目录
1. Confusion Matrix
2. 其他的性能指标
3. example
4. 代码实现混淆矩阵
5. 测试,计算混淆矩阵
6. show
7. 代码
1. Confusion Matrix
混淆矩阵可以将真实标签和预测标签的结果以矩阵的形式表示出来,相比于之前计算的正确率acc更加的直观。
如下,是花分类的混淆矩阵:
之前计算的acc = 预测正确的个数 / 总个数 = 对角线的和 / 矩阵的总和

2. 其他的性能指标
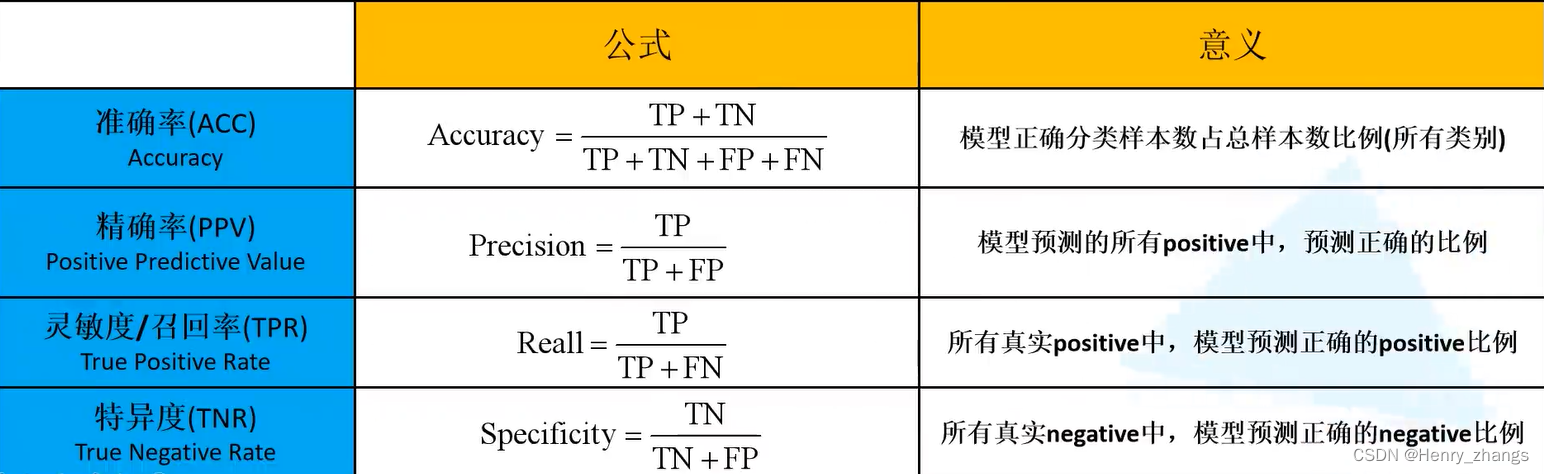
除了准确率之外,还有别的指标可能更加方便的知道每一个类别的预测情况。
在介绍下面的内容之前,需要了解一些名词

其中,T都是True预测正确的,F都是False预测错误的。P是正确的label,N是错误的label
TP和TN都是是预测正确的类别。两者说明网络都可以正常分类,TP是真实值比如是猫,预测也是猫。TN是真实值为非猫,预测的结果也是非猫
FP和FN都是预测错误的。两者说明网络都不能正常分类,FN是说,真实值是猫,预测为非猫,FP是说真实值为非猫,预测为猫
方便的记法,T就是网络正确预测,P就是正确的类别。
例如:
TP,就是网络预测是对的,标签也是对的(猫)。
FP就是网络预测错的,标签是对的类别(也就是label是猫,网络预测是非猫,因为F代表错误的)。
FN就是,预测是错误的,N代表不是真正的标签,所以预测出来的是错误的正样本
TN就是,预测是对的,N代表不是正确的类别,所有预测出来也不是正确的类别
常见的有下面几种性能指标:除了准确率,其余的都是针对特定的类别计算的
3. example
比如,下面的为三分类的混淆矩阵

准确率 = 预测正确的 / 样本的总数 = (TP + TN) / (TP+TN+FP+FN) = (10+15+20)/66=0.68
下面都是针对于猫的其三个指标:
精确率 = TP / (TP+FP) = 10 / (10+1+2) = 0.77
精确度也叫查准率Precision,也就是预测为正样本中,真正正样本的比率
召回率 = TP/ (TP + FN) = 10 / (10 +3+5) = 0.56
召回率是说真正正样本中,预测为正样本的比率
特异度 = TN / (TN+FP) = (15+4+20+6) / (15+4+20+6+1+2) = 0.94
4. 代码实现混淆矩阵
首先,实现一个混淆矩阵类

然后更新混淆矩阵的值,传入预测和真正的标签,横坐标是真实值,纵坐标是预测值
p代表矩阵的行,也就是预测,t代表矩阵的列,就是真实

各项指标的计算

接着打印混淆矩阵

5. 测试,计算混淆矩阵
这里用的是之前的resnet34的迁移学习模型,数据是CIFAR10数据集
首先创建混淆矩阵类,上面注释的是手动编写的类别,下面是json文件提取的
注意这里混淆矩阵类,传入的第一个参数是混淆矩阵的size,也就是分类的个数。labels是一个list列表,存放不同的类名
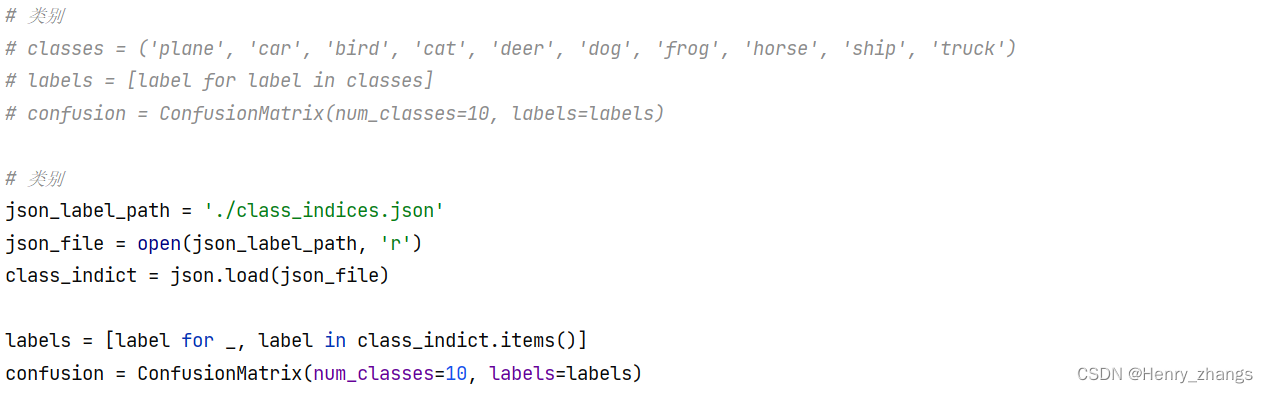
更新打印混淆矩阵

6. show
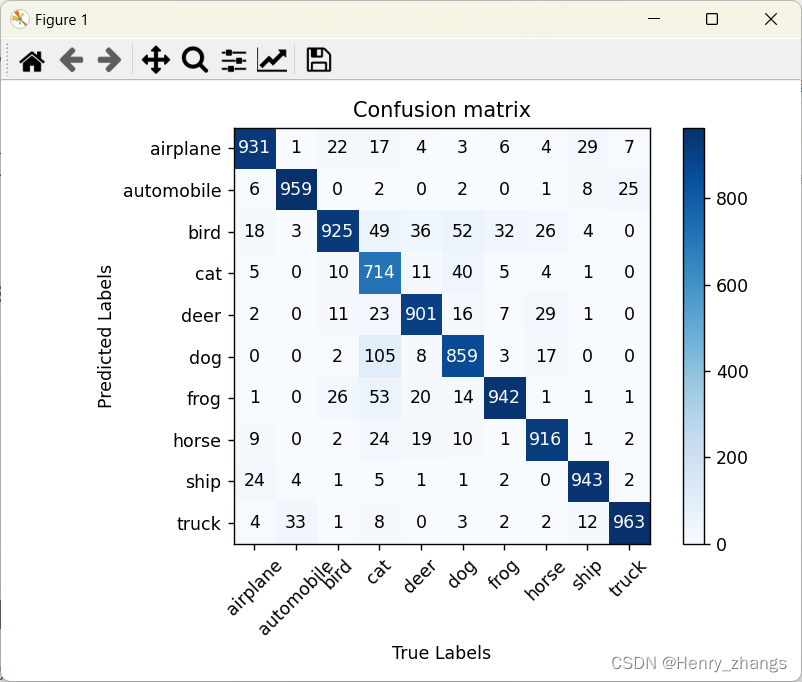
混淆矩阵:
输出控制台:

观察可以发现召回率recall,就是对应对角线的值 / 1000
不难理解,因为recall = TP / (TP+FN),而分母就是label的个数,CIFAR10的测试集有1W张图像,共有10个类别,刚好每个是1k张图像,所有recall的分母都是1k
召回率,真正正样本中预测为正样本的个数
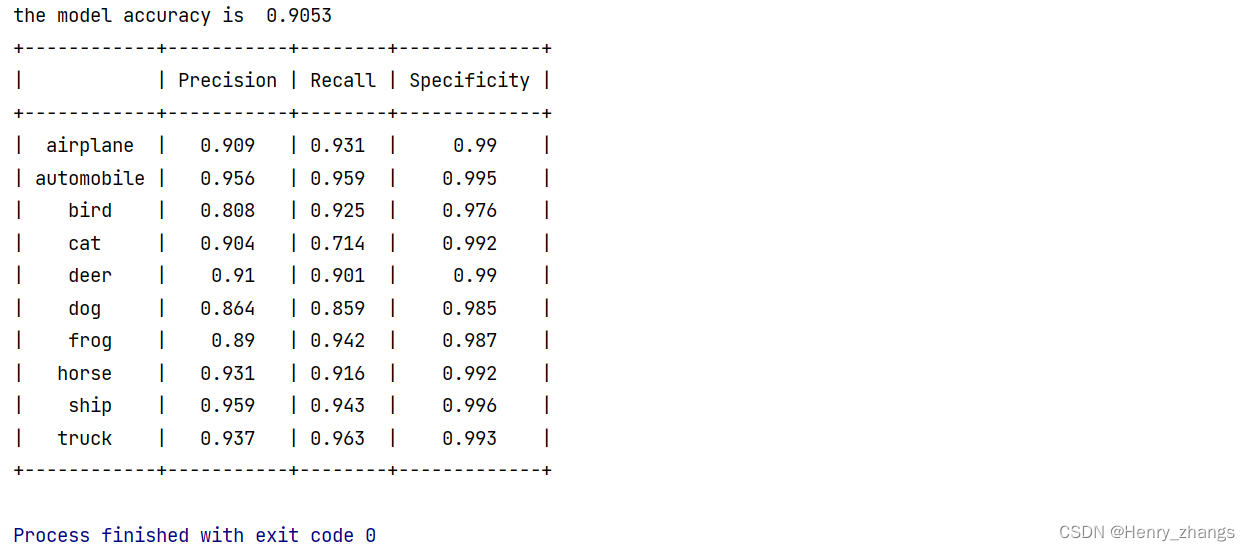
将混淆矩阵输出的图关闭后,会打印性能指标
7. 代码
混淆矩阵放在utils中,utils代码:
import os
os.environ['KMP_DUPLICATE_LIB_OK'] = 'True'import matplotlib.pyplot as plt
import numpy as np
from prettytable import PrettyTable# 计算混淆矩阵
class ConfusionMatrix(object):def __init__(self, num_classes: int, labels: list):self.matrix = np.zeros((num_classes, num_classes)) # 初始化混淆矩阵self.num_classes = num_classesself.labels = labelsdef update(self, preds, labels): # 计算混淆矩阵的值for p, t in zip(preds, labels):self.matrix[p, t] += 1def summary(self): # 计算各项指标# calculate accuracysum_TP = 0for i in range(self.num_classes):sum_TP += self.matrix[i, i] # 对角线的和acc = sum_TP / np.sum(self.matrix) # 混淆矩阵的和print("the model accuracy is ", acc)# precision, recall, specificitytable = PrettyTable()table.field_names = ["", "Precision", "Recall", "Specificity"] # 表格的tittlefor i in range(self.num_classes):TP = self.matrix[i, i] # label为真,预测为真FP = np.sum(self.matrix[i, :]) - TP # label为假,预测为真FN = np.sum(self.matrix[:, i]) - TP # label为假,预测为真TN = np.sum(self.matrix) - TP - FP - FN # label为假,预测为假Precision = round(TP / (TP + FP), 3) if TP + FP != 0 else 0.Recall = round(TP / (TP + FN), 3) if TP + FN != 0 else 0.Specificity = round(TN / (TN + FP), 3) if TN + FP != 0 else 0.table.add_row([self.labels[i], Precision, Recall, Specificity])print(table)def plot(self):matrix = self.matrixprint(matrix)plt.imshow(matrix, cmap=plt.cm.Blues)plt.xticks(range(self.num_classes), self.labels, rotation=45) # 设置x轴坐标labelplt.yticks(range(self.num_classes), self.labels) # 设置y轴坐标labelplt.colorbar() # 显示 colorbarplt.xlabel('True Labels')plt.ylabel('Predicted Labels')plt.title('Confusion matrix')thresh = matrix.max() / 2 # 在图中标注数量/概率信息for x in range(self.num_classes):for y in range(self.num_classes):# 注意这里的matrix[y, x]不是matrix[x, y]info = int(matrix[y, x])plt.text(x, y, info,verticalalignment='center',horizontalalignment='center',color="white" if info > thresh else "black")plt.tight_layout()plt.show()网络model:这里是resnet的代码
import torch
import torch.nn as nn# residual block
class BasicBlock(nn.Module):expansion = 1def __init__(self,in_channel,out_channel,stride=1,downsample=None):super(BasicBlock,self).__init__()self.conv1 = nn.Conv2d(in_channel,out_channel,kernel_size=3,stride=stride,padding=1,bias=False) # 第一层的话,可能会缩小size,这时候 stride = 2self.bn1 = nn.BatchNorm2d(out_channel)self.relu = nn.ReLU()self.conv2 = nn.Conv2d(out_channel,out_channel,kernel_size=3,stride=1,padding=1,bias=False)self.bn2 = nn.BatchNorm2d(out_channel)self.downsample = downsampledef forward(self,x):identity = xif self.downsample is not None: # 有下采样,意味着需要1*1进行降维,同时channel翻倍,residual block虚线部分identity = self.downsample(x)out = self.conv1(x)out = self.bn1(out)out = self.relu(out)out = self.conv2(out)out = self.bn2(out)out += identityout = self.relu(out)return out# bottleneck
class Bottleneck(nn.Module):expansion = 4 # 卷积核的变化def __init__(self,in_channel,out_channel,stride=1,downsample=None):super(Bottleneck,self).__init__()# 1*1 降维度 --------> padding默认为 0,size不变,channel被降低self.conv1 = nn.Conv2d(in_channel,out_channel,kernel_size=1,stride=1,bias=False)self.bn1 = nn.BatchNorm2d(out_channel)# 3*3 卷积self.conv2 = nn.Conv2d(out_channel,out_channel,kernel_size=3,stride=stride,bias=False)self.bn2 = nn.BatchNorm2d(out_channel)# 1*1 还原维度 --------> padding默认为 0,size不变,channel被还原self.conv3 = nn.Conv2d(out_channel,out_channel*self.expansion,kernel_size=1,stride=1,bias=False)self.bn3 = nn.BatchNorm2d(out_channel*self.expansion)# otherself.relu = nn.ReLU(inplace=True)self.downsample =downsampledef forward(self,x):identity = xif self.downsample is not None:identity = self.downsample(x)out = self.conv1(x)out = self.bn1(out)out = self.relu(out)out = self.conv2(out)out = self.bn2(out)out = self.relu(out)out = self.conv3(out)out = self.bn3(out)out += identityout = self.relu(out)return out# resnet
class ResNet(nn.Module):def __init__(self,block,block_num,num_classes=1000,include_top=True):super(ResNet, self).__init__()self.include_top = include_topself.in_channel = 64 # max pool 之后的 depth# 网络最开始的部分,输入是RGB图像,经过卷积,图像size减半,通道变为64self.conv1 = nn.Conv2d(3,self.in_channel,kernel_size=7,stride=2,padding=3,bias=False)self.bn1 = nn.BatchNorm2d(self.in_channel)self.relu = nn.ReLU(inplace=True)self.maxpool = nn.MaxPool2d(kernel_size=3,stride=2,padding=1) # size减半,padding = 1self.layer1 = self.__make_layer(block,64,block_num[0]) # conv2_xself.layer2 = self.__make_layer(block,128,block_num[1],stride=2) # conv3_xself.layer3 = self.__make_layer(block,256,block_num[2],stride=2) # conv4_Xself.layer4 = self.__make_layer(block,512,block_num[3],stride=2) # conv5_xif self.include_top: # 分类部分self.avgpool = nn.AdaptiveAvgPool2d((1,1)) # out_size = 1*1self.fc = nn.Linear(512*block.expansion,num_classes)def __make_layer(self,block,channel,block_num,stride=1):downsample =Noneif stride != 1 or self.in_channel != channel*block.expansion: # shortcut 部分,1*1 进行升维downsample=nn.Sequential(nn.Conv2d(self.in_channel,channel*block.expansion,kernel_size=1,stride=stride,bias=False),nn.BatchNorm2d(channel*block.expansion))layers =[]layers.append(block(self.in_channel, channel, downsample =downsample, stride=stride))self.in_channel = channel * block.expansionfor _ in range(1,block_num): # residual 实线的部分layers.append(block(self.in_channel,channel))return nn.Sequential(*layers)def forward(self,x):# resnet 前面的卷积部分x = self.conv1(x)x = self.bn1(x)x = self.relu(x)x = self.maxpool(x)# residual 特征提取层x = self.layer1(x)x = self.layer2(x)x = self.layer3(x)x = self.layer4(x)# 分类if self.include_top:x = self.avgpool(x)x = torch.flatten(x,start_dim=1)x = self.fc(x)return x# 定义网络
def resnet34(num_classes=1000,include_top=True):return ResNet(BasicBlock,[3,4,6,3],num_classes=num_classes,include_top=include_top)def resnet101(num_classes=1000,include_top=True):return ResNet(Bottleneck,[3,4,23,3],num_classes=num_classes,include_top=include_top)
主函数main:
import torch
from torchvision import transforms, datasets
from tqdm import tqdm
from model import resnet34
from utils import ConfusionMatrix
import jsonif __name__ == '__main__':device = torch.device("cuda" if torch.cuda.is_available() else "cpu")print(device)data_transform = transforms.Compose([transforms.Resize(256),transforms.CenterCrop(224),transforms.ToTensor(),transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])])# 加载数据validate_dataset = datasets.CIFAR10(root='./data',train=False,transform=data_transform)validate_loader = torch.utils.data.DataLoader(validate_dataset,batch_size=16, shuffle=True)# 加载网络net = resnet34(num_classes=10)model_weight_path = "./resnet.pth"net.load_state_dict(torch.load(model_weight_path, map_location=device))net.to(device)# 类别# classes = ('plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck')# labels = [label for label in classes]# confusion = ConfusionMatrix(num_classes=10, labels=labels)# 类别json_label_path = './class_indices.json'json_file = open(json_label_path, 'r')class_indict = json.load(json_file)labels = [label for _, label in class_indict.items()]confusion = ConfusionMatrix(num_classes=10, labels=labels)net.eval()with torch.no_grad():for val_data in tqdm(validate_loader):val_images, val_labels = val_dataoutputs = net(val_images.to(device))outputs = torch.softmax(outputs, dim=1)outputs = torch.argmax(outputs, dim=1)confusion.update(outputs.to("cpu").numpy(), val_labels.to("cpu").numpy()) # 更新混淆矩阵的值confusion.plot() # 绘制混淆矩阵confusion.summary() # 计算指标

![[C++笔记]初步了解STL,string,迭代器](https://img-blog.csdnimg.cn/6687c2c8fdd24eaaac287c971d2436b8.png)