摘要:我们目前看到从可配置性有限的固定功能网络设备向具有完全可编程处理流水线的网络设备的转变。这种发展的一个突出例子是P4,它提供了一种语言和参考架构模型来设计和编程网络设备。这个参考模型的核心元素是可编程匹配动作表,它定义了网络数据包的处理步骤。在本文中,我们演示了这些表,我们使用它们来创建自己的建模框架,它们是设备性能的关键驱动因素。
P4可编程器件有各种各样的底层硬件架构,如基于CPU的系统或ASIC,代表了这两个领域的两端。基于CPU的P4目标平台性能有限,但易于扩展。ASIC P4目标拥有专用的P4处理流水线,可编程性有限,但性能高度优化。为了反映这些基本差异,我们的建模框架结合了不同的方法来精确地建模和预测支持P4的设备的性能。

01
INTRODUCTION
2014年,博斯哈特等人[1]引入了P4,一种用于软件可编程网络设备的特定领域语言。随后,各种支持P4的硬件和软件设备出现了。只要有合适的P4程序,这种设备几乎可以承担任何数据包处理任务,只受其特定硬件能力的限制。本文分析了这种高度灵活和可扩展的分组处理系统的性能,即延迟、抖动、吞吐量和资源消耗。
Dang等人[2]和Rotsos等人[3]使用基准来确定网络设备的性能。他们的结果表明,网络设备可以根据其专业化程度进行分类,例如,为特定目的构建的高度专业化的ASIC或依赖于通用处理器的灵活的基于软件的设备。
我们的论文调查了两个设备组的两个不同代表的性能。作为硬件目标,我们分析了一个专门构建的英特尔Tofino交换ASIC。由于高度的并行性和缺乏缓存,该设备在性能方面表现突出。由于其固定数量的可编程流水线级,实现了硬件目标典型的低延迟、低抖动特性。资源限制因素是所需功能的复杂性和使程序适合目标资源。我们的软件目标使用t4p4s P4编译器,它产生DPDK兼容的[4]代码,运行在商业现成的(COTS)基于CPU的系统上。这是典型的CPU系统,t4p4s行为受许多因素影响,包括中断、内存层次和缓存大小[5]。虽然实现了更低的吞吐量和更高的延迟,但优势在于P4程序的复杂性和定制功能实际上没有限制。
在P4,数据包处理任务表示为数据包或元数据上的一系列匹配和操作。作为每个P4程序的中心,匹配动作性能对于理解整个分组处理流水线的性能至关重要。因此,我们分析这个组件时特别关注不同目标平台之间的差异。基于我们的测量,我们推导出两个被调查目标平台的性能模型,反映了每个平台的单独硬件限制。
本文的贡献可以总结如下: 提供了一个关于最终用户感兴趣的属性的P4目标的细粒度分类。深入分析了P4项目的匹配动作表,最后介绍了一种基于其核心组件——匹配动作表来预测P4设备性能的新型建模技术。
本文其余部分的结构如下。第二节讨论相关工作。第三节讨论了P4的背景、关键性能指标和目标设备的特性。我们的方法和测量设置分别在第四节和第五节中介绍。随后,第六节详细阐述了我们的CPU性能模型,而第七节介绍了我们的ASIC资源模型。第八节是本文的结论。
02
相关著作
由于作为理解网络设备的性能特征的手段的基准测试的概念被很好地探索,所以存在各种相关的讨论。
Rotsos等人[3]介绍了OFLOPS,一个OpenFlow交换机的基准测试套件。他们的套件用不同的OpenFlow规则对交换机行为进行了基准测试。他们指出,OpenFlow交换机的不同硬件和软件实现之间的交换机性能有很大差异。Dang等人[2]提出了一个类似基准测试套件的想法,但专门针对具有P4功能的设备(如CPU或FPGA)进行性能评估。比较P4的广泛实施,他们仍然在他们的表现调查抽象,但集中在P4程序的组成部分。
除此之外,我们提供了针对P4表的见解,重点是P4的最新版本,即P416。
舒尔茨等人[6]对外部P4函数的不同实现方式的性能进行了深入的讨论,即加密图形散列法。它们为不同的P4目标增加了外部散列功能,即CPU、NPU和FPGA。此扩展的性能影响通过全面的基准测试进行调查,揭示了每个平台的巨大性能差异。此外,他们表明,该功能最多只需要目标总资源的2 %。在对Netronome智能网卡的P4实现的性能研究中,Harkous等人[7]探讨了报头解析和修改的影响以及匹配动作表应用的影响。他们提出了一个描述高吞吐量场景中可观察到的延迟的模型。我们通过增加研究参数的粒度来改进所提供的见解。此外,不同目标之间的比较将个人的测量放在适当的位置。Geyer等人[8]在航空电子应用的背景下研究P4。他们在不同的目标上对P4航空电子全双工交换以太网(AFDX)的实现进行了基准测试。他们的调查显示,目标平台之间的延迟不同,但延迟与现有的专用AFDX硬件相当。
P4的一个吸引人的特性,不仅仅是对航空电子设备,是它的设计促进了程序行为的简化验证,例如,在P4没有环路。刘等人[9]和内维斯等人[10]演示了使用断言来识别应用程序中的错误的程序的验证。诺特兹利等人[11]采用了一种不同的代码正确性方法。基于P4程序,他们自动创建测试用例来检查正确的程序编译。我们的P4设备模型将预测从正确性扩展到了性能 。
前面的例子表明,P4程序的性能是高度特定于目标的。因此,我们的论文以特定于目标的方式测量这些属性。我们的建模方法也反映了目标的特异性,提出了基于所研究平台的根本不同的硬件架构的模型,从而实现了更准确的预测。
03
可编程网络设备
> P4 Programming Language
P4提供了一种新的方法,允许网络运营商对定制的网络设备行为进行编程。这是一种以数据包为中心的语言,侧重于应用匹配动作表。抽象架构模型定义了一系列控制块。这些控制块由一个解析器(从位序列构造数据包)和它的对应部分组成,执行依赖于报头的动作和数据包修改。因此,解析器、匹配动作控制块,和deparser 描述了P4架构基本组成部分。具体来说,例如可用控制块的数量、附加元信息或附加功能的可用性,在不同的网络设备之间有所不同。因此,P4介绍了硬件的抽象表示,总结了它的设计和功能。
P4的核心是匹配动作表。它们被设计成允许组合多组关键字,例如特定的标题字段,以确定动作。表条目在运行时由控制平面提供。可以将一系列不同的匹配动作表应用于分组,以实现分组处理任务。[1]
> 关键性能指标 (Key Performance Indicator, KPI)
关键性能指标概述了网络硬件感兴趣的属性。在本次讨论中,我们区分两组关键性能指标:
① P4 target selection properties P4目标选择属性是确定满足预期服务质量水平的P4目标的相关标准。这些属性包括资源消耗、功能性和设置时间(resource consumption, functionality, and setup time)。根据程序的复杂性,资源消耗可能会限制能够运行程序的潜在设备。与此相反,功能性指的是设备对标准化P4功能以及附加功能的支持——通过所谓的P4外部设备提供。如果所需的外部环境不可用,定义自定义功能的能力可以提供一个替代方案。最后,设置时间是部署和启动P4程序和设备所需的时间。假设大多数P4设备很少被提供,我们忽略这个非功能性属性(包括编译时)来进行讨论。
用性能要求选择底层硬件实现
② Runtime properties 运行时属性主要通过吞吐量、延迟和抖动来定义。典型地,一个目标是最高的可用吞吐量,这仍然允许设备运行而不受分组丢失的损害。与此相反,延迟应该保持尽可能低,而数据包延迟的变化,即观察到的抖动,应该尽可能小。我们将设备入口和出口端口之间的延迟以及抖动视为该延迟的波动。
> Classes of Programmable Devices
P4可用于各种可编程器件。表1提供了使用第三节中定义的关键性能指标的概述。基于通用COTS CPU,这些系统使用软件实现来提供任意功能。虽然这通常是以性能为代价的,但它在功能性和复杂性方面提供了灵活性。CPU的处理能力限制了这些系统的吞吐量,中断和缓存效应可能会影响延迟和抖动。
NPU是一个多核架构,由针对数据包处理进行优化的内核组成。可编程网卡可以配备这样的NPU。其优化的体系结构提供了高吞吐量性能和始终如一的低延迟。然而,由于网络处理器是特殊的硬件,比固定功能的网卡有更少的尺寸,这些好处是以降低灵活性为代价的。
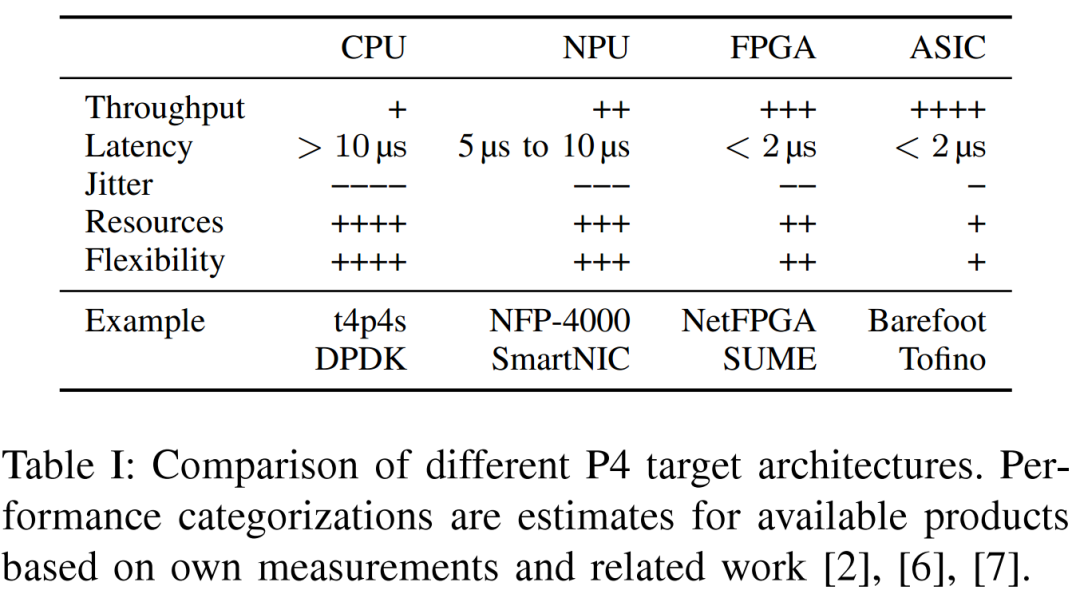
可通过硬件描述语言(HDLs)编程,FPGAs可编程以提供几乎任意的功能。仅受基本硬件限制(如内存资源和时序限制)的限制,FPGAs在吞吐量、抖动和延迟方面通常优于以前的目标架构。虽然从理论上讲,FPGAs是一种高度灵活的架构,但编程需要特定于硬件的知识,在HDL中实现网络算法变得非常耗时。
与所有以前的平台相比,ASIC(ASICs)有一个专门构建但有限的指令集。通过优化,例如高度并行性,它们在处理方面表现出色,即吞吐量、延迟和抖动。然而,ASIC指令集的有限表达能力也限制了它们在功能实现方面的灵活性。
虽然存在其他体系结构,但以上是文献中最常见的目标。此外,他们在正在开发或已经上市的商业产品数量上得分。在讨论的目标中,一方面是运行时属性和成本之间的权衡,另一方面是灵活性和资源限制。
04
方法学
我们从一个完整的P4项目过渡到自上而下的独立组件。我们的工作集中在P4的主要特点:匹配动作表的表现。
> P4 Program Components
P4的核心原则之一是将数据包处理分割成分离的可编程块[2],例如,解析器、匹配动作流水线和deparser。这反映在语言和架构模型中,定义了具体目标的阶段。遵循这种严格的模块化,我们分别研究每个P4阶段。我们认为,个别P4阶段的模型可以在以后组合起来,以代表完整的P4程序。组合模型的性能预测可用于验证单个P4阶段模型。
我们的性能分析考虑了复杂性不断增加的多个P4程序。最初,一个基线P4程序被导出,它包括尽可能少的功能,同时仍然允许性能测量。随后,通过匹配动作表扩展基线程序,由此在连续的测试中,表的不同属性被缩放和基准化。这些程序中的每一个,通过修改单个属性(例如,匹配键或表条目的数量),都不同于公共基线程序。由此,我们导出了匹配动作表组件的性能模型。最终,组合单个组件的模型有助于通过将程序的行为描述为应用组件的总和来建模任意程序。这种建模方法的结果是,随着所描述的组件属性的粒度的增加,所得到的模型的精度预计会增加。
> P4 Match-Action Table Properties
应用所提出的用于性能建模的调查组件属性的方法,匹配动作表的下列参数被识别:
(1)表的匹配类型——精确的、最长前缀匹配(LPM)或ternary——其确定分组报头或元数据字段值和可用表条目之间的比较模式;
(2)单个表条目的大小,由键的大小和数量、动作的数量以及动作数据来定义;
(3)匹配动作表中的条目数;
(4)P4程序中匹配动作表的总数。
对所有参数的组合进行实验评估,例如测试不同的键宽度,是不可行的。因此,我们确定影响最大的参数,并将其作为建模的重点。
05
Measurment Setup
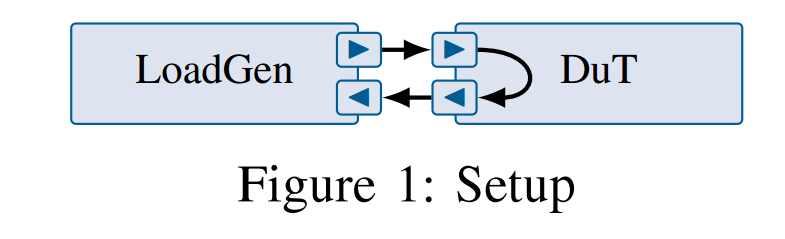
测量以自动化和可复制的方式进行[12]。图1显示了由两个节点组成的设置,负载发生器和被测设备(DuT),它们直接相连。我们使用MoonGen [13]作为负载发生器,用于吞吐量和精确的延迟测量。DuT的配置在相应的章节中给出。
06
Performance Model (基于CPU的)
我们使用基于DPDK的t4p4s P4交换机作为我们性能模型的基础[14]。与其他可用的P4目标体系结构相比,它在COTS CPU系统上运行,具有高度动态的吞吐量和延迟特性,因此需要对这些关键性能指标进行深入分析。t4p4s P4编译器生成独立于目标的C代码,然后可以与为不同平台提供特定于目标的代码的库相链接。一个这样的库使用DPDK,这将在下面的讨论中介绍。我们使用上游的t4p4s版本(commit 919c521 [15]),由于性能或功能的原因,有一些小的变化。运行交换机的DuT配备了时钟频率为2.0 GHz的英特尔至强处理器E5-2640 v2和英特尔X540-AT2网卡。对于所有测量,turboboost和超线程被禁用,以减少性能抖动。我们讨论了CPU周期、端到端延迟和资源。
> Resource Utilization
对于基于CPU的系统上的P4程序来说,内存消耗通常不是问题,因为现代服务器可以提供高达TB范围的内存。但是,当涉及不同级别的缓存时,内存的实际使用会对性能产生影响。对于包含大量条目的表,即大型BGP路由表,可能会出现这种情况。因此,我们使用白盒评测来分析内存消耗的影响,并将结果作为我们的性能模型的一部分。
> Baseline Model
我们使用图2所示的双重方法来确定CPU目标的基线模型。第一步(实心蓝色箭头,称为无P4)不包括任何与P4相关的代码,只专注于使用DPDK接收和发送数据包。这是为了了解底层DPDK运行时的性能开销。第二步(绿色虚线箭头,称为基线)添加了一个最小的P4管道,每个数据包都经过这个管道,它只包含一个最小的解析器和一个解析器,静态地设置出口端口,而不使用匹配动作表。和以前一样,目标是理解通过P4样板代码生成的处理开销,即使P4程序没有进行实际处理。我们将此基线模型用于表格组件的所有进一步测量。
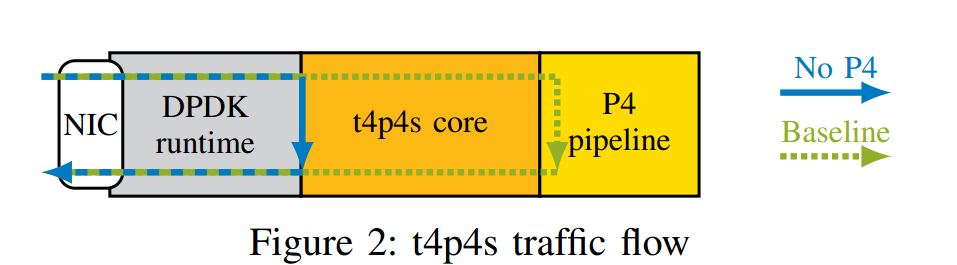
图3显示了处理后的数据包速率随CPU内核频率的变化。在1.3Ghz时,无P4程序受到10Gbps线路速率的限制。简单地添加由最小P4程序生成的样板代码可以将数据包速率降低大约6 Mpps。增加一个内核的CPU频率或使用多个内核进行处理会导致线性扩展,受线速限制。更高的频率等于每秒更多的CPU周期,允许在相同的时间间隔内进行更多的数据包处理操作。

在本文的剩余部分,我们使用测得的最大数据包速率来计算每个数据包的周期,基于CPU频率

一个包的整体处理需要大约,无P4和基线方案分别为84和146个周期,这在DPDK数据包处理的预期范围内[5]。对于所有进一步的实验,CPU的时钟频率为2Ghz,我们假设等式(2)为基准CPU周期消耗:
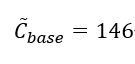
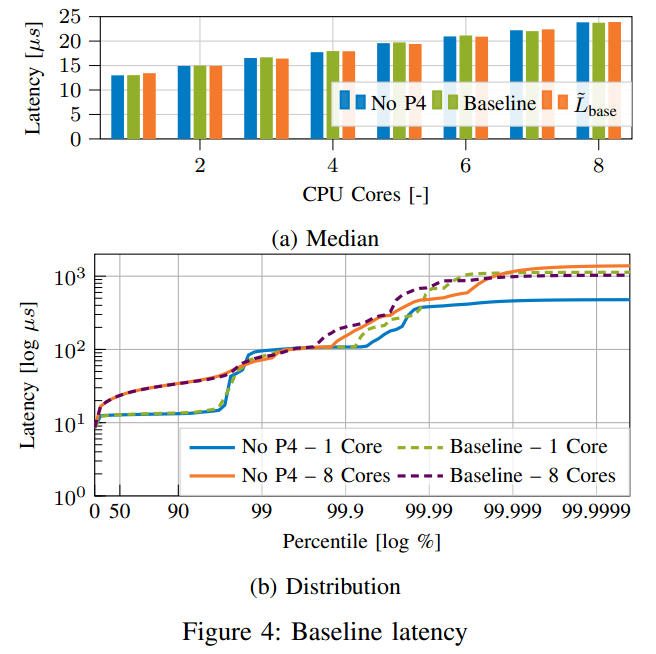
中值延迟,如图4所示,随着CPU内核数量的增加而线性增加。这是因为DPDK的批量处理。虽然批次大小保持不变,但增加核心数量也会增加处理的批次数量。保持恒定的包速率会导致每批填充随着内核数量的增加而变慢,从而导致更长的延迟。两种情况(每个数据包62个周期)的处理差异导致延迟在2 GHz时差异约为为31 ns。图4b中的高动态范围直方图显示了基于CPU的系统的典型延迟分布。在最坏的情况下,每100us处理一次批次[15],导致第99百分位的平稳状态,系统中断和其他副作用导致长尾[16],这种长尾在所有后续测量中持续存在。
基于图4a,我们使用线性回归来模拟基线中位延迟
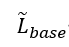
与时钟频率为2 GHz的CPU内核数量的关系:
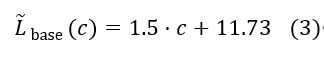
该基线用于评估和比较在P4程序中利用匹配动作表添加P4指令的影响。
> Number of Table Entries
对于许多P4应用程序来说,表条目的数量是一个关键因素。由于与硬件目标相比,CPU目标具有充足的内存,因此我们可以不严格限制表条目的可能数量。一个真实的例子是BGP IPv4路由表,它的唯一可路由前缀的数量稳步增长,在2020年初达到800K个IPv4条目[17]。
P4支持3种不同的匹配类型:精确匹配、三元匹配和LPM匹配。在硬件中,匹配类型使用专用硬件来实现,例如,用于三进制和LPM匹配的三进制内容可寻址存储器(TCAM)。在软件中,使用了不同的算法,这些算法在限制和预期性能方面具有不同的特性。软件的第二个重要方面是存储和访问表项所需的内存,即内存层次结构对性能的影响。

图5描述了不同匹配类型的最大处理包速率,使用至多8个CPU核。像基线程序一样,性能与使用的CPU内核数量成线性比例。表条目基本由一个4 × 4 B匹配关键字组成,除了LPM匹配使用1 × 4 B关键字。缓存(Caches)可以通过保存高概率查询的条目来加速内存访问。我们的目标是一个具有挑战性的场景,因此,我们的流量是这样生成的,即每个数据包都命中另一个表条目。

a) 精确匹配类型:图5a显示了直到条表项时,性能是逐渐下降的;添加更多条目会显著降低性能,导致处理的数据包速率减半。这是由于内存层次结构,特别是图6所示的L3缓存未命中,需要访问慢速主内存。根据表项数、键大小(以Bytes计)和动作(以Bytes计)的大小,检查等式(4)中精确匹配的实现结果,以对精确匹配表所需的资源Reexact(以Bytes计)进行建模:

上式中是由于高速缓存行对齐。使用k = 16 B、a = 64 B(高速缓存行对齐)和R弧(因公众号原因,所有字母上面的符号用文字表示,下同) = 20 MB =R弧下标L3 (所用处理器的L3高速缓存大小)求解等式(4)得到220000的条目来填充L3高速缓存(参见图6中的标记)。这是一个过高的估计,因为高速缓存不仅用于表条目,还包括数据包数据。类似地,性能下降约30和500,这是与L1和L2缓存大小大致相关的条目数。但是,由于这两个缓存之间的访问时间差小于5 ns,因此性能损失不如超过L3缓存大小时那么明显[18]。
虽然我们会生成每个数据包都命中另一个条目的流量,但这并不是哈希表查找的最坏情况。哈希表中的理论搜索复杂度平均为常数(O(1)),因此影响性能的主要因素是内存访问,特别是当超过L3缓存大小时。使用一个CPU内核的数据,我们首先使用最小二乘曲线拟合导出一个包速率模型(如图5中的P弧下标e,<type >)。由此,我们推导出精确匹配条目(C弧下标e,exact)的每个包的周期(图5中显示为C弧下标e,<type >),与4×4 B表条目的数量n和CPU的数量c的关系:
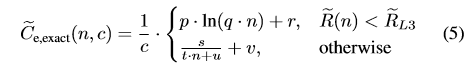
参数p,…,v的具体值列在表二中,与不同的匹配类型无关。图5a显示,在扩展CPU内核时,该模型保持准确。
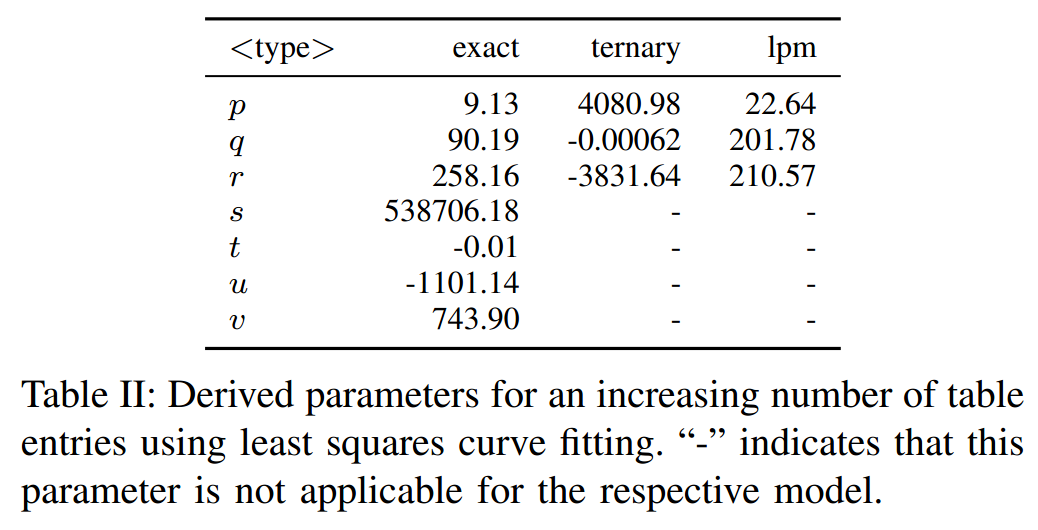
b)Ternary Match Type 由于缺乏像TCAM这样的专用硬件,在软件中实现三值匹配比较困难。t4p4s的当前实现只是遍历表条目列表,直到找到匹配的条目,这导致了指数级的搜索复杂性。由于在这种情况下表条目的数量较少(<1000),内存访问对性能没有明显影响。这可以在图5b和我们导出的模型方程(6)中看到。

c)LPM match type t4p4s使用DIR-24-8数据结构[19]用于32位密钥大小(IPv4 LPM)。虽然使用不同的数据结构来允许128位密钥(IPv6 lpm),但我们主要关注前者。DIR-24-8使用两种不同的表,tbl24是一个表,最多存储2的24次方个条目中前缀的最高有效24位。默认情况下,第二类表(tbl8)是2的8次方个表项,用于存储剩余的8位。≤ 24位的前缀长度可以通过在第一个表中进行一次查找来解决,较长的前缀需要在相应的tbl8中进行第二次查找。DIR-24-8假设前缀长度大于24位的路由很少,优化了较小前缀长度的查找,同时限制了可以存储的大于24位前缀的数量[19]。
这个算法更新可能比较复杂,因为短的前缀可能影响很多长的具体表项。
图5c显示了仅使用24位前缀时的结果。插入超过250K个条目需要相当长的时间,因此不包括这些测量值。测量显示的是对数而不是理论常数标度。与精确匹配一样,缓存大小,尤其是L3缓存,是限制因素。已经有200个表条目,30%的查找是DRAM绑定的,需要从主存储器中提取数据(见图7)。这是由于DIR-24-8结构的尺寸增加,因为tbl24已经需要64 MB [19],[20]。因此,共享的L3缓存由每个内核的DIR-24-8结构填充。硬件架构施加的这些限制导致了使用的CPU内核数量的次线性扩展,导致了基本情况下的等式(7)。
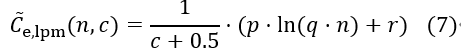

前缀长度的影响如图8所示。我们向tbl8添加了一个恒定的256个30位前缀,这样每个表匹配现在都由两次查找组成。对于少于200个条目,性能的提高是显而易见的。然而,这一增加是由于256个表条目的静态增加。当增加表条目的数量时,额外的256个条目的成本摊销,将额外查找的成本留在tbl8中。为简单起见,我们不包括模型中的额外成本(大约。对于超过1000个条目,准确性损失6 %)。
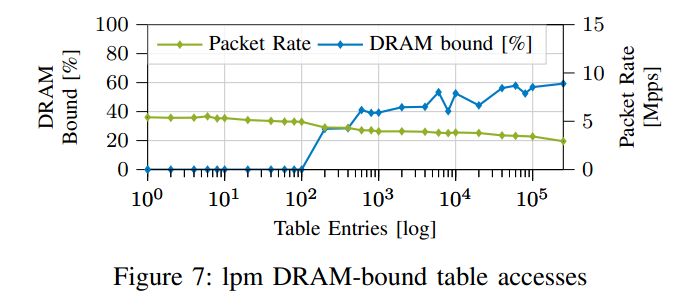
d)latency 延迟:图9显示了对越来越多的表条目的延迟测量。该行为与上一节的性能结果相当。只有当最大处理包速率由于内存或算法限制而大幅下降时,与基线模型基数的偏差才是明显的。3个或更少内核的精确匹配和lpm匹配就是这种情况。此外,对于单个内核,具有1K个和10K个条目的三值匹配的中值延迟分别提高到50us和80us以上。除了三进制匹配外,所有测量中下部晶须(1.5个四分位范围)保持不变,而上部晶须随着表格条目的数量而增加。这可以用L3缓存未命中的增加来解释,这导致在访问正确的内存之前,数据包被停止的可能性更高。
> Increasing Table Entry Size
可以通过增加key的大小或数量,或者通过增加action data,来增加table entry的大小。在这两种情况下,这都会改变R弧的参数k和a,因此,当达到L3缓存限制时。我们的实验表明,情况确实如此。然而,对于ternary表和LPM表,已经讨论过的各自表实现的局限性超过了这种影响。
> Table Key Segmentation
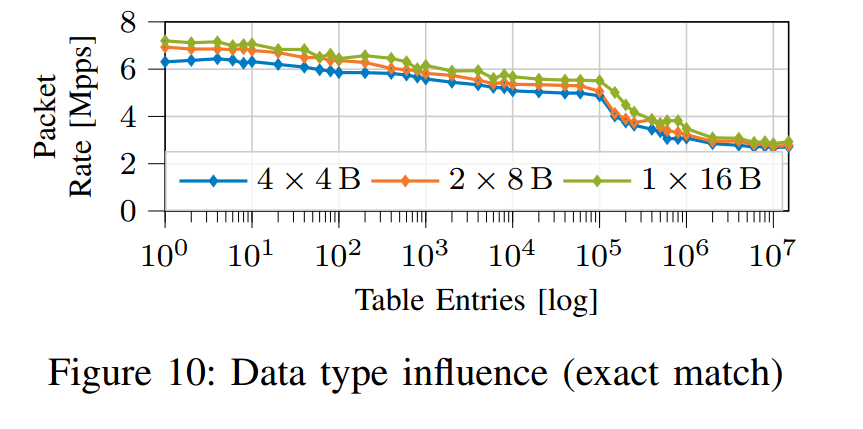
在基于CPU的系统上,用作匹配键的数据可以使用不同的数据类型来表示。图10显示了使用2 × 8 B或1 × 16 B数据结构而不是用于表示的4 × 4 B数据结构表示key时的包速率。由于总密钥大小相同,我们可以排除内存访问是性能差异的原因。事实上,性能分析表明,4×4 B密钥分段的性能降低是特定于体系结构的。在这种情况下,存储转发(Store Forwarding)是一种性能增强功能,它允许将先前的内存写入转发到后续的内存读取,而不必将值写入主内存[21],但由于将数据错误地传递给哈希函数,该功能在100 %的情况下失败。对于我们的CPU架构,这将导致12个时钟周期的性能损失[21]。优化t4p4s生成的代码将允许存储转发成功,产生更好的性能。虽然这种影响会对性能产生影响,但为了简单起见,我们不将它包括在我们的模型中。相反,我们对所有测量使用最坏情况(默认)的关键分段。
> Number of Table Applications
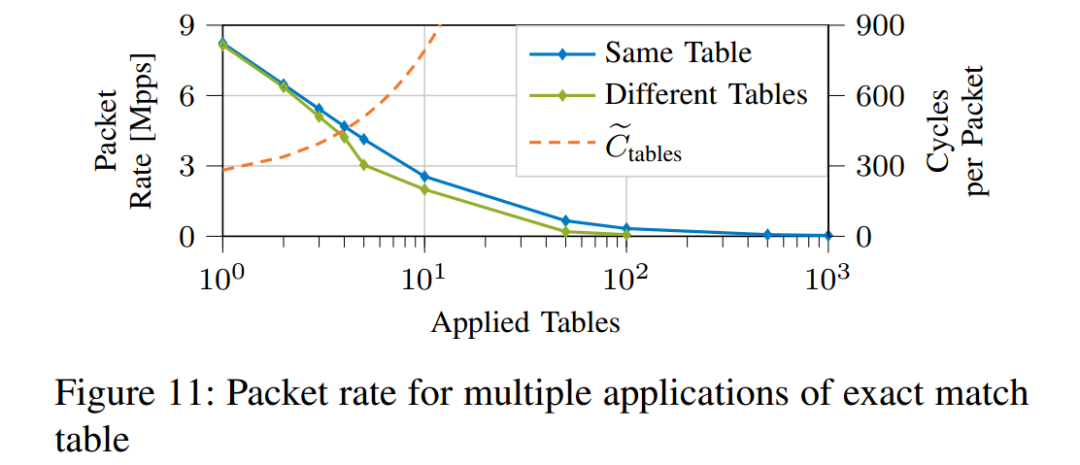
我们分析的最后一个属性是P4程序中应用的表的数量。虽然硬件P4目标通常不允许每个数据包多次应用同一个表,但t4p4s中不存在这种限制。这种灵活性允许对实际表应用程序(即哈希计算)的成本进行更接近的估计,而无需为键和条目提取数据。对于连续的表应用程序,提取的数据是相同的,得到缓存并摊销所需的周期。因此,我们分析两种情况,应用相同的表t次,应用不同的表t次。每个表都用一个4 × 4 B匹配键填充一个条目。
如图11所示,包速率随着应用的表的数量而线性下降。增加每个应用表的条目数(未示出)会导致图5a中讨论的效果,其中存储器访问增加了每个包的周期。应用相同或不同的表之间的差异很小,因此我们专注于应用相同的表。表应用程序循环模型显示,每个表应用程序每个包增加57个循环:
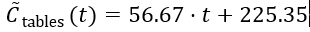
主要因素是计算用于访问表的哈希的成本,因为加载输入数据和结果的成本是通过缓存分摊的。
07
ASIC Resource Model
我们使用商用的Intel Tofino 1 ASIC Delta ET-X064FFRB,作为P4可编程硬件进行资源建模;它支持64个100GbE端口。
> 性能
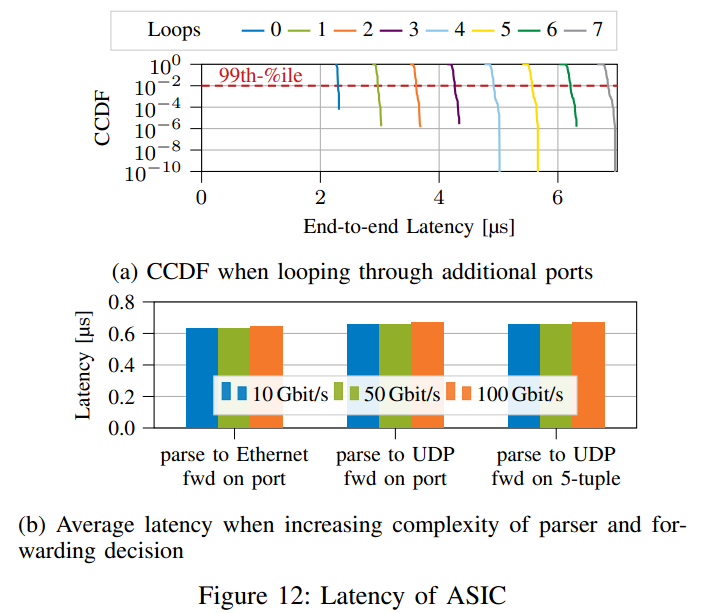
我们使用10Gbps网卡和英特尔Tofino的数据包复制功能来产生100Gbps的流量。此设置中的基线端到端延迟约为2us。当通过回送电缆通过越来越多的100Gbps以太网端口循环100Gbps的流量时,延迟会线性增加(参见图12a)。实际上,每增加一个环路,就会增加ASIC的负载,但是延迟保持稳定,在更高的负载下不会出现长尾现象。
如图12b所示,增加P4程序的复杂性会产生纳秒范围内的延迟变化。这种行为甚至在更复杂的场景中也持续存在,因此我们关注ASIC目标的资源消耗。
Tofino ASIC对于复杂协议的处理做的很好,处理变复杂,延迟没有很大变化。
> Available Resources
ASIC通常提供大量负担得起的SRAM。出于特殊目的,使用少量更昂贵的TCAM。根据匹配类型,这些资源用于创建P4表。精确匹配是在SRAM上实现的,而ternary或LPM匹配在TCAM效果最好。SRAM和TCAM的数量是固定的,不仅限制了P4程序的复杂性,而且限制了表的大小,特别是使用三进制或lpm匹配的表。
> Table Resource Model
如第六节所述,我们已经确定了影响ASIC上P4表资源消耗的三个主要因素。单个条目由键宽度k(对于特定匹配类型)和总动作a(查找结果)引起的成本R杠下标width定义;这个成本进一步地用表项条目数n扩展,进而得到总的成本:
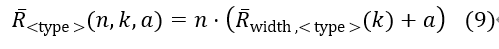
动作数据a可以是P4程序中定义的任何数据结构,因此变化很大,很难衡量其资源成本。因此,我们将其作为未知变量,并假设其与动作数据大小成线性比例关系。然而,我们详细观察了不同键宽度的影响,以验证我们的线性相关性假设。由于硬件限制,每个数据包只能应用一次表,因此P4管道的所有表所需的资源都是单个表成本的总和。
> Key Width Resource Cost

我们已经测试了P4程序,该程序包含一个单独的表,该表具有不同的键宽度,适用于我们测试设备上的所有匹配类型。当增加表条目的数量时,资源消耗是一个离散的阶梯函数,我们用一个线性函数来近似(见图13a的精确匹配)。键宽度增加了该近似函数对资源使用的倾向。由此,我们为每一种匹配类型插入增加键宽度的梯度,如图13b所示。
为简单起见,我们假设一个表只使用一个匹配键。但是,该模型可以通过将每个匹配关键字的成本相加,然后乘以表条目的数量来扩展。
我们只依赖于使用的总键宽度,而不是键分段和表键的数量。因此,我们可以使用等式(10)来表示不同键宽度的资源使用情况:

其中p是梯度,q是插值函数的偏移,取决于匹配类型。我们测试的设备的具体值列于表3;请注意在我们的测试中,三元匹配和LPM匹配的占用是相同的。解释是LPM是三值匹配的特例,因此硬件实现可能是相同的。

08
结论
网络性能是网络基础设施提供商主要关心的问题。虽然网络基础设施管理方面的变化,如SDN或P4,开辟了新的可能性,但性能仍然相关。我们的贡献是为基于硬件和软件的P4目标提供了一套性能模型。根据目标的类型,目标体系结构的不同方面变得越来越重要。我们研究了基于软件的系统,其中底层硬件资源(如缓存大小)会影响性能,而内存资源很丰富,几乎不会影响性能。所分析的基于ASIC的设备提供了低延迟和低抖动的高吞吐量,即使在增加程序复杂性时也是如此。然而,可用的memory资源是一个限制因素。
性能和资源模型都表明,每个P4目标都提供独特的属性,这使得它更适合所讨论的任务。总的指导方针是,程序复杂性通过可利用的资源利益与软件目标相关联。另一方面,吞吐量和延迟通常是硬件目标特有的优势。此外,所提出的模型能够确定给定P4实现的可行性。虽然提出的模型仍然依赖于目标,即其他P4目标的参数化可能不同,但模型输出提供了关于可能性和限制的提示。
软件因灵活性更适合执行复杂的程序;硬件更适合执行高性能程序。
众所周知,ASIC目标在提供稳定、可扩展的性能方面表现出色,而软件目标提供了一个资源几乎无限的平台。我们认为设备特性的建模应该关注它们各自的弱点。这导致了对资源使用建模的关注,将其作为ASIC目标的明智度量。与此相反,软件目标的致命弱点是性能行为。
使用软件实现时需要重点关注性能;硬件ASIC实现重点关注资源。
对于这个问题的未来工作,我们程序研究其他可用软件目标的模型参数,例如,eBPF或XDP的P4转译器[22]。
> 参考文献
[1] P. Bosshart, D. Daly, G. Gibb, M. Izzard, N. McKeown, J. Rexford, C. Schlesinger, D. Talayco, A. Vahdat, G. Varghese, and D. Walker, “P4:ProgrammingProtocol-independentPacketProcessors,”SIGCOMM Comput. Commun. Rev., vol. 44, no. 3, pp. 87–95, Jul. 2014.
[2] H. T. Dang, H. Wang, T. Jepsen, G. Brebner, C. Kim, J. Rexford, R. Soul´e, and H. Weatherspoon, “Whippersnapper: A P4 Language Benchmark Suite,” in Proceedings of the Symposium on SDN Research, ser. SOSR ’17. New York, NY, USA: ACM, 2017, pp. 95–101.
[3] C. Rotsos, N. Sarrar, S. Uhlig, R. Sherwood, and A. W. Moore, “OFLOPS: An Open Framework for OpenFlow Switch Evaluation,” in Passive and Active Measurement, N. Taft and F. Ricciato, Eds. Berlin, Heidelberg: Springer Berlin Heidelberg, 2012, pp. 85–95.
[4] DPDK Project, “DPDK Homepage,” 2019, https://www.dpdk.org/.
[5] S. Gallenm¨uller, P. Emmerich, F. Wohlfart, D. Raumer, and G. Carle, “Comparison of Frameworks for High-Performance Packet IO,” in ACM/IEEE Symposium on Architectures for Networking and Communications Systems (ANCS 2015), Oakland, CA, USA, May 2015.
[6] D. Scholz, A. Oeldemann, F. Geyer, S. Gallenm¨uller, H. Stubbe, T. Wild, A. Herkersdorf, and G. Carle, “Cryptographic Hashing in P4 Data Planes,” in 2nd P4 Workshop in Europe, Cambridge, UK, Sep. 2019.
[7] H. Harkous, M. Jarschel, M. He, R. Pries, and W. Kellerer, “Towards Understanding the Performance of P4 Programmable Hardware,” in ACM/IEEE Symposium on Architectures for Networking and Communications Systems - 2nd EuroP4 Workshop, Cambridge, UK, Sep 2019.
[8] F. Geyer and M. Winkel, “Towards Embedded Packet Processing Devices for Rapid Prototyping of Avionic Applications,” in 9th European Congress on Embedded Real Time Software and Systems, Jan. 2018.
[9] J. Liu, W. T. Hallahan, C. Schlesinger, M. Sharif, J. Lee, R. Soul´ e, H. Wang, C. Cascaval, N. McKeown, and N. Foster, “p4v: practical verification for programmable data planes,” in Proceedings of the 2018 Conference of the ACM Special Interest Group on Data Communication, SIGCOMM 2018, Budapest, Hungary, August 20-25, 2018, S. Gorinsky and J. Tapolcai, Eds. ACM, 2018, pp. 490–503.
[10] M. C. Neves, L. Freire, A. E. S. Filho, and M. P. Barcellos, “Verification of P4 programs in feasible time using assertions,” in Proceedings of the 14th International Conference on emerging Networking EXperiments and Technologies, CoNEXT 2018, Heraklion, Greece, December 04-07, 2018, X. A. Dimitropoulos, A. Dainotti, L. Vanbever, and T. Benson, Eds. ACM, 2018, pp. 73–85.
[11] A. N¨otzli, J. Khan, A. Fingerhut, C. W. Barrett, and P. Athanas, “p4pktgen: Automated test case generation for P4 programs,” in Proceedings of the Symposium on SDN Research, SOSR 2018, Los Angeles, CA, USA, March 28-29, 2018. ACM, 2018, pp. 5:1–5:7.
[12] S. Gallenm¨uller, D. Scholz, F. Wohlfart, Q. Scheitle, P. Emmerich, and G. Carle, “High-Performance Packet Processing and Measurements (Invited Paper),” in 10th International Conference on Communication Systems & Networks (COMSNETS 2018), Bangalore, India, Jan. 2018.
[13] P. Emmerich, S. Gallenm¨uller, D. Raumer, F. Wohlfart, and G. Carle, “Moongen: A scriptable high-speed packet generator,” in Proceedings of the 2015 Internet Measurement Conference. ACM, 2015, pp. 275–287.
[14] P. V¨ or¨os, D. Horp´acsi, R. Kitlei, D. Lesk´o, M. Tejfel, and S. Laki, “”T4P4S: A Target-independent Compiler for Protocolindependent Packet Processors”,” in IEEE HPSR, 2018, pp. 17–20.
[15] P4ELTE, “T4P4S, a multitarget P416 compiler,” 2020. [Online]. Available: https://github.com/P4ELTE/t4p4s
[16] S. Gallenm¨uller, J. Naab, I. Adam, and G. Carle, “5G QoS: Impact of Security Functions on Latency,” in 2020 IEEE/IFIP Network Operations and Management Symposium (NOMS 2020), Budapest, Hungary.
[17] Huston, Geoff, “BGP in 2019 – The BGP Table,” 2020. [Online]. Available: https://blog.apnic.net/2020/01/14/bgp-in-2019-the-bgp-table/
[18] Intel 64 and IA-32 Architectures Optimization Reference Manual, Intel.
[19] P. Gupta, S. Lin, and N. McKeown, “Routing lookups in hardware at memory access speeds,” in Proceedings. IEEE INFOCOM ’98, the Conference on Computer Communications. Seventeenth Annual Joint Conference of the IEEE Computer and Communications Societies. Gateway to the 21st Century (Cat. No.98), vol. 3, pp. 1240–1247 vol.3.
[20] DPDK Project, “rte_lpm.h File Reference,” 2019, https://doc.dpdk. org/api-19.02/rte lpm 8h source.html; last accessed on 2020-05-29.
[21] A. Fog, “The microarchitecture of Intel, AMD and VIA CPUs: An optimization guide for assembly programmers and compiler makers,” Copenhagen University College of Engineering, p. 134, 2012.
[22] W. Tu, F. Ruffy, and M. Budiu, “P4C-XDP: Programming the linux kernel forwarding plane using P4,” in Linux Plumber’s Conference, Vancouver, Canada, November 13-15 2018. [Online]. Available: http://budiu.info/work/p4c-xdp-lpc18-paper.pdf
THE END
原文链接:https://cloud.tencent.com/developer/article/1739567
(免费订阅,永久学习)学习地址: Dpdk/网络协议栈/vpp/OvS/DDos/NFV/虚拟化/高性能专家-学习视频教程-腾讯课堂
更多DPDK相关学习资料有需要的可以自行报名学习,免费订阅,永久学习,或点击这里加qun免费
领取,关注我持续更新哦! !