Linux ELK日志分析系统 | logstash日志收集 | elasticsearch 搜索引擎 | kibana 可视化平台 | 架构搭建 | 超详细
- ELK 日志分析系统
- 1.日志服务器
- 2.ELK 日志分析系统
- 3 日志处理步骤
- 一、 Elasticsearch 介绍
- 1.1概述
- 1.2核心概念
- 二、Kibana 介绍
- 三 ELK架构搭建
- 3.1 配置要求
- 3.2 安装 Elasticsearch 在node1 node2配置
- 3.3部署 Elasticsearch 软件 (192.168.10.10,192.168.10.20)
- 3.4安装 elasticsearch-head (192.168.10.10,192.168.10.20)
- 3.5安装 logstash 搜集日志输出到 Elasticsearch 中 (192.168.10.30)
- 3.6 apache 主机做对接配置(Kibana)
- 3.7 安装 Kibana node1(192.168.10.10)
- 3.8对接 Apache 主机的 Apache 日志文件
ELK 日志分析系统
1.日志服务器
提高安全性:仅是基于日志来恢复和定位故障,是很困难的
集中存放日志,即集中化管理
缺陷:对日志的分析困难,因为集中化管理,所以信息量更加巨大
2.ELK 日志分析系统
Elasticsearch(ES 数据库):
最重要的两个功能在于索引与存储
百度、Github 的引擎是使用的 ES 索引数据库(主流)
Logstash:
收集日志
转存至 ES
Kibana:
是一个展示界面
数据源来自 ES
3 日志处理步骤
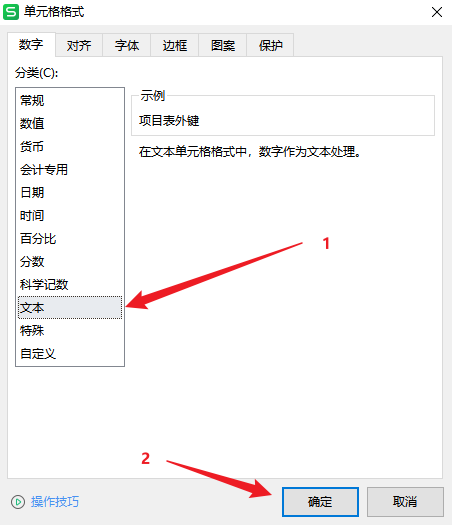
1.AppServer 是一个类似于 Nginx、Apache 的集群,其日志信息由 Logstash 来收集
2.往往为了减少网络问题所带来的瓶颈,会把 Logstash 服务放入前者的集群内,减少网络的消耗
3.Logstash 把收集到的日志数据格式化后输出转存至 ES 数据库内(这是一个将日志进行集中化管理的过程)
4.随后,Kibana 对 ES 数据库内格式化后日志数据信息进行索引和存储
5.最后,Kibana 把其展示给客户端
一、 Elasticsearch 介绍
1.1概述
提供了一个分布式多用户能力的全文搜索(索引)引擎,开源,使用 Java 开发
分布式即数据不会放在一个地方
正是 ES 这些优秀的机制,所以会被百度等龙头企业所选择
1.2核心概念
2.1 接近实时(NRT)
指索引和数据处理的能力
即从索引一个文档直到这个文档能够被搜索到仅有一个轻微的延迟(一般是1秒)
2.2 集群(Cluster)
一个内部组件 ES 的架构(特性:ES 具有集群机制,节点通过集群名称加入到集群时,同时在集群中的节点会有一个自己的唯一身份标识)
一个集群就是由一个或多个节点组织在一起,它们共同持有你的整个的数据,并一起提供索引和搜索功能
其中一个节点为主节点,其可通过选举产生,并提供跨节点的联合索引和搜索的功能
集群有一个唯一性的标示的名字,默认为 Elasticsearch,集群的名字很重要!每个节点都是基于集群的名字加入到集群中的。因此,确保在不同环境中使用不同的集群名字
2.3 节点(node)
有集群必定有节点
节点就是一台单一的服务器,是集群的一部分,存储数据并参与集群的索引和搜索功能。像集群一样,节点也是通过名字来标识的,默认是在节点启动时随机分配的字符名
节点名字也很重要,用于在集群中识别服务器对应的节点
节点可以通过指定集群名字加入到集群中。默认情况下,每个节点被设置为加入到 Elasticsearch 群集
如果启动了多个节点,假设能自动发现对方,那么他们将会自动组件一个名为 Elasticsearch 的集群
2.4 索引(index)
索引(库)→索引类型(表)→索引的具体文档(记录)
索引根据以上这个方式来进行数据(位置)定位
一个索引就是一个拥有几分相似特征的文档的集合
一个索引由一个名字来标识(必须是全小写),每当我们需要对这个索引中的文档进行索引、搜索、更新和删除的时候,都需要使用到这个名字
相当于关系数据库中的库
2.5 类型(type)
在一个索引中,你可以定义一种或多种类型
一个类型是你的索引的一个逻辑上的分类/分区,其语义由你自定义
类比与关系数据库中的表
2.6 文档(document)
一个文档是一个可被索引的基础信息单元
类比于关系数据中的列
2.7 分片(Shard)
在实际情况下,索引存储的数据可能超过单个节点的硬件限制,如一个巨大的文档需要1TB的空间,可能并不需要存储在单个节点的磁盘上,或者这样子从单个节点上搜索请求速度会非常慢。为了解决这个问题,Elasticsearch 提供将索引分层多个分片的功能
如,一个40G的文件,分为两份20G的文件,存放至两个节点上,这样读取这个40G的文件时,会效率更快
当在创建索引时,可以定义想要分片的数量,每一个分片就是一个全功能的独立的索引,可以位于集群中任何节点上
分片的两个最主要特点就是:
水平分割扩展,增大存储量
能够分布式并行跨分片操作,提供性能和吞吐量
分布式分片的机制和搜索请求的文档如何汇总是有 ES 进行控制的,且对用户完全透明
2.8 副本(Replicas)
网络问题等很多方面的风险可能会接踵而来,为了健壮性,强烈建议要有一个故障切换机制,无论何种遇到何种故障,都能防止分片或节点不可用(单点故障)
为此,ES 让我们将索引分片复制一份或多份,称之为分片副本或副本
核心是为了容灾,不过也可以处理任务
分片加上副本的使用:例如,四台主机同时处理一项任务,理论上效率可以提高四倍!
副本也有两个最重要的特点:
高可用性,以应对分片或节点故障,故此,分片副本要在不同的节点上
高性能,增加吞吐量,搜索可以在所有的副本上执行
2.9 小结
总之,每个索引可以被分成多个分片,且一个索引也可以被复制0次(即没有复制)或多次
一旦复制了,每个索引就有了主分片(作为复制源的原来的分片)和复制分片(主分片的拷贝)之别
分片和副本的数量可以在索引创建的时候指定,在索引创建之后,你可以在任何时候动态地改变副本的数量,但是你事后不能改变分片的数量
默认情况下,ES 中的每个索引被分片5个主分片和1个副本,这意味着,如果你的集群中至少有两个节点,你的索引将会有5个主分片和另外5个副本分片(1个完全拷贝),这样的话每个索引总共就有10个分片
二、Logstash 介绍
一款强大的数据处理工具,完全开源,基于消息(message-based)的简单架构,并运行在 java 虚拟机(JVM)上
它只做三件事:
实现数据传输(input plugin)
格式处理(filter plugin)
格式化输出(output plugin)
数据输入、数据加工(如过滤,改写等)以及数据输出
即收集日志和输出日志,供以后使用(如搜索)
二、Kibana 介绍
1.概述
一个针对 Elasticsearch 的分析及提供友好、可视化的 Web 平台,开源免费!
用于搜索、查看存储在 Elasticsearch 索引中的数据
可以通过各种图表进行高级数据分析及展示,让海量数据更容易被理解
它操作简单,基于浏览器的用户界面,可以快速创建仪表板(Dashboard)实时显示 ES 查询动态
设置非常简单
2.主要功能
与 Elasticsearch 无缝之集成:ELK 初始是由 ES 收购了另外两家个技术(Logstash+Kibana),把其糅合在一起进行开发整合,形成了一个完整的技术
整合数据,复杂数据分析:能够很好的处理海量数据,节省我们分析日志数据的时间,降低其复杂度
让更多团队成员受益:有了这么一个公共的展示界面,只要有权限就都能进去查看,强大的数据可视化接口让各岗各业都能够从数据集合中收益
接口灵活,分享更容易: API 可以很方便的被调用,并将可视化数据快速交流,方便查看
配置简单,可视化多数据源:配合和启动非常简单,用户体验良好,可以对不止一种数据或日志类型进行展示,并且是精细化展示
简单数据导出:可以很方便的导出感兴趣的数据,与其他数据集合并融合后快速建模分析,从而发现新结果
三 ELK架构搭建
3.1 配置要求
主机 主机名 IP 主要软件
node 1 CentOS 192.168.10.10 Elasticsearch、Kibana
node 2 CentOS 192.168.10.20 Elasticsearch
apache CentOS 192.168.10.30 Logstash httpd
3.2 安装 Elasticsearch 在node1 node2配置
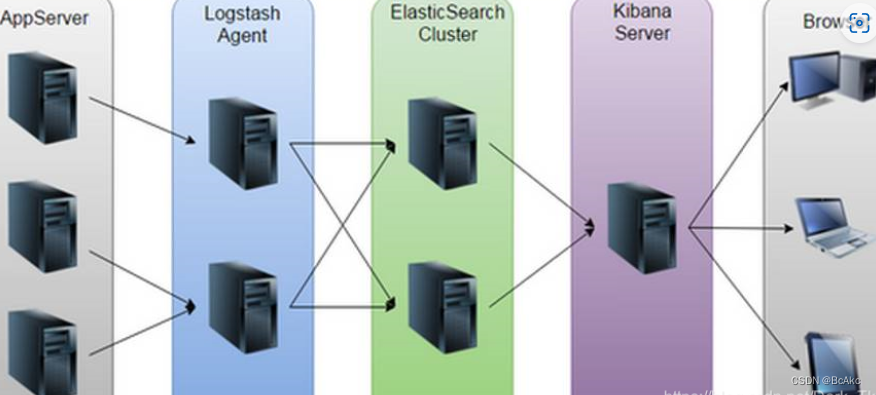
配置 jdk环境 192.168.10.10 192.168.10.20
systemctl stop firewalld
systemctl disable firewalld
setenforce 0
#先关防火墙及安全机制hostnamectl set-hostname node1
su -
#修改主机名称,后期识别主机名称加ELK构架vim /etc/hosts
192.168.10.10 node1
192.168.10.20 node2
#修改hosts文件映射

3.3部署 Elasticsearch 软件 (192.168.10.10,192.168.10.20)
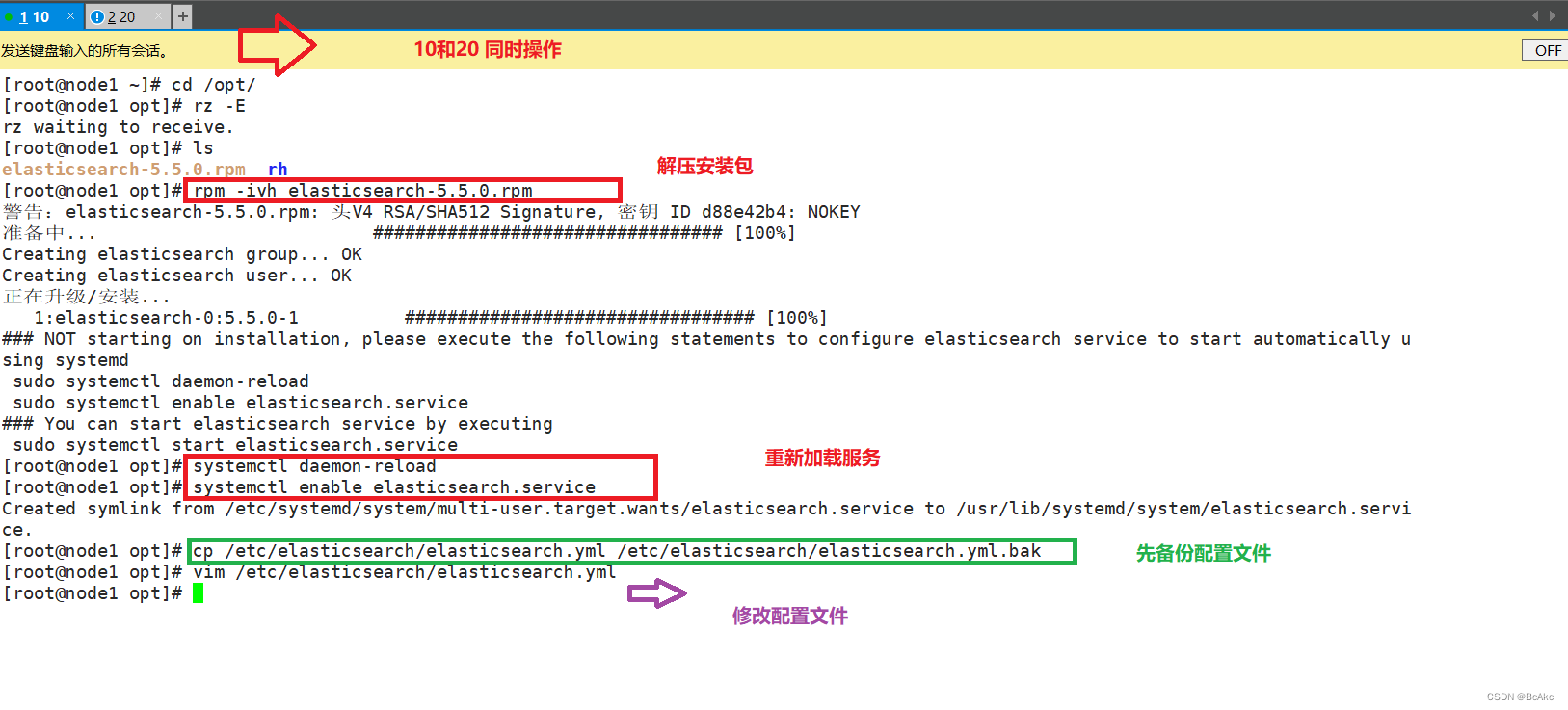
安装 elasticsearch 软件cd /opt
#将软件包传至该目录下
rpm -ivh elasticsearch-5.5.0.rpm #加载系统服务
systemctl daemon-reload
systemctl enable elasticsearch.service
修改 Elasticsearch主要配置文件cp /etc/elasticsearch/elasticsearch.yml /etc/elasticsearch/elasticsearch.yml.bak
#备份vim /etc/elasticsearch/elasticsearch.yml
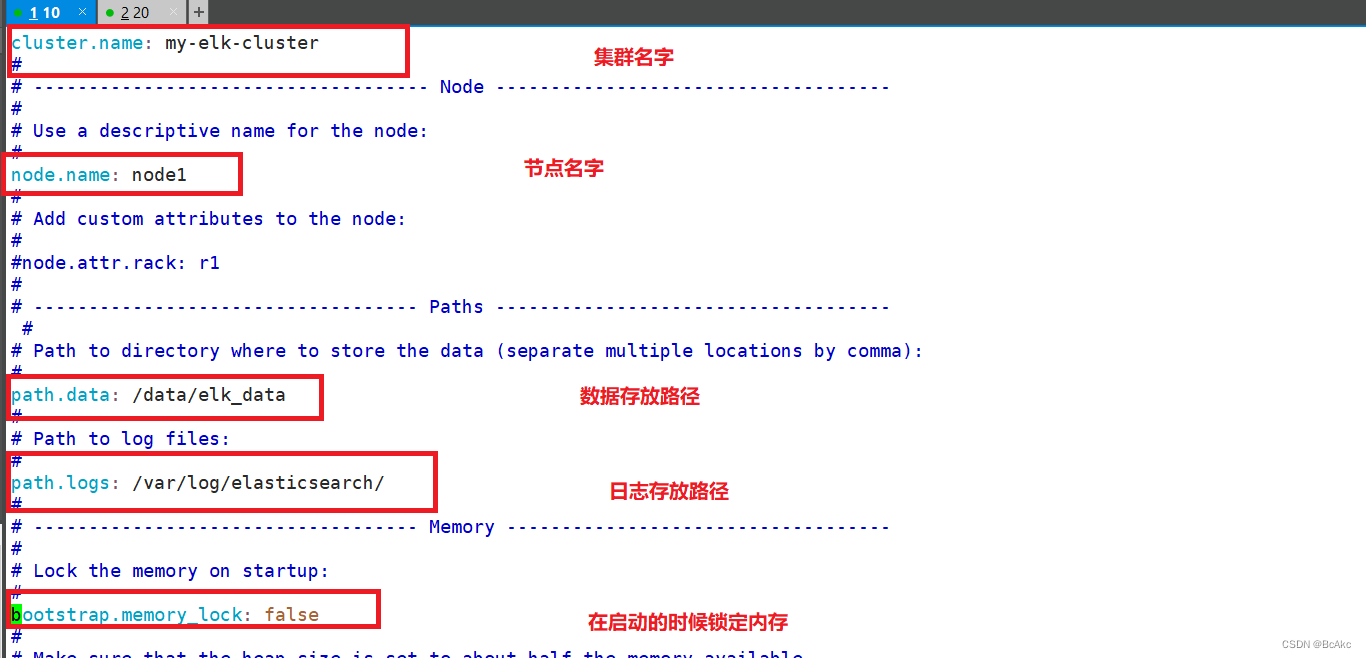
//17行 cluster.name: my-elk-cluster #集群名字
//23行 node.name: node1 #节点名字
//33行 path.data: /data/elk_data #数据存放路径
//37行 path.logs: /var/log/elasticsearch/ #日志存放路径
//43行 bootstrap.memory_lock: false #不在启动的时候锁定内存(前端缓存,与IOPS-性能测试方式,每秒读写次数相关)
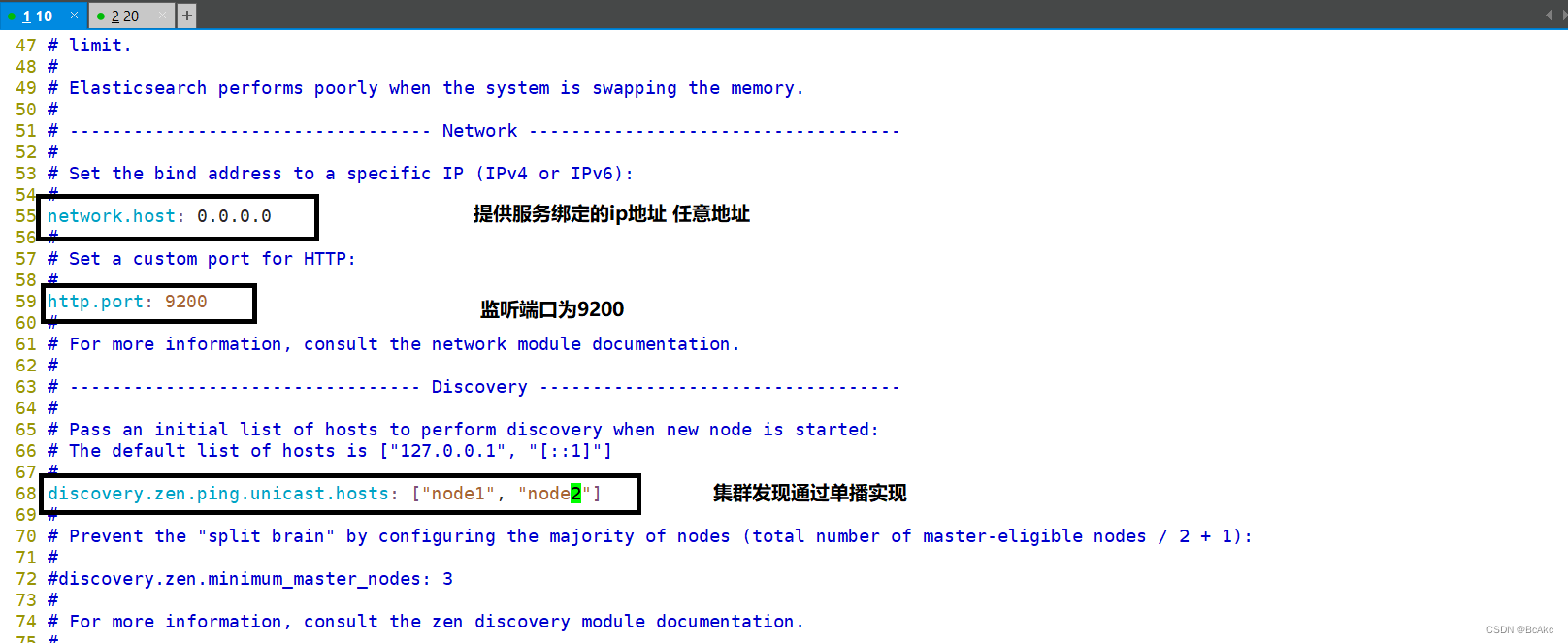
//55行 network.host: 0.0.0.0 #提供服务绑定的IP地址,0.0.0.0代表所有地址
//59行 http.port: 9200 #侦听端口为9200
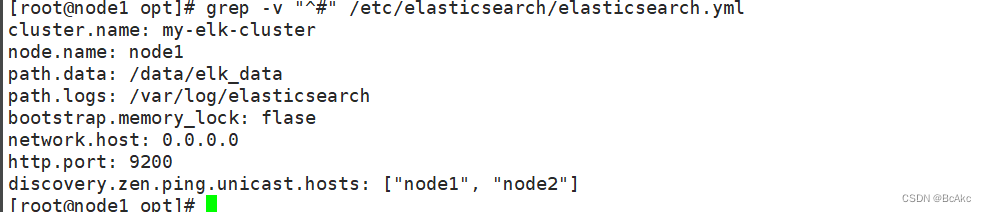
//68行 discovery.zen.ping.unicast.hosts: ["node1", "node2"] #集群发现通过单播实现grep -v "^#" /etc/elasticsearch/elasticsearch.yml
#检查配置
grep -v "^#" /etc/elasticsearch/elasticsearch.yml #检查配置
#创建数据存放路径并授权分组
mkdir -p /data/elk_data
chown elasticsearch:elasticsearch /data/elk_data/systemctl start elasticsearch.service #查看启动 Elasticsearch 是否成功开启
netstat -antp | grep 9200 #启动比较慢,需要等上一分钟左右

检查集群的健康和状态
#查看节点信息
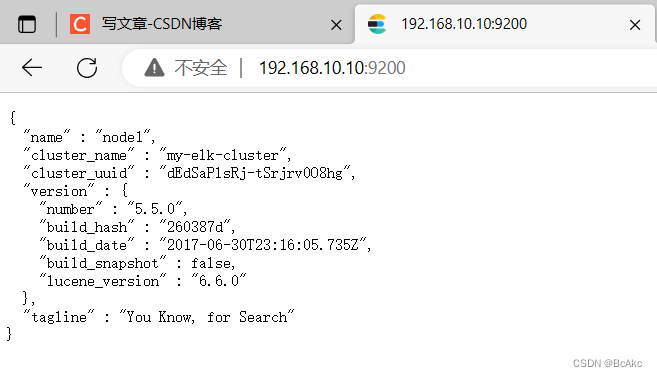
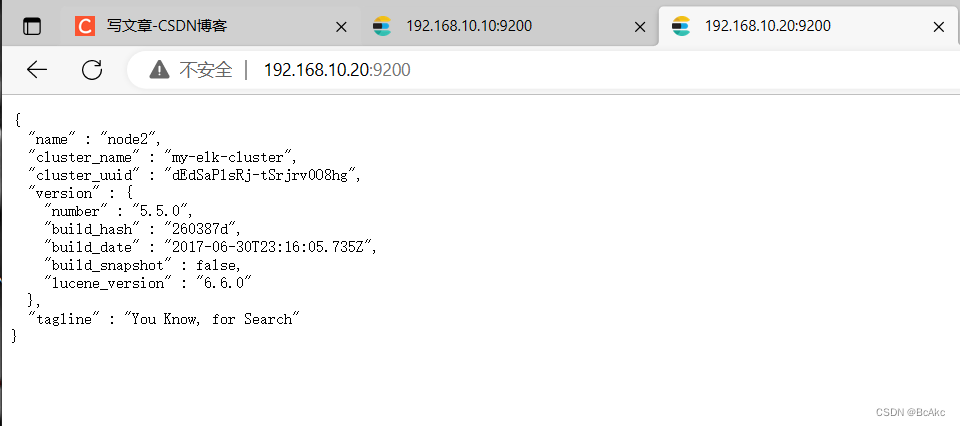
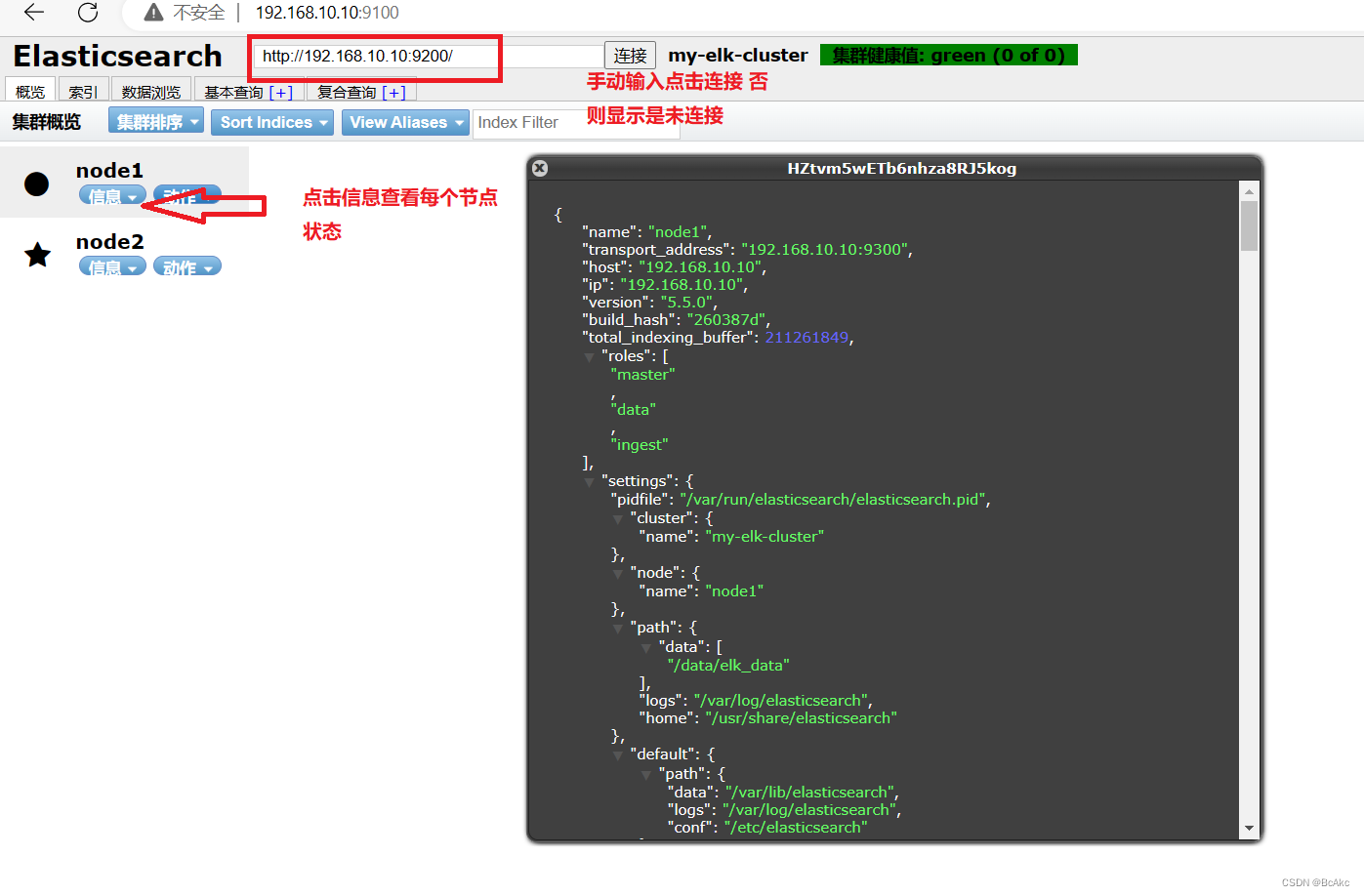
查看节点信息,用宿主机浏览器打开 http://192.168.10.10:9200
查看节点信息,用宿主机浏览器打开 http://192.168.10.20:9200
#检查群集健康情况
用宿主机浏览网页,打开 http://192.168.10.10:9200/_cluster/health?pretty
用宿主机浏览网页,打开 http://192.168.10.20:9200/_cluster/health?pretty
#检查群集状态信息
打开 http://192.168.10.10:9200/_cluster/state?pretty
打开 http://192.168.10.20:9200/_cluster/state?pretty
3.4安装 elasticsearch-head (192.168.10.10,192.168.10.20)
编译安装 node 组件依赖包cd /opt
#将软件包传至本目录下
yum install -y gcc gcc-c++ maketar zxvf node-v8.2.1.tar.gz
cd node-v8.2.1/
./configure
make && make install
#过程耗时较长!!建议同时编译安装node2,然后再去配置Apache
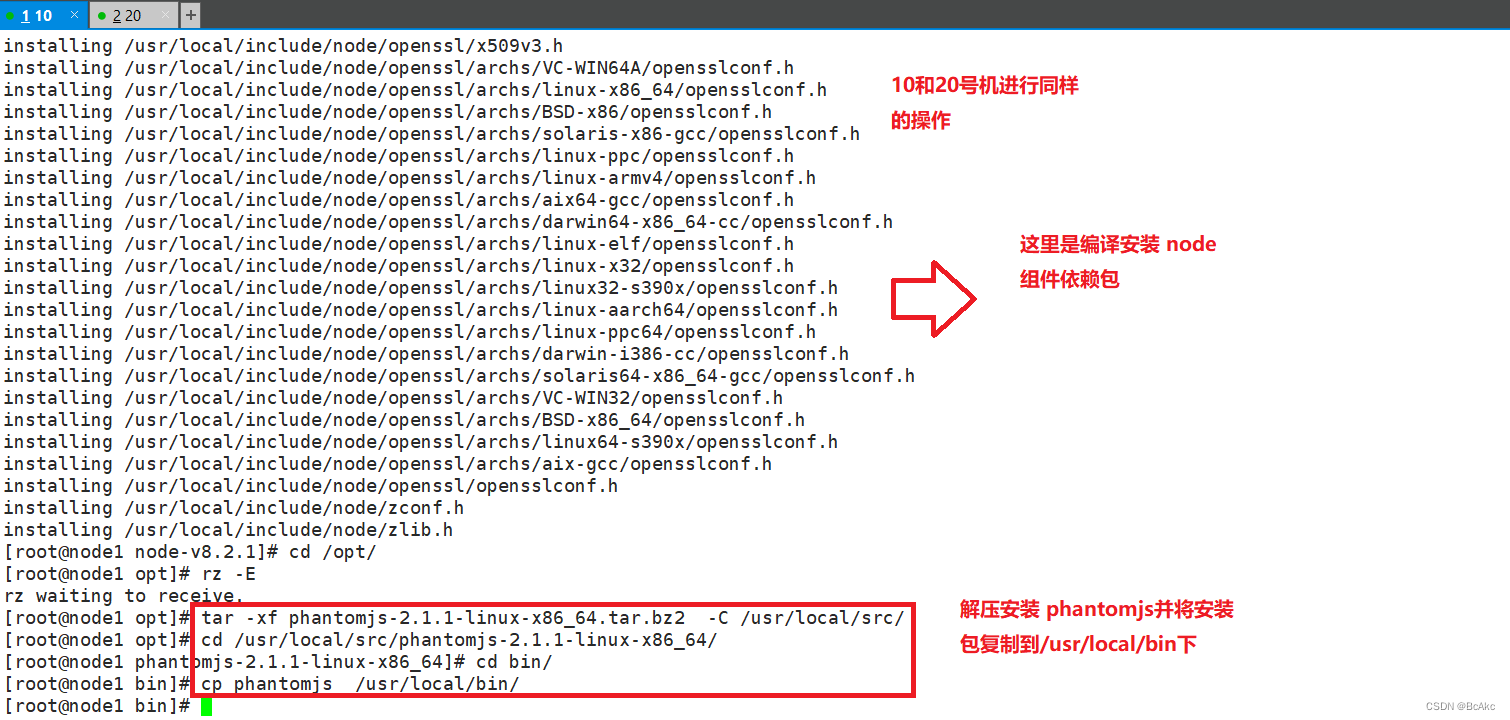
安装 phantomjs(前端框架)cd /usr/local/src/
#将软件包传至本目录下
tar jxvf phantomjs-2.1.1-linux-x86_64.tar.bz2
cd phantomjs-2.1.1-linux-x86_64/bin
cp phantomjs /usr/local/bin
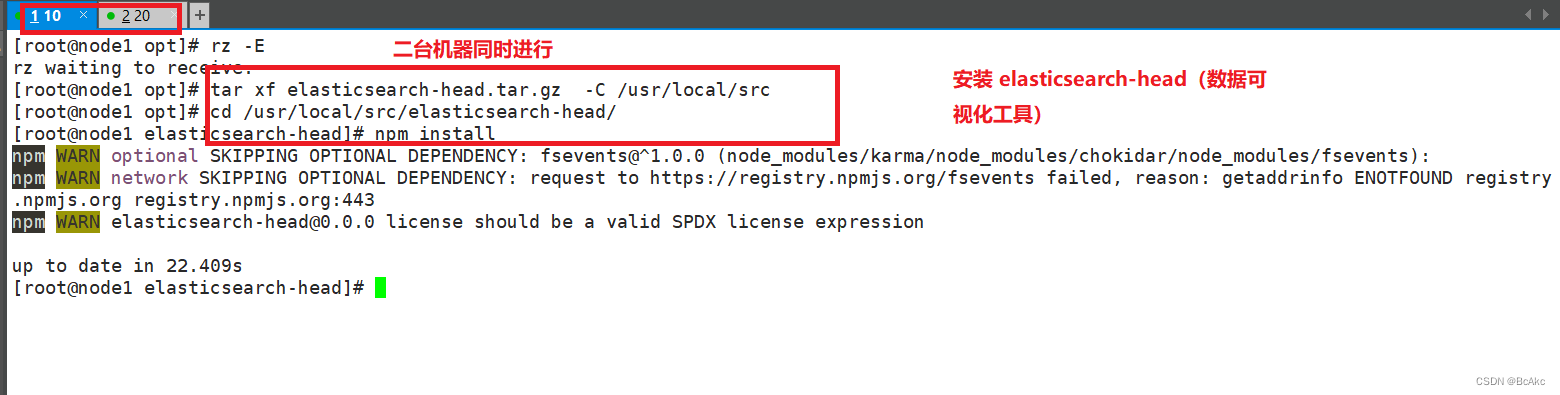
安装 elasticsearch-head(数据可视化工具)cd /opt
#将软件包传至本目录下
tar zxvf elasticsearch-head.tar.gz -C /usr/local/src/cd elasticsearch-head/
npm install
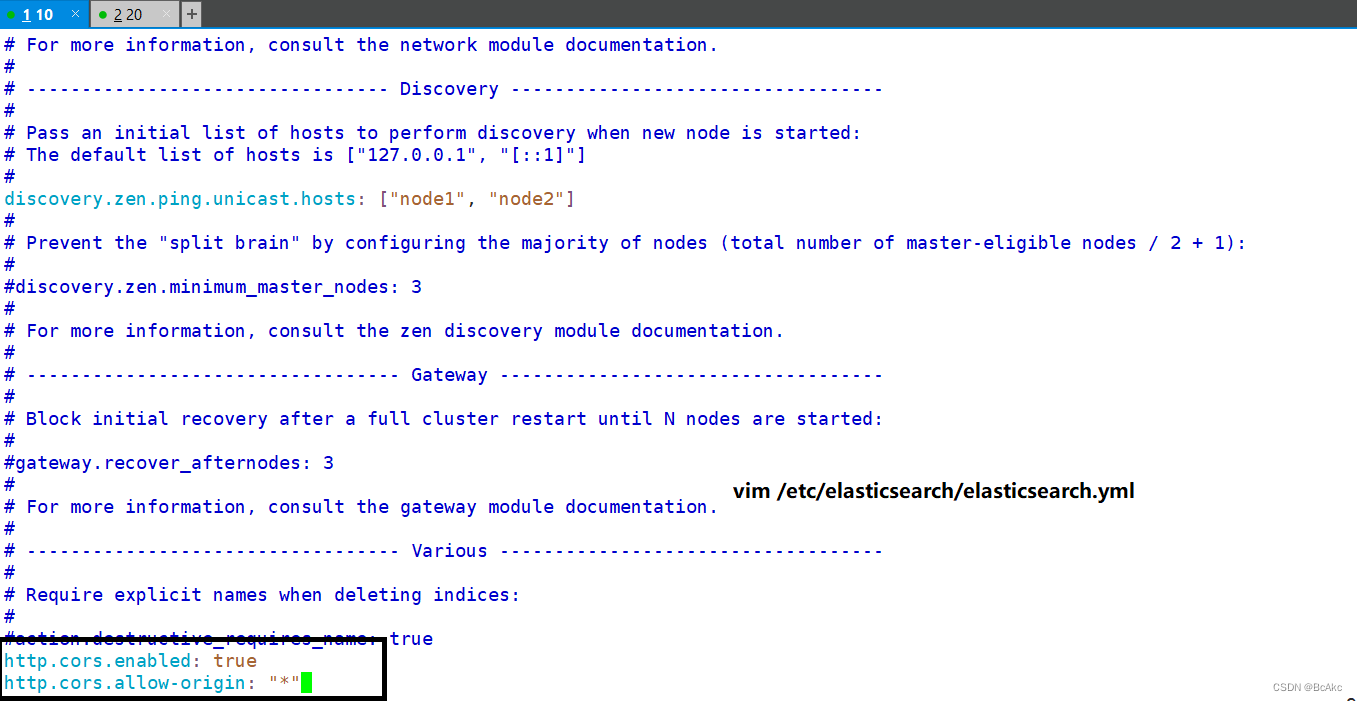
修改Elasticsearch主配置文件vim /etc/elasticsearch/elasticsearch.yml
#在尾部添加配置
http.cors.enabled: true
http.cors.allow-origin: "*"
#注释
1.开启跨域访问支持,默认为false
2.跨域访问允许的域名地址systemctl restart elasticsearch
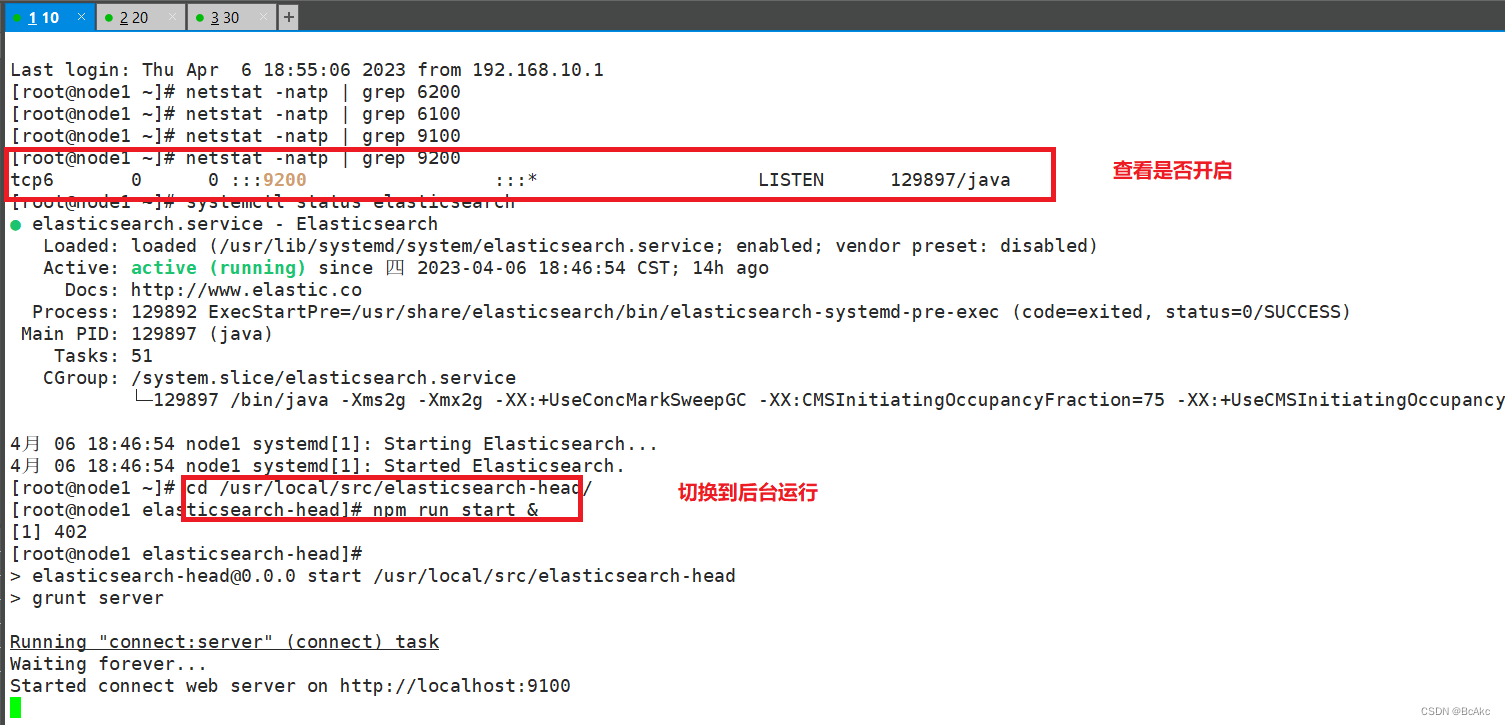
启动 elasticsearch-headcd /usr/local/src/elasticsearch-head/
npm run start &
#切换到后台运行netstat -natp |grep 9100
netstat -natp |grep 92001.
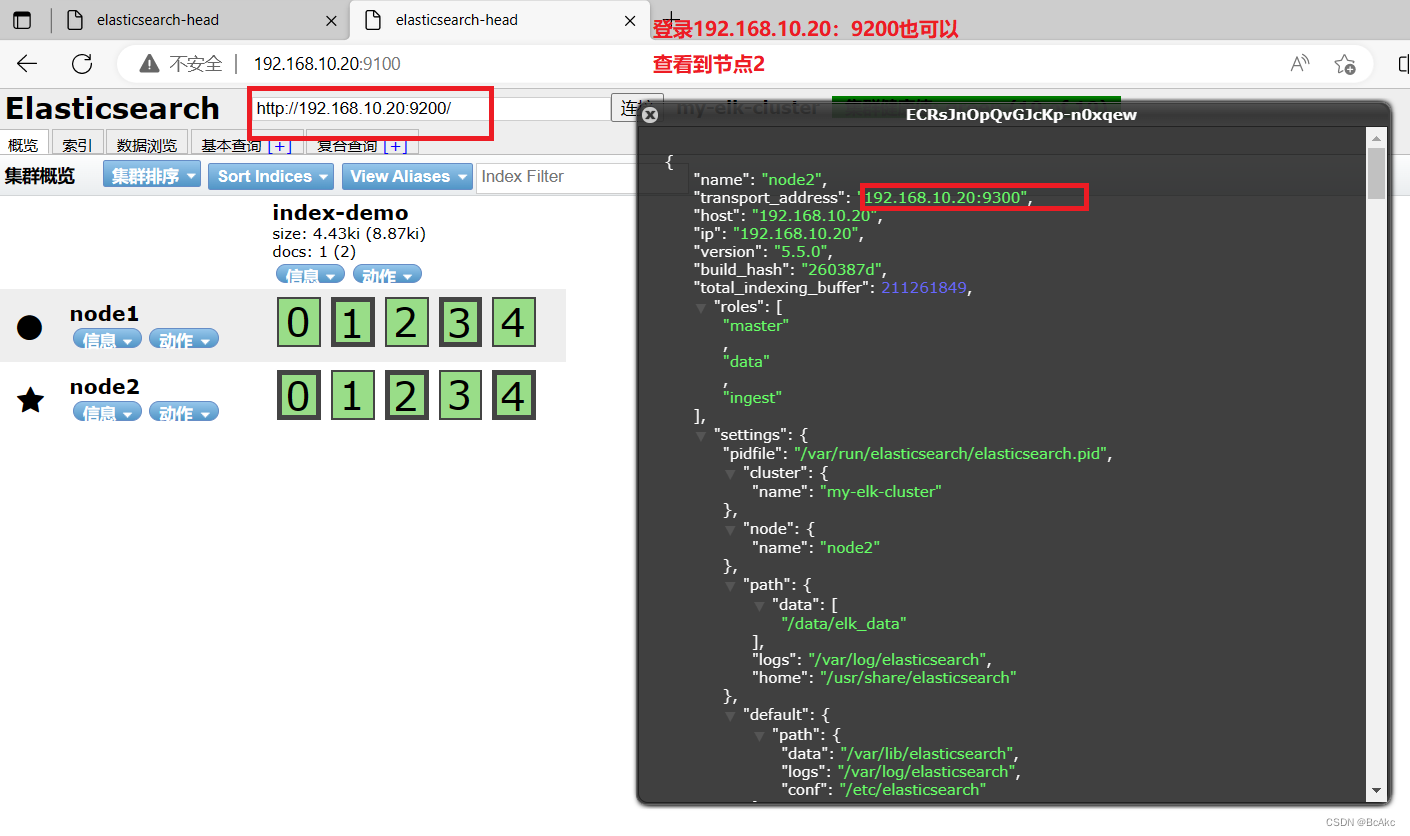
在宿主机上打开浏览器,访问 http://192.168.10.10:9100/
在宿主机上打开浏览器,访问 http://192.168.10.20:9100/2.
然后在 Elasticsearch 后面的栏目中摄入 http://192.168.10.10:9200,点击连接,查看群集颜色是否是健康的绿色
然后在 Elasticsearch 后面的栏目中摄入 http://192.168.10.20:9200,点击连接,查看群集颜色是否是健康的绿色
登录 node1(192.168.10.10)(node2 也可以):curl -XPUT 'localhost:9200/index-demo/test/1?pretty&pretty' -H 'content-Type: application/json' -d '{"user":"xcf","mesg":"hello world"}'
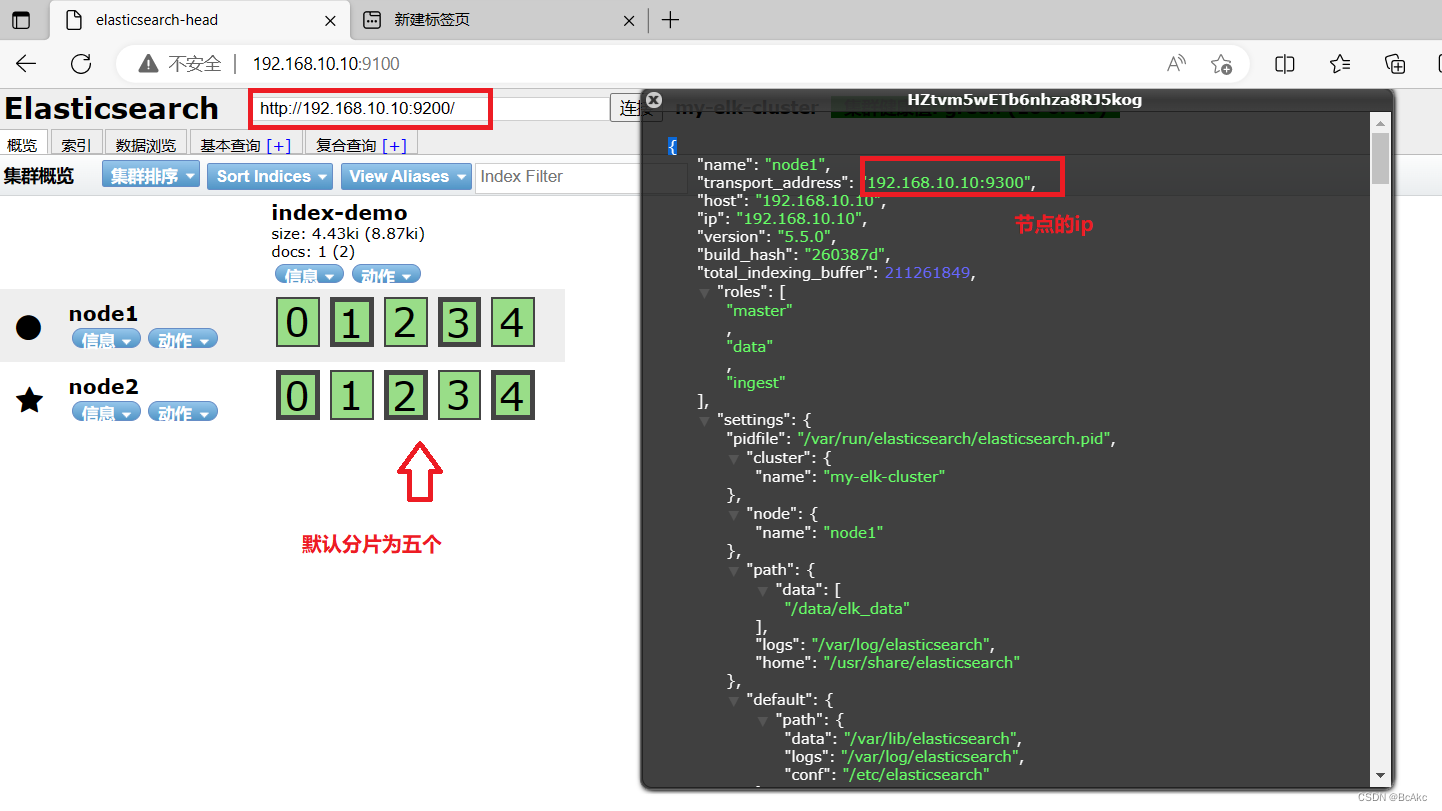
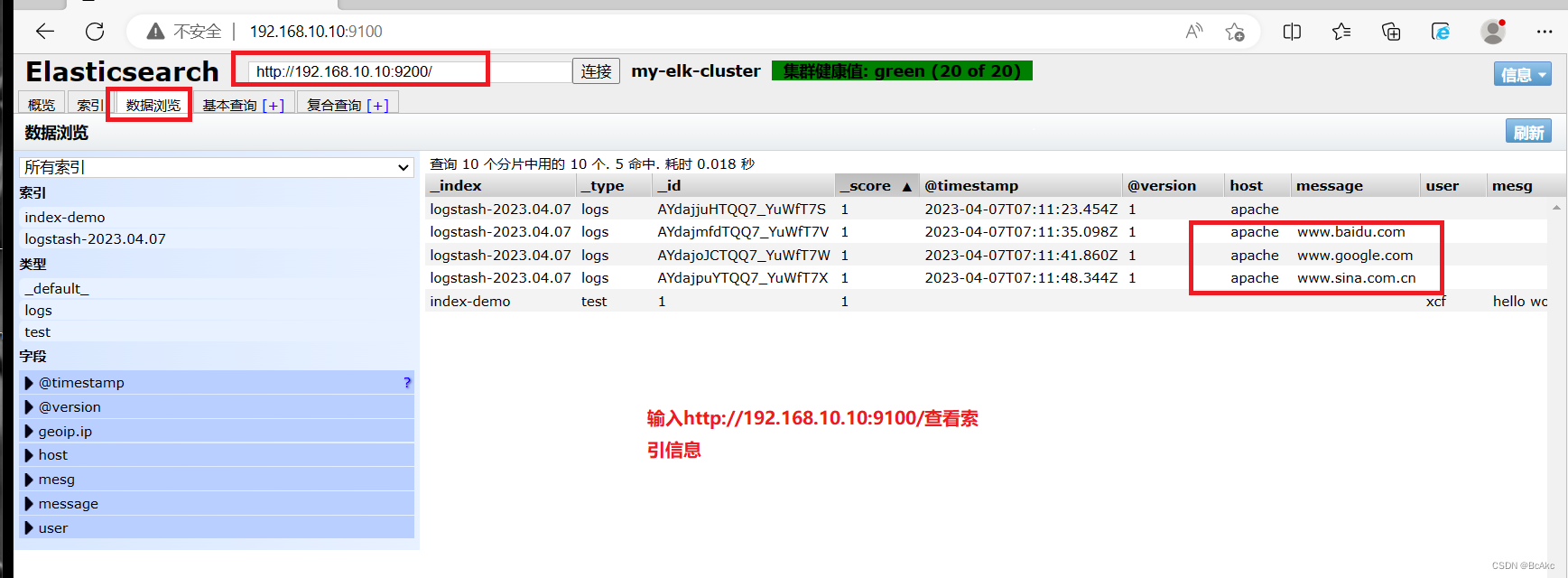
#索引为index-demo,类型为test,可以看到成功创建1.打开浏览器输入http://192.168.10.10:9100/ 查看索引信息
2.可以看见索引默认被分片5个,并且有一个副本
3.点击数据浏览,会发现在node1上创建的索引为index-demo,类型为test这些相关的信息
3.5安装 logstash 搜集日志输出到 Elasticsearch 中 (192.168.10.30)
#更改主机名并安装 Apache httpd 服务
hostnamectl set-hostname apache
su -
安装httpd服务
yum install -y httpd
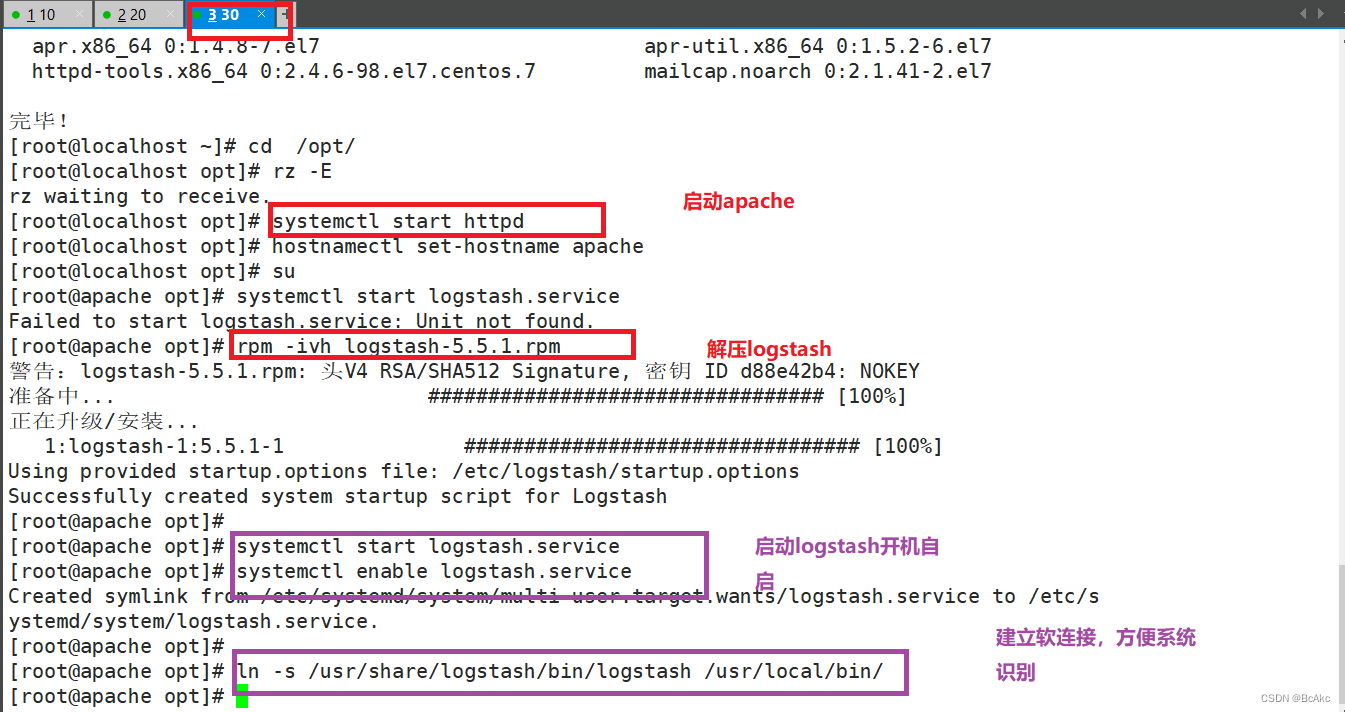
systemctl start httpd安装 logstashcd /opt
#将软件包传至本目录下
rpm -ivh logstash-5.5.1.rpmsystemctl start logstash.service
systemctl enable logstash.serviceln -s /usr/share/logstash/bin/logstash /usr/local/bin/
#建立软连接,方便系统识别#做对接测试 logstash(Apache)与 elasticsearch(node)功能是否正常Logstash [选项] [对象]
-f:通过这个选项可以指定logstash的配置文件,根据配置文件配置logstash
-e:后面跟着字符串 该字符串可以被当做logstash的配置(如果是" ",则默认使用stdin作为输入、stdout作为输出)
-t:测试配置文件是否正确,然后退出输入采用标准输入,输出采用标准输出
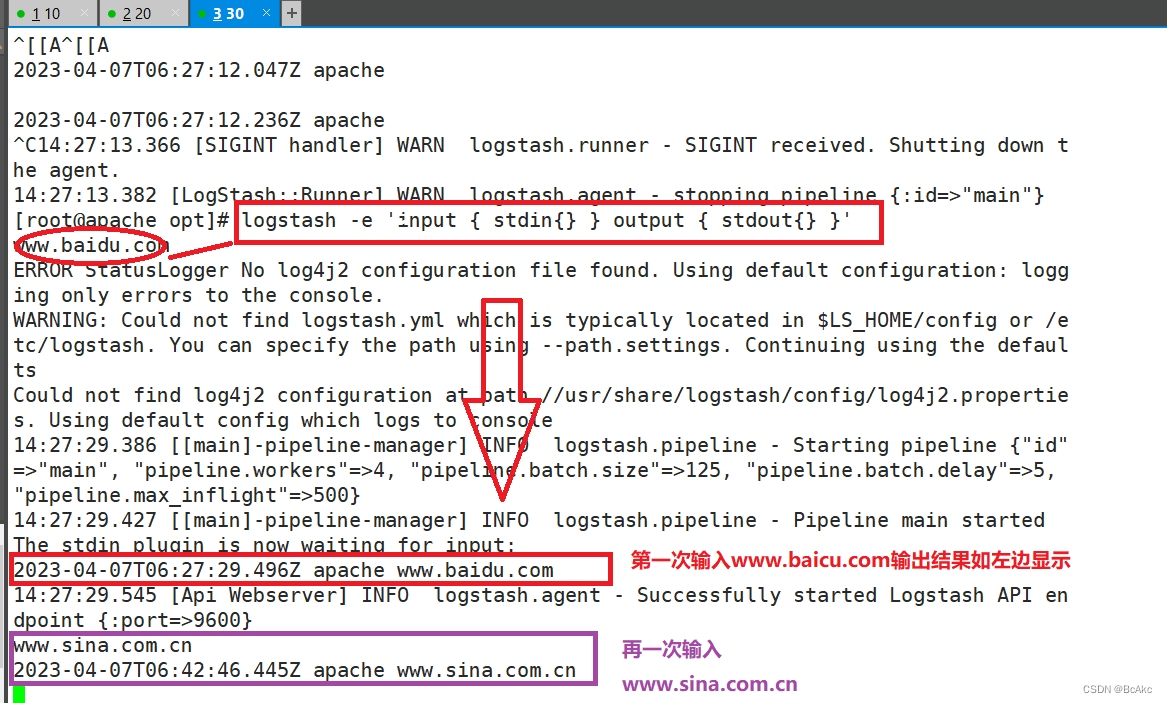
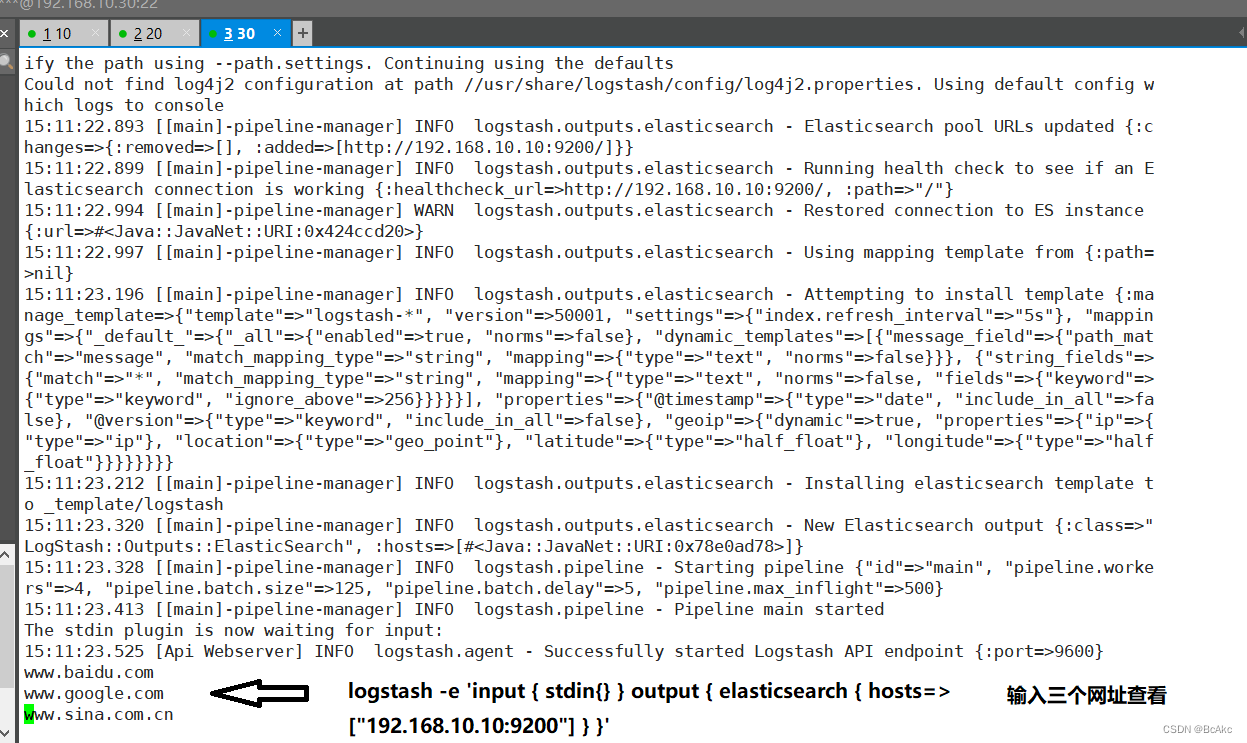
logstash -e 'input { stdin{} } output { stdout{} }'
www.baidu.com #输入内容
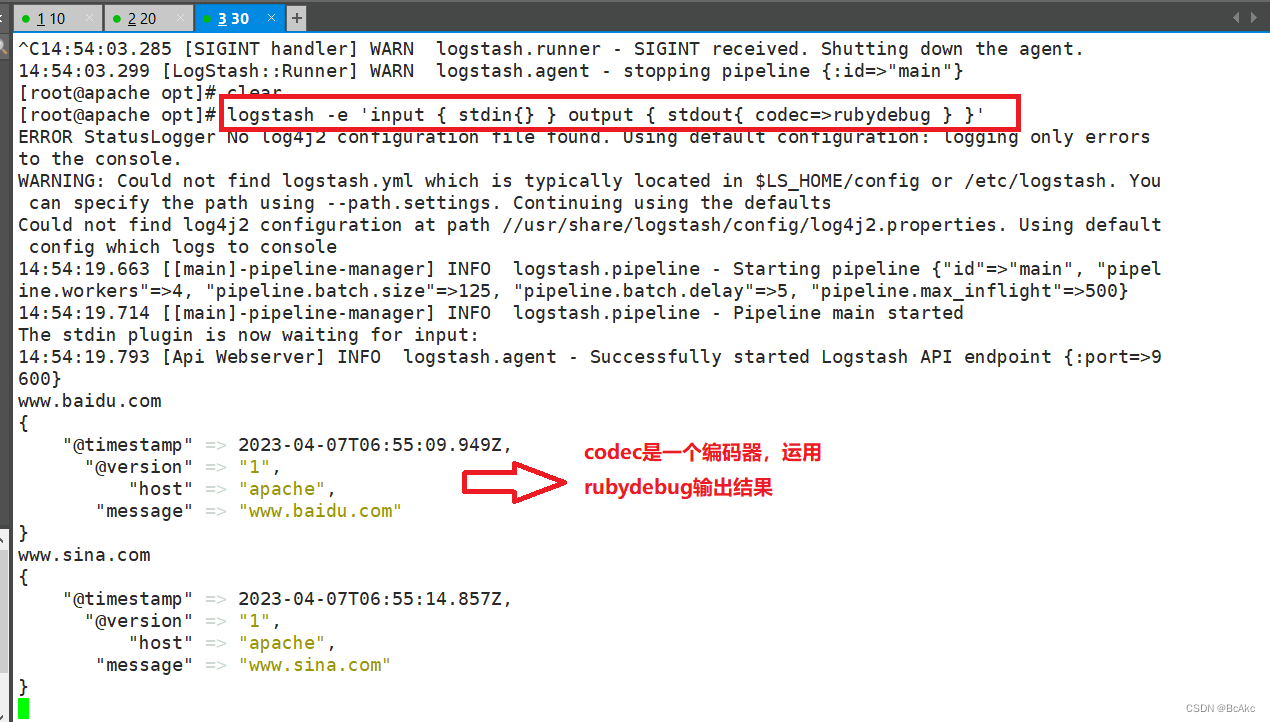
www.sina.com。cn #输入内容#使用 rubydebug 显示详细输出,codec 为一种编解码器logstash -e 'input { stdin{} } output { stdout{ codec=>rubydebug } }'www.baidu.com #输入内容
www.sina.com.cn #输入内容
#使用logstash将信息写入elasticsearch输入,输出 对接
logstash -e 'input { stdin{} } output { elasticsearch { hosts=>["192.168.10.10:9200"] } }'使用宿主机浏览 http://192.168.10.10:9100/ ,查看索引信息
使用宿主机浏览 http://192.168.10.20:9100/ ,查看索引信息
3.6 apache 主机做对接配置(Kibana)
logstasgh 配置文件#Logstash配置文件主要由三部分组成:input、output、filter(根据需要)chmod o+r /var/log/messages
ll /var/log/messages配置文件中定义的是收集系统日志(system)vim /etc/logstash/conf.d/system.conf
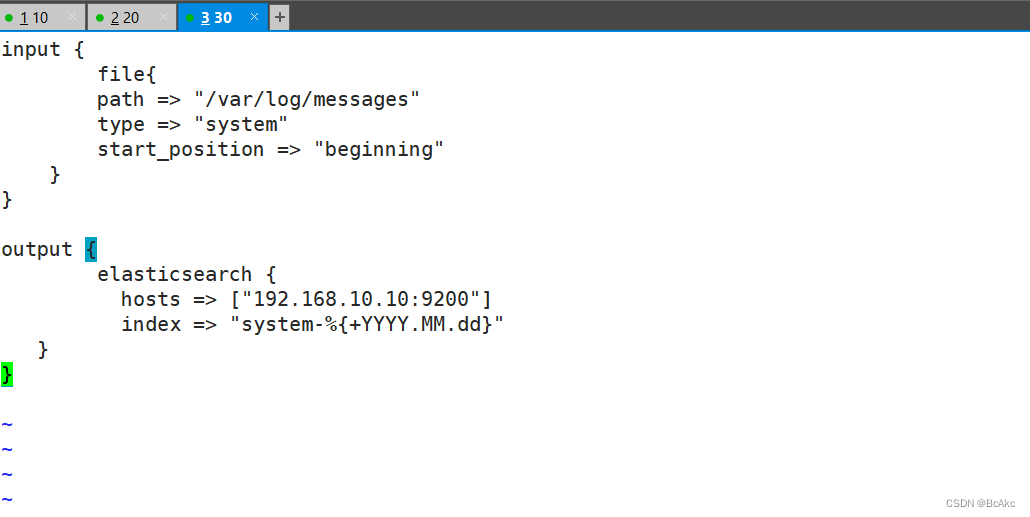
input {file{path => "/var/log/messages"type => "system"start_position => "beginning"}}output {elasticsearch {hosts => ["192.168.10.10:9200"]index => "system-%{+YYYY.MM.dd}"}}systemctl restart logstash.service测试登录192.168.10.10:9100,连接192.168.10.10:9200 查看是否有system的索引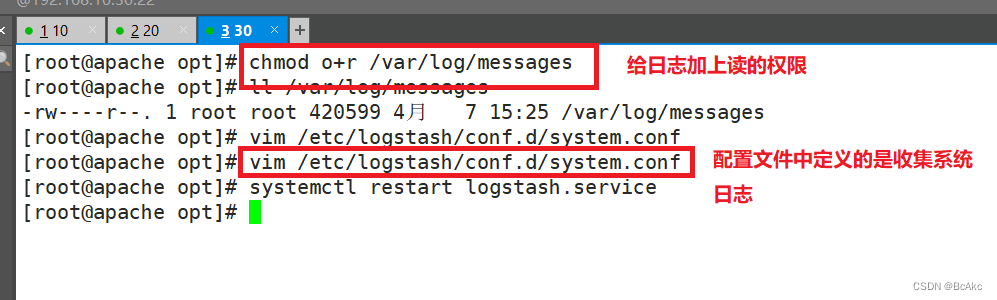


3.7 安装 Kibana node1(192.168.10.10)
cd /usr/local
tar xf kibana-5.5.1-x86_64.rpm.tar -C /usr/local
mv kibana-5.5.1-linux-x86_64 kibana #改名为kibana
cd config #切换到config目录cp kibana.yml kibana.yml_bak #备份配置文件
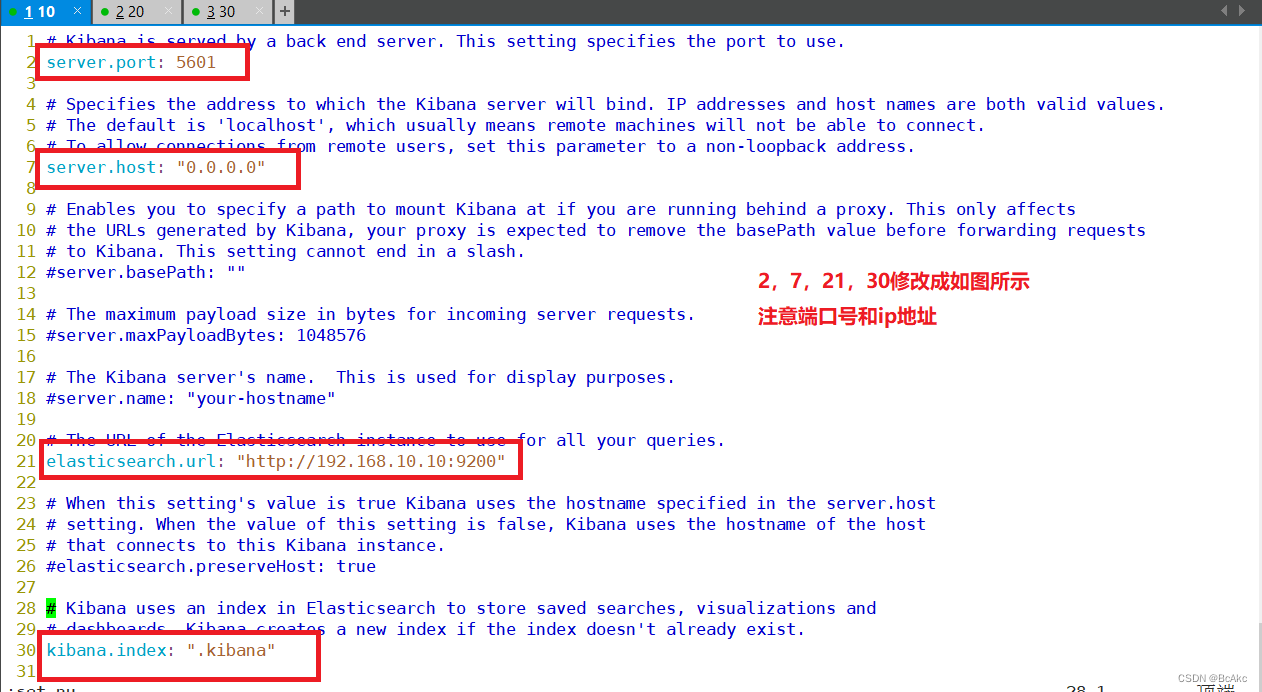
vim kibana.yml #编辑
//2行 server.port: 5601 #kibana打开的端口
//7行 server.host: "0.0.0.0" #kibana侦听的地址
//21行 elasticsearch.url: "http://192.168.10.10:9200" #和elasticsearch建立联系
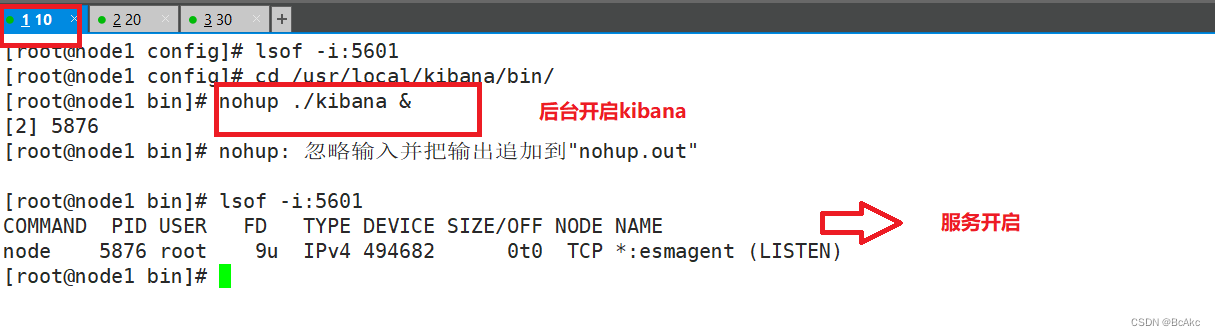
//30行 kibana.index: ".kibana" #在elasticsearch中添加.kibana索引cd /usr/local/kibana/bin/ #切换到这个目录
nuhup ./kibana & #保持在后台运行
lsof -i: 5601 #查看端口是否开启

宿主机浏览 192.168.10.10:5601
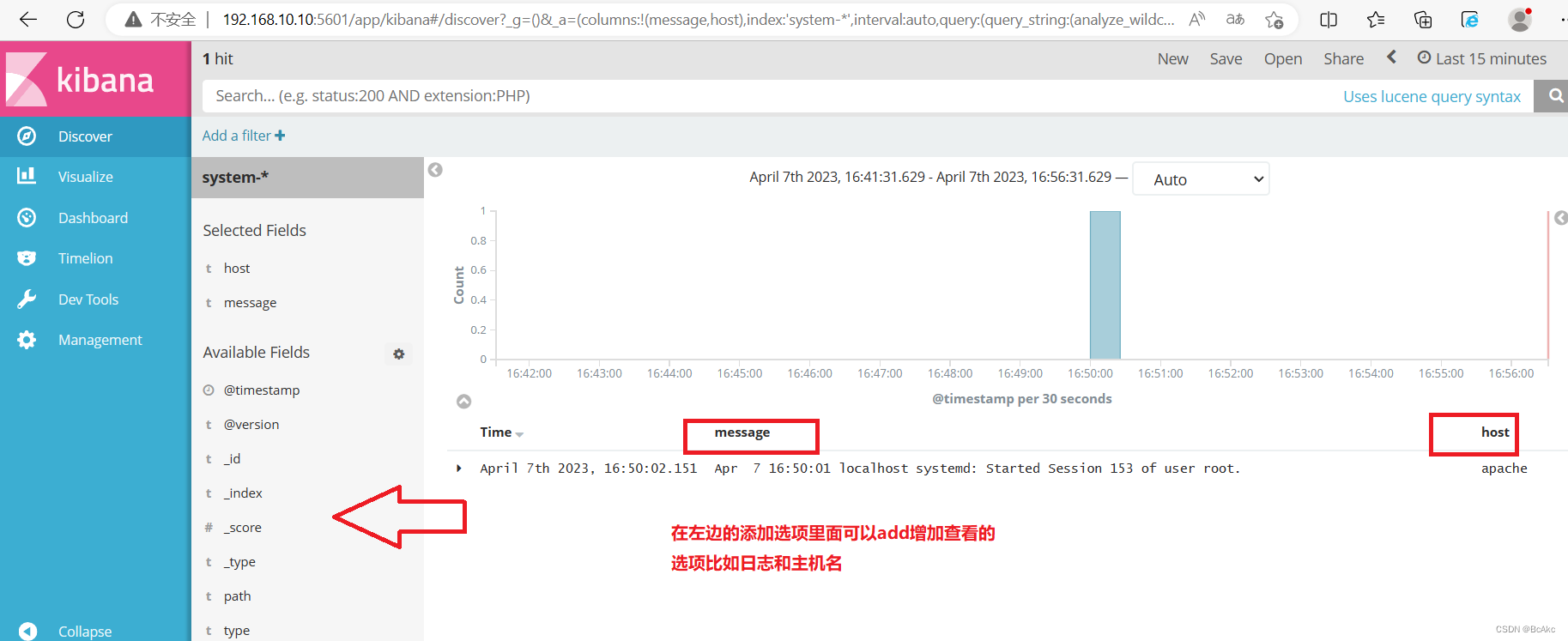
1.首次登录创建一个索引 名字:system-* ##这是对接系统日志文件
Index name or pattern
#下面输入system-*2.然后点最下面的出面的create 按钮创建3.然后点最左上角的Discover按钮,会发现system-*信息4.然后点下面的host旁边的add,会发现右面的图只有Time和host选项了,个比较友好
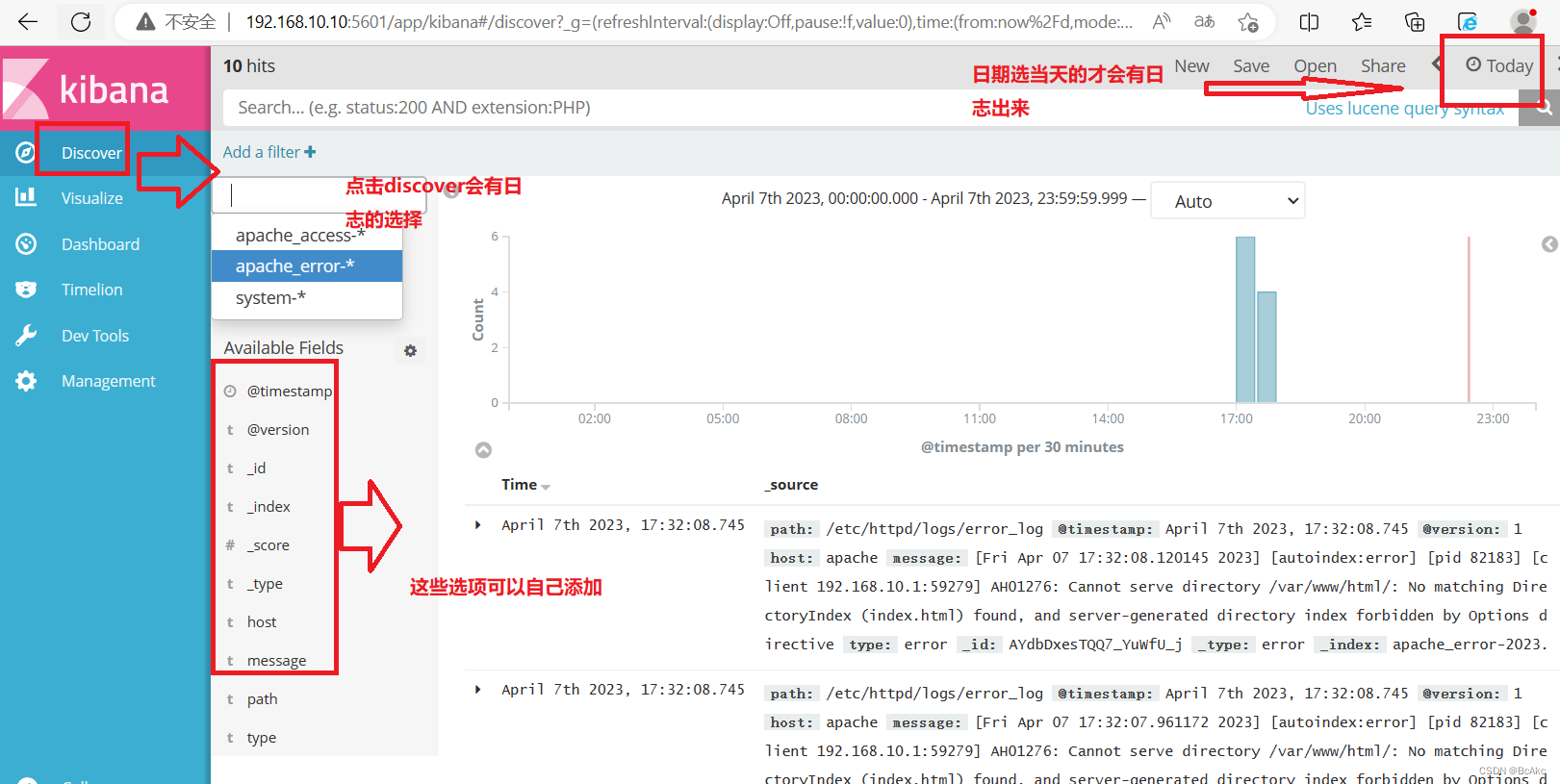
3.8对接 Apache 主机的 Apache 日志文件
Apache(192.168.10.30):cd /etc/logstash/conf.d/
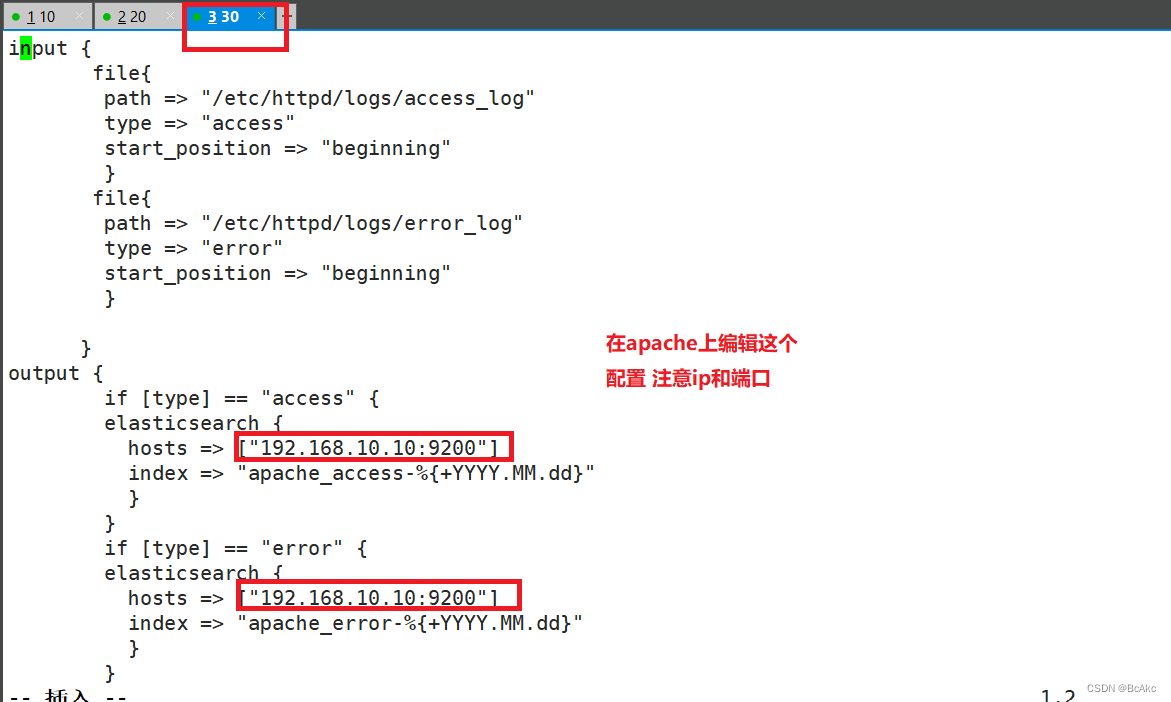
touch apache_log.confvim apache_log.conf
input {file{path => "/etc/httpd/logs/access_log"type => "access"start_position => "beginning"}file{path => "/etc/httpd/logs/error_log"type => "error"start_position => "beginning"}}
output {if [type] == "access" {elasticsearch {hosts => ["192.168.10.10:9200"]index => "apache_access-%{+YYYY.MM.dd}"}}if [type] == "error" {elasticsearch {hosts => ["192.168.10.10:9200"]index => "apache_error-%{+YYYY.MM.dd}"}}}指定文件测试
/usr/share/logstash/bin/logstash -f apache_log.conf
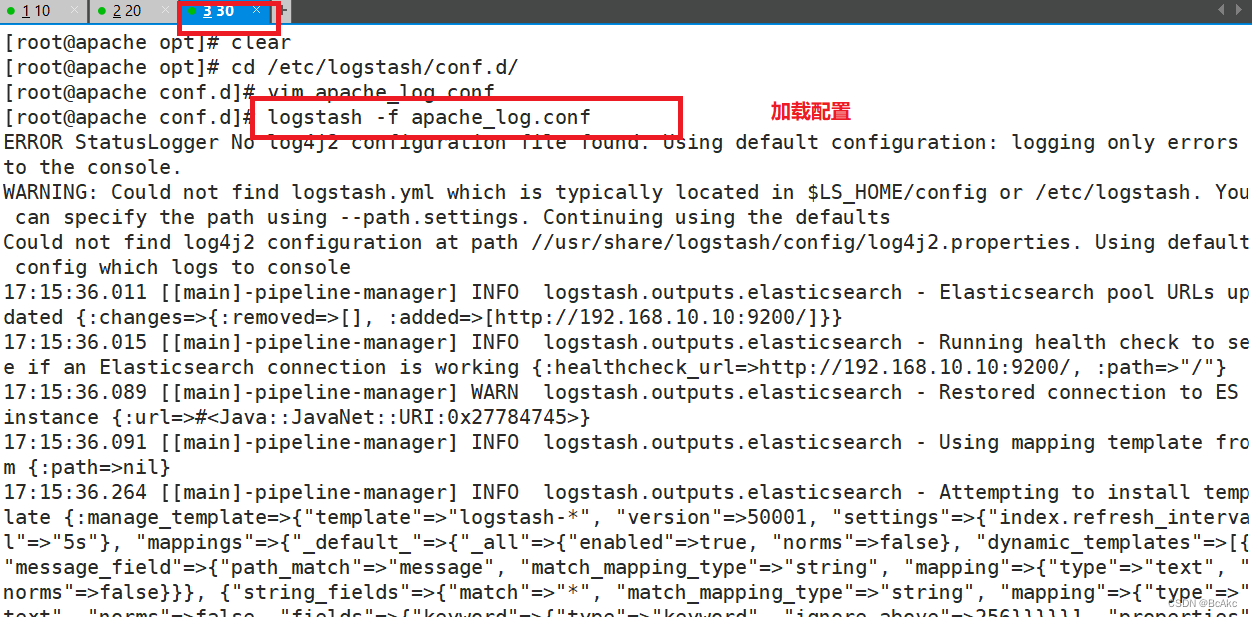
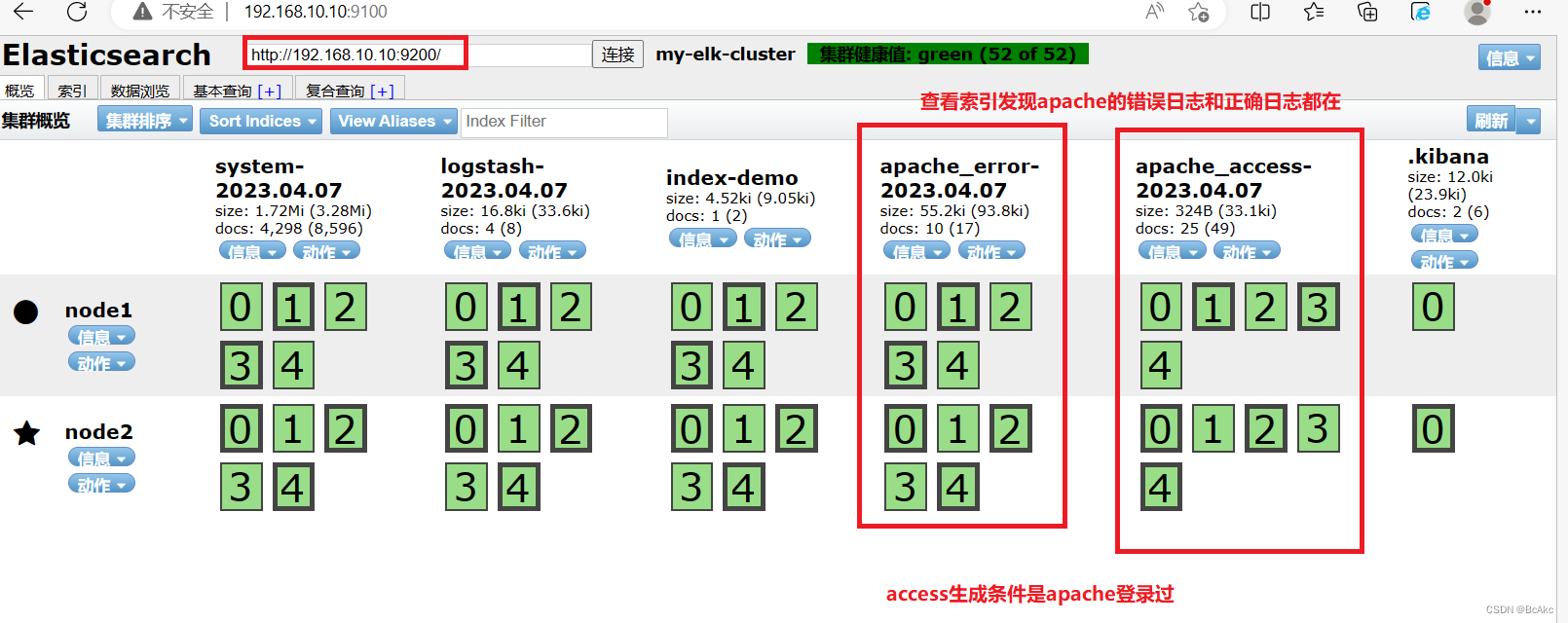
1.宿主机浏览器,输入http://192.168.10.30,访问apache2.输入http://192.168.10.10:9100/,查看索引信息3.输入http://192.168.10.10:5601
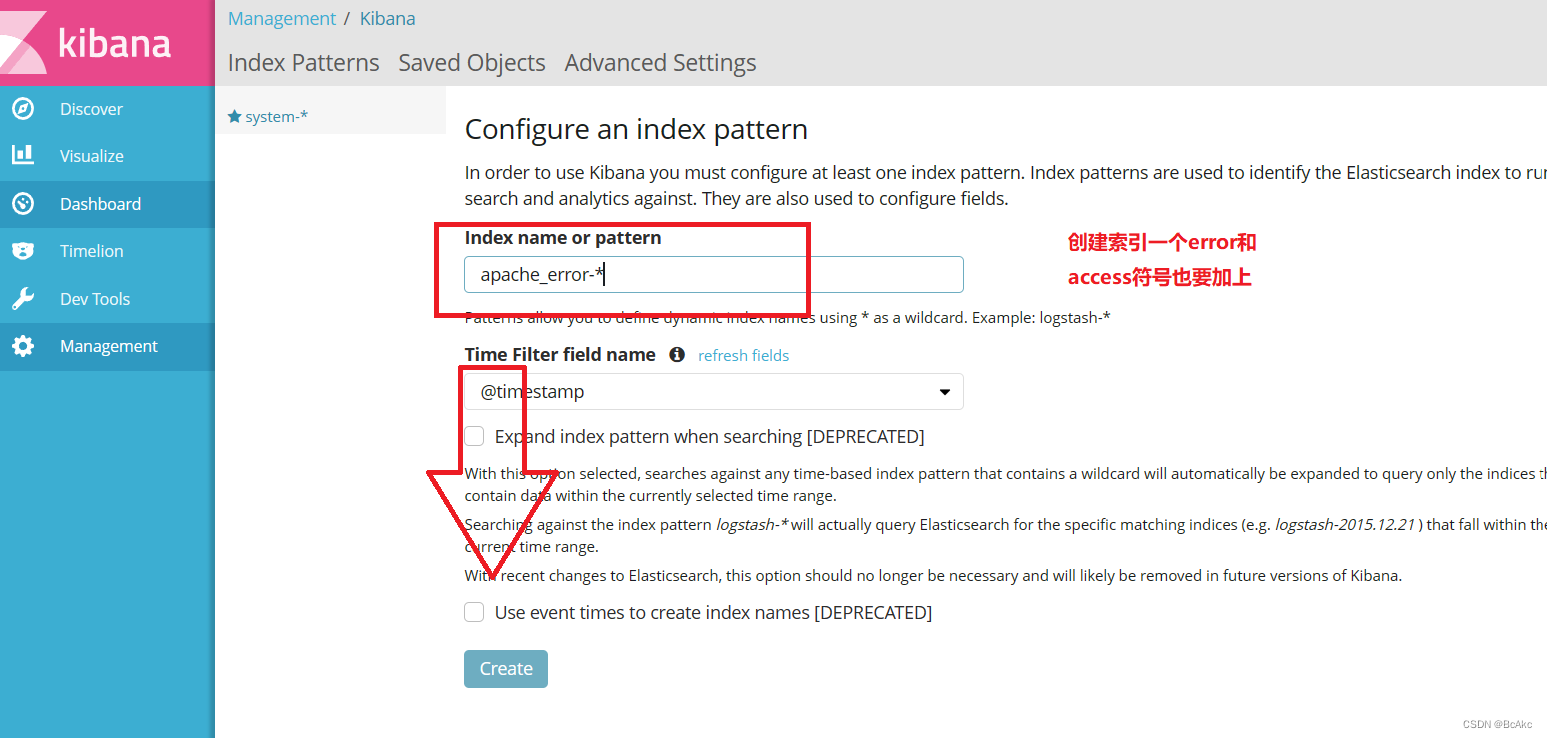
点击左下角有个management选项
index patterns
create index pattern
分别创建"apache_error-*"和"apache_access-*"的索引



![[C++笔记]初步了解STL,string,迭代器](https://img-blog.csdnimg.cn/6687c2c8fdd24eaaac287c971d2436b8.png)