Mybatis - 一二级缓存的原理
- 前言
- 一. 一级缓存原理
- 1.1 原理分析
- 1.2 一级缓存 Key
- 1.3 查询逻辑
- 1.4 一级缓存的清除或失效场景
- 1.5 一级缓存总结
- 二. 二级缓存原理
- 2.1 二级缓存的实验
- 2.2 二级缓存的开启和相关配置解析
- 2.3 二级缓存的封装Cache类
- 2.4 二级缓存的存储
- 2.5 二级缓存总结
前言
我们直到Mybatis中存在着两层缓存,并且有着以下特征:
- 一级缓存:默认开启。
SqlSession级别。 - 二级缓存:需要手动开启。
namespace级别。
那么在了解一二级缓存的原理之前,我们应该先知道其相关的知识。
一. 一级缓存原理
SqlSession对于Mybatis而言,相当于JDBC中的一个Connection。是应用程序与持久存储层之间执行交互操作的一个单线程对象。 可想而知,它的地位非常重要,它实现的功能也是Mybatis的一个核心:
- 包含相关的
SQL操作方法。 - 执行映射的
SQL语句。 - 控制数据库事务。
注意:SqlSession是一个单线程的实例,即每个线程应该有自己的一个SqlSession。用完之后确保其被close()。
那么一级缓存又是什么呢?
一级缓存是在同一个 SqlSession 会话对象中,调用同样的查询方法,对数据库只会执行一次SQL语句,第二次查询直接从缓存中取出返回结果。它的一个缓存共享范围在于一个SqlSession内部。
那么如果希望多个SqlSession共享缓存,就需要开启二级缓存。 这里的二级缓存就相当于一个全局的缓存了。
1.1 原理分析
首先,本文是基于Spring-Mybatis来讲的。因此SqlSession接口的实现应该是SqlSessionTemplate。SqlSessionTemplate中有一个属性是SqlSession的实例。它是通过JDK动态代理创建出来的,我在Mybatis - Spring整合后一级缓存失效了这篇文章有讲到过。
我们来看下代理中拦截器的核心逻辑:
private class SqlSessionInterceptor implements InvocationHandler {@Overridepublic Object invoke(Object proxy, Method method, Object[] args) throws Throwable {// 1.创建一个SqlSessionSqlSession sqlSession = getSqlSession(SqlSessionTemplate.this.sqlSessionFactory,SqlSessionTemplate.this.executorType, SqlSessionTemplate.this.exceptionTranslator);try {// 2.调用原始函数Object result = method.invoke(sqlSession, args);if (!isSqlSessionTransactional(sqlSession, SqlSessionTemplate.this.sqlSessionFactory)) {// 如果不是事务,关闭当前的SqlSessionsqlSession.commit(true);}return result;} catch (Throwable t) {// ...catch} finally {// 关闭SqlSessionif (sqlSession != null) {closeSqlSession(sqlSession, SqlSessionTemplate.this.sqlSessionFactory);}}}}
我们自己写一个查询SQL,并且调用一下。通过Debug我们可以发现,程序确实会跑到这里:
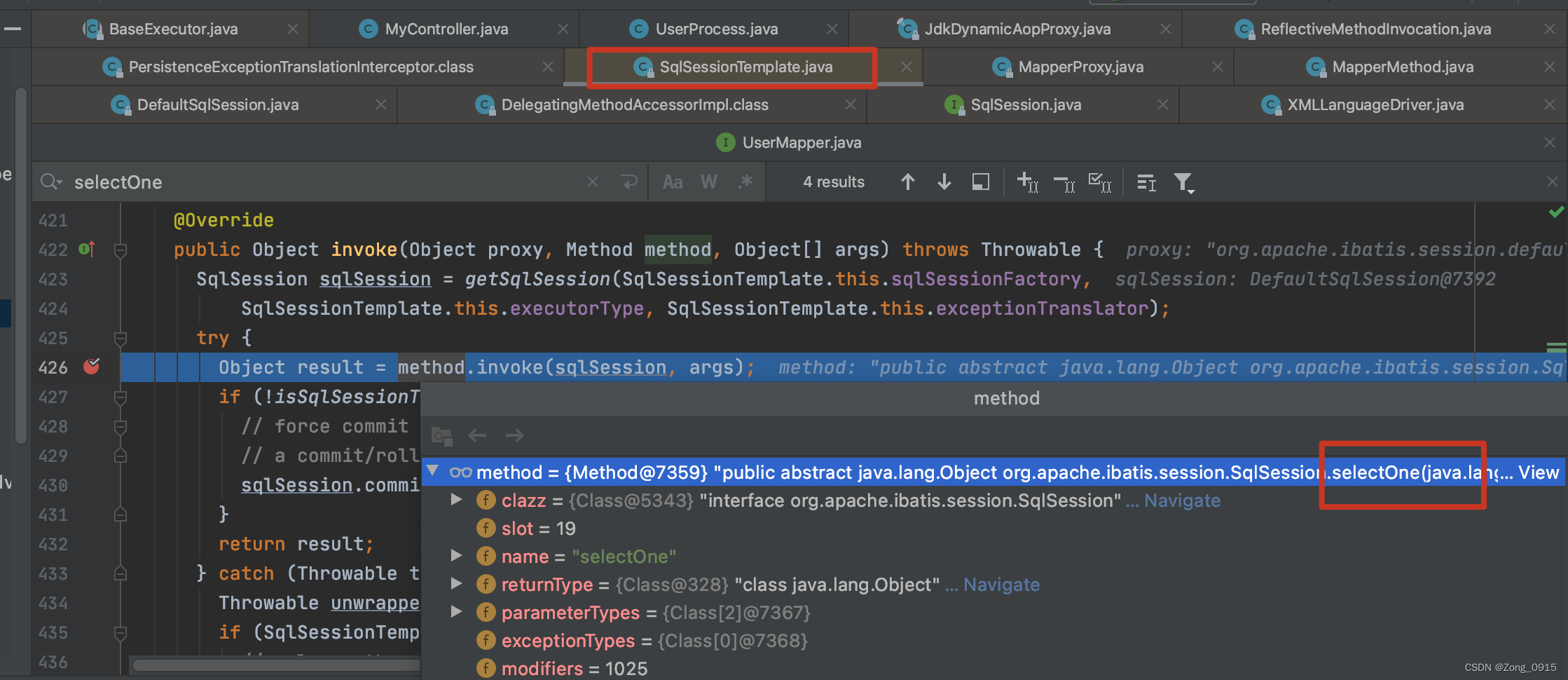
不断地深入,可以发现,最终底层调用在于DefaultSqlSession中的实现:
public class DefaultSqlSession implements SqlSession {@Overridepublic <E> List<E> selectList(String statement, Object parameter, RowBounds rowBounds) {try {MappedStatement ms = configuration.getMappedStatement(statement);return executor.query(ms, wrapCollection(parameter), rowBounds, Executor.NO_RESULT_HANDLER);} catch (Exception e) {throw ExceptionFactory.wrapException("Error querying database. Cause: " + e, e);} finally {ErrorContext.instance().reset();}}
}
这里的executor是CachingExecutor类型的实例:
(因为我配置文件里面直接开启了二级缓存,在创建Executor的时候,会有判断,如果开启了二级缓存,就会创建CachingExecutor类型的实例。)
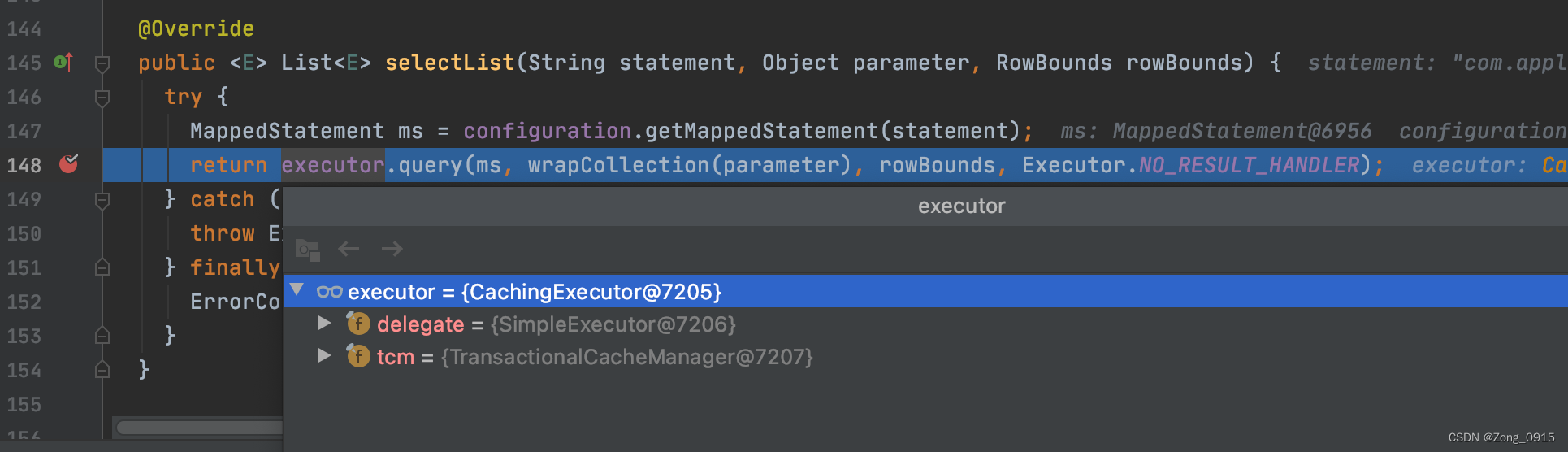
到这里就可以算是一级缓存的一个重点部分了。我们看下这个query函数:
public class CachingExecutor implements Executor {@Overridepublic <E> List<E> query(MappedStatement ms, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler) throws SQLException {BoundSql boundSql = ms.getBoundSql(parameterObject);// 创建一级缓存的KeyCacheKey key = createCacheKey(ms, parameterObject, rowBounds, boundSql);// 查询return query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);}
}
1.2 一级缓存 Key
我们主要来看下一级缓存的Key是由什么来做决定的:
CacheKey key = createCacheKey(ms, parameterObject, rowBounds, boundSql);
↓↓↓↓↓↓
@Override
public CacheKey createCacheKey(MappedStatement ms, Object parameterObject, RowBounds rowBounds, BoundSql boundSql) {return delegate.createCacheKey(ms, parameterObject, rowBounds, boundSql);
}
↓↓↓↓↓↓最后还是会调用到BaseExecutor下的代码:
public abstract class BaseExecutor implements Executor {@Overridepublic CacheKey createCacheKey(MappedStatement ms, Object parameterObject, RowBounds rowBounds, BoundSql boundSql) {if (closed) {throw new ExecutorException("Executor was closed.");}CacheKey cacheKey = new CacheKey();// mapper的IdcacheKey.update(ms.getId());// 分页偏移cacheKey.update(rowBounds.getOffset());// 分页大小cacheKey.update(rowBounds.getLimit());// SQL语句cacheKey.update(boundSql.getSql());List<ParameterMapping> parameterMappings = boundSql.getParameterMappings();TypeHandlerRegistry typeHandlerRegistry = ms.getConfiguration().getTypeHandlerRegistry();// mimic DefaultParameterHandler logicfor (ParameterMapping parameterMapping : parameterMappings) {if (parameterMapping.getMode() != ParameterMode.OUT) {Object value;// 这里主要是拿到参数String propertyName = parameterMapping.getProperty();if (boundSql.hasAdditionalParameter(propertyName)) {value = boundSql.getAdditionalParameter(propertyName);} else if (parameterObject == null) {value = null;} else if (typeHandlerRegistry.hasTypeHandler(parameterObject.getClass())) {value = parameterObject;} else {MetaObject metaObject = configuration.newMetaObject(parameterObject);value = metaObject.getValue(propertyName);}// 参数值cacheKey.update(value);}}if (configuration.getEnvironment() != null) {// issue #176cacheKey.update(configuration.getEnvironment().getId());}return cacheKey;}
}
这么看代码可能看得不是很懂。我们来看下我程序里的一些代码。这是我的Mapper.xml文件:
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapperPUBLIC "-//mybatis.org//DTD Mapper 3.0//EN""http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<!--关联UserMapper接口 ,下面的id要和接口中对应的方法名称一致,实现一对一的对应-->
<mapper namespace="com.application.mapper.UserMapper">
<!-- <cache readOnly="true"/>--><select id="getUserById" parameterType="String" resultType="user">select * from user where userName=#{userName}</select>
</mapper>
对应的传参部分:就是这个 tom
userProcess.getUser("tom");
再看下调试的截图:
-
Mapper中对应SQL的ID:

-
偏移量:默认是0。

-
分页:默认是
Integer.MAX_VALUE。

-
SQL语句:
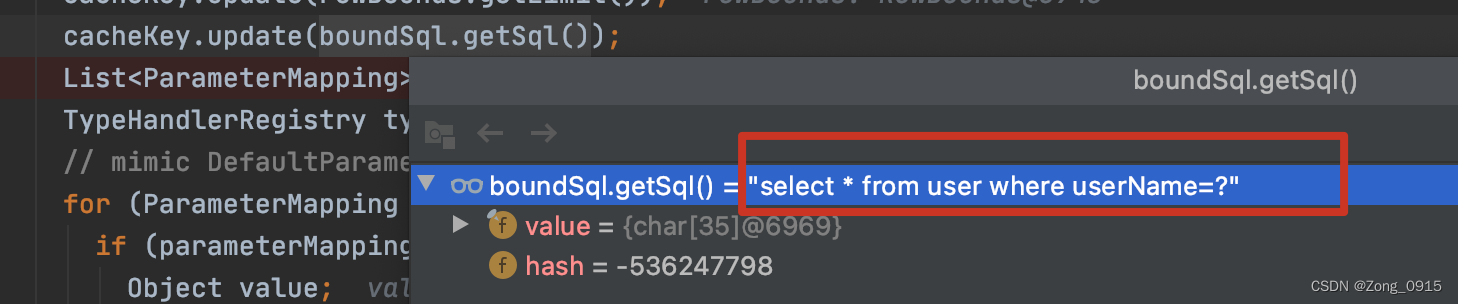
-
参数:
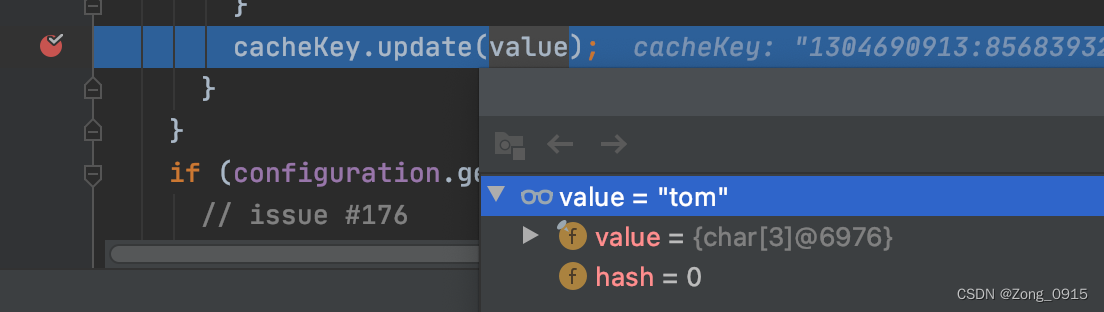
总结下就是,Mybatis中一级缓存是通过:MapperID+offset+limit+Sql+入参 来做决定的。
1.3 查询逻辑
public class CachingExecutor implements Executor {@Overridepublic <E> List<E> query(MappedStatement ms, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql)throws SQLException {Cache cache = ms.getCache();if (cache != null) {// 这部分本案例中代码走不到}// 最后还是走BaseExecutor.queryreturn delegate.<E> query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);}
}
↓↓↓↓↓↓
public abstract class BaseExecutor implements Executor {@Overridepublic <E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {ErrorContext.instance().resource(ms.getResource()).activity("executing a query").object(ms.getId());if (closed) {throw new ExecutorException("Executor was closed.");}// 如果语句声明了 flushCache=true,就清除一级缓存if (queryStack == 0 && ms.isFlushCacheRequired()) {clearLocalCache();}List<E> list;try {queryStack++;// 尝试从一级缓存中取list = resultHandler == null ? (List<E>) localCache.getObject(key) : null;if (list != null) {// 如果是CALLABLE的调用存储过程的语句,还需要进行一些额外的处理,这块部分本文忽略handleLocallyCachedOutputParameters(ms, key, parameter, boundSql);} else {// 从数据库中取list = queryFromDatabase(ms, parameter, rowBounds, resultHandler, key, boundSql);}} finally {queryStack--;}if (queryStack == 0) {for (DeferredLoad deferredLoad : deferredLoads) {deferredLoad.load();}// issue #601deferredLoads.clear();// 如果localCache的作用域是STATEMENT级别,就清除一级缓存if (configuration.getLocalCacheScope() == LocalCacheScope.STATEMENT) {clearLocalCache();}}return list;}
}
那么在第一次查询的时候,缓存肯定是没有内容的,肯定是会从数据库中去查询,因此走的是下面的queryFromDatabase函数:
private <E> List<E> queryFromDatabase(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {List<E> list;// 这里相当于放一个占位符的作用,在查询完本次SQL后,会将其剔除,然后放入的value是真正的结果。localCache.putObject(key, EXECUTION_PLACEHOLDER);try {list = doQuery(ms, parameter, rowBounds, resultHandler, boundSql);} finally {// 剔除占位符localCache.removeObject(key);}// 将查询结果放入缓存localCache.putObject(key, list);if (ms.getStatementType() == StatementType.CALLABLE) {localOutputParameterCache.putObject(key, parameter);}return list;}
在查询完数据库后,就会将结果放入到本地缓存中:
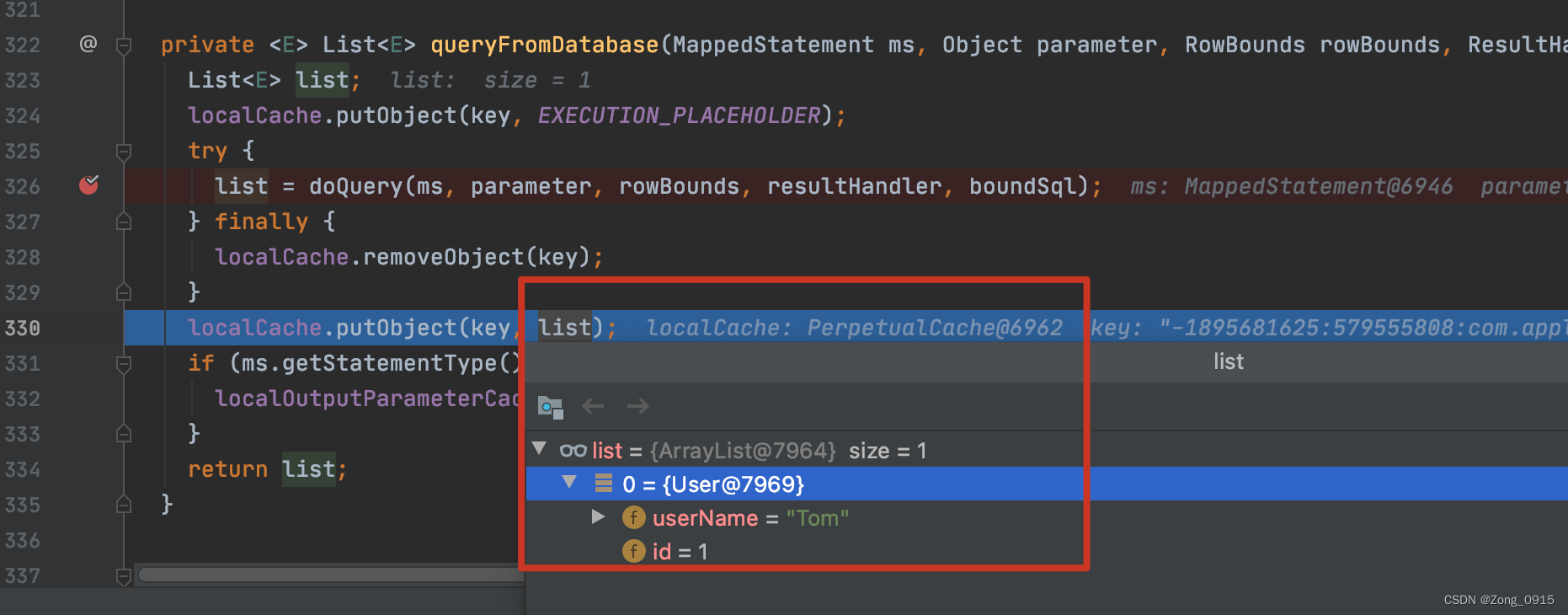
那么在第二次查询的时候,就会尝试从本地缓存中读取:
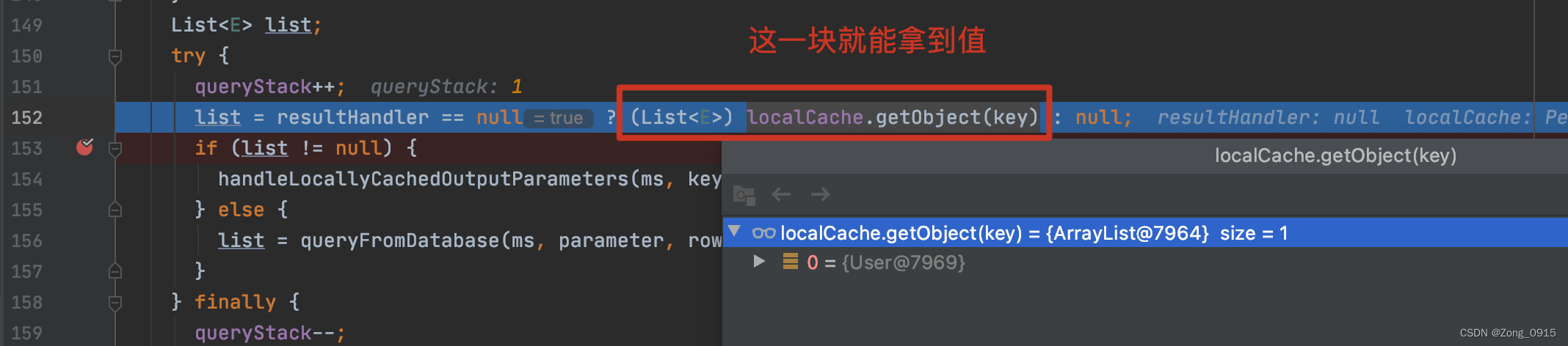
1.4 一级缓存的清除或失效场景
既然上面可以证实,Mybatis在查询的时候,会将相关的结果放入到一个本地缓存中,以便于同一个SqlSession对象实例可以共享。那么必然这个缓存也不可能一直存在。在源码中,我们看到这样一个函数:
@Override
public void clearLocalCache() {if (!closed) {localCache.clear();localOutputParameterCache.clear();}
}
这个函数显然就是用来清除一级缓存的。那么它在什么时候生效呢?我们看下它的引用一共有7个地方:
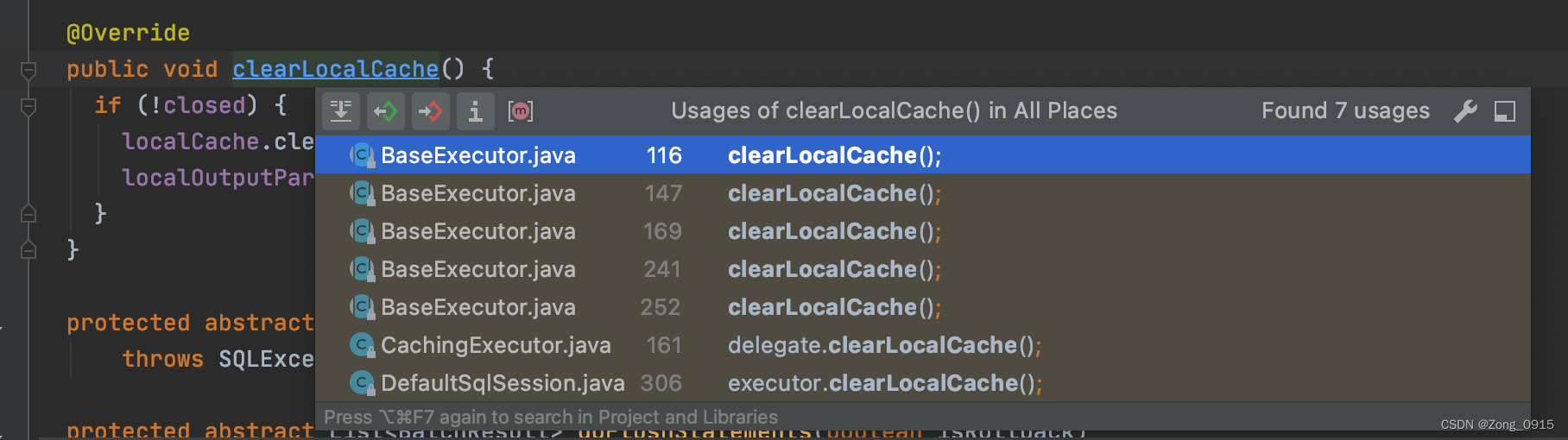
场景一:更新操作。
@Override
public int update(MappedStatement ms, Object parameter) throws SQLException {ErrorContext.instance().resource(ms.getResource()).activity("executing an update").object(ms.getId());if (closed) {throw new ExecutorException("Executor was closed.");}// 在更新之前,先清除一下一级缓存clearLocalCache();return doUpdate(ms, parameter);
}
场景二:查询声明了flushCache为true。
if (queryStack == 0 && ms.isFlushCacheRequired()) {clearLocalCache();
}
例如我可以把Mapper文件改成这样:

那么在查询的时候,就会判断到这个属性,将缓存清空,一级缓存也就失效了:
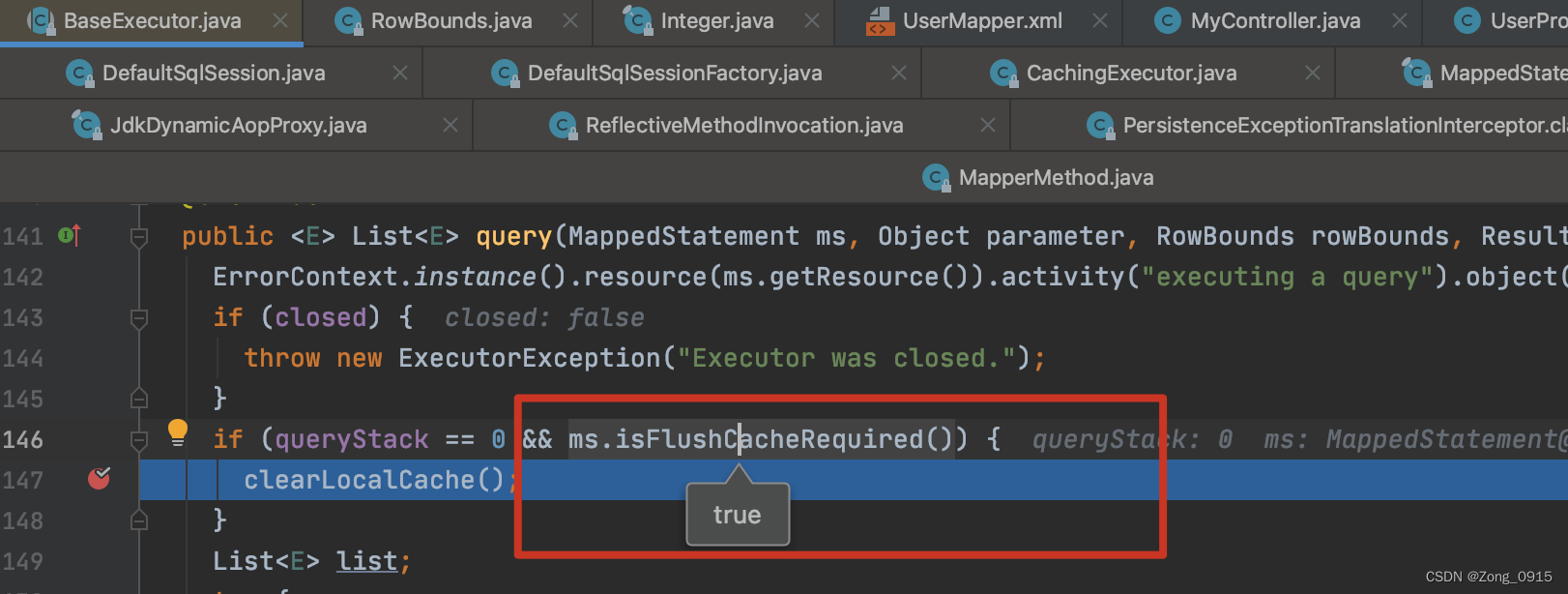
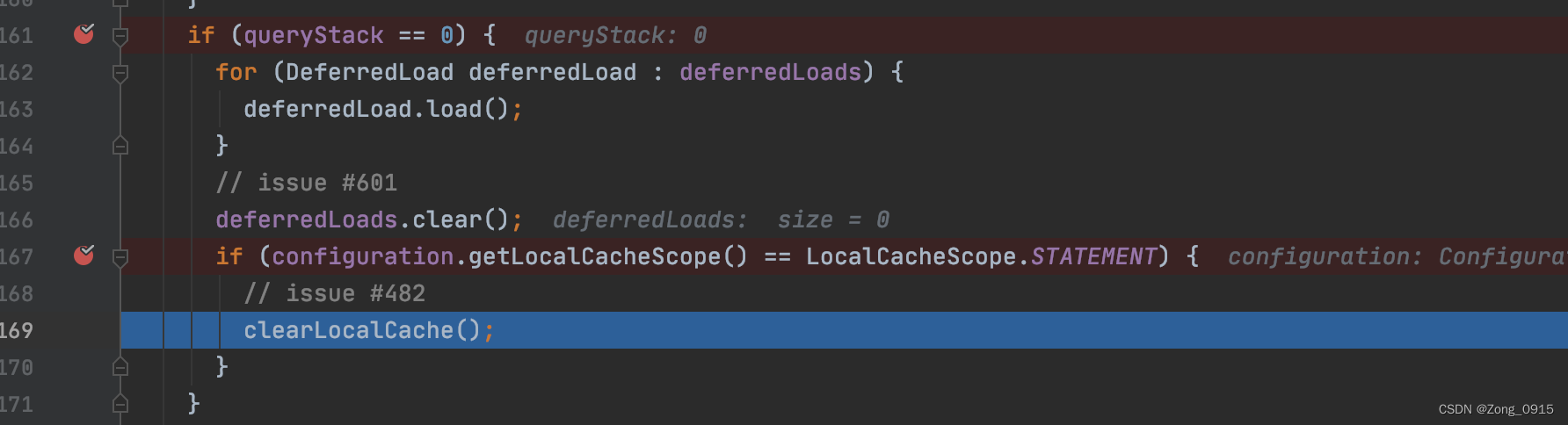
场景三:声明 localCache 的 scope 为 STATEMENT 。
if (queryStack == 0) {for (DeferredLoad deferredLoad : deferredLoads) {deferredLoad.load();}// issue #601deferredLoads.clear();if (configuration.getLocalCacheScope() == LocalCacheScope.STATEMENT) {// issue #482clearLocalCache();}
}
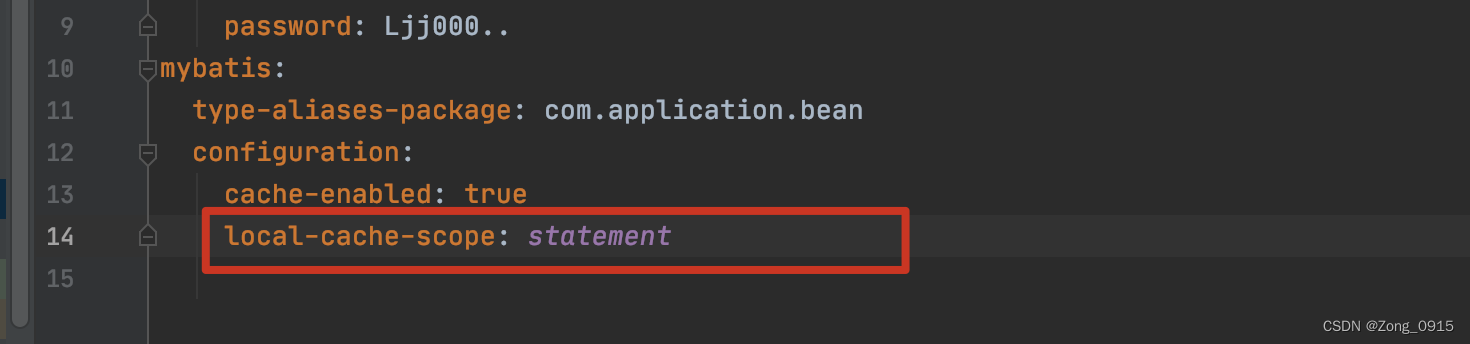
一级缓存的相关配置中,有这么一个属性:localCacheScope,它有两个选项可以选择:
- 默认的
SESSION:会缓存一个会话中执行的所有查询 STATEMENT:本地缓存将仅用于执行语句,对相同SqlSession的不同查询将不会进行缓存。
如果你在配置文件中这么设置:(application.yml文件)
那么每次查询之后,也会将一级缓存删除:
场景四:事务提交SqlSession.commit。
@Override
public void commit(boolean required) throws SQLException {if (closed) {throw new ExecutorException("Cannot commit, transaction is already closed");}clearLocalCache();flushStatements();if (required) {transaction.commit();}
}
场景五:事务回滚SqlSession.rollback。
@Override
public void rollback(boolean required) throws SQLException {if (!closed) {try {clearLocalCache();flushStatements(true);} finally {if (required) {transaction.rollback();}}}
}
场景六:SqlSession会话关闭SqlSession.close。
@Overridepublic void close(boolean forceRollback) {try {try {rollback(forceRollback);} finally {if (transaction != null) {transaction.close();}}} catch (SQLException e) {// Ignore. There's nothing that can be done at this point.log.warn("Unexpected exception on closing transaction. Cause: " + e);} finally {transaction = null;deferredLoads = null;localCache = null;localOutputParameterCache = null;closed = true;}}
场景七:调用SqlSession.closeCache。
public class DefaultSqlSession implements SqlSession {@Overridepublic void clearCache() {executor.clearLocalCache();}
}
1.5 一级缓存总结
- 一级缓存默认开启,底层查询基于一级缓存实现。
- 一级缓存的
Key是一种MapperID+offset+limit+Sql+入参的组合。可以参考下图:

3.一级缓存失效的原因总结:更新操作、事务提交、回滚、SqlSession会话关闭、flushCache=true。一级缓存localCacheScope属性设置为STATEMENT。
二. 二级缓存原理
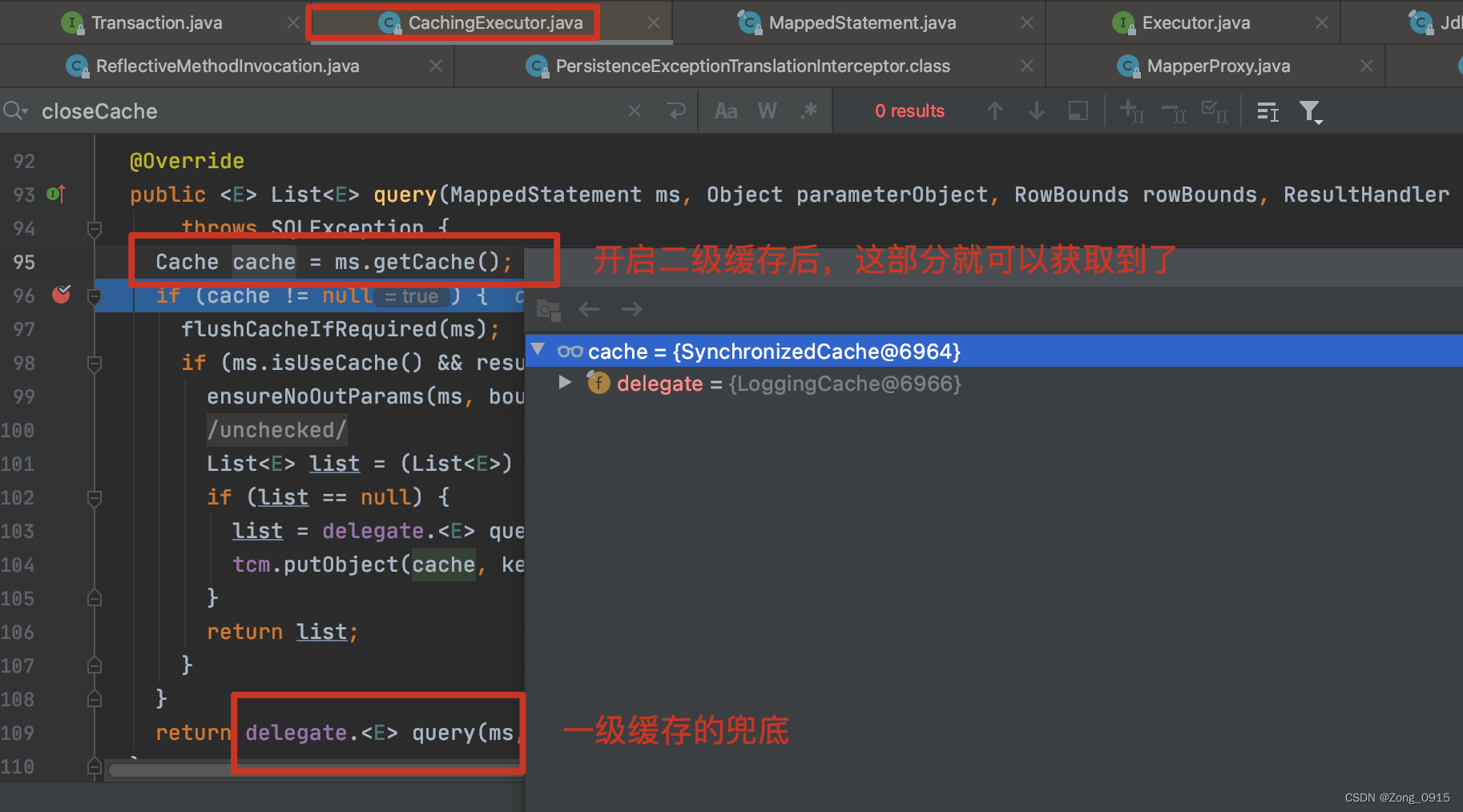
二级缓存在一级缓存的基础上,包装了下Executor。也就是CachingExecutor。因此上文在调试中,虽然看到executor的类型是CachingExecutor,但是实际上他并没有什么作用,因为它是服务于二级缓存的。
如果开启了二级缓存,那么在进行SQL查询的时候,这部分代码时能够获取到的:
2.1 二级缓存的实验
1.我们编写一个自定义的MyApplicationContext。
(这么写的目的是想在一次请求中更加直观的给大家看到不同SqlSession之间的缓存共享问题,当然也可以不那么复杂,直接同样的请求调用两次即可)
@Component
public class MyApplicationContext implements ApplicationContextAware {public ApplicationContext applicationContext;@Overridepublic void setApplicationContext(ApplicationContext applicationContext) throws BeansException {this.applicationContext = applicationContext;}
}
2.Controller层代码:主要是要测试两个SqlSession之间的缓存共享。
@Autowired
private MyApplicationContext myApplicationContext;@PostMapping("/hello")
@Transactional
public User hello() {SqlSessionFactory sqlSessionFactory = (SqlSessionFactory) myApplicationContext.applicationContext.getBean("sqlSessionFactory");SqlSession sqlSession1 = sqlSessionFactory.openSession(true);SqlSession sqlSession2 = sqlSessionFactory.openSession(true);UserMapper mapper1 = sqlSession1.getMapper(UserMapper.class);UserMapper mapper2 = sqlSession2.getMapper(UserMapper.class);User tom = mapper1.getUserById("tom");sqlSession1.commit();User tom2 = mapper2.getUserById("tom");System.out.println(tom);System.out.println(tom2);return tom;
}
测试结果如下:可以看到二级缓存的命中率是0.5。

二级缓存的代码上文其实提到过,在CachingExecutor中的query函数,相当于在查询SQL(基于一级缓存)之前,多一个二级缓存的查询罢了。
public class CachingExecutor implements Executor {@Overridepublic <E> List<E> query(MappedStatement ms, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql)throws SQLException {// 二级缓存的Cache cache = ms.getCache();if (cache != null) {flushCacheIfRequired(ms);if (ms.isUseCache() && resultHandler == null) {ensureNoOutParams(ms, boundSql);@SuppressWarnings("unchecked")List<E> list = (List<E>) tcm.getObject(cache, key);if (list == null) {list = delegate.<E> query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);tcm.putObject(cache, key, list); // issue #578 and #116}return list;}}// 基于一级缓存的查询return delegate.<E> query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);}
}
那么我们来看下第一次查询:
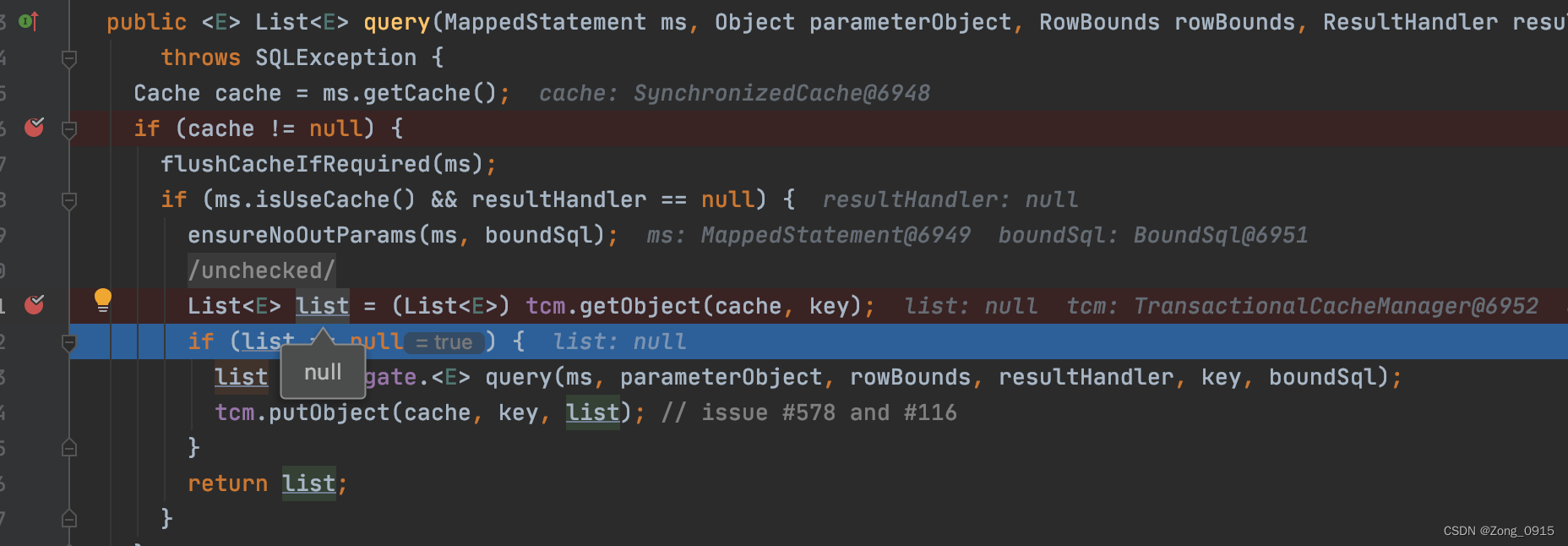
这里可以发现二级缓存为空,那么就会走数据库的查询,然后将结果放到二级缓存中。那么在第二个SqlSession发起相同的查询后,就能从缓存中拿到第一个SqlSession的结果。
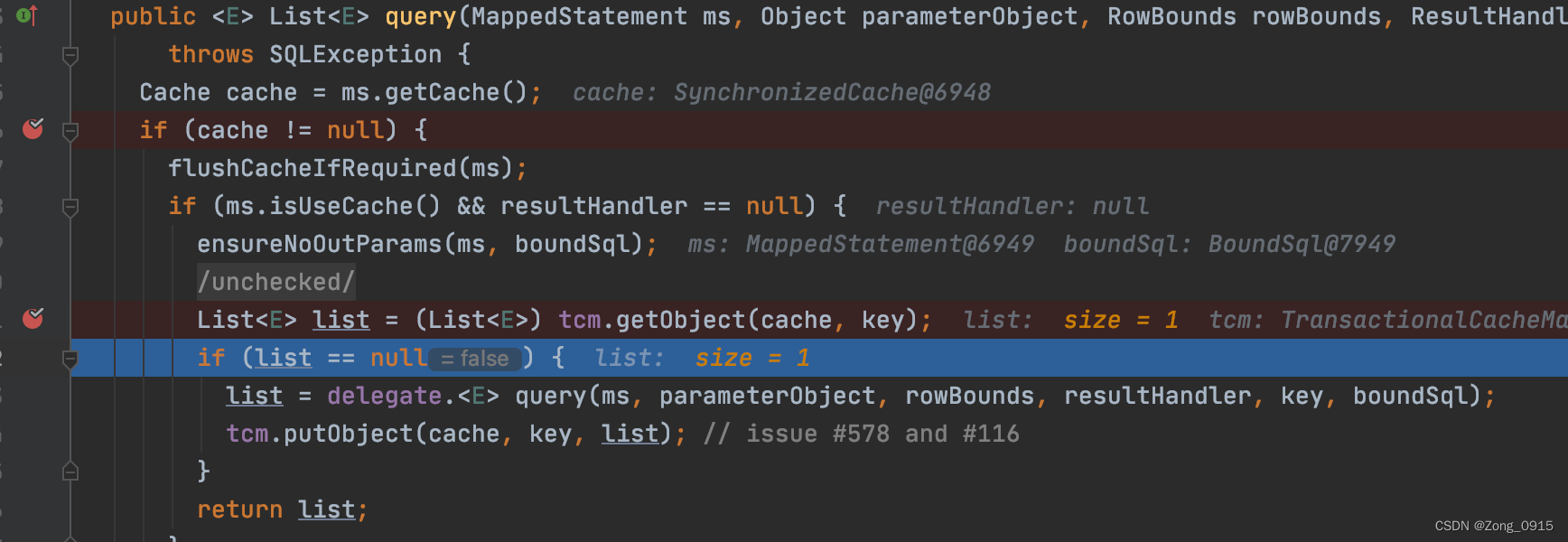
二级缓存的逻辑到很简单,但是这只是表面的现象,有几个疑问:
Cache cache = ms.getCache();这个函数是干什么的?你没有说呀。- 为什么还有个缓存命中率?

- 清除缓存的时机?
别急,我们一个个来。
2.2 二级缓存的开启和相关配置解析
在上述案例中,我并没有把完整的项目配置贴出来,准备在这一小节做具体的介绍。二级缓存的配置需要考虑到三点:
- 全局的
Mybatis的配置文件:可写可不写。

- 对应的
Mapper.xml文件中需要声明开启:(必不可少)
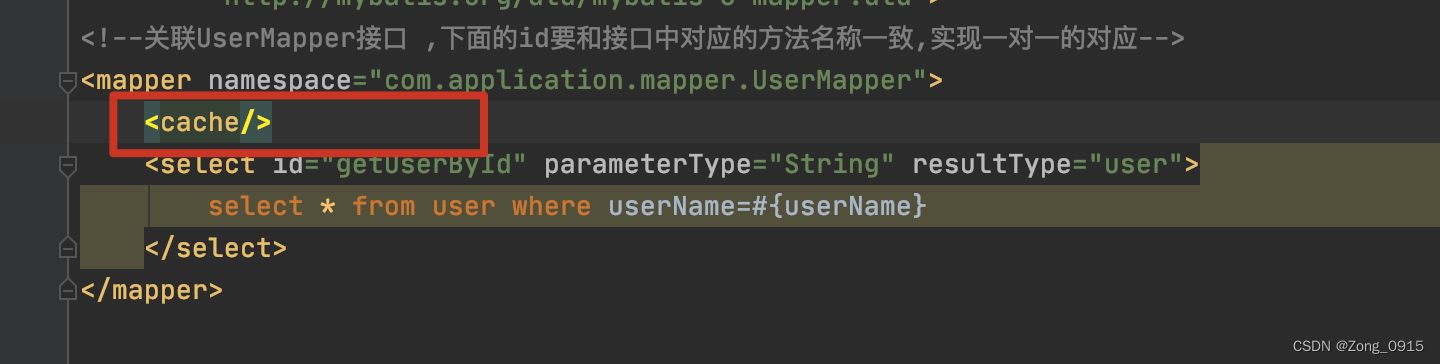
- 在具体
CURD标签上配置useCache=true属性,不过select标签就不用了,默认都是true
boolean useCache = context.getBooleanAttribute("useCache", isSelect);
首先,为什么说第一点可写可不写呢?项目在启动过程中,会读取Mybatis的相关配置或者Mapper文件。配置的读取的具体的实现在于XMLConfigBuilder这个类中,我们看下部分代码:
public class XMLConfigBuilder extends BaseBuilder {private void settingsElement(Properties props) throws Exception {// 默认trueconfiguration.setCacheEnabled(booleanValueOf(props.getProperty("cacheEnabled"), true));}
}
那么再看下Mapper文件的读取,对应的实现相关类就是XMLMapperBuilder:
public class XMLMapperBuilder extends BaseBuilder {private void configurationElement(XNode context) {try {// ... 开启二级缓存的关键标签:cachecacheElement(context.evalNode("cache"));} catch (Exception e) {throw new BuilderException("Error parsing Mapper XML. The XML location is '" + resource + "'. Cause: " + e, e);}}
}
那么我们再看下二级缓存支持哪些属性配置:
private void cacheElement(XNode context) throws Exception {if (context != null) {// 自定义cache的实现,默认PERPETUAL,就是本地缓存,我们也可以自定义一个Redis缓存,就是二级缓存放在那里String type = context.getStringAttribute("type", "PERPETUAL");Class<? extends Cache> typeClass = typeAliasRegistry.resolveAlias(type);// 负责过期缓存的实现,默认是LRUString eviction = context.getStringAttribute("eviction", "LRU");Class<? extends Cache> evictionClass = typeAliasRegistry.resolveAlias(eviction);// 清空缓存的一个频率大小,0则代表不清空Long flushInterval = context.getLongAttribute("flushInterval");// 缓存容器的大小Integer size = context.getIntAttribute("size");// 是否序列化,如果只是读,则不需要,如果需要写操作,那么实体类需要实现Serializable接口boolean readWrite = !context.getBooleanAttribute("readOnly", false);// 是否阻塞boolean blocking = context.getBooleanAttribute("blocking", false);Properties props = context.getChildrenAsProperties();builderAssistant.useNewCache(typeClass, evictionClass, flushInterval, size, readWrite, blocking, props);}}
讲完了二级缓存的相关配置和加载之后,我们再回到二级缓存的使用部分,我们看下Cache实例获取。
2.3 二级缓存的封装Cache类
我们来看下这个函数返回的对象:
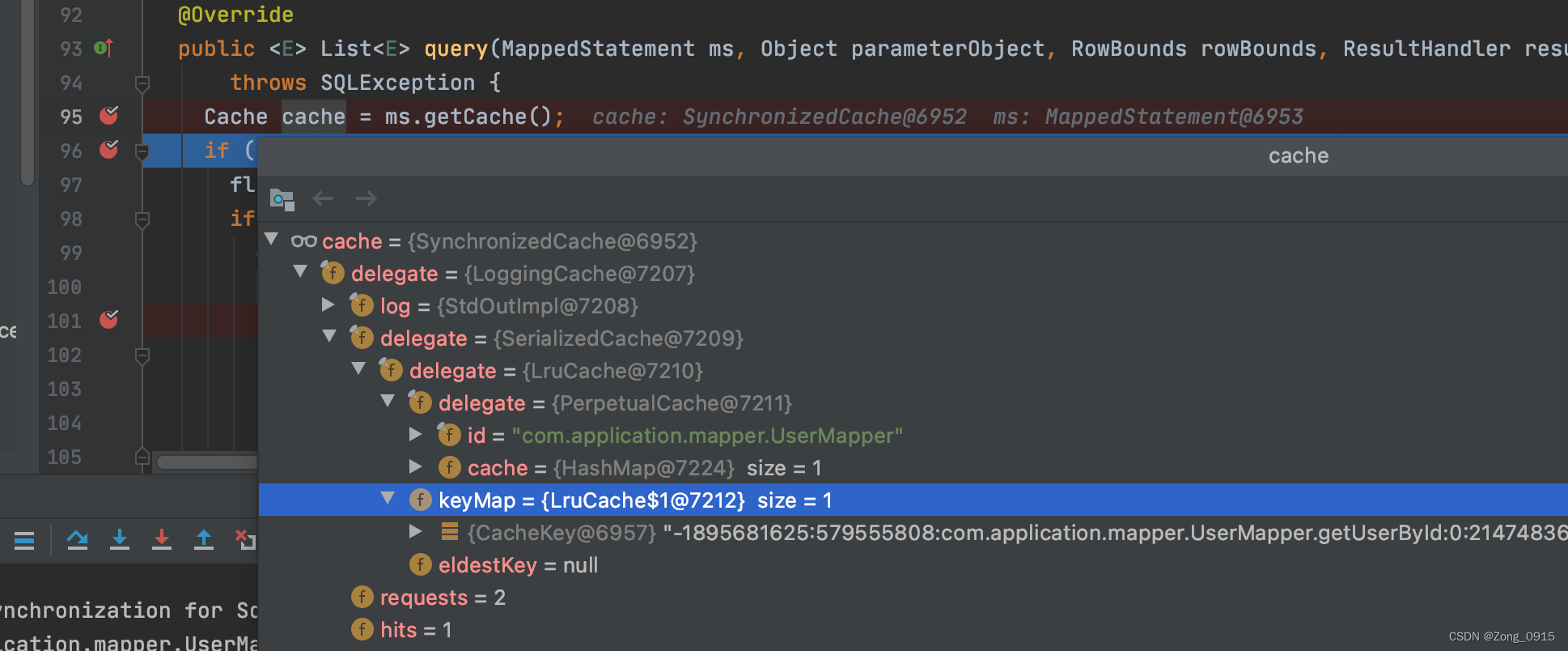
那我们从上到下依次来说下这几个类的作用:
SynchronizedCache: 一种同步缓存,直接使用synchronized修饰方法。LoggingCache: 具有日志功能的装饰类,用于记录缓存的命中率。SerializedCache: 序列化功能,将值序列化后存到缓存中。LruCache: 采用了Lru算法的缓存实现,移除最近最少使用的缓存。PerpetualCache: 作为为最基础的缓存类,底层实现比较简单,直接使用了HashMap。一级缓存用的就是他。 也是一二级缓存中,最终数据存储的地方。
那么我们再结合二级缓存来看:
Cache cache = ms.getCache();
↓↓↓↓↓
List<E> list = (List<E>) tcm.getObject(cache, key);
这个tcm是一个TransactionalCacheManager类型的实例。这个类中包含一个Map,它的Key就是我们上文拿到的Cache对象。
public class TransactionalCacheManager {private final Map<Cache, TransactionalCache> transactionalCaches = new HashMap<Cache, TransactionalCache>();
那么这样看来,ms.getCache()获取到的Cache实例,目的就是作为Key从缓存中拿到一个TransactionalCache实例。
TransactionalCache实现了Cache接口,也是一个装饰类,真正的缓存存储在delete属性中:
public class TransactionalCache implements Cache {private static final Log log = LogFactory.getLog(TransactionalCache.class);private final Cache delegate;// 一个标记位置private boolean clearOnCommit;// 存放的是put时候的值,在commit之后,才会完全的缓存起来。private final Map<Object, Object> entriesToAddOnCommit;//存放的是缓存中没有值的key。在commit的时候,判断,如果在entriesToAddOnCommit里面没有找到这个key就放置一个nullprivate final Set<Object> entriesMissedInCache;public Object getObject(Cache cache, CacheKey key) {return getTransactionalCache(cache).getObject(key);}public void putObject(Cache cache, CacheKey key, Object value) {getTransactionalCache(cache).putObject(key, value);}
}
我们知道了这个TransactionalCache的结构后,再来看二级缓存是如何存储的。
2.4 二级缓存的存储
首先看下存储过程:
tcm.putObject(cache, key, list);
↓↓↓↓↓TransactionalCacheManager.putObject↓↓↓↓↓
public void putObject(Cache cache, CacheKey key, Object value) {// getTransactionalCache就是根据Cache这个Key获取一个TransactionalCachegetTransactionalCache(cache).putObject(key, value);
}
↓↓↓↓↓TransactionalCache.putObject↓↓↓↓↓
public class TransactionalCache implements Cache {@Overridepublic void putObject(Object key, Object object) {entriesToAddOnCommit.put(key, object);}
}
那么为什么说只有在commit的时候,二级缓存才会存储呢?我们看下commit操作:
public class TransactionalCache implements Cache {public void commit() {if (clearOnCommit) {delegate.clear();}flushPendingEntries();reset();}↓↓↓↓↓private void flushPendingEntries() {// 只有提交的时候,才会将entriesToAddOnCommit中的数据同步到底层Cache中for (Map.Entry<Object, Object> entry : entriesToAddOnCommit.entrySet()) {delegate.putObject(entry.getKey(), entry.getValue());}// 如果不存在值,就放入一个nullfor (Object entry : entriesMissedInCache) {if (!entriesToAddOnCommit.containsKey(entry)) {delegate.putObject(entry, null);}}}
}
我们调试下代码就可以发现:在第一次接口调用结束后,代码就会执行commit操作,然后将本次SqlSession中的结果存储到Cache实例中。
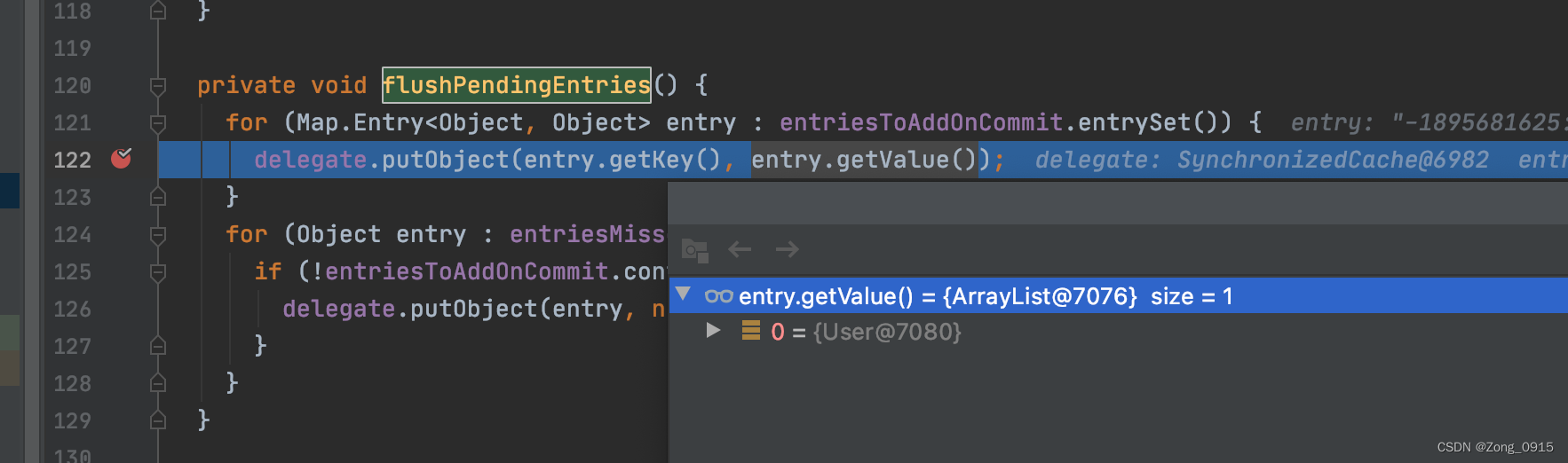
最终调用的putObject函数的实现是PerpetualCache这个类中。意思为持久性缓存。那么在第二次接口调用的时候,就会发现Cache实例中已经保存了上一次SqlSession的结果:
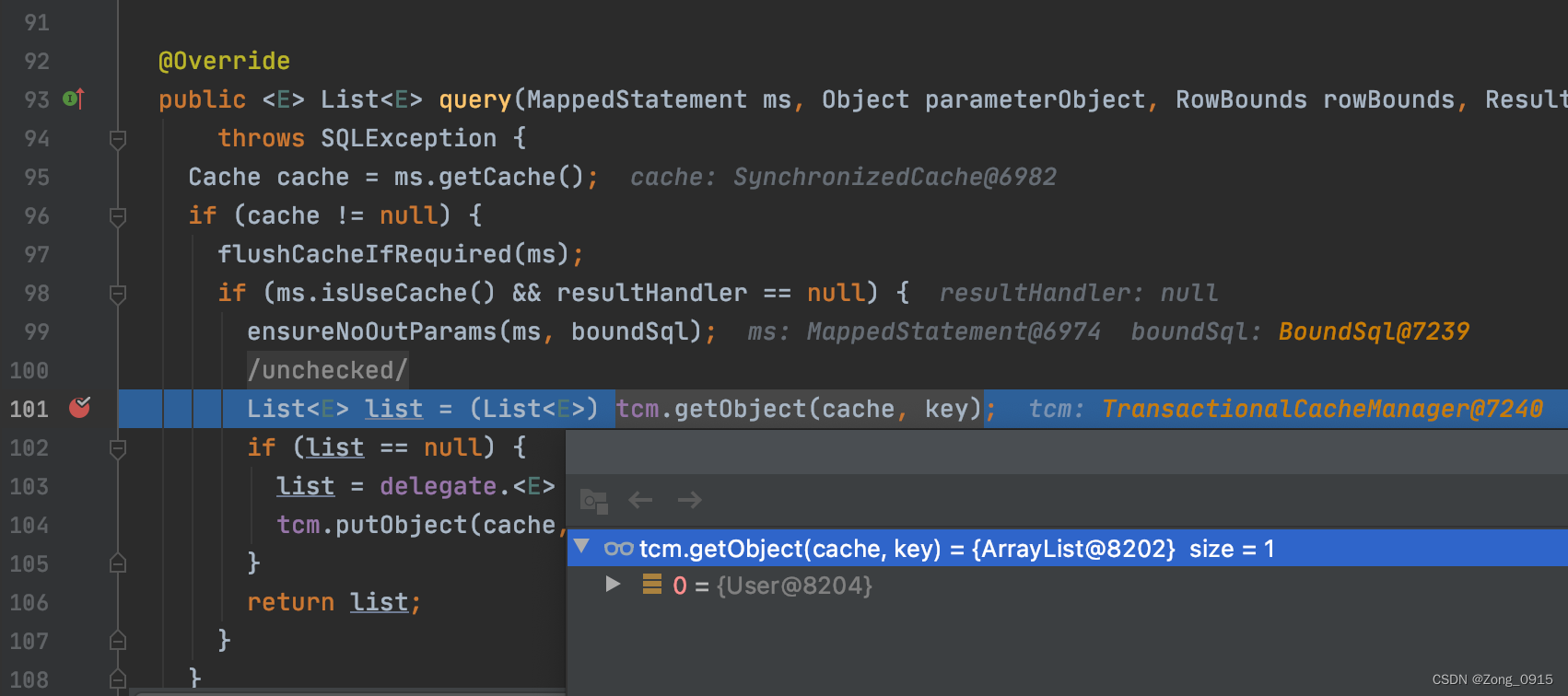
相关的函数:
public class TransactionalCache implements Cache {public Object getObject(Object key) {// 同样是从PerpetualCache类中取缓存Object object = delegate.getObject(key);// 如果没有值,往entriesMissedInCache中插入一个key,代表该key的缓存为null。if (object == null) {entriesMissedInCache.add(key);}// issue #146if (clearOnCommit) {return null;} else {return object;}}
}
2.5 二级缓存总结
- 二级缓存和一级缓存的本质一样,最终的真实结果都是保存到
PerpetualCache这个类中的。只不过二级缓存在其基础上封装了很多层,也就是Cache实例对象(详细的看2.3小节)。 - 二级缓存的开启:必须在对应
Mapper文件中添加cache标签。其他属性可配。 - 二级缓存在一级缓存的基础上,对
Executor进行了封装,封装一个CachingExecutor类,读取数据的顺序是:二级缓存-->一级缓存-->数据库。 - 无非就是
CachingExecutor类中保存了TransactionalCacheManager这个实例,通过Cache实例对象作为Key,拿到对应的TransactionalCache实例对象。它相当于一种缓存装饰器,可以为Cache实例增加一个事务功能。 - 我们可以看出来,
Mybatis中的二级缓存,用到了大量的装饰器模式风格的开发。不断的对缓存进行一个装饰封装。日志、同步等等。