目录
前言
一、DataFrame
1. 列的选取
2. 行的选取
3. 列的修改
4. 列的删除
5. 嵌套字典赋给DataFrame
总结
前言
继续上一节的内容。往期内容如下:
【自学】利用python进行数据分析 LESSON5 <pandas入门——pandas数据结构介绍1>_Rachel MuZy的博客-CSDN博客主要学习了pandas的数据结构,包括 Series 和 DataFramehttps://blog.csdn.net/mzy20010420/article/details/127026241
一、DataFrame
行也可以通过位置或特殊属性的 loc 进行选取,列的引用直接说明列的名称即可
1. 列的选取
DataFrame中的一列,可以按照字典型标记或属性那样检索为series:
示例:
import pandas as pd
import numpy as npdata = {'state': ['Astrilia', 'Mexico', 'China', 'Japan'],'years': [2000, 2001, 2002, 2003],'pop': [1.5, 3.6, 2.4, 5.1]}
frame = pd.DataFrame(data, columns = ['years', 'state', 'pop'])
val = pd.Series([-1.2, -1.5, -1.7])
frame['debt'] = val
val_1 = pd.Series([100, 200, 300], index = [0, 1, 3])
frame['pofit'] = val_1
print(frame)
frame_1 = frame['state']
print(frame_1)
frame_2 = frame.state
print(frame_2)
#可以说,frame['state']和frame.state是等价的结果:
years state pop debt pofit
0 2000 Astrilia 1.5 -1.2 100.0
1 2001 Mexico 3.6 -1.5 200.0
2 2002 China 2.4 -1.7 NaN
3 2003 Japan 5.1 NaN 300.0
0 Astrilia
1 Mexico
2 China
3 Japan
Name: state, dtype: object
0 Astrilia
1 Mexico
2 China
3 Japan
Name: state, dtype: object2. 行的选取
通过特殊属性loc进行选取:
示例:
import pandas as pd
import numpy as npdata = {'state': ['Astrilia', 'Mexico', 'China', 'Japan'],'years': [2000, 2001, 2002, 2003],'pop': [1.5, 3.6, 2.4, 5.1]}
frame = pd.DataFrame(data, columns = ['years', 'state', 'pop'])
val = pd.Series([-1.2, -1.5, -1.7])
frame['debt'] = val
val_1 = pd.Series([100, 200, 300], index = [0, 1, 3])
frame['pofit'] = val_1
print(frame)#当行为默认的索引标签时
frame_1row = frame.loc[1]
print(frame_1row)#当行有自己设定的索引标签时
frame_label = pd.DataFrame(data, columns = ['years', 'state', 'pop'], index = ['one', 'two', 'three', 'four'])
print(frame_label)
frame_label_row = frame_label.loc['two']
print(frame_label_row)结果:
years state pop debt pofit
0 2000 Astrilia 1.5 -1.2 100.0
1 2001 Mexico 3.6 -1.5 200.0
2 2002 China 2.4 -1.7 NaN
3 2003 Japan 5.1 NaN 300.0
years 2001
state Mexico
pop 3.6
debt -1.5
pofit 200.0
Name: 1, dtype: objectyears state pop
one 2000 Astrilia 1.5
two 2001 Mexico 3.6
three 2002 China 2.4
four 2003 Japan 5.1
years 2001
state Mexico
pop 3.6
Name: two, dtype: object3. 列的修改
列的引用是可以修改的。例如空的‘debt’列可以赋值为标量值或值数组。
示例:
import pandas as pd
import numpy as npdata = {'state': ['Astrilia', 'Mexico', 'China'],'years': [2000, 2001, 2002],'pop': [1.5, 3.6, 2.4]}
frame = pd.DataFrame(data, columns = ['years', 'state', 'pop'])
print(frame)
frame['debt'] = 16.2
print(frame)
frame['pofit'] = np.random.randint(100, 200, size = 3)
print(frame)结果:
years state pop
0 2000 Astrilia 1.5
1 2001 Mexico 3.6
2 2002 China 2.4years state pop debt
0 2000 Astrilia 1.5 16.2
1 2001 Mexico 3.6 16.2
2 2002 China 2.4 16.2years state pop debt pofit
0 2000 Astrilia 1.5 16.2 192
1 2001 Mexico 3.6 16.2 138
2 2002 China 2.4 16.2 140当将列表或数组赋值给一个列时,值的长度必须和DataFrame的长度相匹配。
示例:
import pandas as pd
import numpy as npdata = {'state': ['Astrilia', 'Mexico', 'China', 'Japan'],'years': [2000, 2001, 2002, 2003],'pop': [1.5, 3.6, 2.4, 5.1]}
frame = pd.DataFrame(data, columns = ['years', 'state', 'pop'])
print(frame)
val = pd.Series([-1.2, -1.5, -1.7])
frame['debt'] = val
print(frame)
val_1 = pd.Series([100, 200, 300], index = [0, 1, 3])
frame['pofit'] = val_1
print(frame)结果:
years state pop
0 2000 Astrilia 1.5
1 2001 Mexico 3.6
2 2002 China 2.4
3 2003 Japan 5.1years state pop debt
0 2000 Astrilia 1.5 -1.2
1 2001 Mexico 3.6 -1.5
2 2002 China 2.4 -1.7
3 2003 Japan 5.1 NaNyears state pop debt pofit
0 2000 Astrilia 1.5 -1.2 100.0
1 2001 Mexico 3.6 -1.5 200.0
2 2002 China 2.4 -1.7 NaN
3 2003 Japan 5.1 NaN 300.0如果被复制的列不存在,则会生成一个新的列:
示例:
import pandas as pd
import numpy as npdata = {'state': ['Astrilia', 'Mexico', 'China', 'Japan'],'years': [2000, 2001, 2002, 2003],'pop': [1.5, 3.6, 2.4, 5.1]}
frame = pd.DataFrame(data, columns = ['years', 'state', 'pop'])
val = pd.Series([-1.2, -1.5, -1.7])
frame['debt'] = val
val_1 = pd.Series([100, 200, 300], index = [0, 1, 3])
frame['pofit'] = val_1
print(frame)#给新的一列赋值
frame['date'] = np.random.randint(1, 10, size = 4)
print(frame)结果:
years state pop debt pofit
0 2000 Astrilia 1.5 -1.2 100.0
1 2001 Mexico 3.6 -1.5 200.0
2 2002 China 2.4 -1.7 NaN
3 2003 Japan 5.1 NaN 300.0years state pop debt pofit date
0 2000 Astrilia 1.5 -1.2 100.0 7
1 2001 Mexico 3.6 -1.5 200.0 1
2 2002 China 2.4 -1.7 NaN 8
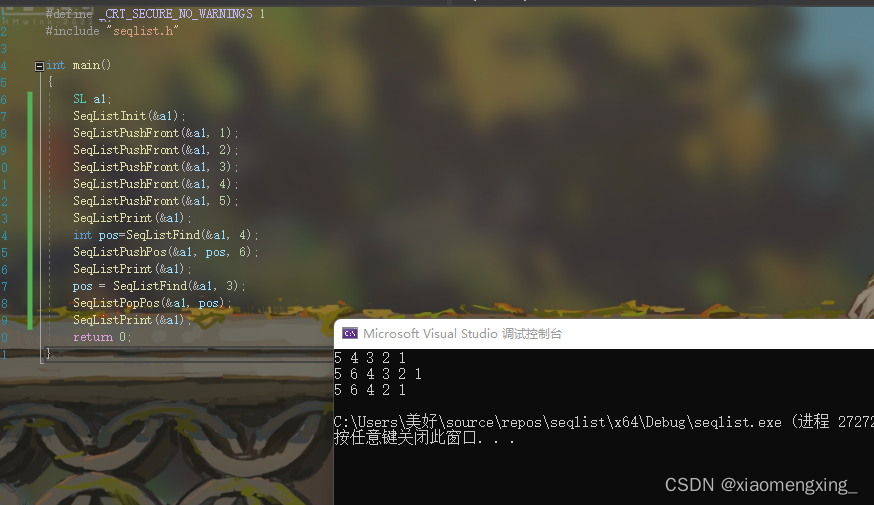
3 2003 Japan 5.1 NaN 300.0 44. 列的删除
用del函数
示例:先增添一个由布尔值组成的列:
import pandas as pd
import numpy as npdata = {'state': ['Astrilia', 'Mexico', 'China', 'Mexico'],'years': [2000, 2001, 2002, 2003],'pop': [1.5, 3.6, 2.4, 5.1]}
frame = pd.DataFrame(data, columns = ['years', 'state', 'pop'])
val = pd.Series([-1.2, -1.5, -1.7])
frame['debt'] = val
val_1 = pd.Series([100, 200, 300], index = [0, 1, 3])
frame['pofit'] = val_1
print(frame)'''现在构建一个布尔值组成的数组,如果state == Mexico,则在FT列输出T,否则为F'''
#方法1
frame['TF'] = frame.state == 'Mexico'
print(frame)print(frame.TF[0])#方法2
Buer = []
for i in range(4):Buer.append(frame.state[i] == 'Mexico')
frame['tf'] = Buer
print(frame)结果:
years state pop debt pofit
0 2000 Astrilia 1.5 -1.2 100.0
1 2001 Mexico 3.6 -1.5 200.0
2 2002 China 2.4 -1.7 NaN
3 2003 Mexico 5.1 NaN 300.0years state pop debt pofit TF
0 2000 Astrilia 1.5 -1.2 100.0 False
1 2001 Mexico 3.6 -1.5 200.0 True
2 2002 China 2.4 -1.7 NaN False
3 2003 Mexico 5.1 NaN 300.0 True
Falseyears state pop debt pofit TF tf
0 2000 Astrilia 1.5 -1.2 100.0 False False
1 2001 Mexico 3.6 -1.5 200.0 True True
2 2002 China 2.4 -1.7 NaN False False
3 2003 Mexico 5.1 NaN 300.0 True True进程已结束,退出代码0
然后删除TF列:
import pandas as pd
import numpy as npdata = {'state': ['Astrilia', 'Mexico', 'China', 'Mexico'],'years': [2000, 2001, 2002, 2003],'pop': [1.5, 3.6, 2.4, 5.1]}
frame = pd.DataFrame(data, columns = ['years', 'state', 'pop'])
val = pd.Series([-1.2, -1.5, -1.7])
frame['debt'] = val
val_1 = pd.Series([100, 200, 300], index = [0, 1, 3])
frame['pofit'] = val_1
print(frame)'''现在构建一个布尔值组成的数组,如果state == Mexico,则在FT列输出T,否则为F'''
#构建一个新的列
frame['TF'] = frame.state == 'Mexico'
print(frame)#删除该列
del frame['TF']
print(frame)结果:
years state pop debt pofit
0 2000 Astrilia 1.5 -1.2 100.0
1 2001 Mexico 3.6 -1.5 200.0
2 2002 China 2.4 -1.7 NaN
3 2003 Mexico 5.1 NaN 300.0years state pop debt pofit TF
0 2000 Astrilia 1.5 -1.2 100.0 False
1 2001 Mexico 3.6 -1.5 200.0 True
2 2002 China 2.4 -1.7 NaN False
3 2003 Mexico 5.1 NaN 300.0 Trueyears state pop debt pofit
0 2000 Astrilia 1.5 -1.2 100.0
1 2001 Mexico 3.6 -1.5 200.0
2 2002 China 2.4 -1.7 NaN
3 2003 Mexico 5.1 NaN 300.0进程已结束,退出代码0
注意这里:

必须要这样写,才可以正常跑通
如果写成这样:
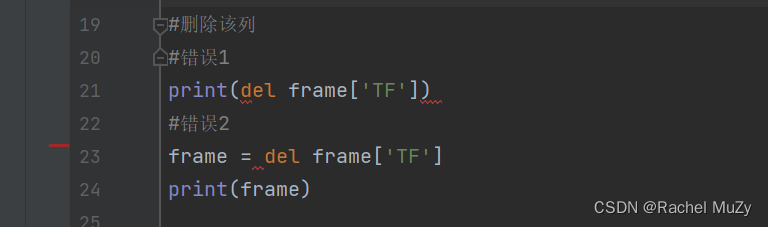 这两种写法都会报错!!!
这两种写法都会报错!!!
5. 嵌套字典赋给DataFrame
如果嵌套字典被赋值给DataFrame,pandas会将字典的键作为列,内部字典的键作为行索引:
示例:
import pandas as pd
import numpy as nppop = {'MZY': {2001: 2.4, 2002: 2.9},'DRX': {2000: 1.5, 2001: 1.7, 2002: 3.6}}
frame = pd.DataFrame(pop)
print(frame)结果:
MZY DRX
2001 2.4 1.7
2002 2.9 3.6
2000 NaN 1.5可以使用类似于numpy的语法对其进行转置:
示例:
import pandas as pd
import numpy as nppop = {'MZY': {2001: 2.4, 2002: 2.9},'DRX': {2000: 1.5, 2001: 1.7, 2002: 3.6}}
frame = pd.DataFrame(pop)
print(frame)#转置
print(frame.T)结果:
MZY DRX
2001 2.4 1.7
2002 2.9 3.6
2000 NaN 1.52001 2002 2000
MZY 2.4 2.9 NaN
DRX 1.7 3.6 1.5如果显示指明索引的话,内部字典的键不会被排序:
示例:
import pandas as pd
import numpy as nppop = {'MZY': {2001: 2.4, 2002: 2.9},'DRX': {2000: 1.5, 2001: 1.7, 2002: 3.6}}
frame = pd.DataFrame(pop)
print(frame)frame1 = pd.DataFrame(pop, index=[2000, 2002, 2001, 2003])
print(frame1)结果:
MZY DRX
2001 2.4 1.7
2002 2.9 3.6
2000 NaN 1.5MZY DRX
2000 NaN 1.5
2002 2.9 3.6
2001 2.4 1.7
2003 NaN NaN总结
尽管Series和DataFrame不能解决所有问题,但是它们为大多数应用提供了一个有效、易用的基础。