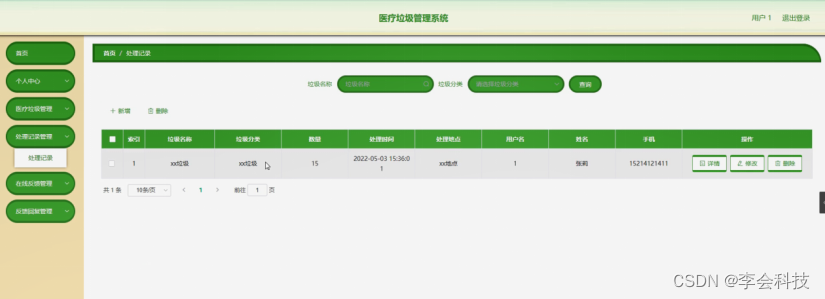
文章目录
- Abstract
- Introduction
- Measuring generalization to held-out tasks
- A unfied prompt format
- Experimental setup
- Results
- Conclusion
Abstract
大模型在多种任务上学习提高了 zero-shot 泛化能力,有人假设这是语言模型在隐式多任务学习的结果。
zero-shot 泛化能力能否通过显式多任务学习来直接引发呢?
Introduction
目标:训练一个模型能够在留出任务上泛化性更好,且不需要很大的模型规模,同时对于 prompt 的措辞选择更鲁棒。
实验学习了两个问题:
- 多任务 prompted training 是否提升了在留出任务上的泛化性
- 我们发现,多任务训练增强了在 zero-shot 任务上的泛化能力
- 在更大范范围的 prompts 上进行训练是否能够提升 prompt 措辞的鲁棒性
- 我们发现,在每个数据集上进行更多 prompt 的训练始终提高在留出任务上性能的中位数,并减少变化性
Measuring generalization to held-out tasks

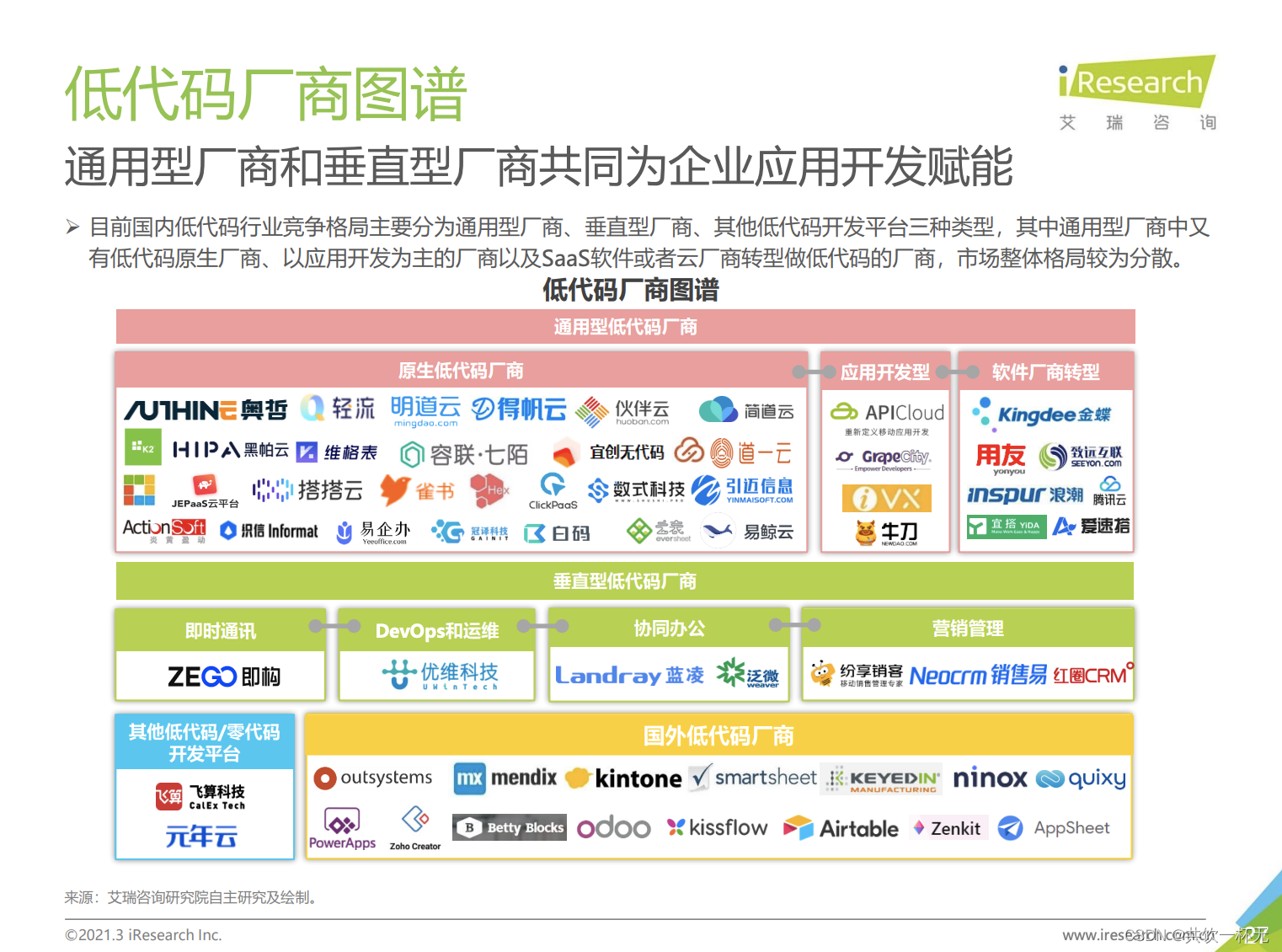
本文提供了四个保留任务(绿色部分):
- 自然语言推理
- 共指消解
- 句子补全
- 词意消歧
同时也在 BIG-bench(这是最近一个由社区驱动的基准测试,它创建了各种各样的困难任务集合,以测试大型语言模型的能力) 中的部分数据集上评估。所有源自 BIG-bench 的任务都是新任务,是从训练中留出的。
A unfied prompt format
所有数据集都是以自然语言 prompt 的格式给到模型,以实现 zero-shot 实验。
定义 prompt 为:包含一个输入模板和一个目标模板,并且带有一组相关元数据
- 模板是将数据示例映射为输入和目标序列的自然语言的函数。实际上,模板允许用户将任何文本与数据字段,元数据,其他用于呈现和格式化原始字段的代码混合
比如一个NLI数据,包含字段premise,Hypothesis,Label。
- 输入模板:If {Premise} is true, is it also true that {Hypothesis}?
- 目标模板:{Choices[label]}
- 这里 choice 是 prompt-specific 元数据,包含选项:yes,maybe,no。对应着label 是 entailment(0),neutral(1),contradiction(2)。

- 这里 choice 是 prompt-specific 元数据,包含选项:yes,maybe,no。对应着label 是 entailment(0),neutral(1),contradiction(2)。
我们收集了一个 prompt 集合,叫做Public Pool of Prompts(P3),包含了对 177 个数据集的 2073 个prompt。实验中使用的 prompt 除BIG-bench外均来自P3, BIG-bench的 prompt 由其维护人员提供。
Experimental setup
Results
Conclusion
我们证明了多任务提示训练可以在语言模型中实现强大的 zero-shot 泛化能力。这种方法为无监督语言模型预训练提供了一个有效的可替代方法,常使我们的 T0 模型优于数倍于其自身大小的模型。我们还进行了消融研究,展示了包括许多不同 prompt 的重要性,以及在每个任务中增加数据集数量的影响。