算法概述
减法聚类算法(Subtractive Clustering Method)是一种不需要提前规定聚类数、只需根据样本数据即可快速决定聚类中心的一种密度聚类算法。该算法把所有样本数据点作为聚类中心的候选点,利用密度函数计算每个候选点的密度指标,选取其中密度指标最大的点作为聚类中心,再去掉已知选择的聚类中心,计算剩余点的密度指标,选取其中密度指标最大的点作为下一个聚类中心。不断重复上述过程,直到满足收敛条件[1]^{[1]}[1]。最终即可得到的已知数目的聚类中心。
具体实现流程
-
Step1:已知n个处于m维空间的数据样本点 (x1,x2,...,xn)(x_1,x_2,...,x_n)(x1,x2,...,xn),每个数据点都是候选聚类中心,定义数据点 xix_ixi 处的密度指标为:
Di=∑j=1nexp(−∥xi−xj∥2(ra/2)2)D_i=\sum_{j=1}^n\exp(-\frac{\|x_i-x_j\|^2}{(r_a/2)^2}) Di=j=1∑nexp(−(ra/2)2∥xi−xj∥2)
其中 rar_ara 是一个常数,一个数据点的邻近数据点越多,该数据点的密度指标越大。rar_ara 也可以理解为以 xix_ixi 数据点为中心,以 rar_ara 为半径的圆形区域,区域以外的数据点对该点的密度指标影响较小。 -
Step2:按照上式计算得到各个样本点的密度指标,密度指标最大的点定义为聚类中心 ckc_kck ,其密度指标为 DckD_{c_k}Dck 。此时 k=1k=1k=1 ,那么每一个数据点 xix_ixi 的密度指标可用以下公式进行更新:
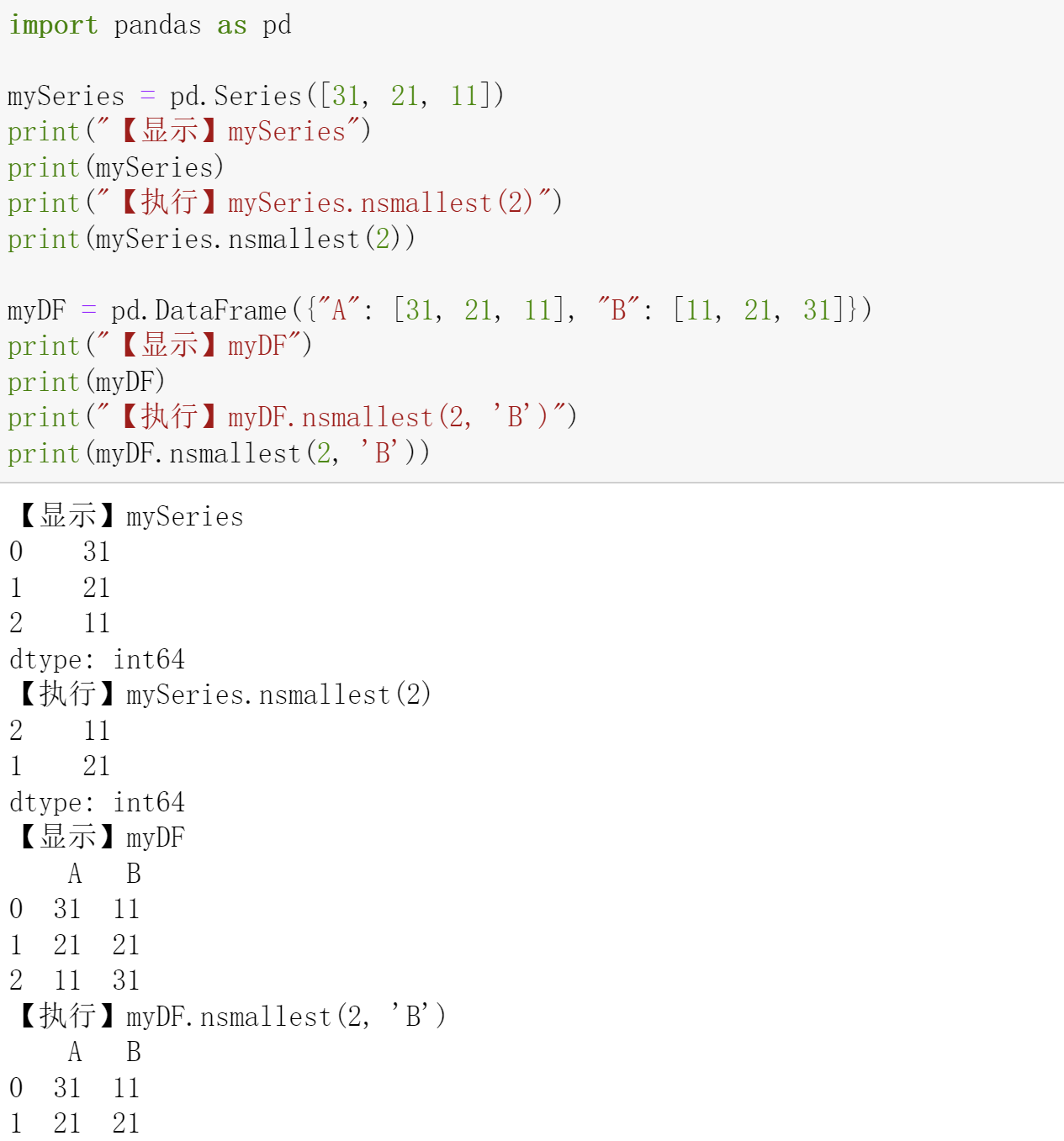
Di=Di−Dckexp(−∥xi−xck∥2(rb/2)2)D_i = D_i - D_{c_k}\exp{(-\frac{\|x_i-x_{c_k}\|^2}{(r_b/2)^2})} Di=Di−Dckexp(−(rb/2)2∥xi−xck∥2)
其中 rbr_brb 是一个常数。可以看出,经过更新公式重新计算密度指标后,靠近聚类中心 ckc_kck 的数据点密度指标明显减小了,这样做的好处是可以避免其成为下一个聚类中心。rbr_brb 定义了一个密度指标显著减小的影响范围[2]^{[2]}[2]。 -
Step3:根据更新修正后的样本数据点密度指标,找出最大值Dmax=max(Di)D_{max}=\max(D_i)Dmax=max(Di),选出下一个聚类中心ck+1c_{k+1}ck+1,重复Step2进行更新修正。
-
Step4:不断迭代计算修正后的密度指标最大值 DmaxD_{max}Dmax ,直到满足下式:
DmaxDc1<δ\frac{D_{max}}{D_{c_1}}<\delta Dc1Dmax<δ
则迭代结束,最终聚类个数为 K=kK=kK=k 。一般取δ≥0.5\delta\ge0.5δ≥0.5 效果较好。
关于Step1和Step2中的ra,rbr_a, r_bra,rb 可通过如下方法进行确定:
ra=rb=12minj{maxi(∥xi−xj∥)}r_a=r_b=\frac{1}{2}\min_j\{\max_i(\|x_i-x_j\|)\} ra=rb=21jmin{imax(∥xi−xj∥)}
其中 ra、rbr_a、r_bra、rb 取样本集合最中间的样本到距离它最远的样本之间距离的一半[3]^{[3]}[3]。
代码实现
为了避免太多循环操作,代码中尽量使用矩阵计算。
首先,创建CSM减法聚类方法类。
import numpy as np
import time
import matplotlib.pyplot as plt
from sklearn.metrics import pairwise_distances_argmin
from sklearn.datasets._samples_generator import make_blobsclass SCM:def __init__(self, r_a = None, r_b = None, delta = 0.5):"""Subtractive Clustering Method:param r_a: float,初始化密度指标邻域大小:param r_b: float,迭代修正密度指标邻域大小:param delta: float,迭代停止阈值"""self.r_a = r_aself.r_b = r_bself.delta = deltaself.cluster_centers = np.array([])def fit(self, X):"""聚类主函数:param X: NxM array,输入样本数据点,N为样本点数量,M为样本数据维数:return: KxM array,聚类中心点集合,K为中心点数量,M为中心点维数"""# 计算欧式距离矩阵EDM(NxN)EDM = self.compute_squared_EDM(X)if not self.r_a or not self.r_b:# 计算r_a和r_bself.r_a = self.r_b = 0.5 * np.min(np.max(EDM, axis = 1))# 计算每个样本点的密度指标D = np.sum(np.exp(-1 * EDM / (0.25 * self.r_a ** 2)), axis = 1)# 选取最大密度指标点作为聚类中心self.cluster_centers = np.append(self.cluster_centers, X[np.argmax(D)]).reshape(-1, X.shape[1])Dc1, Dmax = np.max(D), np.max(D)while True:# 更新修正各点密度指标D -= Dmax * np.exp(-1 * EDM[:, np.argmax(D)] / (0.25 * self.r_b ** 2))Dmax = np.max(D)# 判断是否满足迭代结束条件if Dmax / Dc1 < self.delta:break# 选取最大密度指标点作为下一个聚类中心self.cluster_centers = np.vstack((self.cluster_centers, X[np.argmax(D)]))@staticmethoddef compute_squared_EDM(X):# 获得矩阵都行和列,因为是行向量,因此一共有n个向量n, m = X.shape# 计算Gram 矩阵G = np.dot(X, X.T)# 因为是行向量,n是向量个数,沿y轴复制n倍,x轴复制一倍H = np.tile(np.diag(G), (n, 1))return np.sqrt(H + H.T - 2 * G)
ok,直接开始测试。测试部分代码参考了这篇文章[5]^{[5]}[5]。
# Generate sample data
np.random.seed(0)
centers = [[1, 1], [-1, -1], [1, -1]]
X, labels_true = make_blobs(n_samples = 3000, n_features = 2, centers = centers, cluster_std = 0.5)
# plot result
fig = plt.figure(figsize = (8, 3))
fig.subplots_adjust(left = 0.02, right = 0.98, bottom = 0.05, top = 0.9)
# original data
ax = fig.add_subplot(1, 2, 1)
row, _ = np.shape(X)
for i in range(row):ax.plot(X[i, 0], X[i, 1], '#4EACC5', marker = '.')
ax.set_title('Original Data')
ax.set_xticks(())
ax.set_yticks(())
# compute clustering with SCM
scm = SCM()
t0 = time.time()
scm.fit(X)
t = time.time() - t0
csm_cluster_centers = np.sort(scm.cluster_centers, axis = 0)
csm_labels = pairwise_distances_argmin(X, csm_cluster_centers)
# SCM
ax = fig.add_subplot(1, 2, 2)
import matplotlib.colors as mcolorscolors = list(mcolors.TABLEAU_COLORS.keys()) # 颜色变化
for k, col in zip(range(len(csm_cluster_centers)), colors):my_members = csm_labels == k # my_members是布尔型的数组(用于筛选同类的点,用不同颜色表示)cluster_center = csm_cluster_centers[k]ax.plot(X[my_members, 0], X[my_members, 1], 'w',markerfacecolor = col, marker = '.') # 将同一类的点表示出来ax.plot(cluster_center[0], cluster_center[1], 'o', markerfacecolor = col,markeredgecolor = 'k', marker = 'o') # 将聚类中心单独表示出来
ax.set_title('Subtractive Clustering')
ax.set_xticks(())
ax.set_yticks(())
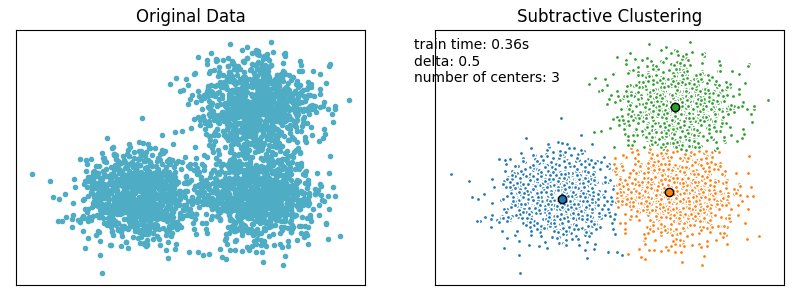
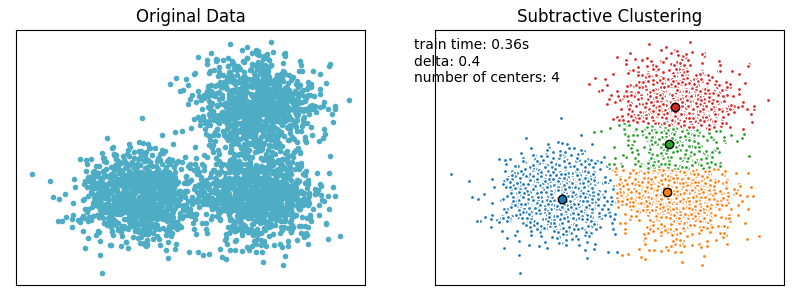
plt.text(-3.5, 1.8,'train time: %.2fs\ndelta: %.2f\nnumber of centers: %d' % (t, scm.delta, len(scm.cluster_centers)))plt.show()
测试结果如下图所示。
总结
-
欧式距离矩阵求解
矩阵运算很好用,能避免for循环,提升运算效率。本代码中距离矩阵构建方法参见文章[4]^{[4]}[4]。
参考
[1] 马慧,赵捧未,王婷婷. 语义减法聚类研究[J]. 计算机工程与科学,2016,38(9):1924-1929. DOI:10.3969/j.issn.1007-130X.2016.09.027.
[2] 袁银莉. 改进的模糊聚类算法[J]. 绍兴文理学院学报,2009,29(10):46-49. DOI:10.3969/j.issn.1008-293X.2009.10.012.
[3] 邵堃侠,郭卫民,杨宁,等. 基于K-means算法的RBF神经网络预测光伏电站短期出力[J]. 上海电机学院学报,2017,20(1):27-33. DOI:10.3969/j.issn.2095-0020.2017.01.006.
[4] https://blog.csdn.net/LoveCarpenter/article/details/85048291
[5] https://blog.csdn.net/qq_41938858/article/details/87738035






![洛谷千题详解 | P1018 [NOIP2000 提高组] 乘积最大【C++、Python、Java、pascal语言】](https://img-blog.csdnimg.cn/img_convert/443d6920a7fea48f91a389bb5103e7fa.png)
![苯丙氨酸甲酯双三氟甲基磺酰亚胺[PheC1][Tf2N]氨基酸酯离子液体](https://img-blog.csdnimg.cn/73fce3fac4094595b2a50e872414056a.png)