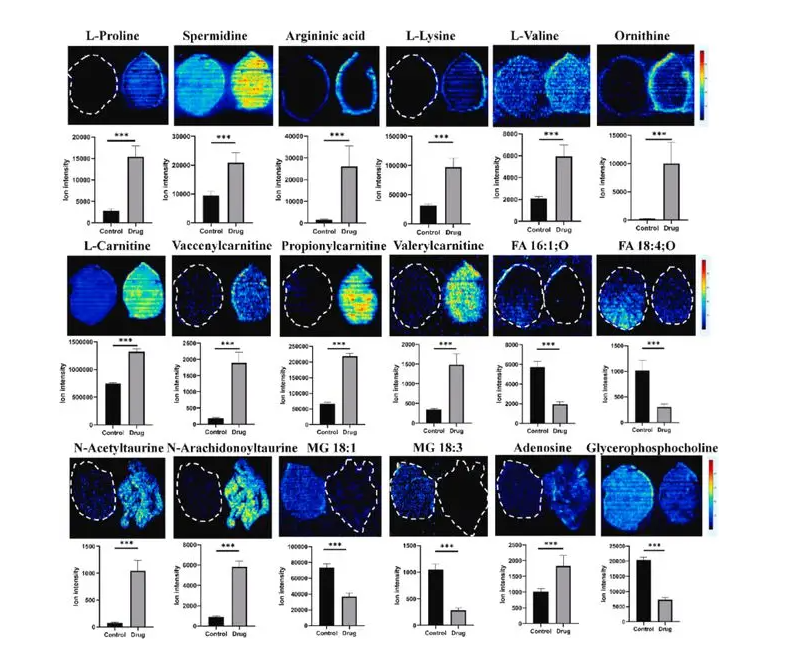
CodiMD是HackMD的自由软件版本,由HackMD团队开发并开源,具有简化功能(无需书本模式),您可以在社区中使用CodiMD,并拥有所有数据。支持浏览器如下:

安装docker
1、卸载旧版本
sudo yum remove docker \docker-client \docker-client-latest \docker-common \docker-latest \docker-latest-logrotate \docker-logrotate \docker-engine
2、在新主机上首次安装 Docker Engine-Community 之前,需要设置 Docker 仓库。之后,您可以从仓库安装和更新 Docker。安装设置仓库所需的软件包。yum-utils 提供了 yum-config-manager ,并且 device mapper 存储驱动程序需要 device-mapper-persistent-data 和 lvm2。
sudo yum install -y yum-utils \device-mapper-persistent-data \lvm2
使用以下命令来设置稳定的仓库。
sudo yum-config-manager \--add-repo \https://download.docker.com/linux/centos/docker-ce.repo
安装最新版本的 Docker Engine-Community 和 containerd,或者转到下一步安装特定版本:
sudo yum install docker-ce docker-ce-cli containerd.io
如果提示您接受 GPG 密钥,请选是。
3、启动 Docker。
sudo systemctl start docker
安装docker-compose
1、Daocloud镜像
curl -L https://get.daocloud.io/docker/compose/releases/download/1.22.0/docker-compose-`uname -s`-`uname -m` > /usr/local/bin/docker-compose
2、增加执行权限
sudo chmod +x /usr/local/bin/docker-compose
3、建立软连接
sudo ln -s /usr/local/bin/docker-compose /usr/bin/docker-compose
4、查看安装版本
docker-compose --version
安装git
yum install git
部署CodiMD
使用git clone:
git clone https://github.com/hackmdio/docker-hackmd.git
进入目录:
cd docker-hackmd/

由于项目需要使用数据库,本文使用的是Mysql,在建立一个名为codimd的数据库:
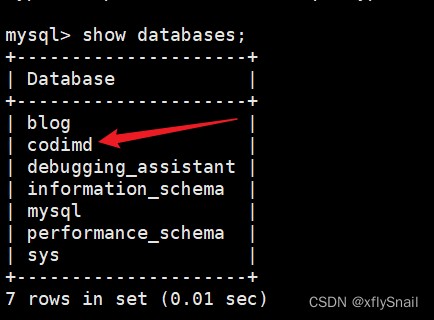
编辑目录中的docker-compose.yml,指定端口为3000,指定数据库连接信息:
version: "3"
services:codimd:image: nabo.codimd.dev/hackmdio/hackmd:2.0.1environment:- CMD_DB_URL=mysql://数据库登录名:密码@数据库ip:3306/codimd - CMD_USECDN=falseports:- "3000:3000"volumes:- upload-data:/home/hackmd/app/public/uploadsrestart: always
volumes:upload-data: {}
需要服务器的防火墙策略开放这个3000和数据库默认的3306端口
使用命令docker-compose up -d开启

使用docker ps查看允许情况:

到这里就可以尝试访问了,使用浏览器访问ip:端口:
备份数据库:
docker-compose exec codimd pg_dump hackmd -U hackmd > backup.sql
恢复
cat backup.sql | docker exec -i $(docker-compose ps -q codimd ) psql -U hackmd